Spark分布式HA环境安装
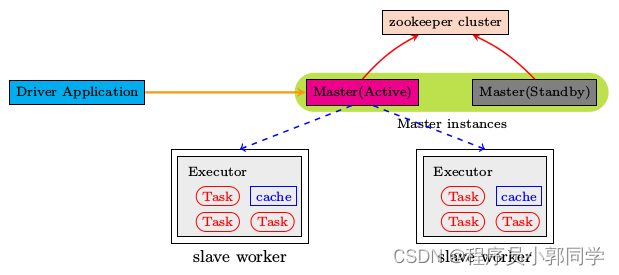
图-12 高可用模式原理
因为在目前情况下,集群中只有一个Master,如果master挂掉,便无法对外提供新的服务,显然有单点故障问题,解决方法就是master的ha。
有两种方式解决单点故障,一种基于文件系统FileSystem(生产中不用),还有一种基于Zookeeper(使用)。
配置基于Zookeeper的一个ha是非常简单的,只需要在spark-env.sh中添加一句话即可。
修改配置文件
注释掉如下内容:
#SPARK_MASTER_HOST=hadoop101
SPARK_MASTER_PORT=7077添加上如下内容:配置的时候保证下面语句在一行,否则配置不成功,每个-D参数使用空格分开
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop101:2181,hadoop102:2181,hadoop103:2181
-Dspark.deploy.zookeeper.dir=/spark"
spark.deploy.recoveryMode设置成 ZOOKEEPER。
spark.deploy.zookeeper.urlZooKeeper URL。
spark.deploy.zookeeper.dir ZooKeeper 保存恢复状态的目录,缺省为/spark。因为ha不确定master在hadoop101上面启动,所以将export SPARK_MASTER_HOST=hadoop101注释掉。
最后别忘了,同步spark-env.sh到其它机器。
scp -r spark-env.sh hadoop102:$PWD
scp -r spark-env.sh hadoop103:$PWD启动并体验
:wq

图-13 hadoop101的master状态图
hadoop102也启动master,其状态如图-14:
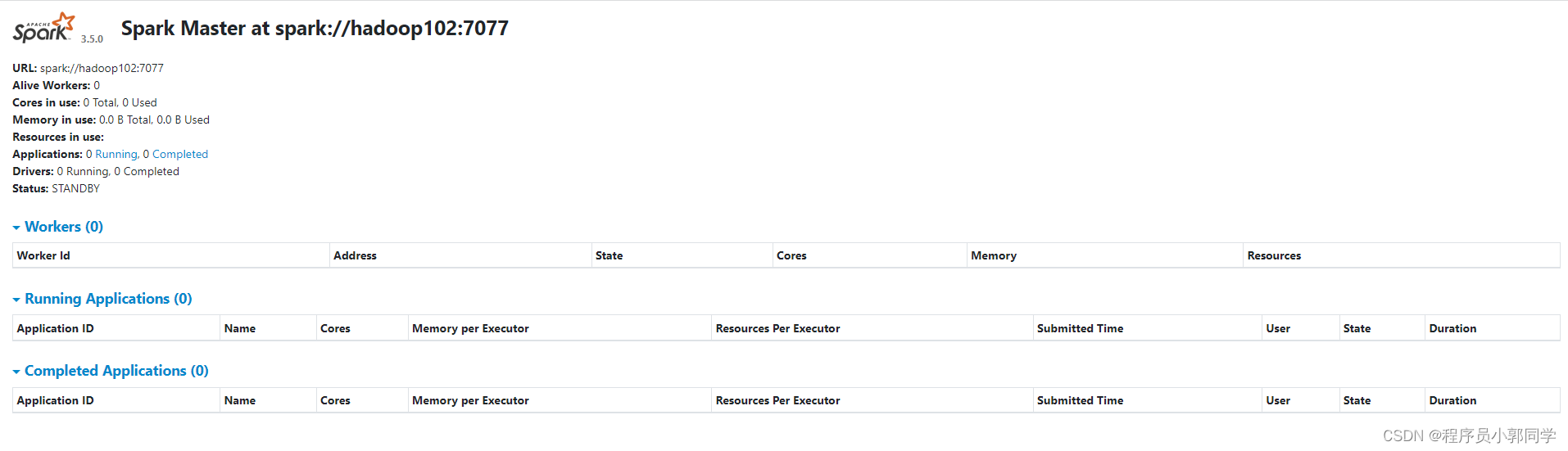
