1.在idea中创建项目 selectData.

2.添加依赖,插件包,指定打包方式,日志文件


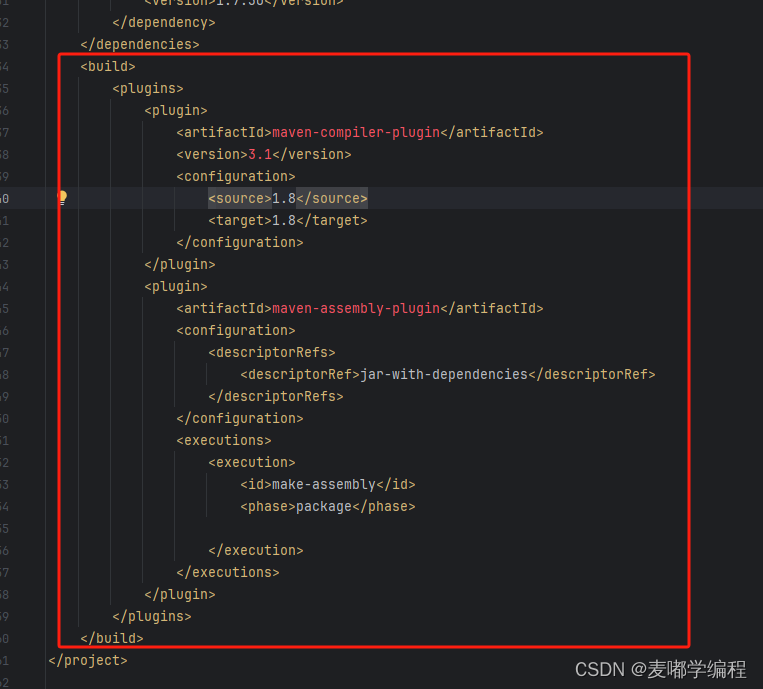

大家可以直接从前面项目复制。
3.本次只需要进行序列化操作,所以不需要Reducer模块,编写Mapper模块
package com.maidu.selectdata;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author:yt
* @since:2024-04-25
*/
public class MyMapper extends Mapper<Object, Text,Text,Text> {
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line =value.toString();
String []arr=line.split(",");
if(arr[4].contains("2021/1") ||arr[4].contains("2021/2")){
context.write(new Text(arr[2]),new Text(arr[4].substring(0,arr[4].indexOf(" ")) ));
}
}
}

4、编写Driver模块
package com.maidu.selectdata;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
/**
* @author:yt
* @since:2024-04-25
*/
public class SelectData {
public static void main(String[] args) throws Exception {
Configuration conf =new Configuration();
String []otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length<2){
System.out.println("必须输入文件输入路径和输出路径");
System.exit(2);
}
Job job = Job.getInstance(conf,"visit count");
job.setJarByClass(SelectData.class);
job.setMapperClass(MyMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//设置输入格式
job.setInputFormatClass(TextInputFormat.class);
//设置输出格式
job.setOutputFormatClass(SequenceFileOutputFormat.class);
//设置reduce任务为0
job.setNumReduceTasks(0);
for(int i=0;i<otherArgs.length-1;i++){
FileInputFormat.addInputPath(job,new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,new Path(otherArgs[ otherArgs.length-1 ]));
System.exit( job.waitForCompletion(true)?0:1 );
}
}

