目录
- 深入理解分布式事务② ---->分布式事务基础(MySQL 的 4 种事务隔离级别【读未提交、读已提交、可重复读、串行化】的最佳实践演示)详解
- 1、MySQL 事务基础
- 1-1:MySQL 中 4 种事务隔离级别的区别
- 1-2:MySQL 中 4 种事务隔离级别的最佳实践演示
- 数据准备:启动两个 MySQL 服务器终端
- 数据准备:创建数据库和表数据
- 1-2-1:演示:读未提交(出现脏读问题)
- 第一步:
- 第二步:
- 第三步:重点来了
- 第四步:
- 额外尝试:
- 演示事务正常提交的结果
- 演示锁等待超时的结果
- 演示事务回滚后的结果
- 1-2-2:演示:读已提交(解决脏读,但出现不可重复读问题)
- 第一步:
- 第二步:
- 第三步:
- 第四步:
- 第五步:
- 终端A 和 终端B 命令总流程对比:
- 1-2-3:演示:可重复读(解决不可重复读问题,但出现幻读问题)
- 第一步:
- 第二步:
- 第三步:
- 第四步:
- 第五步:演示:出现幻读
- 第六步:
- 第七步:
- 1-2-4:串行化(解决幻读等所有并发问题)
- 第一步:
- 第二步:
- 演示串行化级别下进行范围查询的实例:
深入理解分布式事务① ---->分布式事务基础(四大特性、五大类型、本地事务、MySQL并发事务问题、MySQL事务隔离级别命令设置)详解
深入理解分布式事务② ---->分布式事务基础(MySQL 的 4 种事务隔离级别【读未提交、读已提交、可重复读、串行化】的最佳实践演示)详解
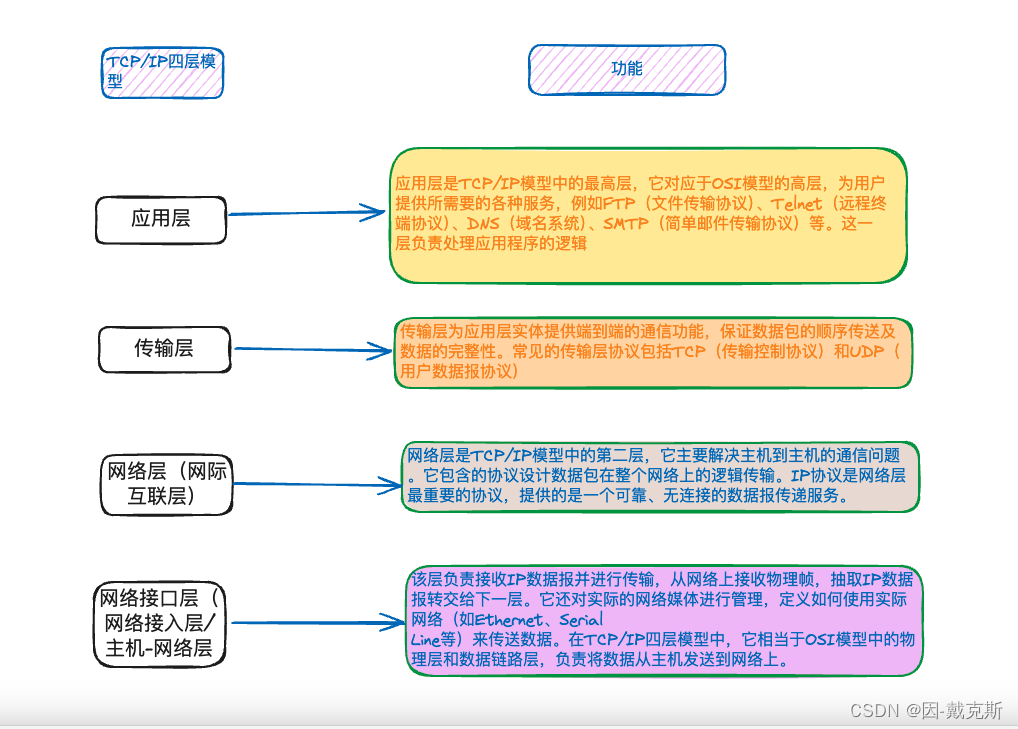
1、MySQL 事务基础
1-1:MySQL 中 4 种事务隔离级别的区别
4 种事务隔离级别对于并发事务带来的问题的解决程度不一样。
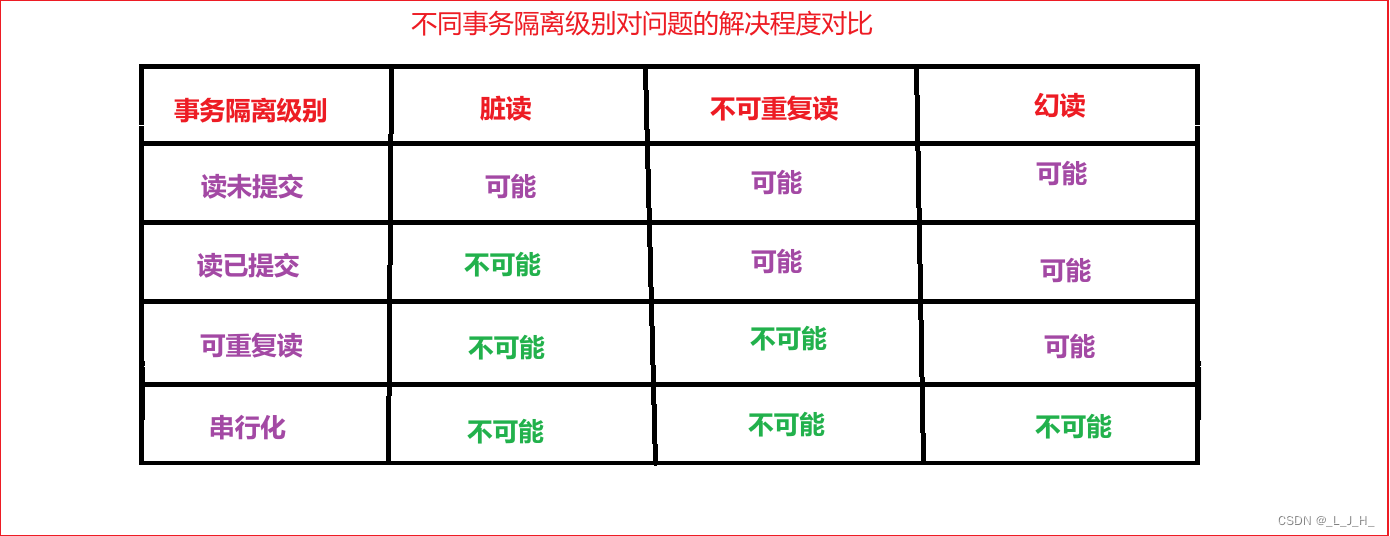
1、读未提交允许脏读,即在读未提交的事务隔离级别下,可能读取到其他会话未提交的事务修改的数据。这种事务隔离级别下存在【脏读】、【不可重复读】和【幻读】的问题。
2、读已提交只能读取到已经提交的数据。Oracle 等数据库使用的默认事务隔离级别就是【读已提交】。这种事务隔离级别存在【不可重复读】和【幻读】的问题。
3、可重复读就是在同一个事务内,无论何时查询到的数据都与一开始查询到的数据一致,这就是 MySQL 中 InnoDB 存储引擎默认的事务隔离级别。
这种事务隔离级别下存在【幻读】的问题。
4、串行化是指完全串行的读,每次读取数据库中的数据时,都需要获得表级别的共享锁,读和写都会阻塞。
这种事务隔离级别解决了并发事务带来的问题,但是完全的串行化操作使得数据库失去了并发特性,所以这种事务隔离级别往往在互联网行业中不太常用。
1-2:MySQL 中 4 种事务隔离级别的最佳实践演示
数据准备:启动两个 MySQL 服务器终端
演示在一台Windows主机上运行两个Mysql服务器(端口号3306 和 3307),安装步骤详解
