目录
MySQL数据库
第一章
1、什么是数据库
2、数据库分类
3、不同数据库的特点
4、MySQL常见命令:
5、MySQL基本语法
第二章
1、MySQL的常见数据类型
1、数值类型
2、字符类型
3、时间日期类型
2、SQL语句分类
1、DDL(数据定义语言)
2、DML(数据操作语言)
3、DQL(数据查询语言)
4、DCL(数据控制语言)
3、MySQL的查询
第三章
函数顺序
函数
排序函数
分组函数
聚合函数
日期函数
字符函数
数学函数
逻辑判断
第四章
1、数据完整性
1、实体完整性
2、域完整性
3、引用完整性
2、三范式
1、第一范式:确保数据表中每一列的原子性
2、第二范式:确保表中的每列都和主键相关
3、第三范式:数据表中的每一列,与主键直接相关,不能间接关联
3、多表连接查询(重点)
1、内连接 INNER JOIN
1、显式内连接
2、隐式内连接
2、外连接 OUTER JOIN
1、左外连接 left outer join
2、右外连接 right outer join
3、子查询
情况1
情况2
情况3
第五章
第六章
1、事务
1、概念:
2、特性:
2、四个特性(ACID)
1、原子性(Atomicity)
2、一致性(Consistency)
3、隔离性(Isolation)
4、持久性(Durability)
3、三个并发问题
1、脏读(Dirty read)
2、不可重复读(Unrepeatable read)
3、幻读(Phantom read)
4、视图(view)
1、视图的概念
2、视图的好处
3、sql展示
5、存储过程
1、什么是存储过程
2、存储过程的优点
第七章
1、jdbc的使用
jdbc几个重要方法
2、基于jdbc的增删改
3、基于jdbc的查询
4、数据库的dao模式
5、jdbc常见错误
第八章
1、数据库连接池的使用
2、jdbctemplate
jdbctemplate模板的使用步骤:
1、查询全部(返回的list集合)
2、根据id查询(返回的对象)
3、查询总人数
4、模糊查询
5、查询全部(返回的map集合)
6、 根据id查询(返回的是map集合)
7、多表联合查询(返回map集合)
MySQL数据库

第一章
1、什么是数据库
存储数据方式:
1、将数据存储在内存中,当程序关闭数据消失
2、将数据存在文件中,通过流的方式写入文件
3、将数据存储在数据库中,如mySQL
2、数据库分类
可分为:
1、关系型数据库
指定数据采用数据表的方式将数据存储在数据库中
SQLserver
MySQL(会学习)
oracle(会学习)
DB2
..
2、非关系型数据库
它的数据是存储在内存中,读取数据快
Redis(会学习)
MongoDB
..
3、不同数据库的特点
1、SQLserver
它是微软开发工程师,主要用于.net项目
2、MySQL(重点)
它是一个中小型数据库,比较方便、灵活。它主要用于中小项目
3、 oracle
甲骨文公司开发的数据库产品,主要中大型项目
4、db2
IMB开发的数据库,主要用于金融类项目
5、redis mongodb
一种非关系型数据库,数据存放在内存中速度会非常快
第三方工具
1、sqlyog 2、navicat
4、MySQL常见命令:
datebase:数据库
table:数据库
create:创建
drop:删除
use:使用
show:查看
show datebases----查看当前数据库系统包含几个数据库: use数据库名称------连接数据库 ------------创建数据库1,指定编码格式utf8 create datebase 新数据库名 default character set utf8; ------------创建数据库2,采用默认的编码格式 create datebase 新数据库名称; ------------创建数据库3,创建时判断数据库名是否存在 create datebase if not exists 数据库新名称; drop datebase if exists 数据库名--------判断是否存在删除
5、MySQL基本语法
#单行注释
--单行注释
/**/多行注释
--------------------------------------操作库
SHOW DATABASES;-- 查看数据库
CREATE DATABASE a DEFAULT CHARACTER SET utf8;--创建数据库
CREATE DATABASE b-- 创建数据库
CREATE DATABASE IF NOT EXISTS d-- 创建数据库
DROP DATABASE a-- 删除数据库
DROP DATABASE IF EXISTS b-- 删除数据库
-------------------------------------操作表
USE d118-- 选择数据库
SHOW TABLES-- 查看表
DROP TABLE student-- 删除表
DESC student-- 查看表结构
ALTER TABLE student RENAME stu_info;-- 修改表名称
--------------------------------------操作列
ALTER TABLE student MODIFY stu_id INT;-- 修改表的数据类型,只能修改类型,不能改名
ALTER TABLE student CHANGE stu_id id VARCHAR(20)-- 修改表的列名 并修改数据类型
ALTER TABLE student ADD stu_cla VARCHAR(20);-- 增加列
ALTER TABLE student DROP stu_cla;-- 删除列
--------------------------------------操作表的数据