图-14 hadoop102的master状态图
提交任务&执行程序:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop101:7077,hadoop102:7077 \
./examples/jars/spark-examples_2.12-3.5.0.jar \
100
ha验证,要干掉alive的master,观察standby的master,hadoop102的状态缓慢的有standby转变为alive。
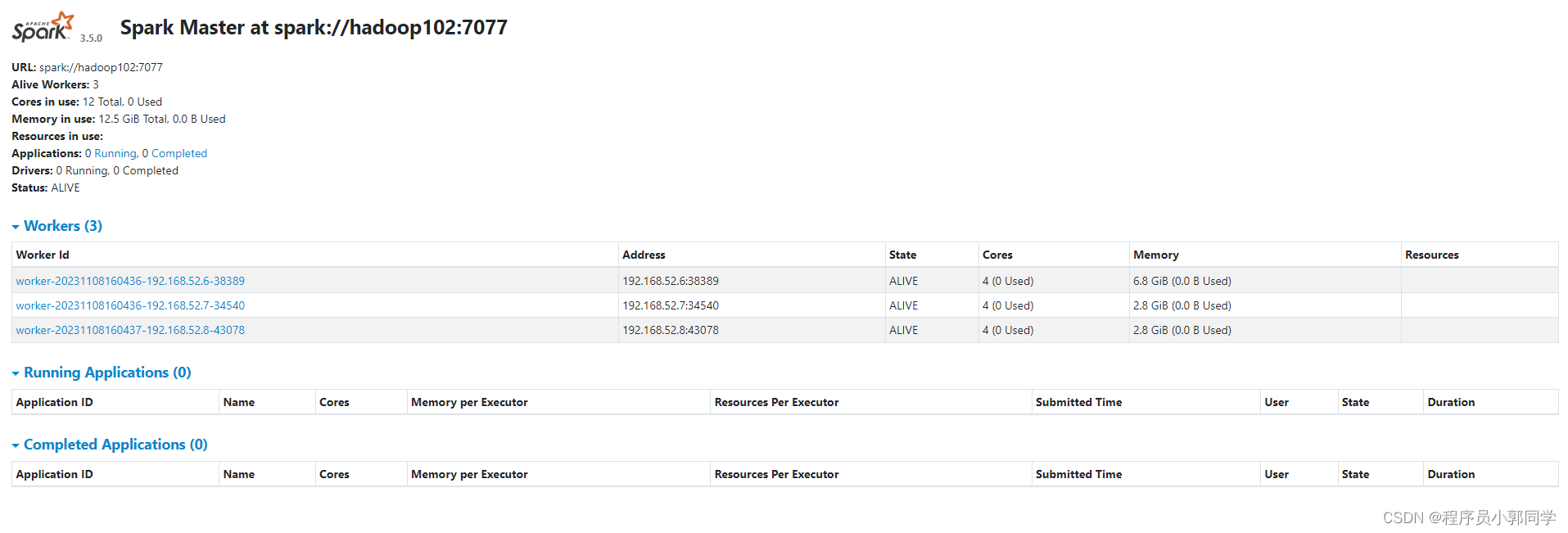
图-15 ha切换之后的master状态图
动态增删节点
1)上线:不需要在现有集群的配置上做任何修改,只需要准备一台worker机器即可,可和之前的worker的配置相同。
图-16 spark集群启动slave配置图
sbin/start-slave.sh hadoop101:7077 -c 4 -m 1024M
2)下线:杀掉对应slave进程,或者执行脚本stop-slave.sh。

图-17 动态下线
Spark分布式Yarn环境安装
修改hadoop配置文件
vim yarn-site.xml
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>修改spark配置文件
vim spark-env.sh
YARN_CONF_DIR=/opt/module/hadoop-3.2.4/etc/hadoop
HADOOP_CONF_DIR=/opt/module/hadoop-3.2.4/etc/hadoop启动并体验
1)client模式:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.12-3.5.0.jar \
100
注意:在提交任务之前需启动HDFS以及YARN集群。
2)cluster模式:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.5.0.jar \
100