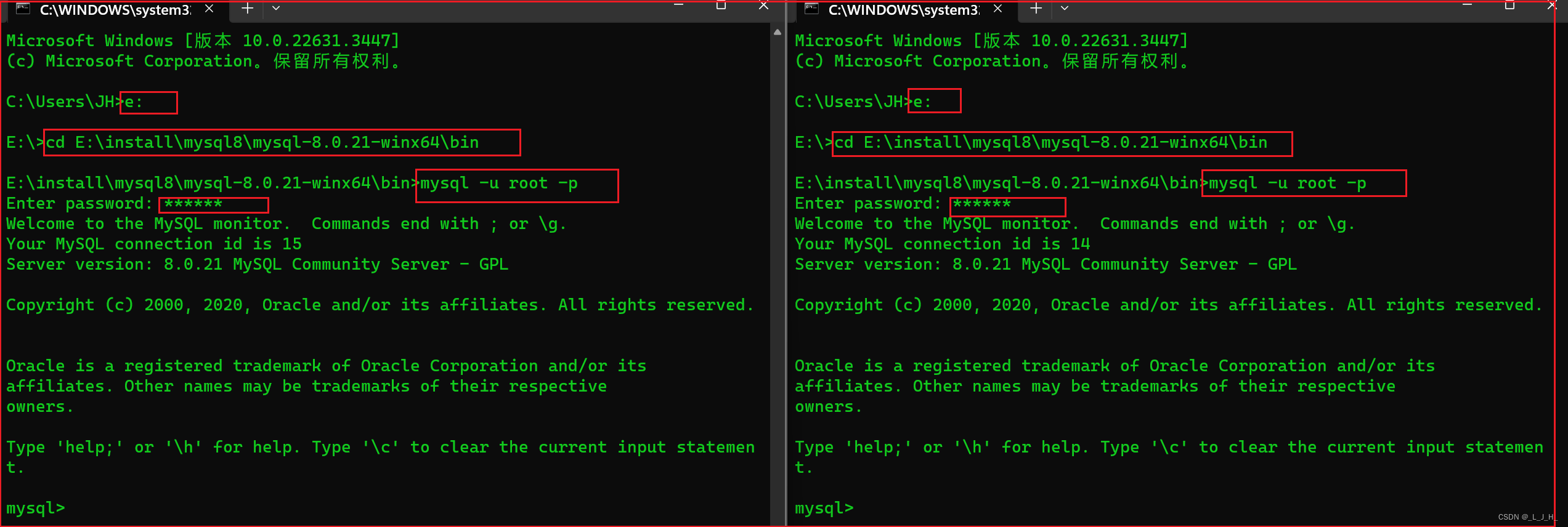
因为要两个服务器终端来演示,因为都是要访问同一个数据库,所以我只需要简单的启动两个命令行窗口,都去访问3306 端口号的 MySQL 服务器就可以了。
3306端口号的bin目录位置:
E:\install\mysql8\mysql-8.0.21-winx64\bin
win+r 打开运行窗口,输入 cmd 打开命令行窗口,输入如下命令启动两个 MySQL 服务器:
e:
cd E:\install\mysql8\mysql-8.0.21-winx64\bin
mysql -u root -p
密码:123456
# 使用这个test数据库
use test;
查看数据库
show databases;
查看端口号
show global variables like 'port';
数据准备:创建数据库和表数据
创建一个test数据库和一张account账户数据表。
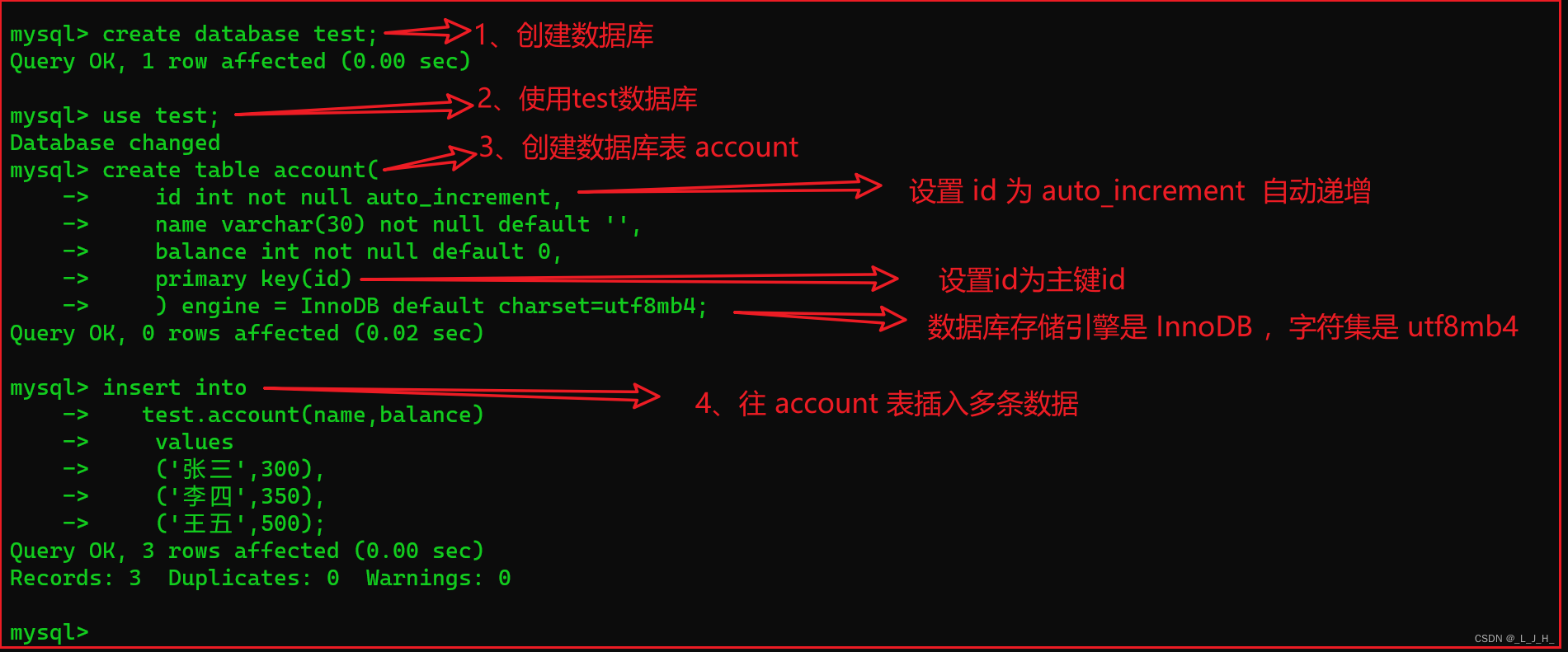
# 创建数据库test
create database test;
# 使用数据库test
use test;
# 创建 account 账户表
# auto_increment 自动递增
create table account(
id int not null auto_increment,
name varchar(30) not null default '',
balance int not null default 0,
primary key(id)
) engine = InnoDB default charset=utf8mb4;
# 往 account 账户表插入数据
insert into
test.account(name,balance)
values
('张三',300),
('李四',350),
('王五',500);
接下来演示 MySQL 中每种事务隔离级别下数据的处理情况。
1-2-1:演示:读未提交(出现脏读问题)
注意:终端A 和 终端B 就是打开两个命令行窗口,同时登录 3306 这个端口号的 MySQL 服务器而已。
第一步:
打开服务器终端A ,登录MySQL,将当前终端的事务隔离级别设置为 read uncommitted ,也就是读未提交。

# 终端A 设置事务隔离级别为:读未提交
set session transaction isolation level read uncommitted;
在终端A 开启事务并查询 account 数据表中的数据,如图:
此时可以看到表中的每个人的名字和账户余额

# 开启事务
start transaction;
# 执行查询
select * from account;
第二步:
在 终端A 的事务提交之前,打开服务器的另一个终端B,连接MySQL,将当前事务模式设置为 read uncommitted (读未提交) 并更新 account 表的数据,将张三的账户余额 +100 元。