1、向表中添加数据
#添加数据
INSERT INTO student(stu_id,stu_name,stu_score,stu_cla) VALUES(1,'lwj',90,'D118');
#添加数据-简化写法
INSERT INTO student VALUES(1,'lwj',90,'D118');
#一次添加多条数据
INSERT INTO student VALUES(1,'lwj',90,'D118'),(2,'lw',95,'D113'),(4,'l',85,'D116');
#给部分列添加
INSERT INTO student(stu_id,stu_cla) VALUES(1,'D118');
2、修改数据
#修改全部数据//让表中的所有成绩都减10分
UPDATE student SET stu_score=stu_score-10;
#根据条件修改
UPDATE student SET stu_score=0 WHERE stu_id=2;
3、删除数据
#删除全部数据
DELETE FROM student;
#根据条件删除//删除id为1的数据
DELETE FROM student WHERE stu_id=1;
/*
delete删除数据与truncate截断表删除的区别
1、delete是一行一行删除 ,可以带条件删
2、truncate一次截断表中的全部数据,只保留表结构,一次性删完,但不能带条件删
drop删除与delete删除的区别
1、drop只能删除对象(数据库),无法删除数据
2、delete只能删除数据,不能删除对象(数据库)
*/
4、查询数据
#查看表的所有数据
SELECT *FROM student;
#查询部分字段
SELECT stu_id,stu_score FROM student;
#查询时,给字段指定别名(AS可以省略不写)
SELECT stu_id AS 姓名,stu_score AS 成绩 FROM student;
#按条件查询
SELECT *FROM student WHERE stu_id=4;
#查询姓名不为空的数据
SELECT *FROM student WHERE stu_name IS NOT NULL;
#查询成绩为空的数据
SELECT *FROM student WHERE stu_score IS NULL;
创建表结构
注释不会被保存
USE d118;
CREATE TABLE student
(
stu_id INT,-- 学生编号
stu_name VARCHAR(20),-- 学生名称,字符长度为20
stu_score FLOAT(8,2)-- 成绩,浮点数,有效位数8位,小数点后保留2位
);
注释会被保存
CREATE TABLE student (
stu_id INT COMMENT'此方法可以导出注释',
-- 学生编号
stu_name VARCHAR (20) COMMENT'名称',
-- 学生名称,字符长度为20
stu_score FLOAT (8, 2) COMMENT'成绩'-- 成绩,浮点数,有效位数8位,小数点后保留2位
);
第二章
1、MySQL的常见数据类型
1、数值类型
INT -- 整数型
BIGINT -- 相当于java的long类型,只能存储整数
FLOAT -- 单精度浮点型
DOUBLE -- 双精度浮点型
DECIMAL -- 表示货币类型的数据
LONG -- 大型文本类型,并不是long类型
2、字符类型
CHAR -- 字符类型
VARCHAR -- 字符类型
char和varchar都能表示字符类型的数据,不区分单双引号
VARCHAR(20)与CHAR(20)有什么区别:
1、CHAR(20)系统会分配20个存储空间,不满20个数据时,空间也不会缩放,造成空间浪费
VARCHAR(20)存储不满20个数据时,空间会自动缩放,节省资源
2、CHAR的速度会快一些,因为它不用检测存储空间是否占满
VARCHAR会检查存储空间,判断是否要进行空间缩放
推荐情况:如果确定存储数据长度,用char更快
如:性别、电话、身份证号码
如果不确定,则用varchar
如:住址、姓名、备注
3、时间日期类型
1、DATE -- 只包含年月日,不带时分秒
2、DATETIME -- 包含年月日,也包含时分秒
3、TIMESTAMP(时间戳) -- 包含年月日,也包含时分秒
给日期类型数据赋值:
1、指定固定值(DATE DATETIME TIMESTAMP)
INSERT INTO student VALUES(1,'JACK','2010-10-10','2010-10-10 11:22;33','2010-10-01 11:22:44') ;
2、采用系统默认时间 NOW()--获得系统时间,包含年月日 时分秒
INSERT INTO student VALUES(2,'zs',NOW(),NOW(),NOW())
3、采用系统默认时间 CURDATE()--获得当前时间,只有年月日,没有时分秒
INSERT INTO student VALUES(2,'zs',CURDATE(),NOW(),NOW())
4、采用系统默认时间 CURTIME();--获得当前时间,只有时分秒
datetime与timestamp的区别:
datetime如果值为null,系统会显示null
timestamp如果值为null,系统会显示默认时间
2、SQL语句分类
1、DDL(数据定义语言)
DDL: DATA DEFINITION DATA
CREATE-- 创建对象
DROP-- 删除对象
2、DML(数据操作语言)
DML: DATA MANIPULATION DATA
INSERT-- 添加数据
UPDATE-- 修改数据
DELETE-- 删除数据
3、DQL(数据查询语言)
DQL: DATA QUERY DATA
