Hive 是一个建立在 Hadoop 上的数据仓库基础架构,它提供了类似于 SQL 的查询语言,称为 HiveQL,用于对存储在 Hadoop 分布式文件系统中的数据进行查询和分析。
1.函数简介
Hive会将常用的逻辑封装成函数给用户进行使用,类似于Java中的方法。
- 好处:避免用户反复写逻辑,可以直接拿来使用。
- 重点:用户需要知道函数叫什么,能做什么。
Hive提供了大量的内置函数,按照其特点可大致分为如下几类:单行函数、聚合函数、炸裂函数、窗口函数。
以下命令可用于查询所有内置函数的相关信息。
1)查看系统内置函数
hive> show functions;

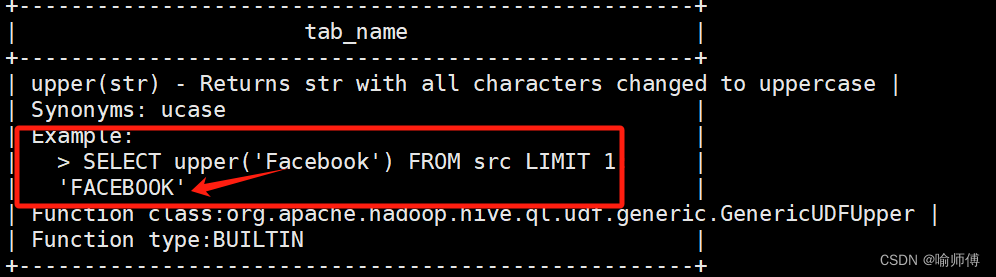
2)查看内置函数用法
hive> desc function upper;

3)查看内置函数详细信息
hive> desc function extended upper;
2.单行函数
- 单行函数的特点是一进一出,即输入一行,输出一行。
- 单行函数按照功能可分为如下几类: 日期函数、字符串函数、集合函数、数学函数、流程控制函数等。
1.算术运算函数
查询出所有员工的薪水后加1显示:
hive (default)> select sal + 1 from emp;
2.数值函数
数值函数是用于对数值数据进行操作和计算的函数,在 SQL 查询中经常用于执行数学运算、取值范围限制等操作。
-
ABS(x):返回 x 的绝对值。
-
ROUND(x, d):将 x 四舍五入到 d 位小数。如果 d 被省略,则默认为 0。
hive> select round(3.3); 3
- CEIL(x):返回不小于 x 的最小整数,向上取整。
hive> select ceil(3.1) ; 4
- FLOOR(x):返回不大于 x 的最大整数,向下取整。
hive> select floor(4.8); 4
-
SQRT(x):返回 x 的平方根。
-
POWER(x, y):返回 x 的 y 次幂。
-
EXP(x):返回 e 的 x 次幂,其中 e 是自然对数的底。
-
LOG(x):返回 x 的自然对数。
-
LOG10(x):返回 x 的以 10 为底的对数。
-
MOD(x, y):返回 x 除以 y 的余数。
-
SIGN(x):返回 x 的符号:1 表示正数,-1 表示负数,0 表示零。
-
RAND():返回一个随机浮点数值,范围在 0 到 1 之间。
示例:
-- 返回 -5 的绝对值
SELECT ABS(-5); -- 输出: 5
-- 将 4.8 四舍五入到最近的整数
SELECT ROUND(4.8); -- 输出: 5
-- 返回不小于 4.8 的最小整数
SELECT CEIL(4.8); -- 输出: 5
-- 返回不大于 4.8 的最大整数
SELECT FLOOR(4.8); -- 输出: 4
-- 返回 25 的平方根
SELECT SQRT(25); -- 输出: 5
-- 返回 2 的 3 次幂
SELECT POWER(2, 3); -- 输出: 8
-- 返回 e 的 2 次幂
SELECT EXP(2); -- 输出: 约为 7.389
-- 返回 100 的自然对数
SELECT LOG(100); -- 输出: 约为 4.605
-- 返回 100 的以 10 为底的对数
SELECT LOG10(100); -- 输出: 2
-- 返回 10 除以 3 的余数
SELECT MOD(10, 3); -- 输出: 1
-- 返回 -5 的符号:-1 表示负数
SELECT SIGN(-5); -- 输出: -1
-- 返回一个范围在 0 到 1 之间的随机浮点数
SELECT RAND(); -- 输出: 0.xxxx (实际结果会变化)
3.字符串函数
concat(str1, str2, …):连接字符串。-- 连接 'hello' 和 'world' SELECT concat('hello', ' ', 'world'); -- 输出: 'hello world'
-