注意点:终端A 和 终端B 都是开启了事务,但是还没有提交。
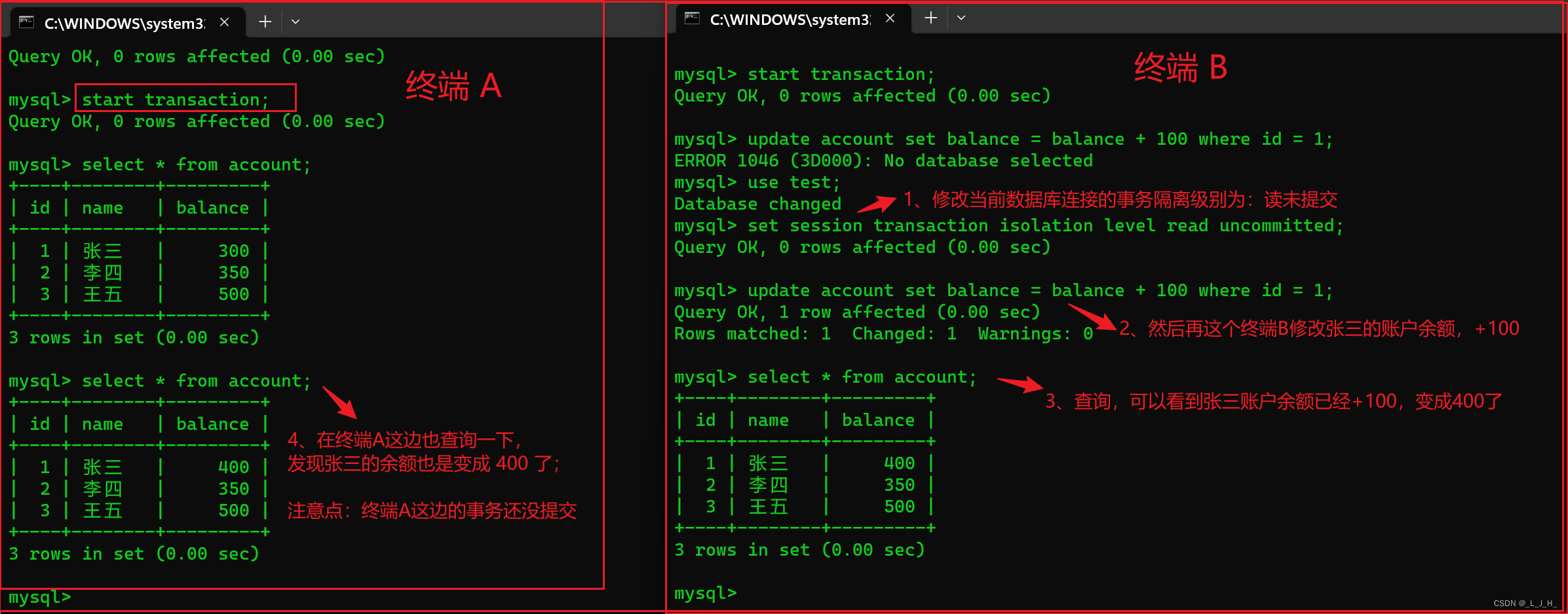
# 这是在 终端B 的命令行窗口操作的,也就是另一个MySQL服务器
# 使用 test 数据库
use test;
# 修改终端B的事务隔离级别为:读未提交
set session transaction isolation level read uncommitted;
# 修改 test 数据库中的acoount 表中的张三的账户余额
update account set balance = balance + 100 where id = 1;
# 执行查询
select * from account;
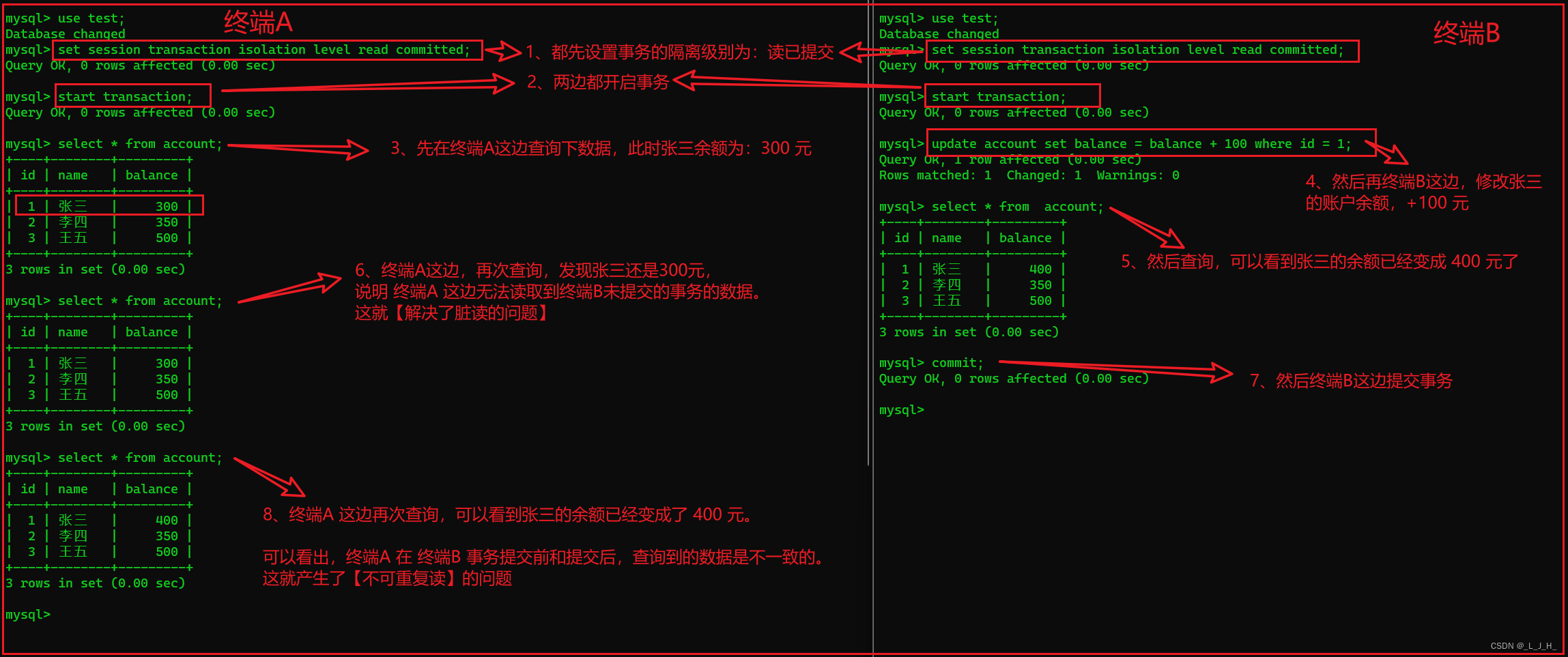
通过上面截图,可以看到,在 终端B 中,当前事务未提交时,张三的账户余额变为更新后的值,即 400 元。
在 终端A 中,可以看到,虽然 终端B 的事务还没有提交,但是 终端A 可以查询到 终端B 已经更新的数据。(这就是读取到其他事务未提交的数据了)
第三步:重点来了
如果此时终端B的事务由于某种原因执行了回滚操作,那么终端B中执行的所有操作都会被撤销。
也就是说,终端A 刚刚查询到的数据其实就是脏数据。
就是 终端B 这边原本修改了张三的账户余额为400,但是因为某些问题回滚了,所以终端B这边的张三的数据又变回300了,而终端A 刚刚已经查到了张三的账户余额为 400 了,那么终端A此时拿到的400元数据就是脏数据,如果终端A拿着这脏数据去执行业务逻辑,那么就会出错。
在终端B 执行事务回滚操作,并查询 account 数据表中的数据,如图:
可以看到,在终端B执行了事务的回滚操作后,张三的账户余额重新变为300元。
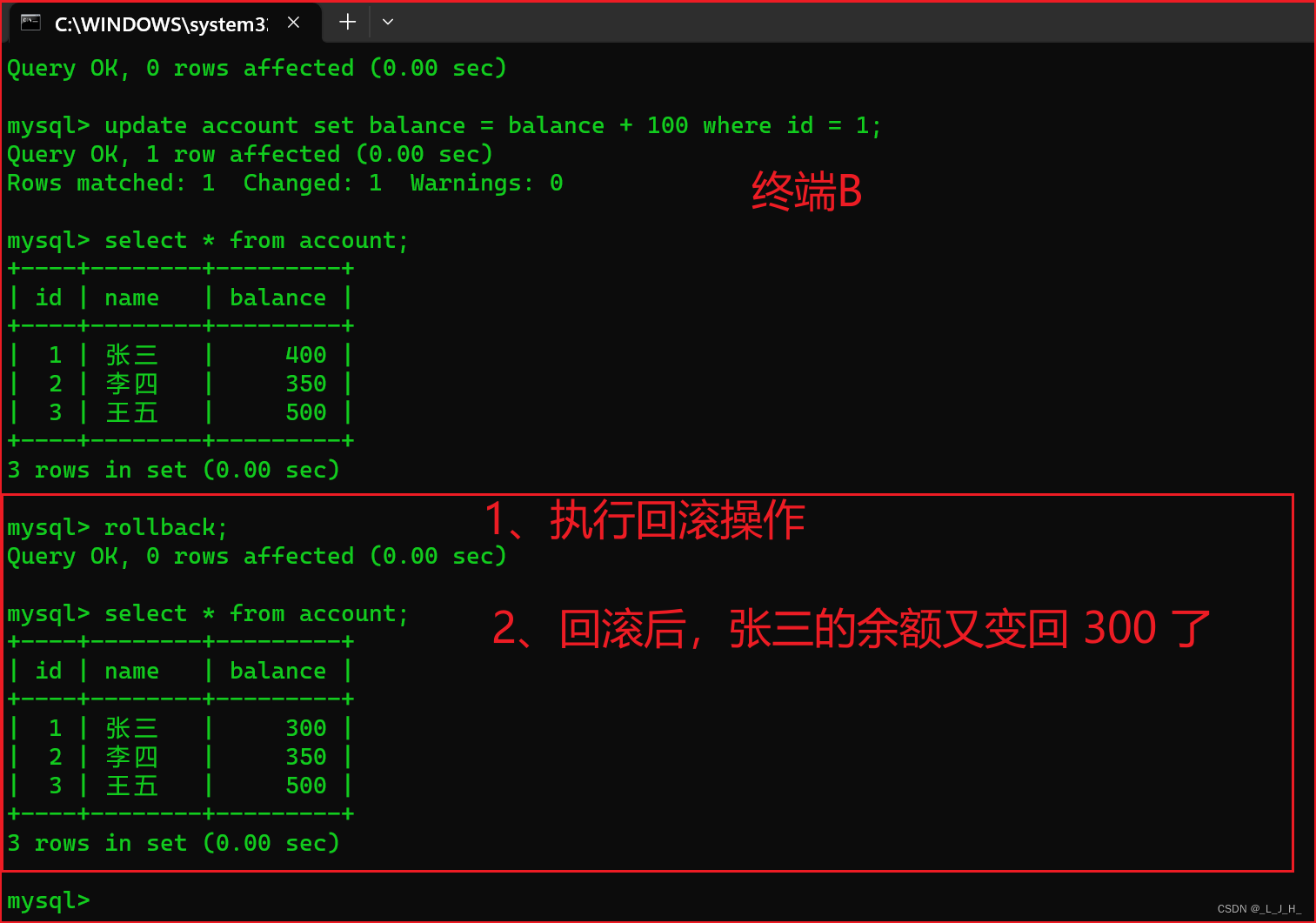
# 执行事务回滚操作
rollback;
# 执行查询
select * from account;
第四步:
此时,画面回到终端A这边,因为终端A查到了张三的账户余额为400元,发现账户余额不对,正确应该是 300 元,所以终端A 这边就会将张三的账户余额 -100 元。
所以最终,因为终端B 那边已经回滚了,终端A不知道,所以实际上 300 -100 = 200,而不是 400 -100 = 300;
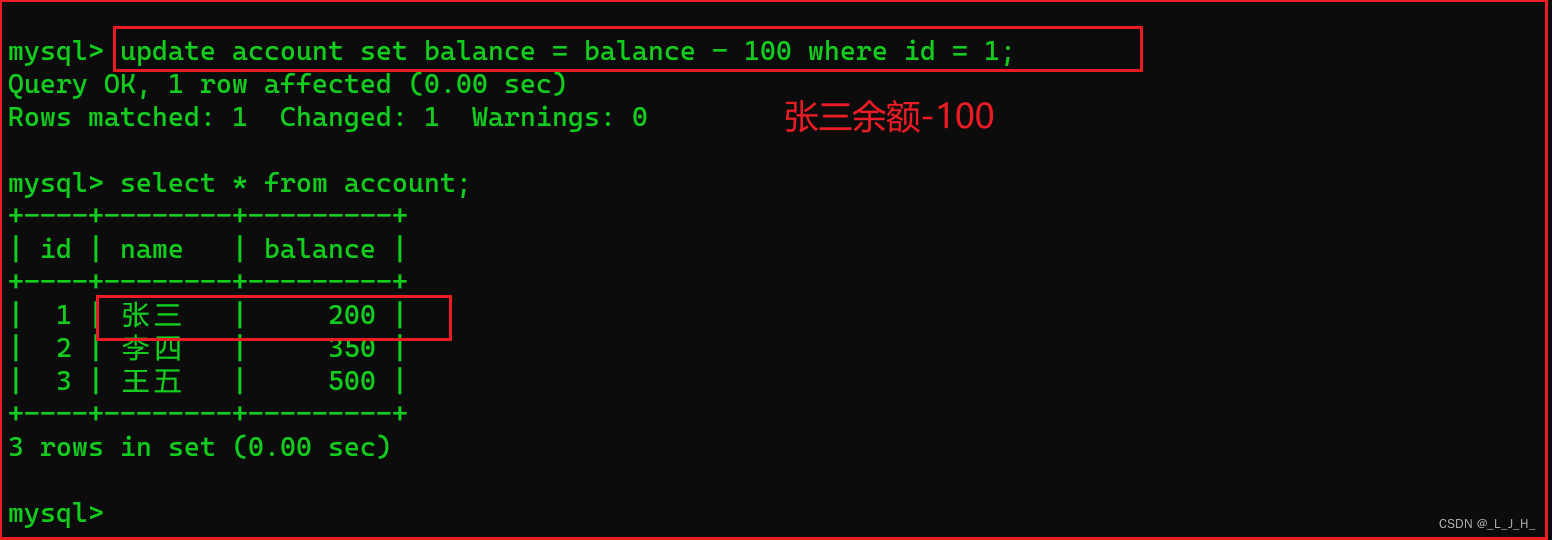
# 终端A 这边,对张三的余额 -100
update account set balance = balance - 100 where id = 1;
# 执行查询操作
select * from account;
因为在应用程序中,并不知道其他会话回滚了事务,所以就会导致拿到的脏数据执行了业务逻辑后,出现错误问题。