SELECT-- 查询数据
4、DCL(数据控制语言)
GRANT-- 给用户授权
REVOKE-- 撤销用户权限
3、MySQL的查询
增删改查(crud):最简单的就是增 删 改,查是最麻烦的
-- 普通查询 #查询全部数据 *:代表所有列 SELECT *FROM student; #只查询部分字段 SELECT stu_id FROM student; #查询时设置别名 SELECT stu_id 编号,stu_name 姓名 FROM student;;
-- 条件查询
#精准查询
SELECT *FROM student WHERE stu_id=1;
#如果查询的条件是字符,需要加引号
SELECT *FROM student WHERE stu_name='张三';
#比较查询 > >= < <= = != <>
SELECT *FROM student WHERE stu_score >=53;
#日期类型也能比较,但只会比较数值大小 2000-10-10>1980-10-10
SELECT *FROM student WHERE stu_bir >'1995-10-10';
#区间查询
BETWEEN AND:
-- 它用于区间查询
-- 语法: 字段 BETWEEN 开始值 AND 结束值(包含开始和结束)
-- 注意: 查询时较小值放在前面
SELECT *FROM student WHERE stu_score BETWEEN 80 AND 90;
#区间排除查询
SELECT *FROM student WHERE stu_score NOT BETWEEN 80 AND 90;
#日期区间查询
SELECT *FROM student WHERE stu_birT BETWEEN '1995-01-01' AND '1999-01-01'
#范围查询
IN:在某个范围中
NOT IN:不在某个范围中
SELECT *FROM student WHERE stu_class IN('d115','d119');
#模糊查询
LIKE:模糊查询的关键字,只能用于字符类型的查询,一般会使用通配符
_ 代表任意的一个字符
% 代表任意长度,任意内容
SELECT *FROM student WHERE stu_name LIKE '刘_';#姓名必须两个字,必须以刘开头
SELECT *FROM student WHERE stu_name LIKE '_文'姓名必须两个字,必须以文结尾
SELECT *FROM student WHERE stu_name LIKE '刘%';必须以刘开头,无论多少字符
SELECT *FROM student WHERE stu_name LIKE '%文%';所有包含文字的内容
#逻辑运算符查询
&& AND --表示连接的多个条件同时满足(用&&或者AND都可以)
|| OR --表示连接的条件只满足一个就可以
SELECT *FROM student WHERE stu_score>=60 AND stu_gender='男';
#对查询的数据排序
ORDER BY:排序的关键字(默认升序)
ASC:升序(从小到大)
DESC:降序(从大到小)
SELECT *FROM student ORDER BY stu_score DESC;按成绩降序排序
#当出现数据相同无法排序时,还可以按其他列排序
SELECT *FROM student ORDER BY stu_score DESC,stu_id DESC
#聚合查询
一般用于统计汇总,它只能返回单行单列的唯一结果
SUM() -- 计算某一个字段值相加的总和
SELECT SUM(stu_score) FORM student; -- 统计总分数
AVG() -- 计算某一个字段的平均分
SELECT AVG(stu_score) FORM student; -- 统计总分数
COUNT() -- 统计总条数据
SELECT COUNT(*) FORM student; -- 统计总条数
MIN() -- 统计某个字段的最小值
MAX() -- 统计某个字段的最大值
-- 统计考试合格的人数
SELECT COUNT(*) FORM student WHERE stu_score>=60;
#分组查询 where只能出现在group 之前
GROUP BY:用于按某一个字段进行分组
语法:SELECT 分组的列,聚合函数 FORM 表 GROUP BY 分组的列;
#统计有哪些班级
SELECT stu_class 班级名称 FORM student GROUP BY stu_class;
#统计有哪些班级,以及每个班有多少学生--先分组,再聚合
SELECT stu_class 班级名称,COUNT(*) FORM student GROUP BY stu_class;
#多列分组
#先分组班级,再分组性别,最后统计人数
SELECT stu_class 班级名称,stu_gender 性别 ,COUNT(*)人数 FORM student GROUP BY stu_class,stu_gender;
#统计每一个班级男生女生考试合格的人数
SELECT stu_class 班级名称,stu_gender 性别 ,COUNT(*)人数 FORM student WHERE stu_score>=60 GROUP BY stu_class,stu_gender;
#统计每一个班,考试合格人数,并且按合格人数,降序排列
SELECT stu_class 班级名称,COUNT(*) FORM student WHERE stu_score>=6 GROUP BY stu_class· ORDER BY COUNT(*) DESC;
#显示所有班级人数在5人以上的班级