语法:concat(string A, string B, string C, ……)
-
返回:string
-
说明:将A,B,C……等字符拼接为一个字符串
hive> select concat('beijing','-','shanghai','-','shenzhen'); 输出: hive> beijing-shanghai-shenzhen
-
upper(str):将字符串转换为大写。-- 将 'hello' 转换为大写 SELECT upper('hello'); -- 输出: 'HELLO' -
lower(str):将字符串转换为小写。-- 将 'WORLD' 转换为小写 SELECT lower('WORLD'); -- 输出: 'world' -
length(str):返回字符串的长度。-- 返回字符串 'hello world' 的长度 SELECT length('hello world'); -- 输出: 11 -
substr(str, start, length):提取子串。-- 提取字符串 'hello world' 的前 5 个字符 SELECT substr('hello world', 1, 5); -- 输出: 'hello'获取倒数第三个字符以后的所有字符
select substring("yushifu",-3); ifu -
replace(str, from_str, to_str):替换字符串中的子串。-- 将字符串 'hello world' 中的 'hello' 替换为 'hi' SELECT replace('hello world', 'hello', 'hi'); -- 输出: 'hi world' -
trim([BOTH | LEADING | TRAILING] trim_str FROM str):去除字符串两侧或指定位置的空格或指定字符。-- 去除字符串 ' hello world ' 两侧的空格 SELECT trim(' hello world '); -- 输出: 'hello world' -- 去除字符串 'xxxhello worldxxx' 两侧的 'x' SELECT trim('x' FROM 'xxxhello worldxxx'); -- 输出: 'hello world' -
ltrim(str):去除字符串左侧的空格。-- 去除字符串 ' hello' 左侧的空格 SELECT ltrim(' hello'); -- 输出: 'hello' -
rtrim(str):去除字符串右侧的空格。-- 去除字符串 'world ' 右侧的空格 SELECT rtrim('world '); -- 输出: 'world' -
regexp_replace函数用于使用正则表达式替换字符串中的匹配项。-- 使用正则表达式替换字符串中的数字为 'X' SELECT regexp_replace('Hello 123 World 456', '\\d+', 'X'); -- 输出: 'Hello X World X''\\d+'是一个正则表达式,用于匹配一个或多个数字。'X'是替换字符串。所以,regexp_replace函数将字符串中的所有数字替换为'X'。
11.repeat:重复字符串
- 语法:repeat(string A, int n)
- 返回值:string
- 说明:将字符串A重复n遍。
hive> select repeat('123', 3);
输出:
hive> 123123123
12.split :字符串切割
- 语法:split(string str, string pat)
- 返回值:array
- 说明:按照正则表达式pat匹配到的内容分割str,分割后的字符串,以数组的形式返回。
hive> select split('a-b-c-d','-');
输出:
hive> ["a","b","c","d"]
13.nvl :替换null值
语法:nvl(A,B)
说明:若A的值不为null,则返回A,否则返回B。
hive> select nvl(null,1);
输出:
hive> 1
14.concat_ws:以指定分隔符拼接字符串或者字符串数组