重点是:终端A 拿到了 终端B 还未提交的数据,所以拿到的这个数据就是脏数据。
这个就是脏读的问题。
可以采用【读已提交】的事务隔离级别来解决这个问题
额外尝试:
演示事务正常提交的结果
我这里尝试在 终端B 的事务还没有提交之前,终端A 能不能对张三的数据进行修改。
结果是不能的,因为 MySQL的InnoDB 默认是行级锁,得等终端B的事务线程结束,释放锁后,终端A 才能对张三的数据执行操作。
如图,终端B 是正常提交,没有回滚,所以数据是正确的。
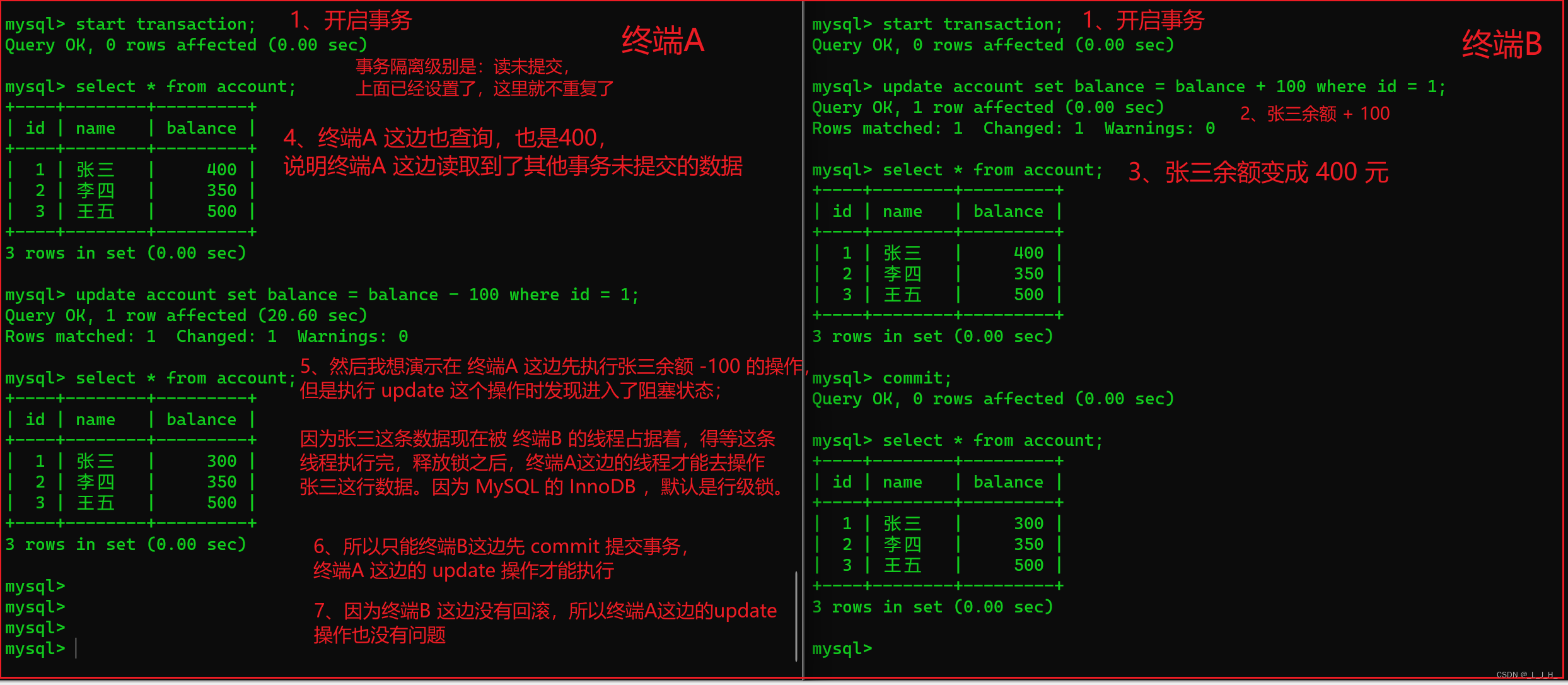
演示锁等待超时的结果
就是张三的数据被终端B的事务线程占据着,在终端B 的事务还没有提交时,也就是该线程还没有执行完;终端A 这边试图获取张三这行数据的锁,因为被 终端B 的线程占据着,所以只能等待,然后一段时间后,终端B 的事务还没有提交,也就是线程还没有执行完,所以终端A 这边就出现了 等待锁超时。
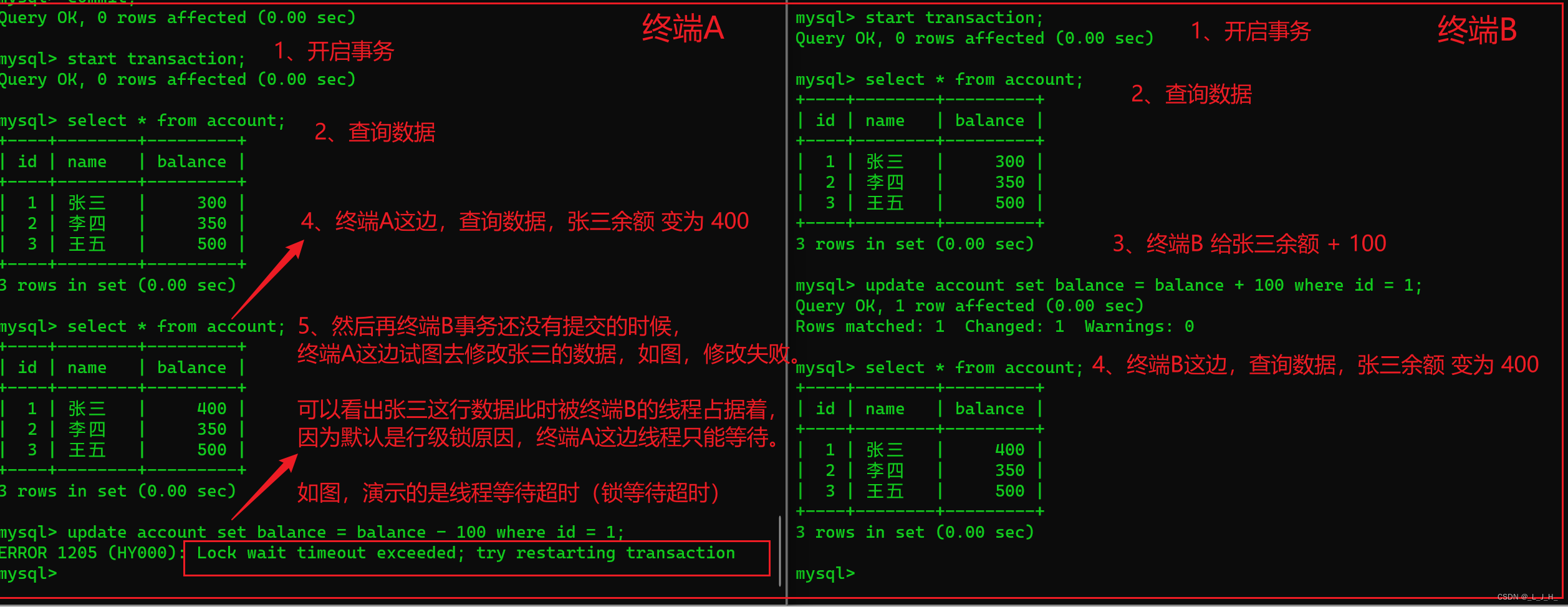
演示事务回滚后的结果
我这里再尝试在 终端B 的事务还没有回滚之前,终端A 对张三的数据进行修改出现的问题演示:
继续从【演示锁等待超时】那里继续演示:
上面是 终端B 修改张三的数据变成 400元,在事务没提交时,终端A 这边拿到了 张三余额400 元的脏数据,发现余额不对,正确应该是 300元,所以执行了 update 操作,要执行 -100 元的操作。
接着如图:终端B 这边执行了回滚,终端A那边并不知道,所以又对数据进行 update 操作。
终端A 想要的是 400-100 = 300,但实际上,因为终端B 那边回滚,导致终端A 这边变成了 300 - 100 = 200。
这就是因为拿到脏数据,导致执行业务逻辑的时候出现了问题。
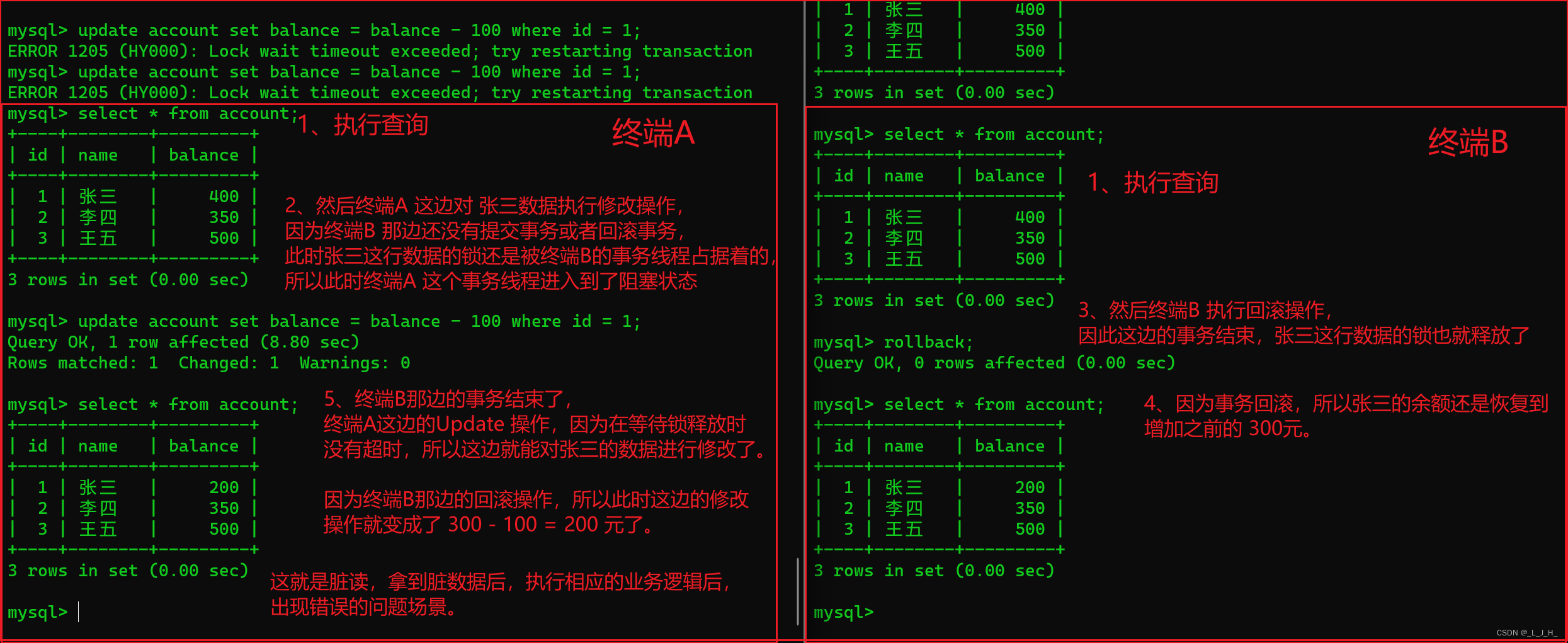
1-2-2:演示:读已提交(解决脏读,但出现不可重复读问题)
注意:终端A 和 终端B 就是打开两个命令行窗口,同时登录 3306 这个端口号的 MySQL 服务器而已。
演示之前,都会把数据恢复成最开始的数据。
第一步:
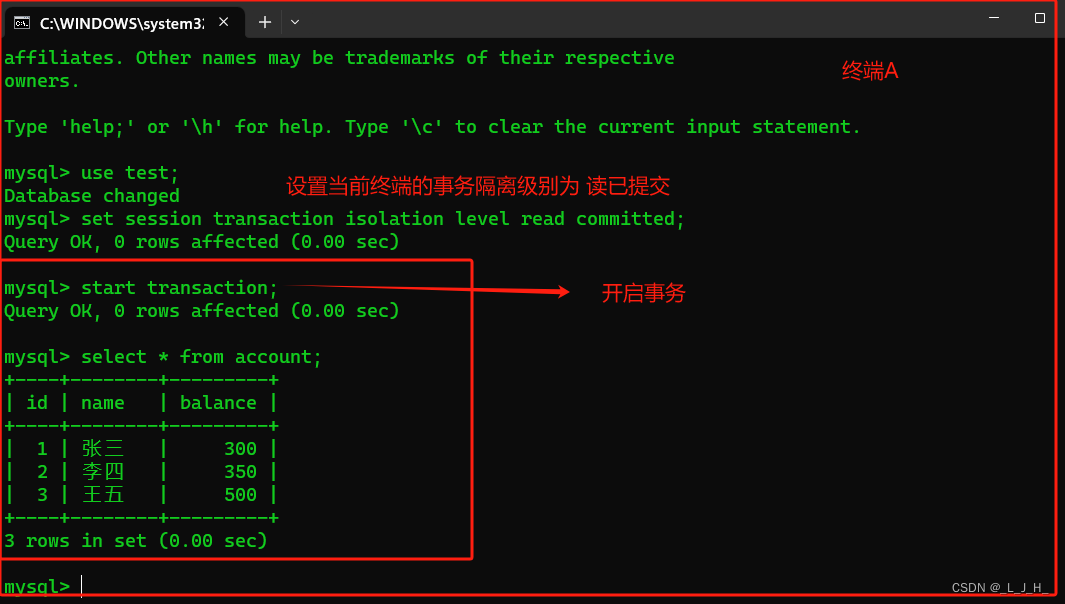
打开一个终端A(就是打开一个命令行窗口,进行登录3306端口号的MySQL服务器而已),将当前终端的事务隔离级别设置为 read committed,也就是【读已提交】。
如图:

# 设置当前终端的事务隔离级别设置为 read committed 读已提交
set session transaction isolation level read committed;
在终端A 开启事务并查询 account 数据表中的数据,如下所示:
# 开启事务
start transaction;
# 执行查询
select * from account;
可以看到,这几个人的账户余额。
第二步:
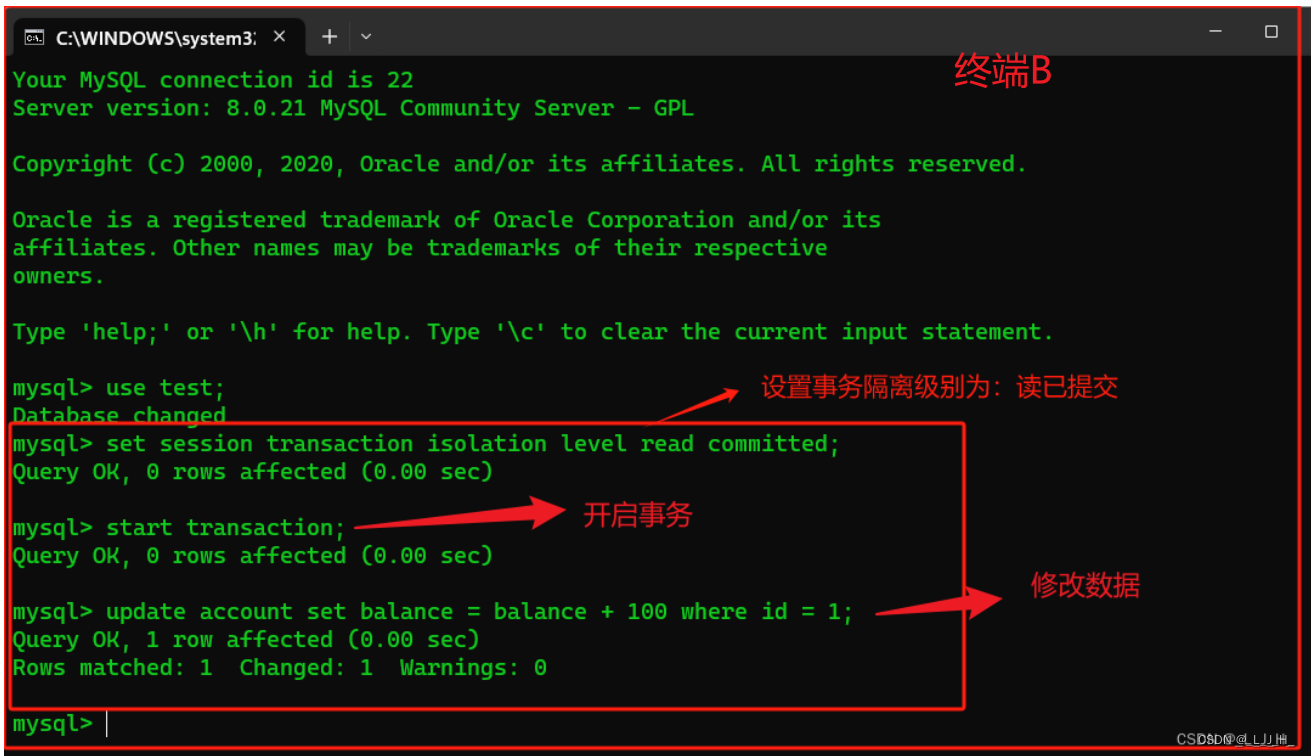
在终端A 的事务提交之前,打开终端B(就是打开另一个命令行窗口,也进行登录3306端口号的MySQL服务器而已),将当前终端的事务隔离级别也设置为 read committed 【读已提交】,开启事务并更新account 数据表中的数据,将张三的账户余额 +100元。
如下所示:
接着,在 终端B 查询 account 数据表中的数据,如下所示:
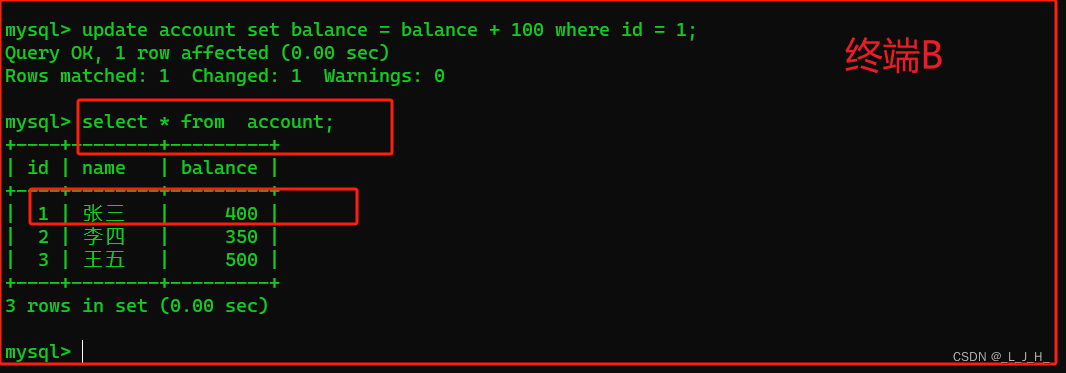
可以看到,在终端B 的查询结果中,张三的账户余额已经由原来的 300 元 变成 400 元。
# 使用 test 这个数据库
use test;
# 设置当前数据库连接的事务隔离级别为:读已提交
set session transaction isolation level read committed;
# 开启事务
start transaction;
# 修改张三的账户余额,+100 元
update account set balance = balance + 100 where id = 1;
# 执行查询
select * from account;
第三步:
在终端B 的事务提交之前,在终端A中查询 account 数据表中的数据,如下所示:

可以看到,在终端A 查询出来的张三的账户余额仍然为 300 元,说明此时已经解决了脏读的问题。
第四步:
在 终端B 提交事务,如下所示

# 提交事务
commit;
第五步:
在终端B提交事务后,在终端A再次查询account数据表中的数据,如下所示:
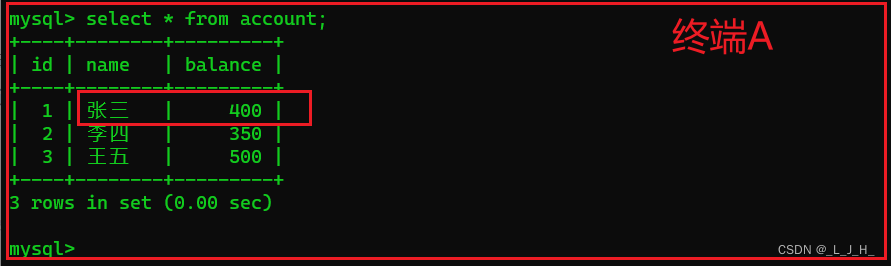
可以看到,终端A 在 终端B 的事务提交前和提交后,读取到的 account 数据表中的数据不一致(张三的账户余额不一致),这就产生了不可重复读的问题。
要想解决这个问题,就需要使用可重复读的事务隔离级别。
终端A 和 终端B 命令总流程对比:
1-2-3:演示:可重复读(解决不可重复读问题,但出现幻读问题)
注意:终端A 和 终端B 就是打开两个命令行窗口,同时登录 3306 这个端口号的 MySQL 服务器而已。
演示之前,都会把数据恢复成最开始的数据。
第一步:
打开终端A,登录 MySQL , 将当前终端的事务隔离级别设置为 repeatable read,也就是【可重复读】。开启事务并查询 account 数据表中的数据。如下所示:
打开一个命令行窗口,作为终端A,登录 MySQL 服务器。
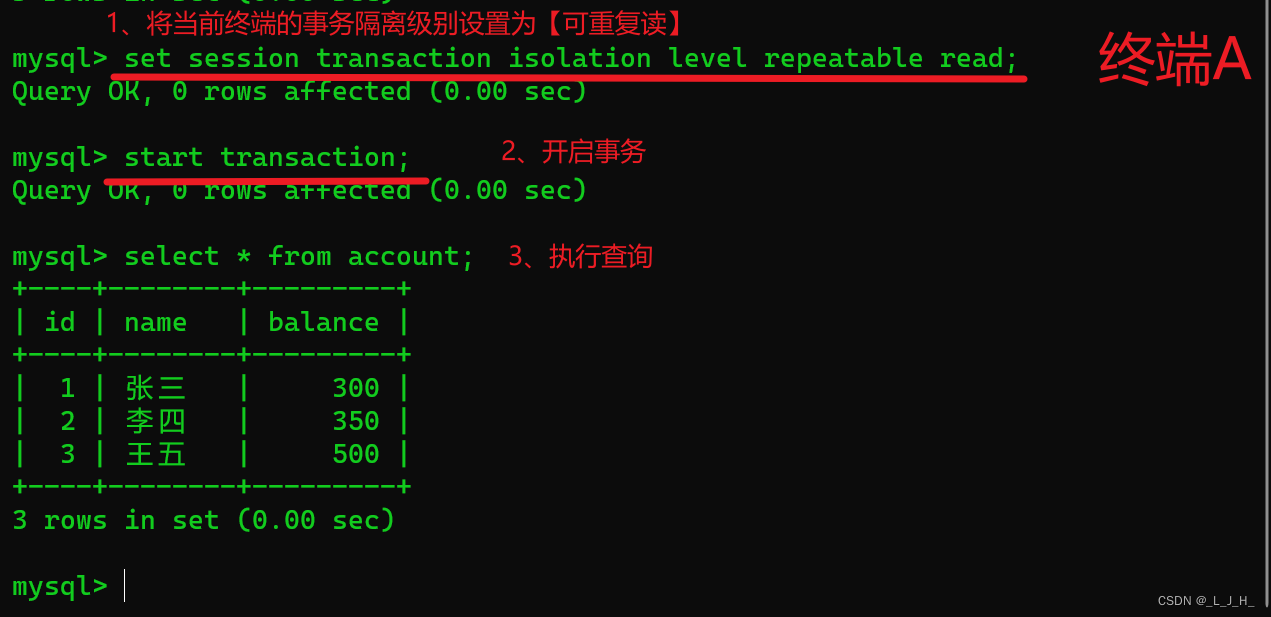
此时可以看到几个人的账户余额。
# 使用 test 数据库
use test;
# 将当前终端的事务隔离级别设置为 repeatable read,也就是【可重复读】
set session transaction isolation level repeatable read;