5、使用maven打包为jar,上传到master上

6、执行jar
[yt@master ~]$ hadoop jar selectData-1.0-SNAPSHOT.jar com.maidu.selectdata.SelectData /bigdata/raceData.csv /bigdata/select_data.txt
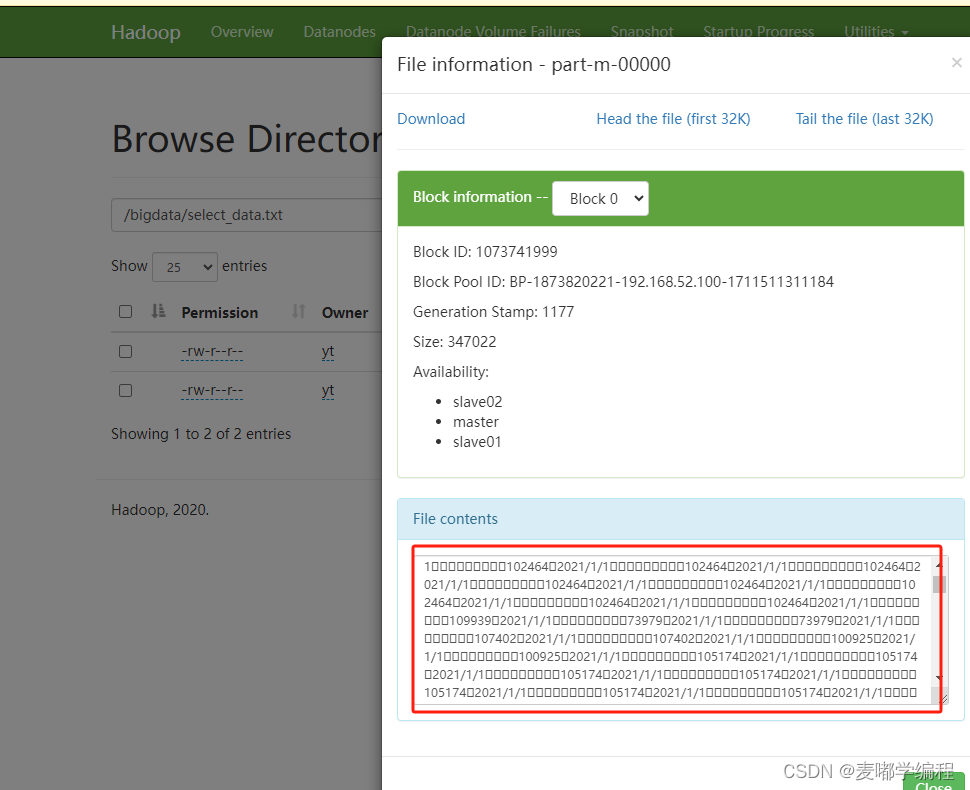