- 语法:concat_ws(string A, string…| array(string))
- 返回值:string
- 说明:使用分隔符A拼接多个字符串,或者一个数组的所有元素。
hive>select concat_ws('-','beijing','shanghai','shenzhen');
输出:
hive> beijing-shanghai-shenzhen
hive> select concat_ws('-',array('beijing','shenzhen','shanghai'));
输出:
hive> beijing-shanghai-shenzhen
15.get_json_object:解析json字符串
- 语法:get_json_object(string json_string, string path)
- 返回值:string
- 说明:解析json的字符串json_string,返回path指定的内容。如果输入的json字符串无效,那么返回NULL。

(1)获取json数组里面的json具体数据
hive> select get_json_object('[{"name":"yushifu","sex":"男","age":"24"},{"name":"彭于晏","sex":"男","age":"47"}]','$.[0].name');
输出:
hive> yushifu
(2)获取json数组里面的数据
hive> select get_json_object('[{"name":"yushifu","sex":"男","age":"24"},{"name":"彭于晏","sex":"男","age":"47"}]','$.[0].name');
输出:
hive> {"name":"yushifu","sex":"男","age":"24"}
4.日期函数
1.unix_timestamp:返回当前或指定时间的时间戳
- 语法:unix_timestamp()
- 返回值:bigint
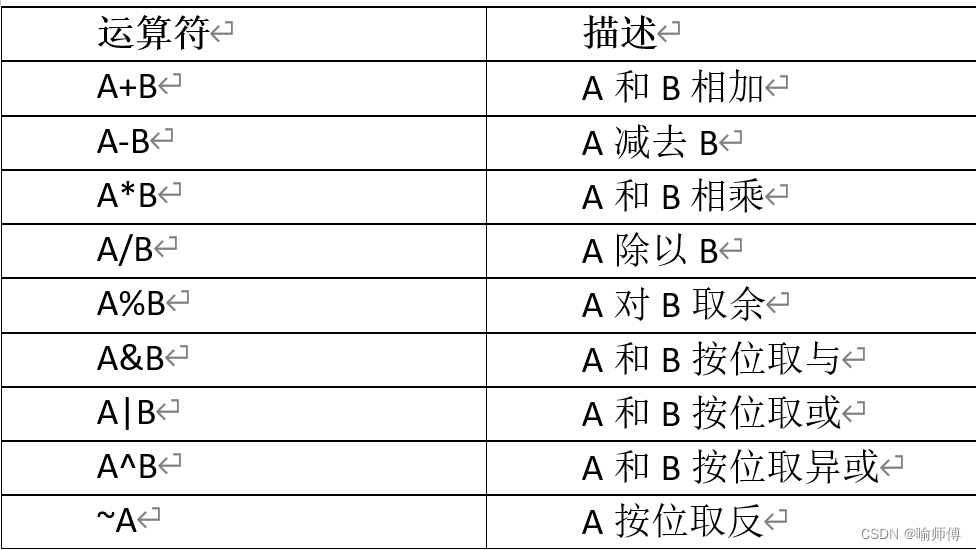
hive> select unix_timestamp('2024/04/25 09-19-08','yyyy/MM/dd HH-mm-ss');
输出:
1714036748
说明:前面是日期后面是指日期传进来的具体格式
2.from_unixtime:转化UNIX时间戳(从 1970-01-01 00:00:00 UTC 到指定时间的秒数)到当前时区的时间格式
- 语法:from_unixtime(bigint unixtime[, string format])
- 返回值:string
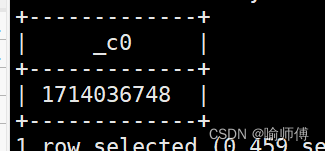
hive> select from_unixtime(1714036748);
输出:
2024-04-25 09:19:08
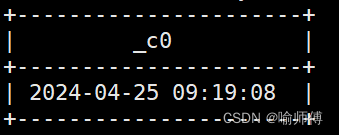
3.current_date:当前日期
hive> select current_date;
输出:
2024-04-25
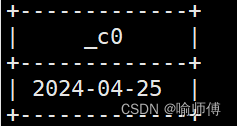
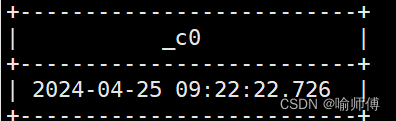
4.current_timestamp:当前的日期加时间,并且精确的毫秒
hive> select current_timestamp;
输出:
2024-04-25 09:22:22.726
5.month:获取日期中的月
- 语法:month (string date)
- 返回值:int
hive> select month('2024-04-25 09:19:08');
输出:
4
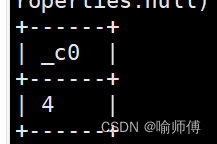
6.day:获取日期中的日
- 语法:day (string date)
- 返回值:int
hive> select day('2024-04-25 09:19:08');