# 开启事务
start transaction;
# 执行查询
select * from account;
第二步:
在终端A 的事务提交之前,打开终端B,登录 MySQL ,将当前终端的事务隔离级别设置为【可重复读】。开启事务,将张三的账户余额 +100 元,随后提交事务,如下所示:
打开一个命令行窗口,作为终端B,登录 MySQL 服务器。
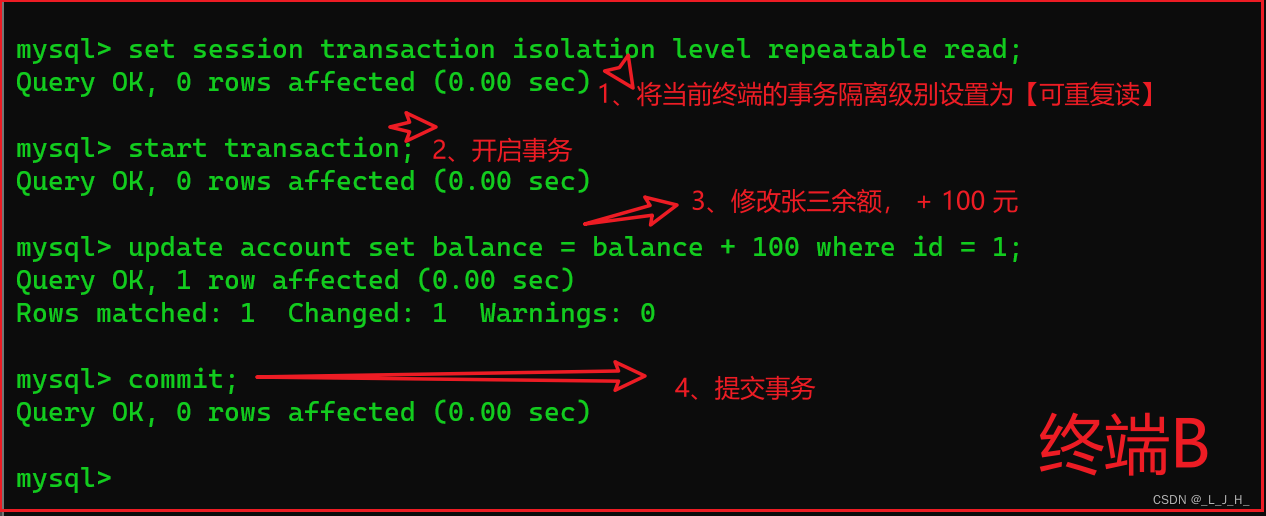
# 使用 test 数据库
use test;
# 将当前终端的事务隔离级别设置为 repeatable read,也就是【可重复读】
set session transaction isolation level repeatable read;
# 开启事务
start transaction;
# 修改张三的余额, + 100 元。
update account set balance = balance + 100 where id = 1;
# 提交事务
commit;
接下来,继续在终端B查询 account 数据表中的数据,如下所示:
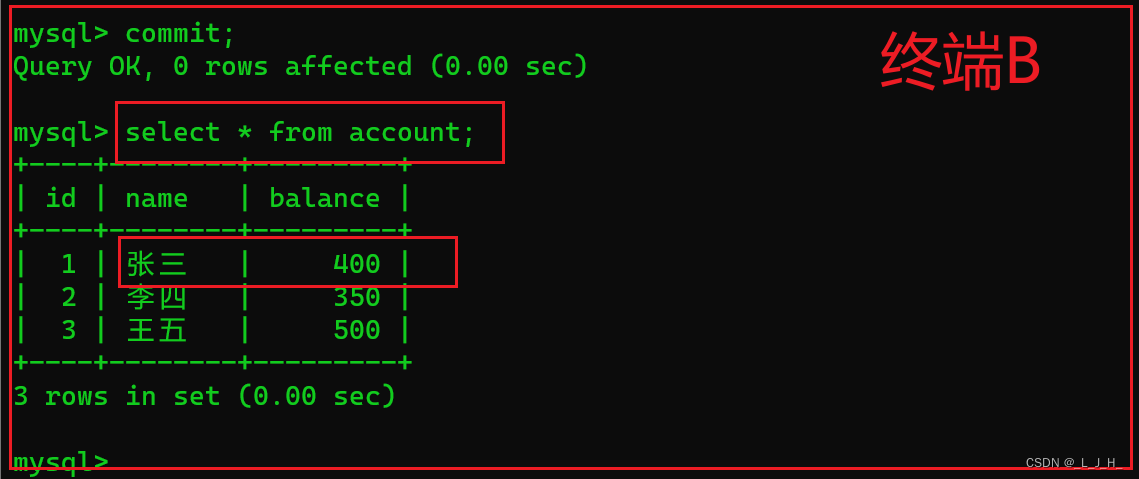
可以看到,在终端B的查询结果中,张三的账户余额已经由原来的 300 元 变成 400 元。
第三步:
在终端A 查询 account 数据表中的数据,如下所示:

可以看到,在终端A 查询的结果中,张三的账户余额仍然为 300 元,并没有出现【不可重复读】的问题,说明可重复读的事务隔离级别解决了不可重复读的问题。
因为此时终端A是设置了【可重复读】的事务隔离级别,而且此时 终端A 的事务还没有提交,所以此时的两次查询都是在同一个事务里面执行的,所以用相同的查询条件,多次查询的结果都是一致的。所以无论终端B怎么修改张三的数据,终端A这边只要还在这个事务内,无论这个查询执行多少次,都是 300 元。
第四步:
在终端A 为张三的账户 + 100 元,如下所示:

# 张三余额 +100
update account set balance = balance + 100 where id = 1;
接下来,在终端A查询 account 数据表中的数据,如下所示:
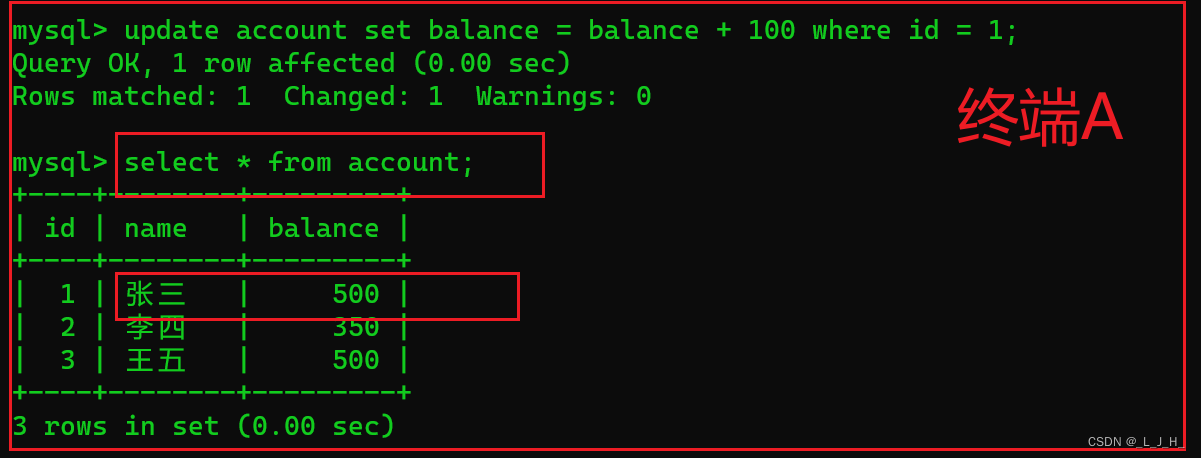
可以看到,查询的时候余额还是300元,执行 +100 元的修改语句后,此时张三的余额竟然变成了 500 元,而不是 400 元,数据的一致性没有遭到破坏。这是因为在终端A 为张三的账户 +100 元之前,终端B 已经为张三的账户余额增加了 100 元,共计增加了 200 元,所以最终张三的账户余额是 500 元,是正确的。
数据的一致性: 就是指在分布式系统中,所有副本的数据在任何时刻都保持相同的状态。换句话说,当数据在一个副本上发生变化时,其他副本也会相应地进行更新,以保持数据的一致性