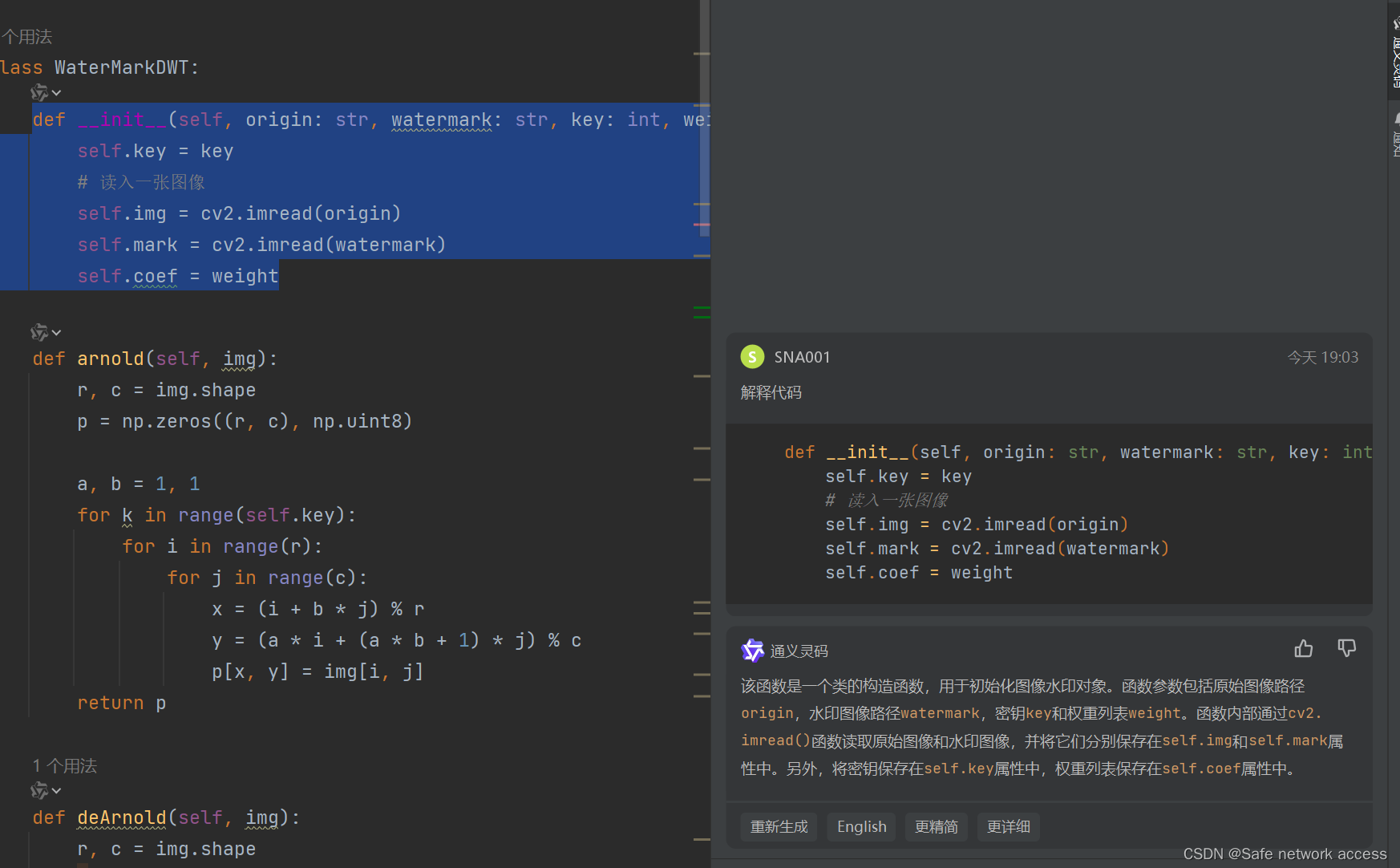
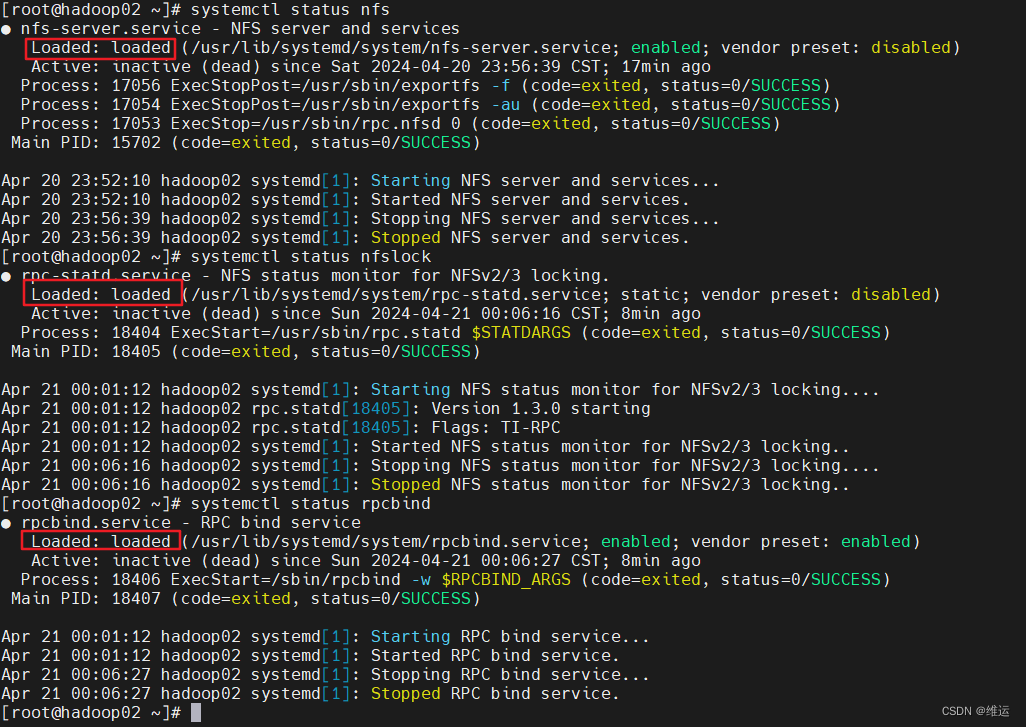
7、查看序列化文件









![[C++]22:C++11_part_one](https://img-blog.csdnimg.cn/direct/79bf6e0d6b764b14aca1185d8cb4c561.png)