where只能在group by之前使用,如果使用分组之后需要条件判断,只能用having设置条件
SELECT stu_class,COUNT(*) FORM student GROUP BY stu_class HAVING COUNT(*)>=5
目前查询用到关键字:
where---过滤条件
group by--分组
having---分组之后设置条件
order by--排序
如果同时出现,必须遵循下列顺叙
where---gruop by---having---order by--
limit分页查询
LIMIT 指定从哪一个下标开始,查询几条数据
语法: SELECT * FORM 表 LIMIT 开始下标,几条数据
SELECT *FROM student LIMIT 0,3;
#查找分数最高的三个学生信息
SELECT *FROM student ORDER BY stu_score DESC LIMIT 0,3;
第三章
函数顺序
select * from 表名 where ... group by ... ha order by score desc limit 0,3
函数
排序函数
排序函数 ORDER BY (DESC降序) (ASC升序) SELECT * FROM 表 ORDER BY 字段; #没有指定排序方式,默认是升序 SELECT * FROM 表 ORDER BY 字段 ASC; SELECT * FROM 表 ORDER BY 字段 DESC; SELECT * FROM 表 ORDER BY 字段1 DESC,字段2 DESC;
分组函数
ROUP BY SELECT 分组字段名,聚合函数 FROM 表 GROUP BY 分组字段名; SELECT 字段名1,字段名2,聚合函数 FROM 表 GROUP BY 字段名1,字段名2; SELECT class,COUNT(*) FROM info GROUP BY class; SELECT class,gender,COUNT(*) FROM info GROUP BY class,gender; ##分组之前设置条件用where,分组之后设置条件用having #分组之前设置条件 SELECT class,COUNT(*) FROM info WHERE score>=60 GROUP BY class; #分组之后设置条件(只统计考试合格人数在5人以上的班级) SELECT class,COUNT(*) FROM info WHERE score>=60 GROUP BY class HAVING COUNT(*)>=5; SELECT class,COUNT(*) FROM info WHERE score>=60 GROUP BY class HAVING COUNT(*)>=5 ORDER BY COUNT(*);
聚合函数
MAX() #求最大值 MIN() #求最小值 COUNT() #求总记录数 SUM() #求总合 AVG() #求平均值 SELECT COUNT(*),MAX(score),MIN(score),AVG(score),SUM(score) FROM info;
日期函数
作用:用于执行与日期相关的操作
NOW();
#获得当前系统时间,包含年月日,时分秒
SELECT NOW();
INSERT INTO 表 VALUES(NOW());
CURDATE();
#获得当前系统时间,包含年月日
SELECT CURDATE();
CURTIME();
#获得当前系统时间,包含时分秒
SELECT CURTIME();
YEAR(),MONTH(),DAY(),HOUR(),MINUTE(),SECOND();
#这一组函数,用于获得当前系统时间指定部分的值
SELECT YEAR(NOW());
SELECT MONTH(NOW());
SELECT DAY(NOW());
SELECT MINUTE(NOW());
SELECT YEAR('2010-10-10');
SELECT NAME,bir,YEAR(bir) FROM info;
LAST_DAY();
#获得指定日期所在月份的最后一天是哪一个日期
SELECT LAST_DAY(NOW());
SELECT NAME,bir,LAST_DAY(bir) FROM info;
#在实际开发中,数据表中不会有年龄字段
DATEDIFF() #该函数用于计算两个日期之间间隔的天数
语法: DATEDIFF(较近的日期,较远的日期);
SELECT DATEDIFF(CURDATE(),'2012-08-01');
SELECT FLOOR(DATEDIFF(CURDATE(),'2012-08-01')/365) 年龄;
TIMESTAMPDIFF() #该函数用于获得两个时间之间间隔的数值(单位由自己设置)
语法: TIMESTAMPDIFF(时间单位,较远的日期,较近的日期)
时间单位:YEAR,MONTH,DAY,HOUR,MINUTE,SECOND
SELECT TIMESTAMPDIFF(YEAR,'2012-08-01',CURDATE());
字符函数
LENGTH() #计算所占字节长度 #注意:一个汉字占3个字节长度
SELECT LENGTH('A');
TRIM();
#去掉字符两侧的空格
SELECT TRIM(' aa ') 数据;
LOWER(),UPPER();
#转换字母的大小定
#lower()转换成小写
#upper()转换成大写
SELECT LOWER('ABCabc') 小写,UPPER('ABCabc') 大写;
SUBSTR(),SUBSTRING();
#这两种函数都是用于截取字符串,没有区别
SELECT SUBSTR(字符数据,开始位置,长度);
SELECT SUBSTR('12345ABC678',6,3);