输出:
25
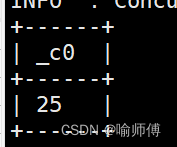
7.hour:获取日期中的小时
- 语法:hour (string date)
- 返回值:int
hive> select hour('2024-04-25 09:19:08');
输出:
9

8)datediff:两个日期相差的天数(结束日期减去开始日期的天数)
- 语法:datediff(string enddate, string startdate)
- 返回值:int
hive> select datediff('2021-08-08','2022-10-09');
输出:
-427
9.date_add:日期加天数
- 语法:date_add(string startdate, int days)
- 返回值:string
- 说明:返回开始日期 startdate 增加 days 天后的日期
hive> select date_add('2022-08-08',2);
输出:
2022-08-10
10.date_sub:日期减天数
- 语法:date_sub (string startdate, int days)
- 返回值:string
- 说明:返回开始日期startdate减少days天后的日期。
hive> select date_sub('2022-08-08',2);
输出:
2022-08-06
11.date_format:将标准日期解析成指定格式字符串
hive> select date_format('2022-08-08','yyyy年-MM月-dd日')
输出:
2022年-08月-08日
5.流程控制函数
1. case when:条件判断函数
- 语法一:case when a then b [when c then d]* [else e] end
- 返回值:T
- 说明:如果a为true,则返回b;如果c为true,则返回d;否则返回 e
hive> select case when 1=2 then 'tom' when 2=2 then 'mary' else 'tim' end ;
mary
- 语法二: case a when b then c [when d then e]* [else f] end
- 返回值: T
- 说明:如果a等于b,那么返回c;如果a等于d,那么返回e;否则返回f
hive> select case 100 when 50 then 'tom' when 100 then 'mary' else 'tim' end;
mary
求出不同部门男女各多少人
emp_sex 表:
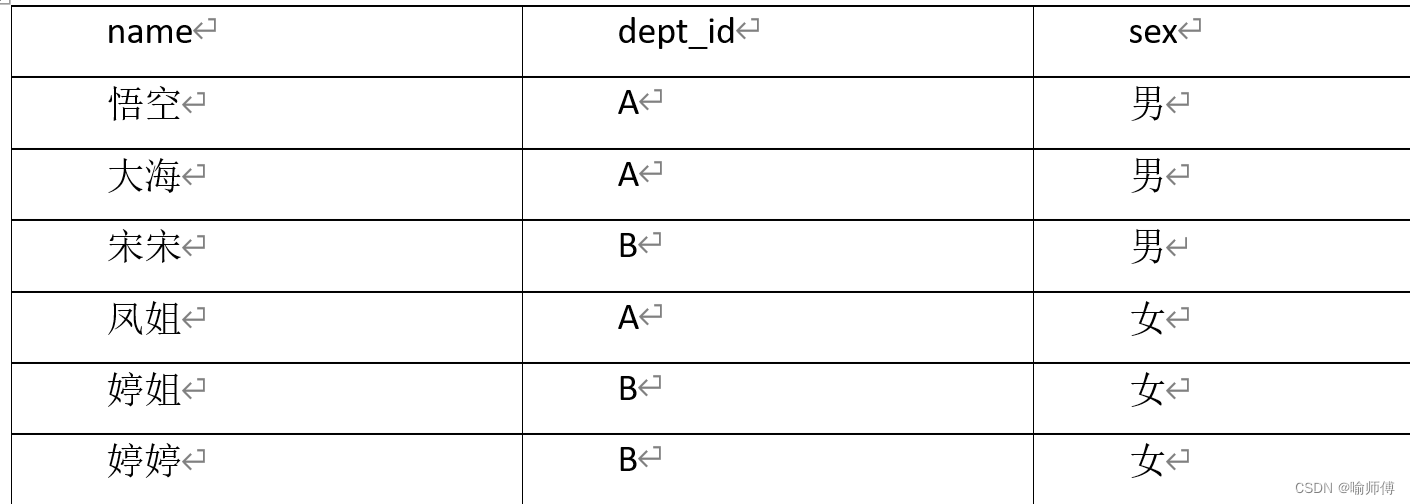
hive (default)>
select
dept_id,
sum(case sex when '男' then 1 else 0 end) male_count,
sum(case sex when '女' then 1 else 0 end) female_count
from emp_sex
group by dept_id;


2. if: 条件判断,类似于Java中三元运算符
- 语法:if(boolean testCondition, T valueTrue, T valueFalseOrNull)
- 返回值:T
- 说明:当条件testCondition为true时,返回valueTrue;否则返回valueFalseOrNull
(1)条件满足,输出正确
hive> select if(10 > 5,'正确','错误');
输出:正确
(2)条件满足,输出错误
hive> select if(10 < 5,'正确','错误');
输出:错误
6.集合函数
1.size:集合中元素的个数
hive> select size(friends) from test;
--2/2 每一行数据中的friends集合里的个数
2.map:创建map集合
- 语法:map (key1, value1, key2, value2, …)