可重复读的隔离级别使用了 MVCC(Multi-Version Concurrency Control,多版本并发控制)机制,数据库中的查询(select)操作不会更新版本号,是快照读,而操作数据表中的数据(insert、update、delete)则会更新版本号,是当前读。
第五步:演示:出现幻读
在 终端B 开启事务,插入一条数据后提交事务,如下所示:
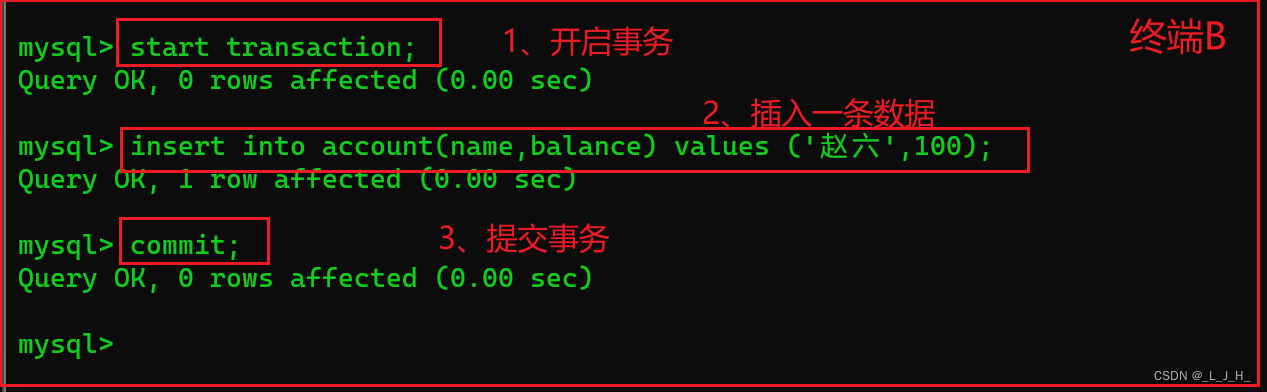
继续在 终端B 查询 account 数据表中的数据,如下所示:
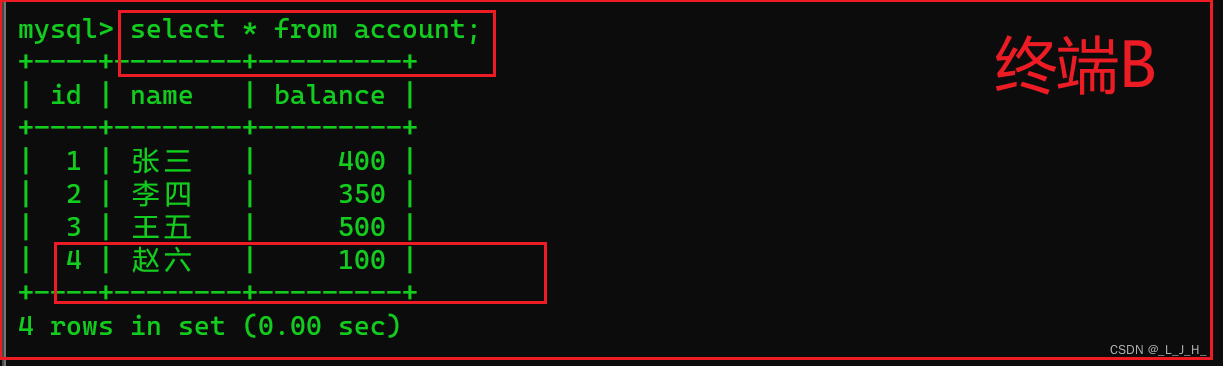
可以看到,在 终端B 查询的结果中,已经显示出新插入的赵六的账户信息了。
# 开启事务
start transaction;
# 执行一条插入语句
insert into account(name,balance) values ('赵六',100);
#提交事务
commit;
# 执行查询
select * from account;
第六步:
在 终端A 查询 account 数据表中的数据,如下所示:
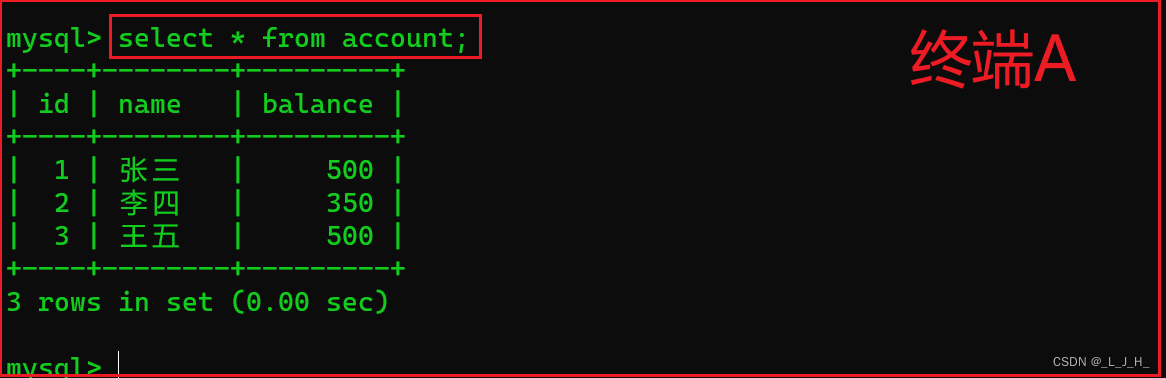
可以看到,在 终端A 查询的数据中,并没有出现赵六的账户信息,注意,此时的 终端A 一直都是处在最开始的那个事务中,还没有提交过。
而在同一个事务内,多次读取一个范围的数据记录,读到的结果都是相同的,说明没有出现【幻读】的情况。
【幻读:就是一个事务两次读取一个范围的数据记录,两次读取到的结果不同】
第七步:
在 终端A 为赵六的账户 +100 元,如下所示:
修改赵六余额的 SQL 语句执行成功。接下来,也是在终端A 查询 account 数据表中的数据:

可以看到,在 终端A 执行完数据更新操作之前是查不到赵六的信息的,
而在 终端A 执行完数据更新操作后,突然就能查询到赵六的账户信息了,这就出现了【幻读】的问题。
注意:这整个演示中,终端A 都是处在同一个事务内的。
要解决幻读问题,得使用串行化的事务隔离级别或者间隙锁和临键锁。
1-2-4:串行化(解决幻读等所有并发问题)
演示之前,都会把数据恢复成最开始的数据。
第一步:
打开 终端A ,登录 MySQL , 将当前终端的事务隔离级别设置为 serializable,也就是串行化,然后开启事务,再查询 account 数据表中 id = 1 的数据,如下所示:
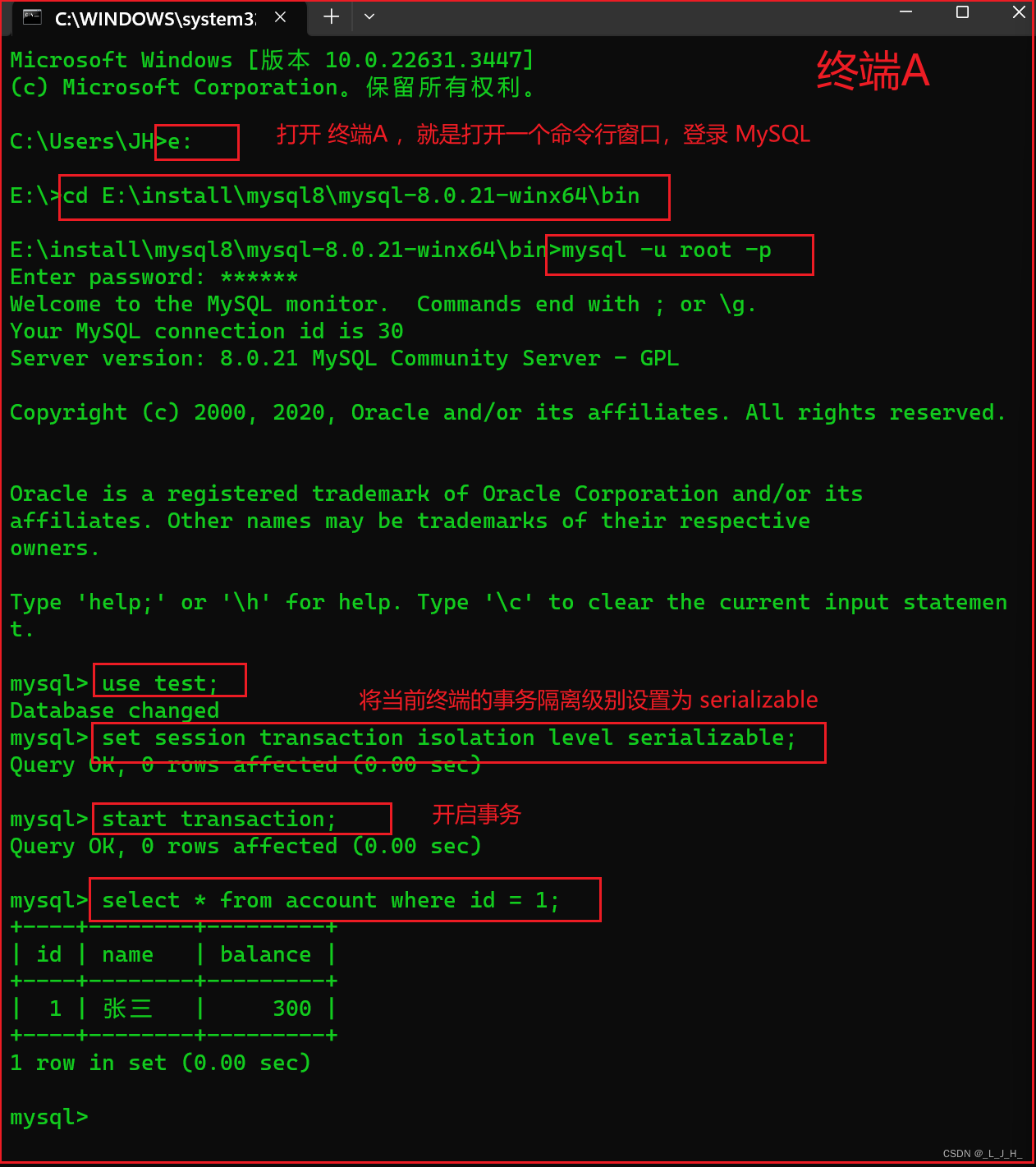
# 打开 终端A (就是打开一个命令行窗口),登录 MySQL
e:
cd E:\install\mysql8\mysql-8.0.21-winx64\bin
mysql -u root -p
密码:123456
# 使用这个test数据库
use test;
# 将当前终端的事务隔离级别设置为 serializable,也就是串行化
set session transaction isolation level serializable;