SELECT SUBSTRING('12345ABC678',6,3);
REPLACE()
#替换字符串的指定内容
SELECT REPLACE(字符内容,旧数据,新数据);
SELECT REPLACE('你好!张三','张三','李四');
SELECT REPLACE('13986141027','86141','*****');
SELECT REPLACE('123ABC123','123','ttt');
SELECT REPLACE('13999999999','99999','*****');
INSERT()
#替换字符串的指定内容
SELECT INSERT(字符数据,开始位置,长度,新内容);
SELECT INSERT('13999999999',4,5,'*****');
CONCAT()
#将多个字符数据。连接成在一起
SELECT CONCAT(字符数据1,字符数据2,字符数据3);
SELECT CONCAT('张三的成绩是','100','分');
SELECT CONCAT(NAME,'的分数是:',score) FROM info;
LPAD,RPAD
LPAD:截取字符数据,如果要截取的数据长度不够,就从左边填充指定字符数据
SELECT LPAD('12345ABCDE123',5,'*');
SELECT LPAD('12',5,'*');
RPAD:截取字符数据,如果要截取的数据长度不够,就从右边填充指定字符数据
SELECT RPAD('12345ABCDE123',5,'*');
SELECT RPAD('12',5,'*');
数学函数
FLOOR();
#向下取整,取一个小于当前浮点数的最大整数
SELECT FLOOR(123.45);
CEIL();
#向上取整,取一个大于当前浮点数的最小整数
SELECT CEIL(123.45);
RAND();
#获得一个介于0-1之间的随机浮点数
SELECT RAND();
POWER(X,Y);
#计算x的y次方
SELECT POWER(2,6);
ROUND();
#对浮点数,四舍五入,保留指定位数
SELECT ROUND(123.45678,2);
UUID();
#产生一个36位的随机字符串,它由32个字符加四根横线构成
SELECT UUID();
逻辑判断
IF()
#作用:用于在查询语句,进行逻辑判断,生成新的信息
SELECT IF(表达式,结果1,结果2);
#如果表达式成立,就显示结果1,否则显示结果2
SELECT NAME,score,IF(score>=60,'合格','不合格') 考核结果 FROM info;
CASE ...WHEN
#作用:用于进行多条件判断
SELECT CASE
WHEN 表达式1 THEN '结果1'
WHEN 表达式2 THEN '结果2'
WHEN 表达式3 THEN '结果3'
ELSE '结果4'
END 结果
SELECT NAME,score,
CASE
WHEN score>=90 THEN '优秀'
WHEN score>=80 THEN '良好'
WHEN score>=60 THEN '合格'
ELSE '不合格'
END 考核结果
FROM info;
第四章
1、数据完整性
数据完整性包含三个方面:
1、实体完整性
目的:保证数据表的每一条记录,可以被唯一标识
下列约束,可以保证数据的实体完整性
1、主键约束 PRIMARY KEY #此约束,该列的值不允许为空,并且不允许出现重复值 2、唯一约束 UNIQUE #此约束不允许出现重复值 3、自动增长列(自动标识列) AUTO_INCREMENT 一#般在主键字段上,可以加上自动标识列,这样,主键值将会由系统自动生成连续的序号 约束:CONSTRAINT #主键约束与唯一约束都要约束保证列不出现重复值,区别是: 1、一张表只能有一个主键约束,一张表可以有多个唯一约束 2、字段加了主键约束后,该字段不允许出现null值, 字段加了唯一约束,可以出现null值,但null值只能出现一次 3、字段加了主键约束,该字段可以被外键引用,加了唯一约束的字段无法被引用 #为了让每一条数据可以被唯一的标识,建议每一张表一定要有主键 #示例: CREATE TABLE student( id INT PRIMARY KEY AUTO_INCREMENT, name varCHAR(20), score INT ) INSERT INTO student(id) VALUE(NULL); (但这样写毫无意义,我因此,我们用到域完整性,保证数据有效)
2、域完整性
目的:保证数据表中每一列的值,准确有效
1、非空约束 not null
此约束不允许出现null值
#示例:
CREATE TABLE student(
id INT PRIMARY KEY AUTO_INCREMENT,(主键)
name varCHAR(20),
score INT NOT NULL(非空约束)
)
2、默认值约束 default
此约束,如果没有给字段赋值,系统会使用默认值
#示例:
CREATE TABLE student{
id INT PRIMARY KEY AUTO_INCREMENT,(主键)
name varCHAR(20),
score INT DEFAULT 0(如果没有赋值,则默认0分)
}
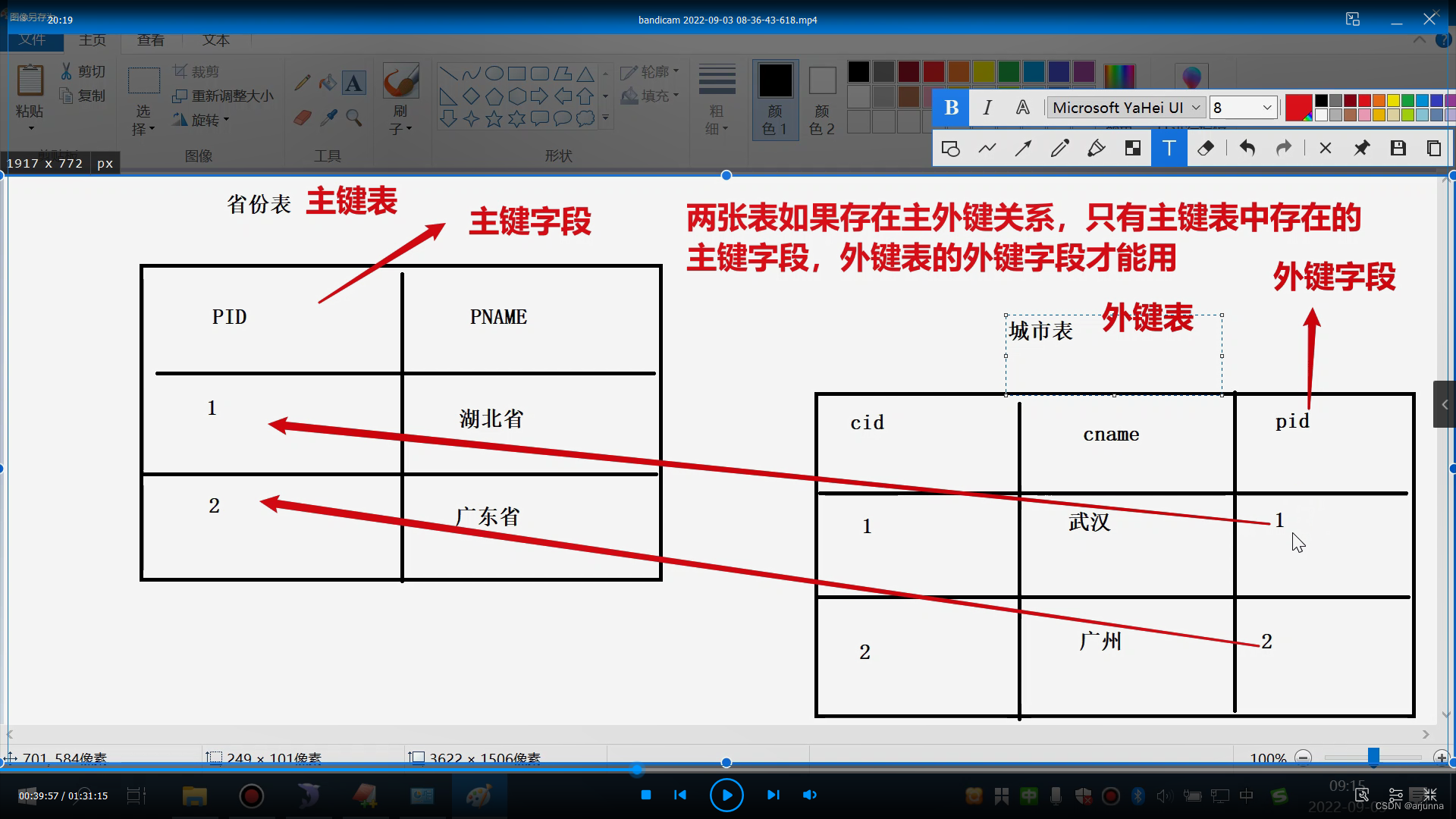
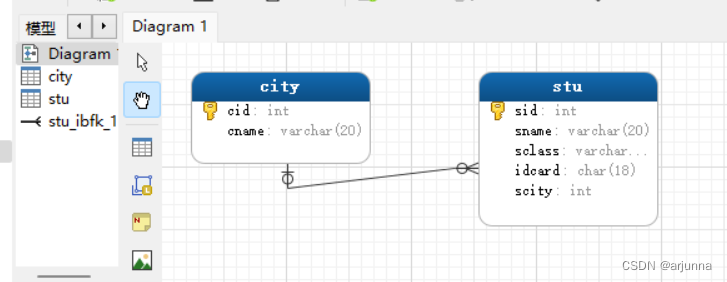
3、引用完整性
目的:保证一张表引用另一张表的数据,引用的数据,在另一张表中是存在的
1、---------------------直接在创表的时候添加主键约束
#省份表(主键表)
CREATE TABLE province{
pid INT PRIMARY KEY AUTO_INCREMENT,(主键 省份编号)