- 说明:根据输入的key和value对构建map类型
hive> select map('uzi',1,'xiaohu',2);
输出:
hive> {"uzi":1,"xiaohu":2}
3.map_keys: 返回map中的key
hive> select map_keys(map('uzi',1,'xiaohu',2));
输出:
hive>["uzi","xiaohu"]
4.map_values: 返回map中的value
hive> select map_values(map('uzi',1,'xiaohu',2));
输出:
hive>[1,2]
5.array:声明array集合
- 语法:array(val1, val2, …)
- 说明:根据输入的参数构建数组array类
hive> select array('1','2','3','4');
输出:
hive>["1","2","3","4"]
6.array_contains: 判断array中是否包含某个元素
hive> select array_contains(array('a','b','c','d'),'a');
输出:
hive> true
7.sort_array:将array中的元素排序
hive> select sort_array(array('a','d','c'));
输出:
hive> ["a","c","d"]
8.struct:声明struct中的各属性
语法:struct(val1, val2, val3, …)
说明:根据输入的参数构建结构体struct类
hive> select struct('name','age','weight');
输出:
hive> {"col1":"name","col2":"age","col3":"weight"}
9.named_struct:声明struct的属性和值
hive> select named_struct('name','uzi','age',18,'weight',80);
输出:
hive> {"name":"uzi","age":18,"weight":80}
3. 高级聚合函数
多进一出 (多行传入,一个行输出)。
-
count(distinct expr[, expr…]):
- 计算唯一值的数量。可以对一个或多个列应用,用逗号分隔。
- 示例:
select count(distinct user_id) from table;
-
collect_set(expr):
- 返回一个包含唯一值的集合,不保证顺序(去重,无序)。
- 示例:
select collect_set(city) from users group by country;
hive>
select
sex,
collect_set(job)
from
employee
group by
sex
- collect_list(expr):
- 返回一个包含所有值的列表,可能包含重复值,保留输入顺序(不去重,有序)。
- 示例:
select collect_list(product_name) from sales group by order_id;

每个月的入职人数以及姓名
hive>
select
month(replace(hiredate,'/','-')) as month,
count(*) as cn,
Collect_list(name) as name_list
from
employee
group by
month(replace(hiredate,'/','-'))
month cn name_list
4 2 ["宋青书","周芷若"]
6 1 ["黄蓉"]
7 1 ["郭靖"]
8 2 ["张无忌","杨过"]
9 2 ["赵敏","小龙女"]
-
grouping sets:
- 允许按不同的维度对数据进行聚合,生成多个分组的聚合结果。
- 示例:
select dept_id, gender, count(*) from employees group by grouping sets (dept_id, gender, ());