# 开启事务
start transaction;
# 查询 account 数据表中 id = 1 的数据
select * from account where id = 1;
第二步:
打开终端B,登录 MySQL ,将当前终端的事务隔离级别设置为 serializable 串行化,修改 account 数据表中 id = 1 的数据,如下所示:
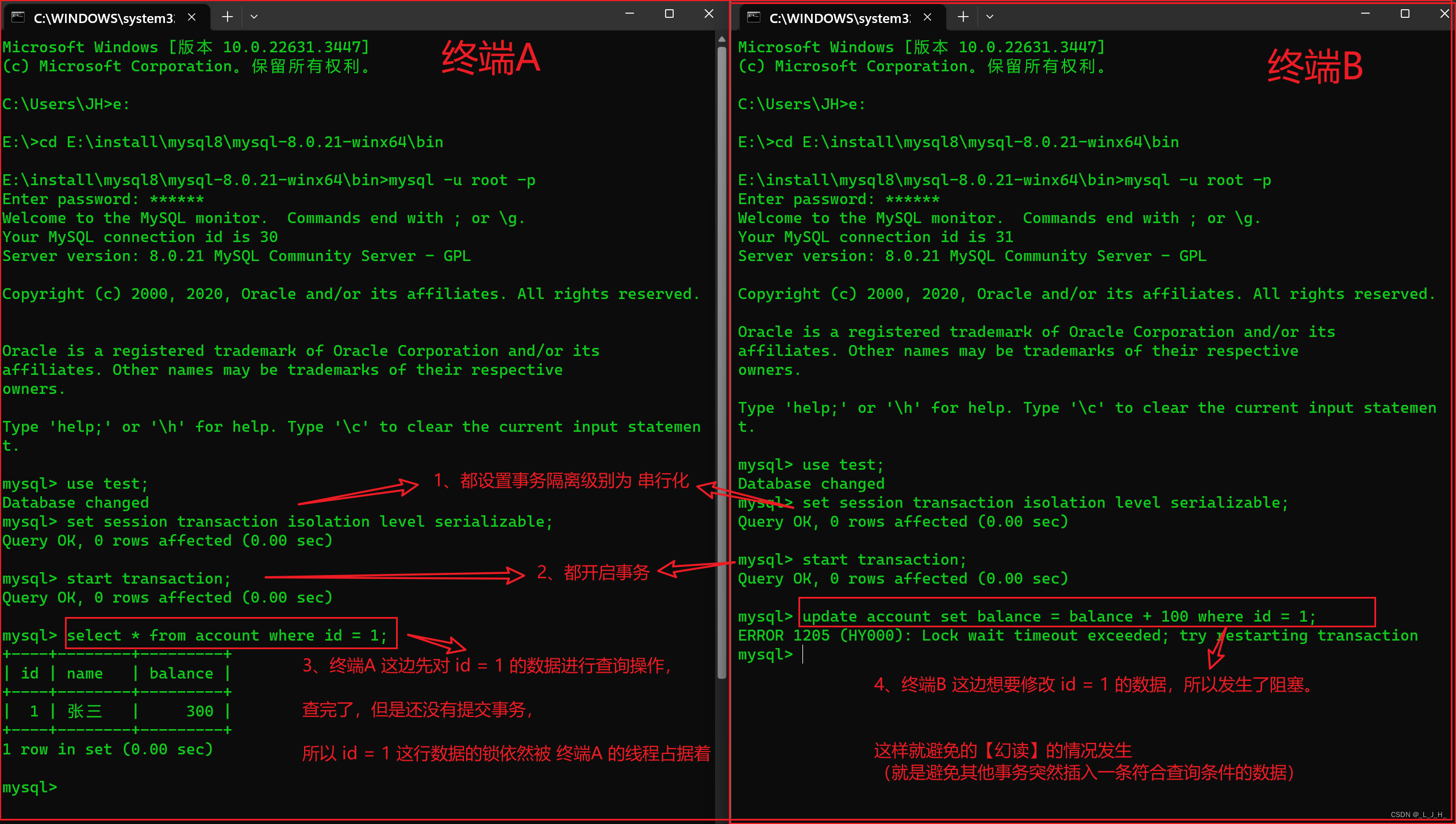
可以看到,在 终端B 中对 account 数据表中 id = 1 的数据执行更新操作时,会发生阻塞,锁超时后会抛出【ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction】异常,这就避免了幻读。
# 将当前终端的事务隔离级别设置为 serializable,也就是串行化
set session transaction isolation level serializable;
# 开启事务
start transaction;
# 终端B 修改 id = 1 的数据
update account set balance = balance + 100 where id = 1;
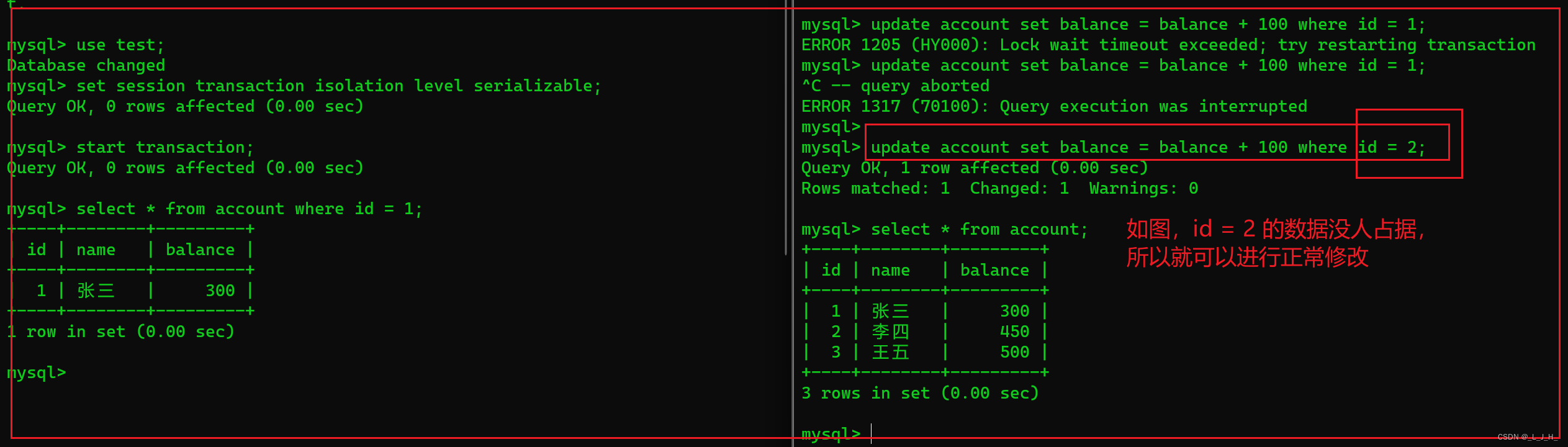
因为当 id = 1 的数据被终端A占据着,那么终端B就不能对其进行修改操作,只能等终端A事务提交后才可以。
简单来说,就是 id = 1 这行数据被终端A 的线程占据了,要等其事务执行完后,释放锁,其他线程才能够操作该条数据。
如果终端B只是查询,是没有影响的,修改就不行,如图:
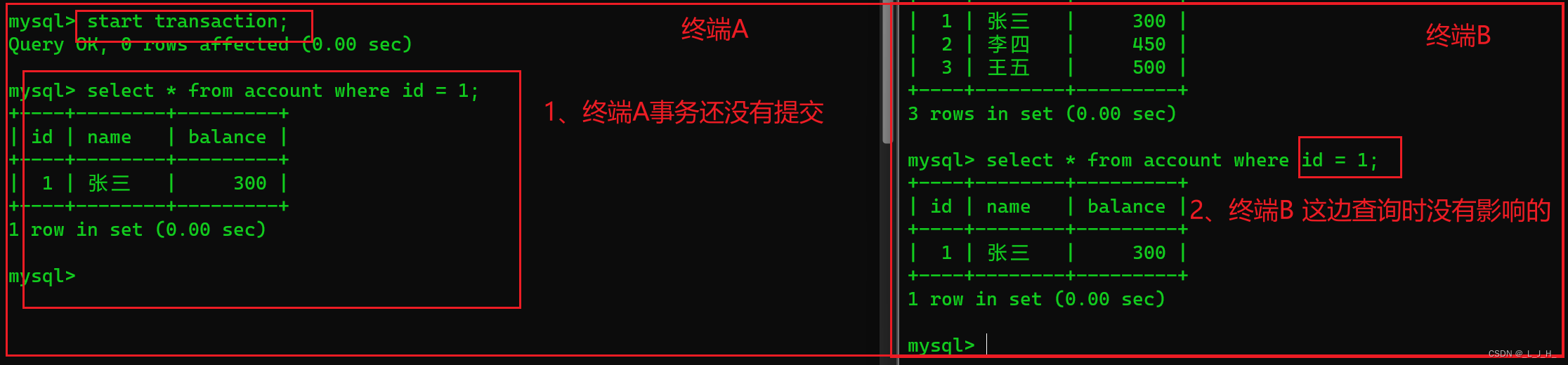
如图:id = 1 这行数据还在终端A 的事务内操作着,终端B 无法对该数据执行更改操作,但是更改其他行数据就没有任何影响,比如更改 id = 2 的数据就没有影响。
演示串行化级别下进行范围查询的实例:
另外,在串行化的事务隔离级别下,如果终端A 执行的是一个范围查询,那么该范围内的所有行(包括每行记录所在的间隙区间范围,如果某行记录还未被插入数据,这行记录也会被加锁,这是一种间隙锁)都会被加锁。
此时 终端B 在此范围内插入数据,就会被阻塞,从而避免幻读,如下所示:
除了 start transaction; 可以开启事务外,begin 也可以,如下所示:
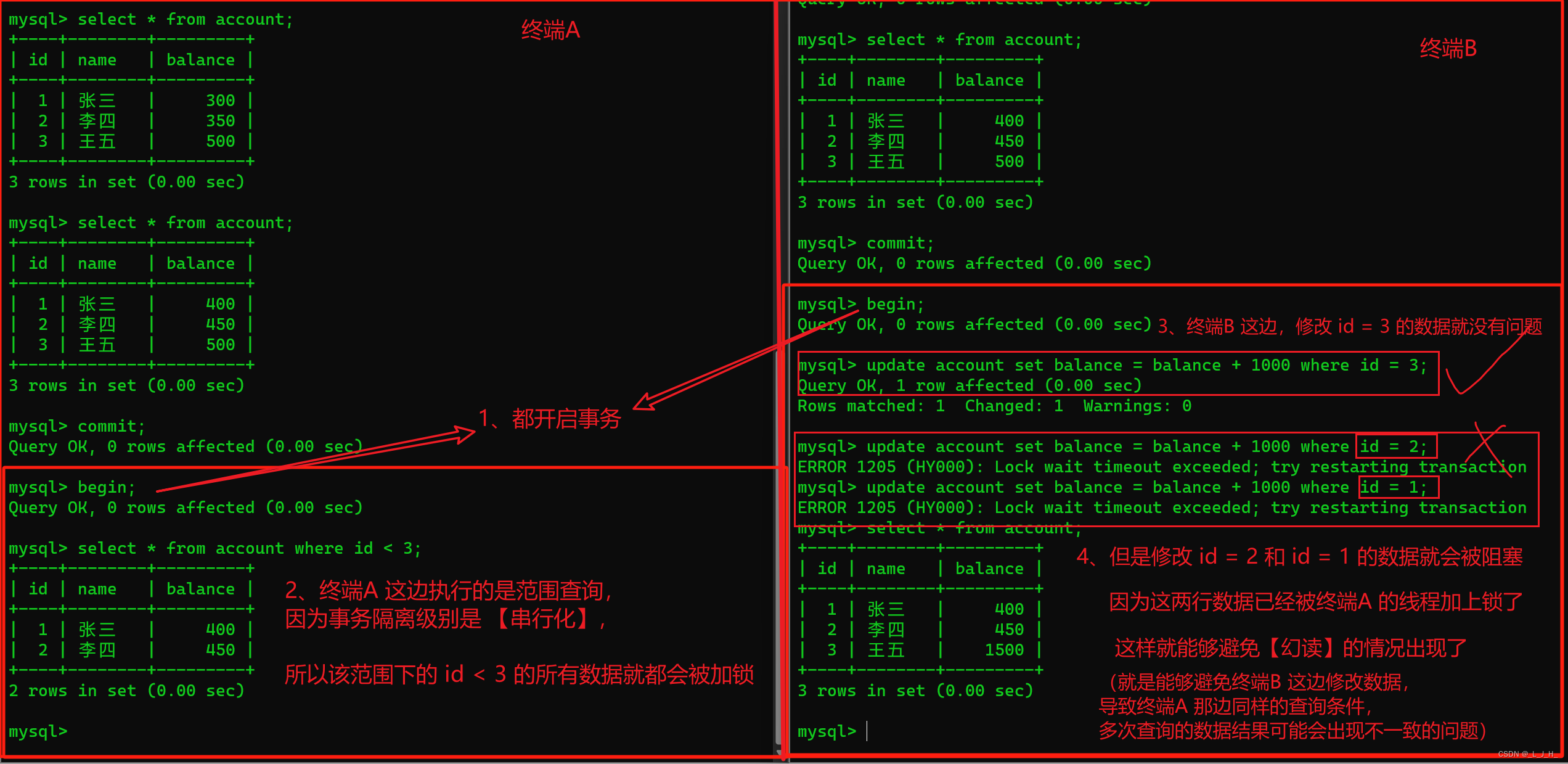
可以看到,终端A 这边的事务执行了一个 id < 3 的范围查询, 那么这个范围的数据,在【串行化】的事务隔离级别下,就都会被加锁。
因此,终端B 这边,在 终端A 的事务还没结束前,是无法对 id < 3 的这个范围的数据进行修改或删除操作的。
# 开启事务
begin;
# 修改数据
update account set balance = balance + 1000 where id = 3;