pname VARCHAR(20)(省份名称)
}
INSERT INTO province VALUES(1,'湖北省');
INSERT INTO province VALUES(1,'广东省');
#城市表(外键表)
CREATE TABLE city{
cid INT PRIMARY KEY AUTO_INCREMENT,(主键 城市编号)
cname VARCHAR(20),(城市名称)
pid INT, (城市所属省份编号)
FOREIGN KEY (pid) REFERENCES province(pid)#外键约束
}
INSERT INTO city VALUES(1,'武汉',1);
INSERT INTO city VALUES(2,'襄阳',1);
INSERT INTO city VALUES(3,'广东',2);
2、-----------------------先创表,再添加约束
#城市(主键表)
CREATE TABLE city{
cid INT ,
cname VARCHAR(20),
}
//修改id为主键约束,并自动增长
ALTER TABLE city MODIEY cid INT PRIMARY KEY AUTO_INCREMENT
//修改城市名称非空
ALTER TABLE city MODIEY cname varchar(20) not null
#学生表
CREATE TABLE stu{
sid INT PRIMARY KEY AUTO_INCREMENT,
sname VARCHAR(20) not null,
cid INT
}
//
ALTER TABLE stu ADD CONSTRAINT fk_cid FOREIGN KEY (cid) REFERENCES city(cid)
1、外键约束 foreign key
此约束,1、只有主键表中存在的主键字段,外键表才可以引用
2、如果主键表的主键字段被外键引用,则当外键表数据删除之前,主键表的数据不允许被删除
3、如果主键表被外键表关联,在外键表被删除之前,主键表不能被删除
#主键表:被外键字段引用的数据表;
#外键表:主动去引用数据的表
FOREIGN KEY (外键表的外键字段名) REFERENCES 主键表(主键字段名)
2、三范式
在创建数据表时,我们一般遵循三范式原则:
采用三范式创建的数据表相对合理,避免产生过多的沉余
1、第一范式:确保数据表中每一列的原子性
翻译:数表的每一列都是不可拆分的最小单元

2、第二范式:确保表中的每列都和主键相关
翻译:一张表只描述一件事,如果描述了多件事,需要分解成不同的表

3、第三范式:数据表中的每一列,与主键直接相关,不能间接关联
翻译:一张表如果引用了另一张表的主键字段,就不能再包含另一张表的其他字段

3、多表连接查询(重点)
#在进行多表关联时,一定要正确设置关联条件,否则会产生“笛卡尔积” 笛卡尔积:数据表的数据交叉匹配(如果去掉on后面的,就会产生笛卡尔积) SELECT 字段.. FROM 表1 INNER JOIN 表2 ON(表1.字段=表2.字段) 例如:a表:5条数据 b表:4条数据 笛卡尔积就等于20条数据 2表至少要设置1个关联条件 3张表至少要设置2个关联条件 n张表要设置n-1个关联条件
1、内连接 INNER JOIN
#特点:它所连接的两张表是平级关系,必须要两张表都存在的数据,才可以建立连接 语法:SELECT 字段.. FROM 表1 INNER JOIN 表2 ON(表1.字段=表2.字段); SELECT stu.sid,stu.sname,stu.sgender,stu.sclass,score.socres FROM stu INNER JOIN score ON(stu.sid=score.Sno) #问题:两张表进行连接是否一定要创建出外键关系? 不需要,外键的作用主要是限制,添加数据时只有主键表有的数据,外键表才能引用。 不论有没有主外键关系,两张表都可以进行连接查询 #问题2: 在进行表连接时,字段名前面的表名称能不能省略不写? 如果当前显示的字段名在两张表中,没有重名的情况下,字段名前的表名可以省 SELECT stu.sid,sname,sgender,sclass,socres FROM stu INNER JOIN score ON(stu.sid=Sno) #如果表名太长 我们可以起别名(a和b) SELECT a.sid,sname,sgender,sclass,socres FROM stu a INNER JOIN score b ON(a.sid=Sno)

内连接有两种写法:
1、显式内连接
#两张表的连接条件用on指定,连接条件要写在括号中 SELECT 字段.. FROM 表1 INNER JOIN 表2 ON(表1.字段=表2.字段); #如果两张表连接后还要设置查询条件,在on的连接条件后,用where指定即可 SELECT 字段.. FROM 表1 INNER JOIN 表2 ON(表1.字段=表2.字段) where 条件
2、隐式内连接
语法:SELECT 字段.. FROM 表1,表2 where 表1.字段=表2.字段 SELECT a.sid,sname,sgender,sclass,socres FROM stu a,score b WHERE a.sid=Sno #如果要设置条件,在后面加and SELECT a.sid,sname,sgender,sclass,socres FROM stu a,score b WHERE a.sid=Sno AND socres=90
#三张表的连接
1、显式语法:
SELECT 字段.. FROM 表1 INNER JOIN 表2 ON(表1.字段=表2.字段)
INNER JOIN 表3 ON(表1.字段=表3.字段)
...