-
rollup:
- 在group by子句中使用rollup,可以生成层次化的聚合结果,从整体到部分的逐层汇总。
- 示例:
select dept_id, gender, count(*) from employees group by rollup (dept_id, gender);
-
cube:
- 类似于rollup,但是生成更多的组合,包括所有可能的组合。
- 示例:
select dept_id, gender, count(*) from employees group by cube (dept_id, gender);
-
percentile(expr, p):
- 计算表达式的百分位数,p是介于0和1之间的数字。
- 示例:
select percentile(salary, 0.75) from employee_salaries;
-
ntile(n):
- 将排序后的数据集分成n个大致相等的部分,并为每个行分配一个标识符。
- 示例:
select name, salary, ntile(4) over (order by salary) as quartile from employees;
4.炸裂函数
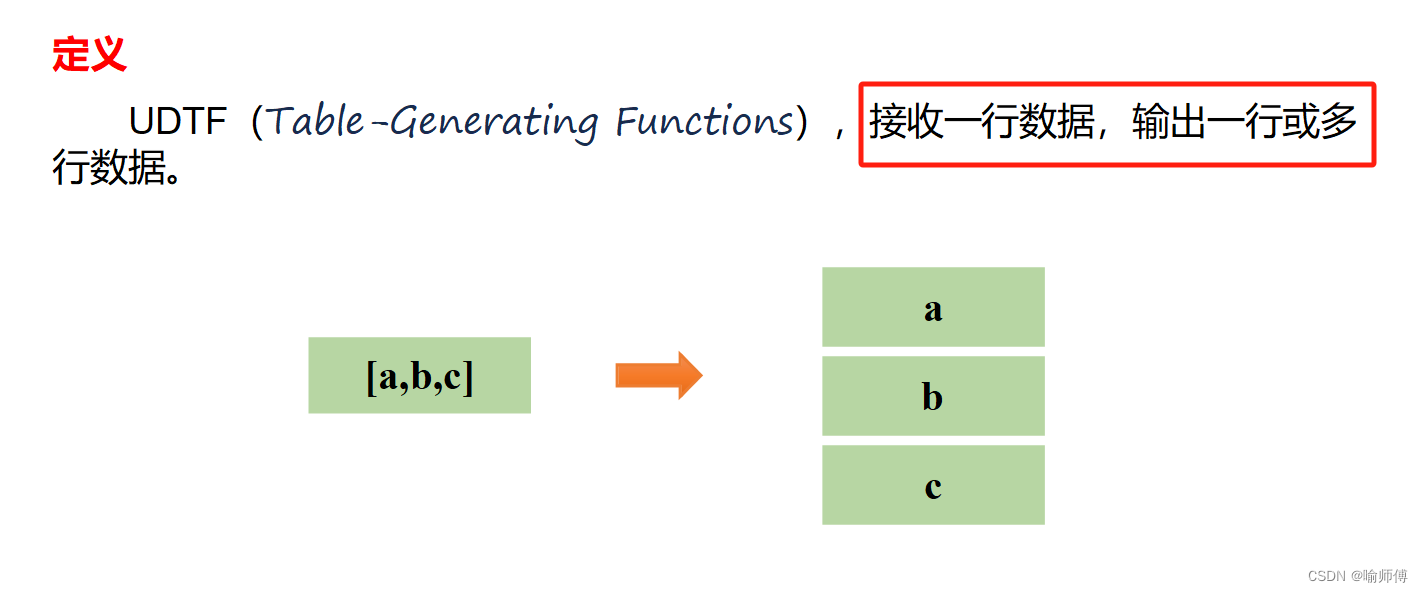
Hive中的炸裂函数通常用于将包含多个元素的字符串或数组拆分成单独的元素,并生成新的行。
-
explode():将数组拆分成单独的元素,并为每个元素生成新的行。
- 示例:
SELECT explode(array_column) AS single_element FROM table;
- 示例:
-
posexplode():类似于explode(),但同时返回元素的位置索引。
- 示例:
SELECT posexplode(array_column) AS (pos, single_element) FROM table;
- 示例:
示例:
+-------------+-------------------+
| student_id | grades |
+-------------+-------------------+
| 1 | ["Math: A", "Science: B", "History: A"] |
| 2 | ["Math: B", "Science: A", "History: C"] |
+-------------+-------------------+
使用explode()函数将grades数组拆分为单独的行
SELECT student_id, explode(grades) AS subject_grade
FROM student_grades;
+-------------+-------------------+
| student_id | subject_grade |
+-------------+-------------------+
| 1 | "Math: A" |
| 1 | "Science: B" |
| 1 | "History: A" |
| 2 | "Math: B" |
| 2 | "Science: A" |
| 2 | "History: C" |
+-------------+-------------------+
每个学生的每个科目成绩都变成了一行。
如果还想保留每个成绩的位置索引,可以使用posexplode()函数:
SELECT student_id, posexplode(grades) AS (pos, subject_grade)
FROM student_grades;
+-------------+------+-------------------+
| student_id | pos | subject_grade |
+-------------+------+-------------------+
| 1 | 0 | "Math: A" |
| 1 | 1 | "Science: B" |
| 1 | 2 | "History: A" |