2、隐式语法:
SELECT 字段.. FROM 表1,表2,表3 where 表1.字段=表2.字段 AND
表1.字段=表3.字段
2、外连接 OUTER JOIN
#特点:外连接的两张表分为主表和副表,主表的数据必须全部显示,副表的数据与主表的数据对应才能显示
#三张表的外连接
SELECT a.sid 编号,sname 姓名,sage 年龄,sgender 性别,sclass 班级,stel 电话,sregtime 入学时间,socres 分数,cname 课程 FROM stu a LEFT JOIN score b ON (a.sid=Sno)
LEFT JOIN course c ON (b.cid=c.cid);
#问题:外连接与内连接有什么区别
1、内连接所连接的两张表是平级关系,必须要两张表都有的数据,才可以建立关联
外连接所连接的两张表不是平级关系,分为主表与副表,主表的数据必须全部显示,副表的数据与主表的数据对应才能显示
1、左外连接 left outer join
#左侧的表是主表,右侧的表是副表 简写:left join a表 left outer join b表 SELECT a.sid,sname,sgender,sclass,socres FROM stu a LEFT JOIN score b ON(a.sid=Sno)
2、右外连接 right outer join
#右侧的表是主表,左侧的表是副表 简写:right join a表 right outer join b表 SELECT a.sid,sname,sgender,sclass,socres FROM stu a RIGHT JOIN score b ON(a.sid=Sno)
3、子查询
#在一条查询语句中,包含多个select子句,这样的查询语句,就称为:子查询(三种情况) 注意:在子查询中,括号里面的语句先执行,括号外面后执行 select * from 表 where 字段 in (select *from 字段)
情况1
#如果子查询语句返回的是单行、单列的唯一结果,子查询语句一般作为查询条件进行数据的过滤,并且在匹配条件是,只能使用下列符号 > >= < <= = != <> 第一步:查询班级考试的平均分 select AVG(socres) FROM score -- 80.5 第二步:查询考试成绩低于班级平均分的学生 select * FROM score WHERE socres <80.5 第三步:推理可得(相当于省略了获得平均分那一步,合并到第二步进行查询) select * FROM score WHERE socres <(select AVG(socres) FROM score)
情况2
#如果子查询语句的结果是返回的单列,多行,它一般也是用作为条件去过滤,并且只能用下列符号进行条件判断 in, not in 题目:查询所有没有参加考试的学生 1、首先查询成绩表,找到参加考试的学生id SELECT sno FROM score -- (1,2,3,4,5,6,7)这些学生参加考试了 2、判断哪些学生没有参加考试 select * from stu WHERE sid NOT in(1,2,3,4,5,6,7) 3、推理可得(把第一步带入到第二步中) select * from stu WHERE sid NOT in(SELECT sno FROM score)
情况3
#如果子查询返回的是多行、多列,一般是把查询结果当做一张表来继续查询 #如果要把查询的结果当做表使用,要求必须给查询的结果指定别名 select * from 第一步:先查询学生表 SELECT *from stu 第二步:连接学生表,成绩表,课程表,按分数来修改学生表的备注res SELECT sname,cname,socres,CASE WHEN socres>=90 THEN '优秀' WHEN socres>=80 THEN '良好' WHEN socres>=60 THEN '及格' ELSE '不及格' END res FROM score a, stu b,course c WHERE a.sno=b.sid AND a.cid=c.cid 第三步:将第一步查询到的学生表结果,当做新的表来查询,指定新表名称为k SELECT *from ( SELECT sname,cname,socres,CASE WHEN socres>=90 THEN '优秀' WHEN socres>=80 THEN '良好' WHEN socres>=60 THEN '及格' ELSE '不及格' END res FROM score a, stu b,course c WHERE a.sno=b.sid AND a.cid=c.cid ) k ; 拓展:将学生表的res分组,合并显示及格多少人,不及格多少人 SELECT res 备注,COUNT(*) 人数 from ( SELECT sname,cname,socres,CASE WHEN socres>=90 THEN '优秀' WHEN socres>=80 THEN '良好' WHEN socres>=60 THEN '及格' ELSE '不及格' END res FROM score a, stu b,course c WHERE a.sno=b.sid AND a.cid=c.cid ) k GROUP BY k.res;