| 2 | 0 | "Math: B" |
| 2 | 1 | "Science: A" |
| 2 | 2 | "History: C" |
+-------------+------+-------------------+
5.窗口函数(开窗函数)



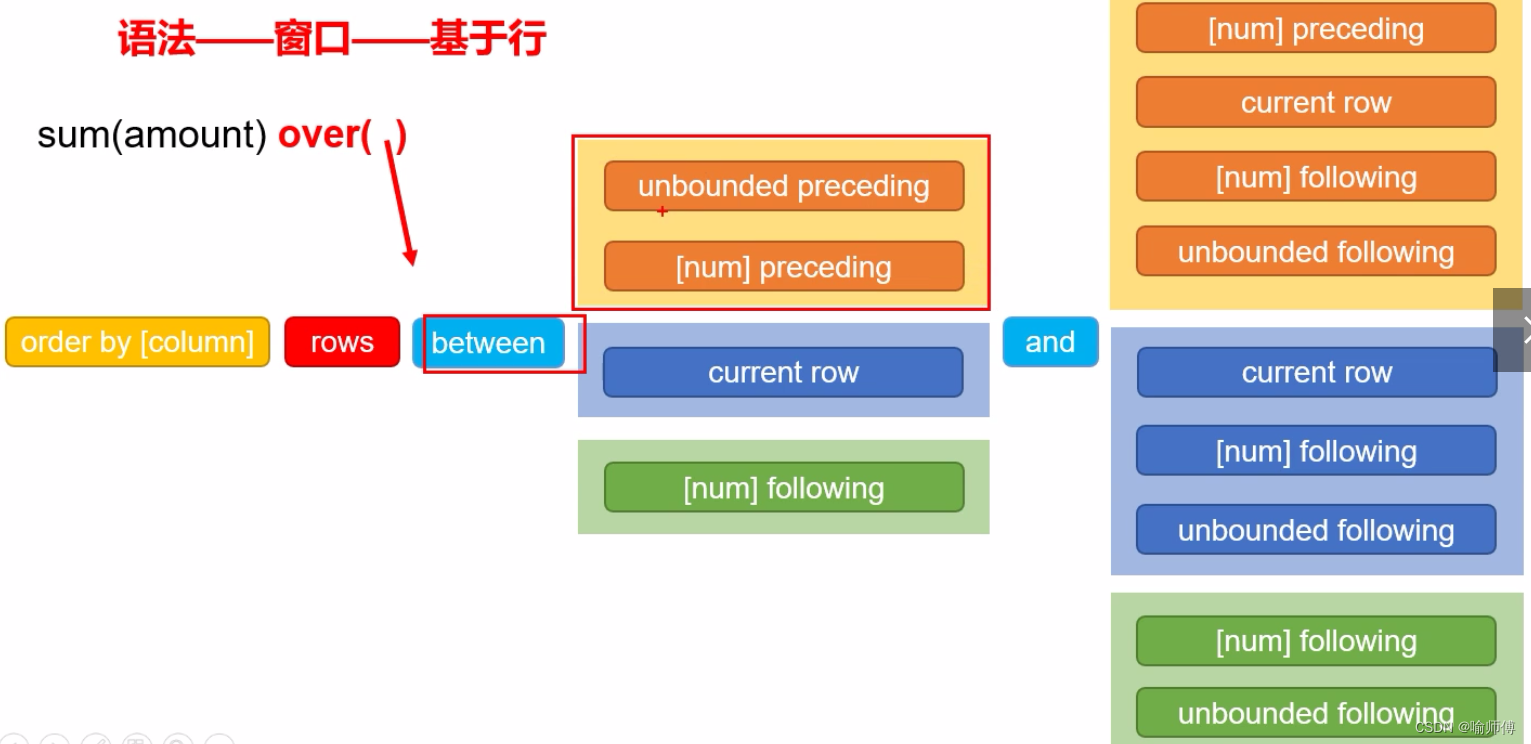
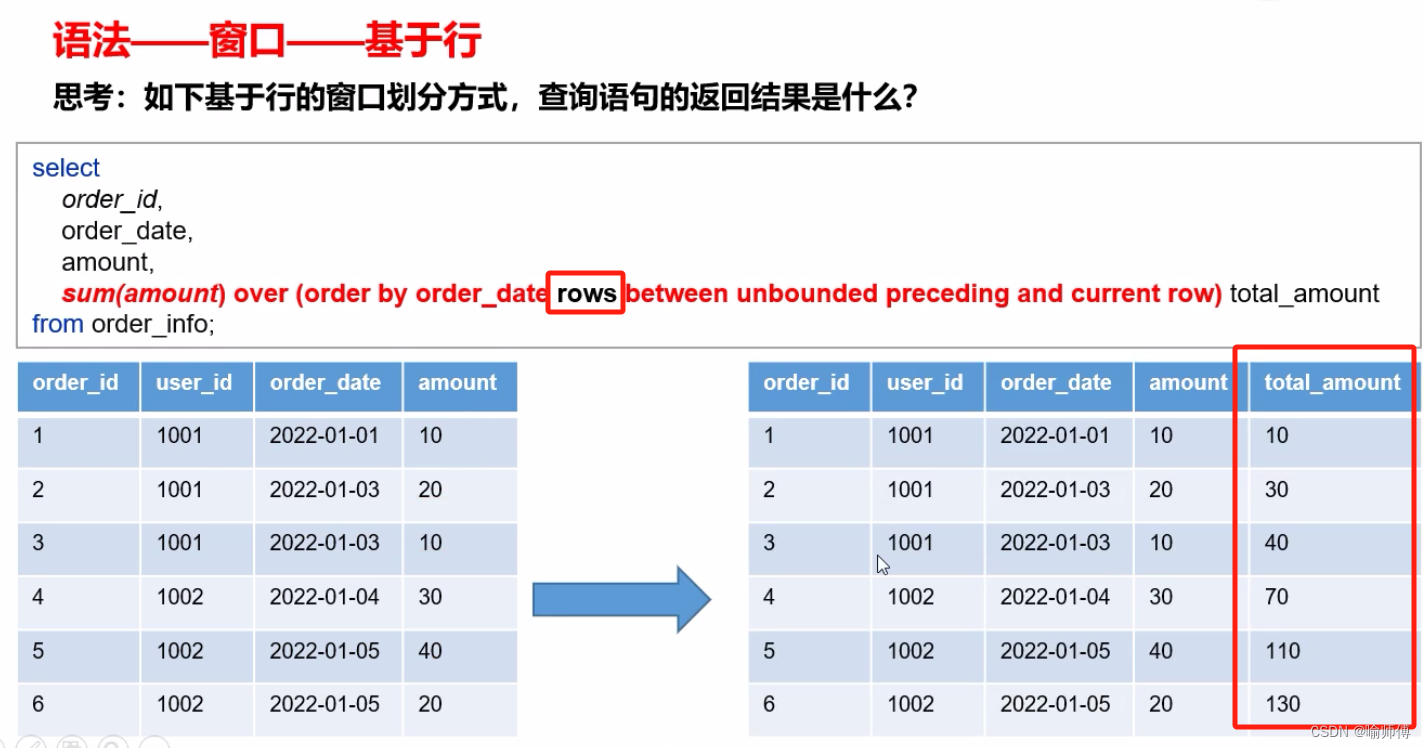
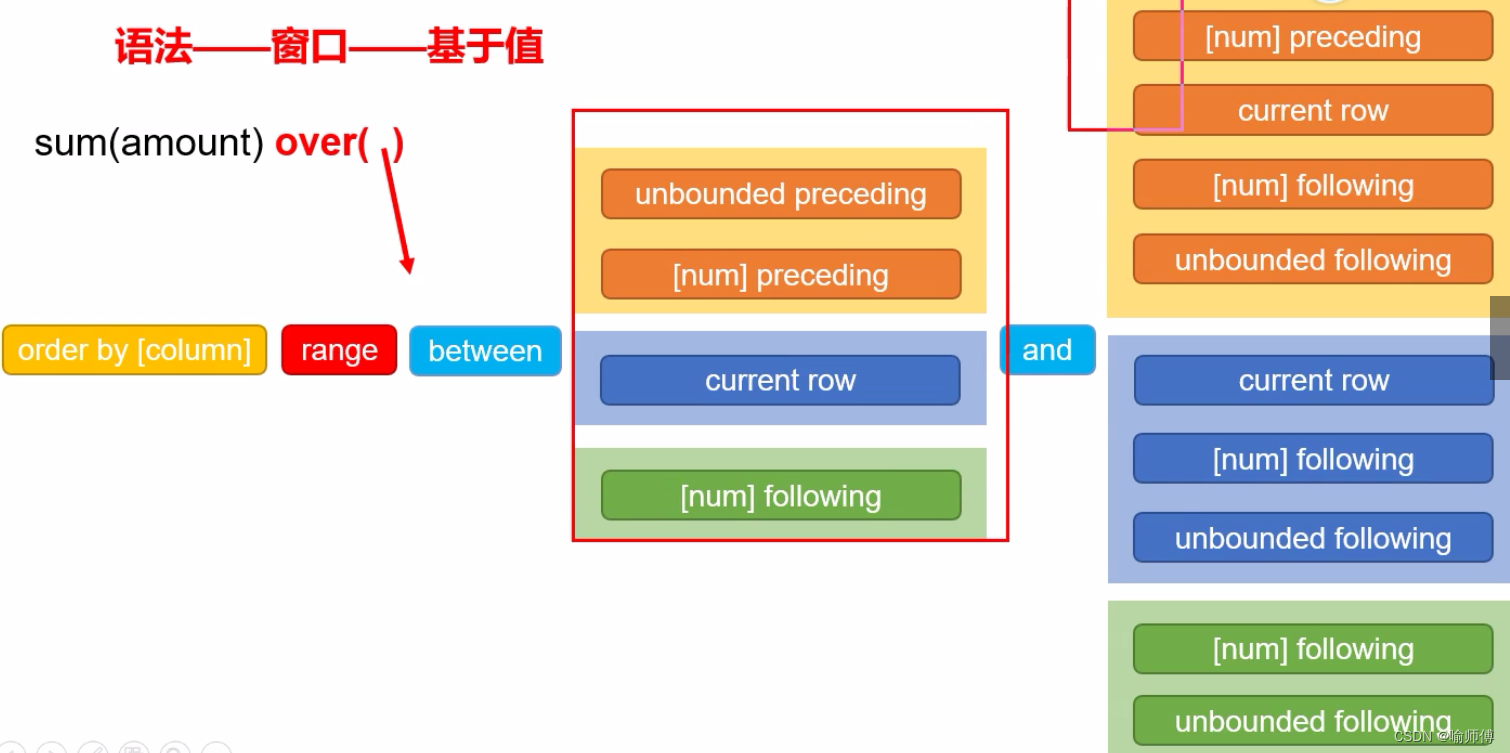
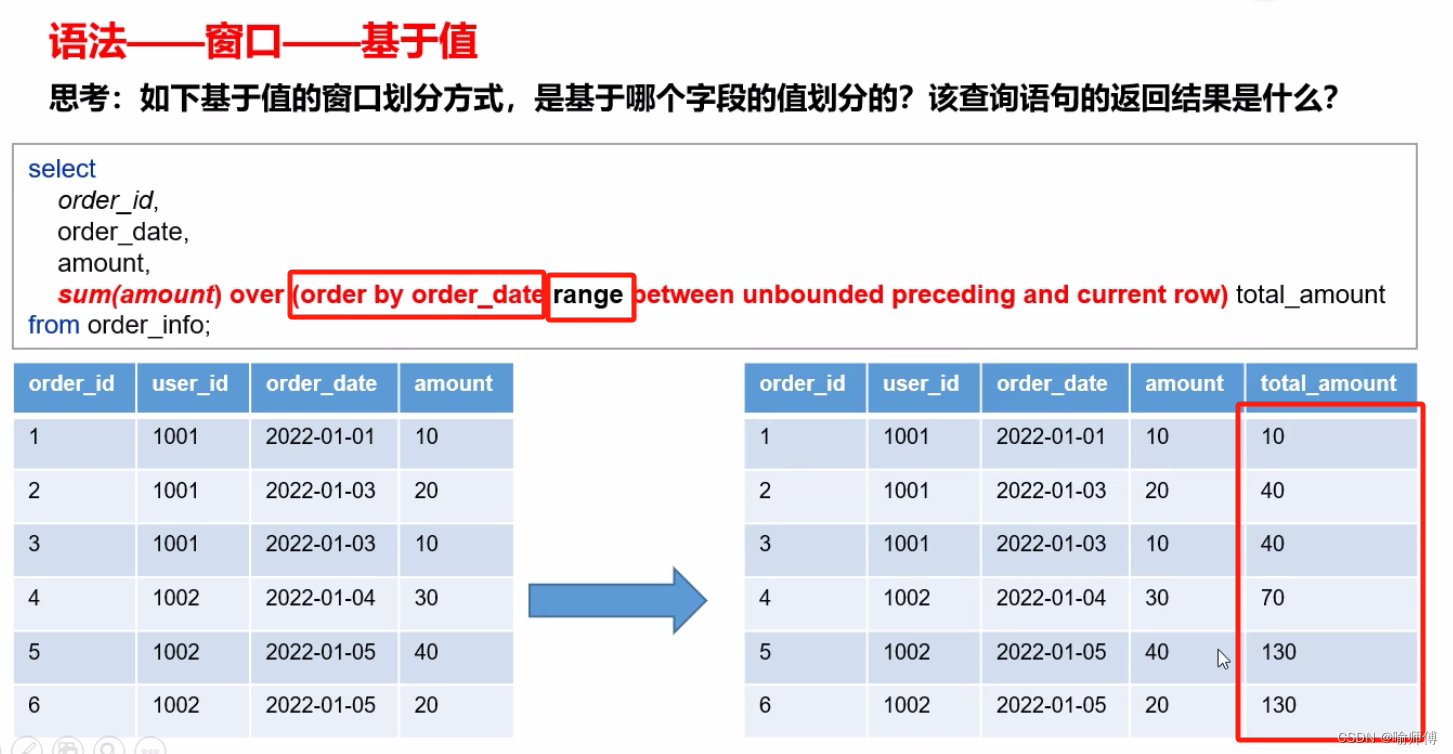

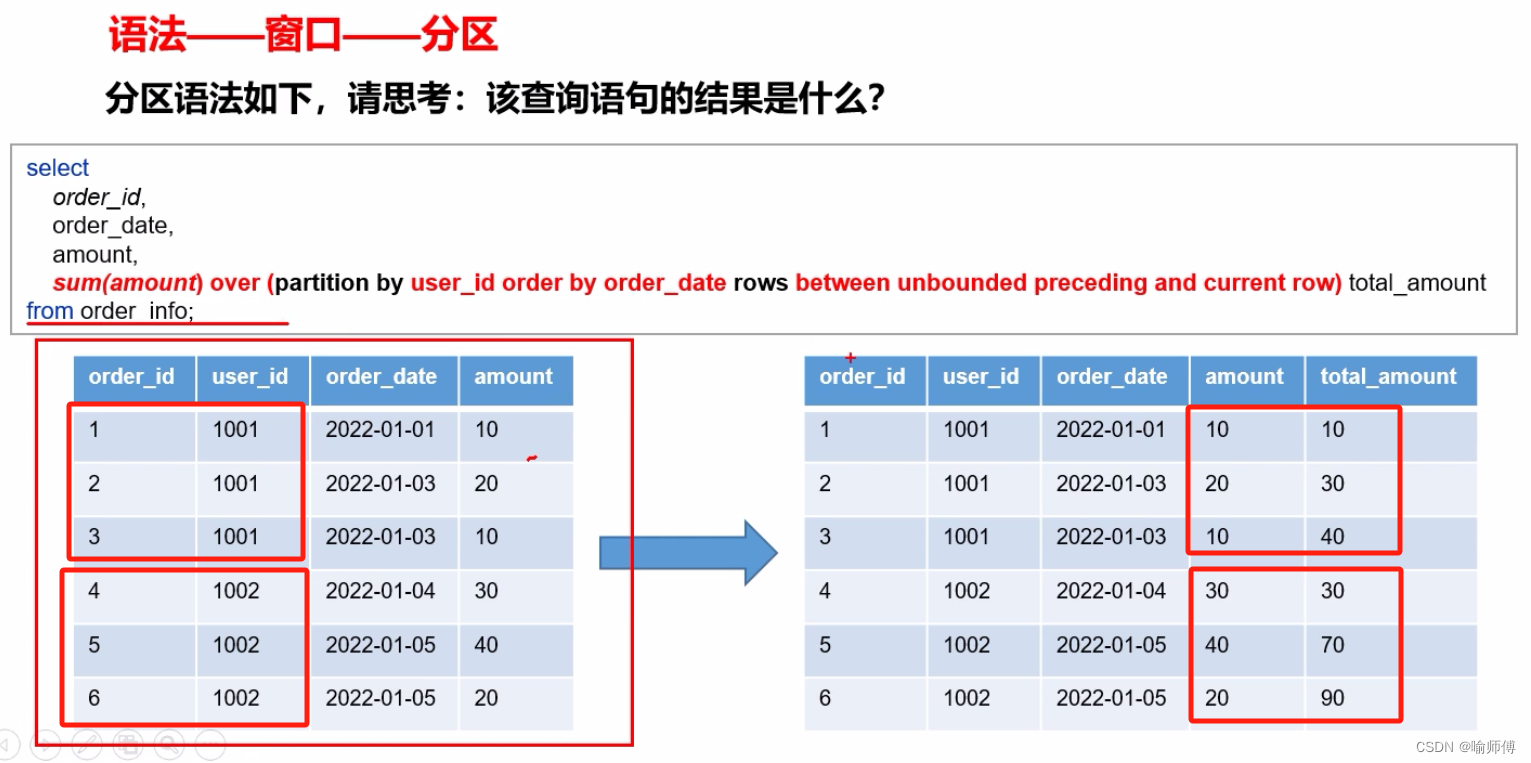

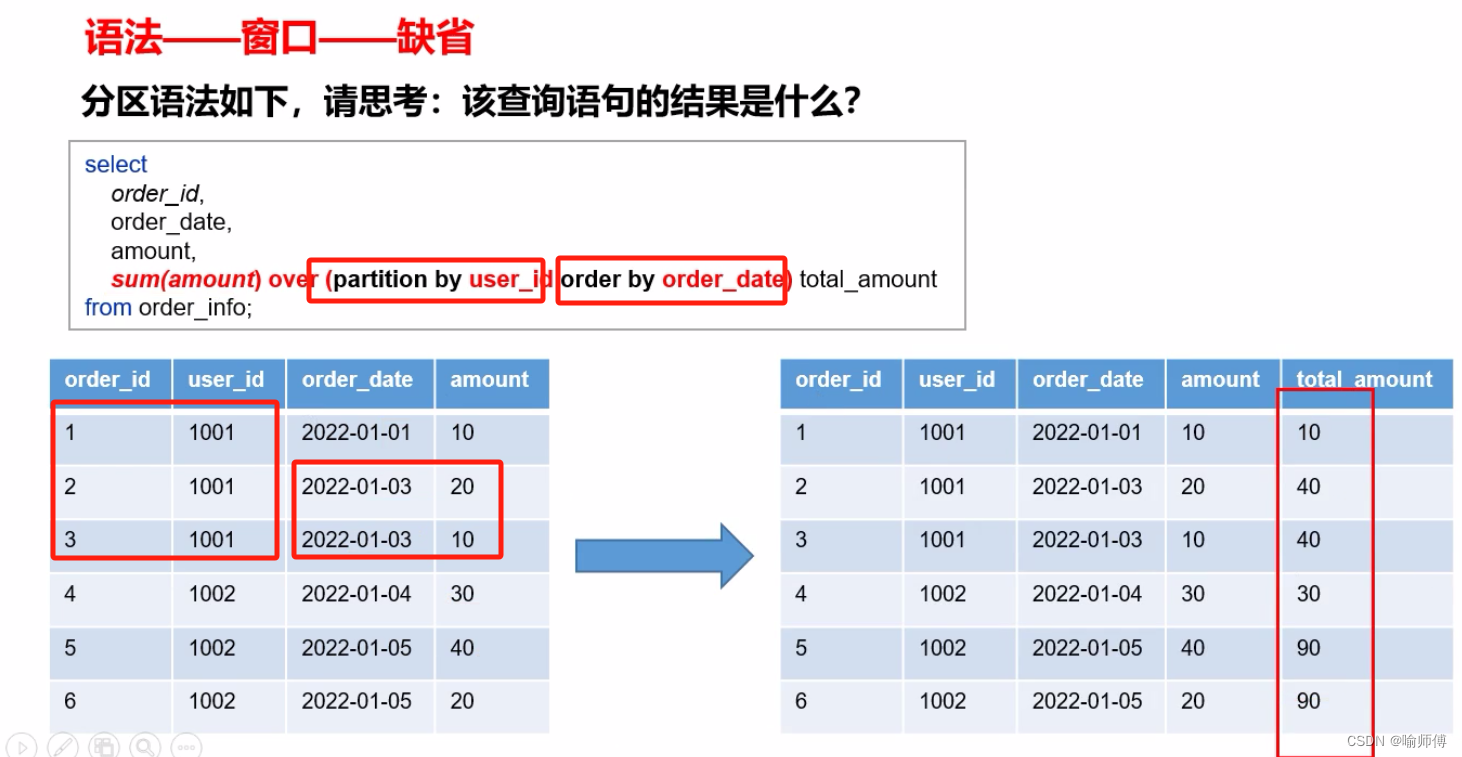
按照功能,常用窗口可划分为如下几类:聚合函数、跨行取值函数、排名函数。
1. 聚合函数
- 这些函数在窗口内执行聚合操作,例如计算平均值、总和、最大值、最小值等。
- 示例:
SUM(),AVG(),COUNT(),MAX(),MIN()。
2. 跨行取值函数
- 这些函数用于获取当前行与其前后行的值,通常用于计算变化值、差值等。
- 示例:
LEAD(),LAG(),FIRST_VALUE(),LAST_VALUE()。
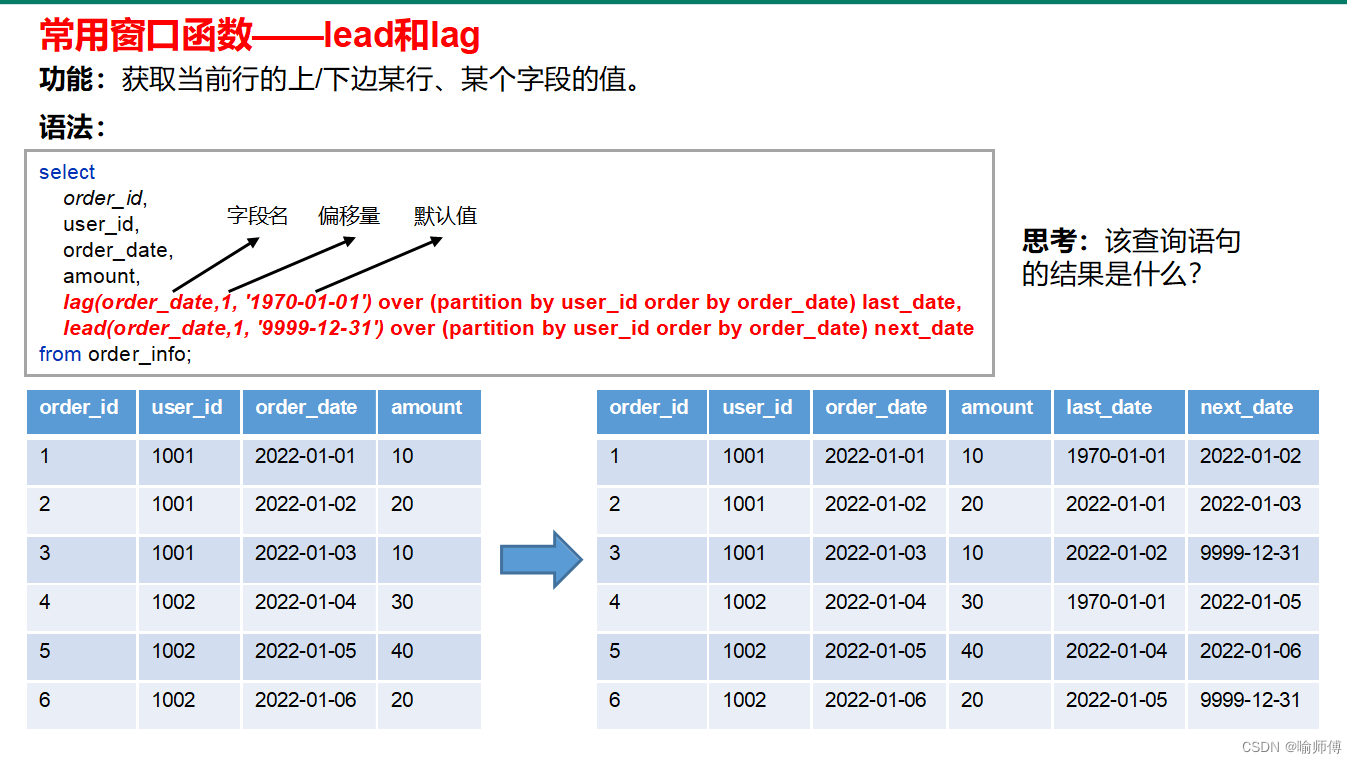
-
lead():该函数用于获取当前行之后偏移量为offset的行的值。
- 示例:
lead(salary, 1, 0) over (order by date) as next_salary
返回按日期排序的薪水数据集中每个员工的下一个日期的薪水,如果没有下一个日期的薪水,则返回0。
- 示例:
-
lag():该函数用于获取当前行之前偏移量为offset的行的值。
- 示例:
lag(salary, 1, 0) over (order by date) as prev_salary
返回按日期排序的薪水数据集中每个员工的前一个日期的薪水,如果没有前一个日期的薪水,则返回0。
- 示例:
-
first_value():该函数用于获取窗口内第一行的值。
- 示例:
first_value(salary) over (partition by department order by hire_date) as first_salary
返回每个部门的第一个雇员的薪水,按入职日期排序。
- 示例:
-
last_value():该函数用于获取窗口内最后一行的值。
- 示例:
last_value(salary) over (partition by department order by hire_date rows between unbounded preceding and unbounded following) as last_salary
返回每个部门的最后一个雇员的薪水,按入职日期排序,并考虑窗口内所有行。

- 示例:
这些函数可以根据具体需求结合使用,对数据进行各种类型的分析和比较,例如计算变化率、检测趋势、识别异常值等。在处理时间序列数据或需要考虑数据历史变化的情况下,这些函数尤其有用。
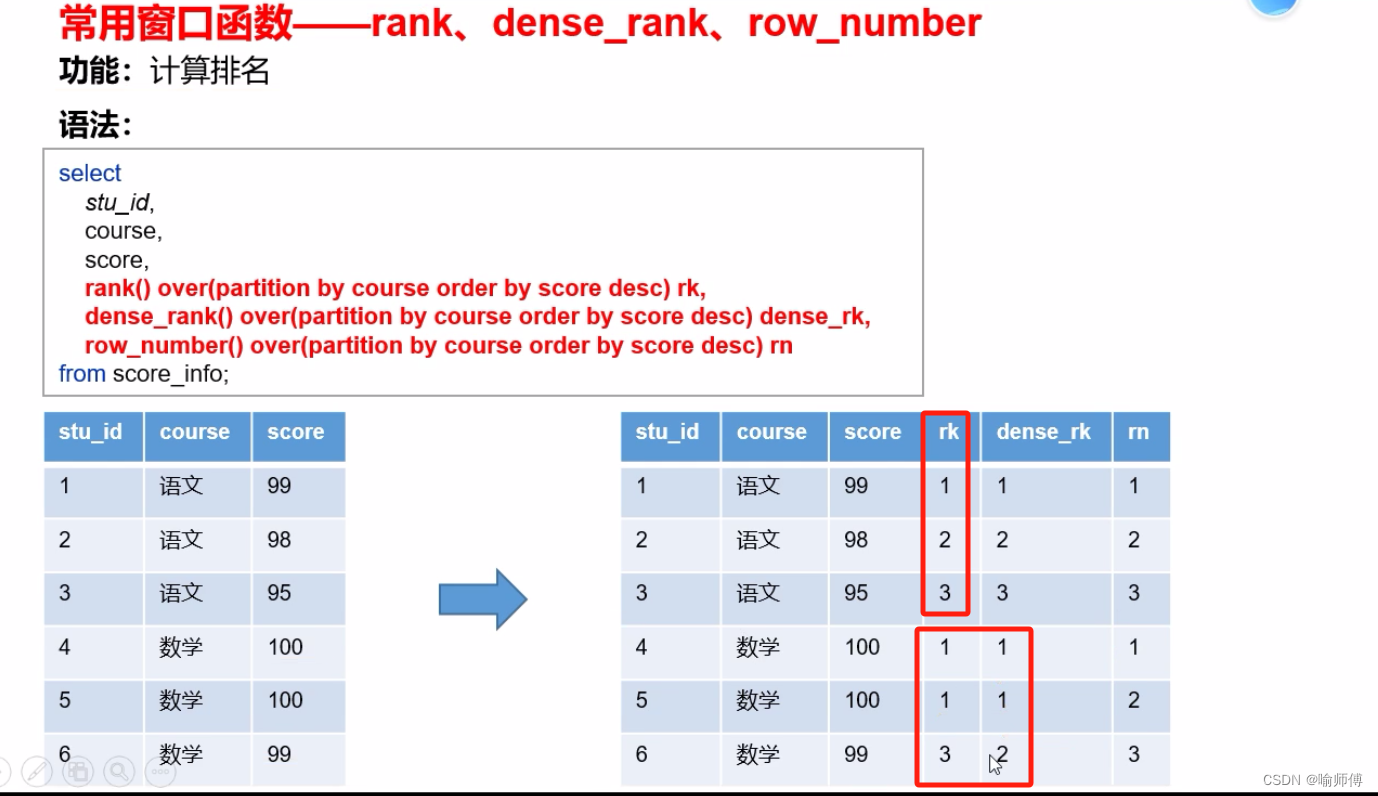
3. 排名函数:
- 这些函数用于为结果集中的每一行分配排名,可以根据需求处理并列排名。
- 示例:
ROW_NUMBER(),RANK(),DENSE_RANK(),NTILE()。
这些函数通常用于在 hive 中对查询结果进行排序和分组,并为每行分配一个序号或者分组号。让我详细解释一下它们的用法:
-
row_number():
- 作用:为查询结果集中的每一行分配一个唯一的连续序号,按照指定的排序顺序进行分配。
- 语法:
row_number() over (order by column1 [, column2, ...]) - 示例:
select column1, column2, row_number() over (order by column1) as row_num from table_name; - 说明:
row_number()函数按照order by子句中指定的列进行排序,然后为每一行分配一个连续的唯一序号。
-
rank():
- 作用:为查询结果集中的每一行分配一个排名,相同的值将会得到相同的排名,但是可能会跳过排名。
- 语法:
rank() over (order by column1 [, column2, ...]) - 示例:
select column1, column2, rank() over (order by column1) as rank from table_name; - 说明:
rank()函数按照order by子句中指定的列进行排序,并为相同值的行分配相同的排名,但是可能会跳过排名(比如有两行值相同,排名为 1 和 2,下一行排名可能是 4)。
-
dense_rank():
- 作用:为查询结果集中的每一行分配一个排名,相同的值将会得到相同的排名,但不会跳过排名,排名是连续的。
- 语法:
dense_rank() over (order by column1 [, column2, ...]) - 示例:
select column1, column2, dense_rank() over (order by column1) as dense_rank from table_name; - 说明:
dense_rank()函数按照order by子句中指定的列进行排序,并为相同值的行分配相同的排名,但是不会跳过排名(比如有两行值相同,排名为 1 和 2,下一行排名仍然是 3)。
-
ntile():
- 作用:将查询结果集分割成指定数量的桶(bucket),并为每一行分配一个桶号。
- 语法:
ntile(n) over (order by column1 [, column2, ...]) - 示例:
select column1, column2, ntile(4) over (order by column1) as quartile from table_name; - 说明:
ntile(n)函数将查询结果集分成n个桶,并为每个桶中的行分配一个桶号(从 1 到n)。如果行数不能被n整除,最后一个桶中的行数可能会少于其他桶。
6.自定义函数
标准函数无法满足需求时,就可以考虑编写自定义函数。这些函数可以用Java编写,并通过Hive的UDF、UDAF、UDTF接口来实现。
-
标量函数(UDF - User-Defined Function):
- 标量函数是处理一行输入并返回单个值的函数。例如,你可以编写一个函数来计算字符串长度、执行日期转换等操作。
- 实现:编写一个Java类,继承自Hive的
org.apache.hadoop.hive.ql.udf.generic.GenericUDF类,并实现evaluate()方法来定义函数的逻辑。然后编译成JAR文件,并在Hive中注册该函数。
-
聚合函数(UDAF - User-Defined Aggregate Function):
- 聚合函数用于对一组值进行聚合操作(如求和、平均值等),并返回单个结果。例如,你可以编写一个函数来计算某列的中位数或者分位数。
- 实现:编写一个Java类,实现Hive的
org.apache.hadoop.hive.ql.exec.UDAFEvaluator接口,并实现一系列方法来定义聚合函数的行为,包括init(),iterate(),terminatePartial(),merge(),terminate()等。然后编译成JAR文件,并在Hive中注册该函数。
-
表生成函数(UDTF - User-Defined Table-Generating Function):
- 表生成函数将输入的一行数据转换成多行数据。例如,你可以编写一个函数来将一列字符串拆分成多行。
- 实现:编写一个Java类,继承自Hive的
org.apache.hadoop.hive.ql.udf.generic.GenericUDTF类,并实现process()方法来定义函数的逻辑。然后编译成JAR文件,并在Hive中注册该函数。