第五章
视图----事务-----jdbc
好家伙,看完第五章视频,结果光讲外连接和子查询去了,视图和事务还有jdbc是一点没讲啊
第六章
此章没有视频,在哔站看的
1、事务
事务:(Transaction)是用来维护数据库完整性的,它能够保证一系列MySQL操作要么全部执行,要么全部执行
1、概念:
事务指的是一个操作序列,该操作序列中的多个操作要么都做,要么都不做,是一个不可分割的工作单位,是数据库环境中逻辑工作单位,由DBMS(数据库管理系统)中的事务管理子系统负责事务处理。
2、特性:
事务处理可以确保非事务性序列内的所有操作都成功,否则不会永久更新面向数据的资源。通过将一组相关操作组合为一个要么全执行,要么全不失败,可以简化错误恢复并使应用程序更加可靠 但不是所有的操作序列都可以称为事务,因为要成为事务,必须满足四个特性 C:\Program Files\MySQL\MySQL Server 5.5
示例:

DROP TABLE account
创建账户表
CREATE TABLE account (
id INT PRIMARY KEY auto_increment,
uname VARCHAR (20) NOT NULL,
balance DOUBLE
查看
SELECT * FROM account
插入数据
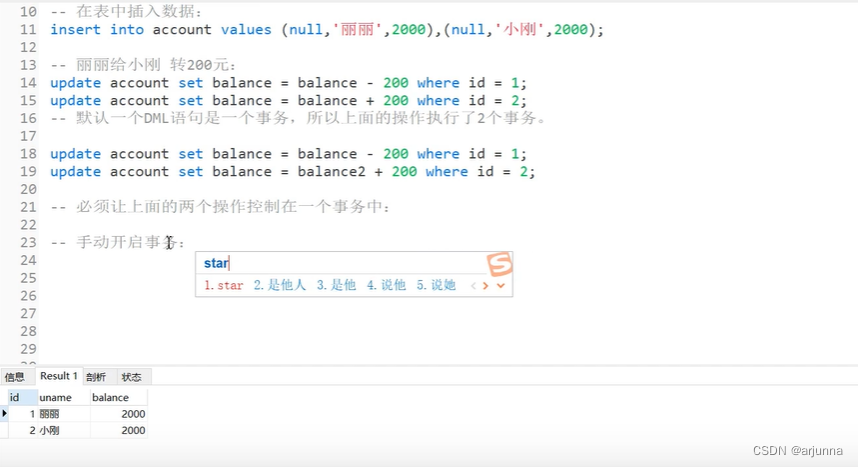
INSERT INTO account VALUES(null,'李白',2000),(null,'韩信',2000)
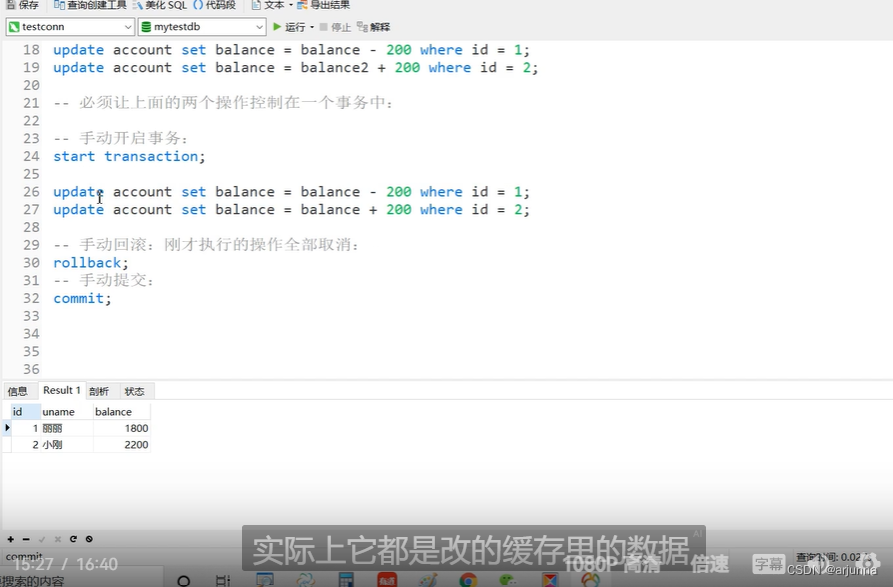
开启事务(开始转账)
START TRANSACTION;
转账(此时改的数据只是缓存的数据,并不是数据库的数据)
UPDATE account set balance=balance-200 WHERE id=1;
UPDATE account set balance=balance+200 WHERE id=2;
回滚(这里之所以可以回滚,是因为数据库的真正数据并没有改变)
ROLLBACK
提交(这时候才是真正改变数据库的数据)
COMMIT
2、四个特性(ACID)
1、原子性(Atomicity)
原子是自然界最小的颗粒,,具有不可再分的特性。事务中的所有操作可以看做一个原子,事务是应用中不可再分的最小逻辑执行体。使用事务对数据进行修改的操作序列,要么全部执行,要么全部不执行。通常,某个事务中的操作都具有共同的目标,并且是相互依赖的。
2、一致性(Consistency)
一致性是指事务执行的结果必须是数据库从一个一致性状态,变到另一个一致性状态。当数据库只包含事务成功提交的结果时,数据库处于一致性状态。一致性是通过原子性来保证的 例如:在转账时,只有保证转出和转入的金额一致才能构成事务。也就是说事务发生前和发生后,数据的总额依然匹配
3、隔离性(Isolation)
隔离性是指各个事务的执行互不干扰,任意一个事务的内部操作对其他并发的事务,都是隔离的。也就是说:并发执行的事务之间即不能看到对方的中间状态,也不能互相影响 例如:在转账时,只有当a账户中的转出和b账户中的转入操作都执行成功后,才能看到a账户中的金额减少,以及b账户中的金额增多。并且其他事务对于转账操作的事务是不能产生任何影响的
4、持久性(Durability)
持久性指事务一旦提交,对数据所做的任何改变,都要记录到永久存储器中,通常是保存进物理数据库,即使数据库出现故障,提交的数据也应该能够恢复。但如果由于外部原因导致的数据库故障,如硬盘损坏那么之前提交的数据则有可能丢失
3、三个并发问题
1、脏读(Dirty read)
当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到数据库这是另外一个事务也访问了这个数据然后使用了当前这个数据。因为数据是还没有提交的数据,那么另外一个事务读到的这个数据就是‘脏数据’,依据脏数据所做的操作可能是不正确的
| 时间点 | 事务A | 事务B |
|---|---|---|
| 1 | 开启事务A | |
| 2 | 开启事务B | |
| 3 | 查询余额为100 | |
| 4 | 余额增加50(150) | |
| 5 | 查询余额为150(脏数据) | |
| 6 | 事务回滚 |
2、不可重复读(Unrepeatable read)
指在一个事务内多次读同一个数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次诉求的数据可能不太一样。这就发生了在一个事务内两次读到的数据不一样的情况,一次称为不可重复读
| 时间点 | 事务A | 事务B |
|---|---|---|
| 1 | 开启事务A | |
| 2 | 开启事务B | |
| 3 | 查询余额为100 | |
| 4 | 余额增加50(150) | |
| 5 | 查询余额为100 | |
| 6 | 事务回滚 | |
| 7 | 查询余额为150 |
3、幻读(Phantom read)
幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时,在随后的查询中,第一个事务(T1)就发现多了一些原本不存在的记录,就好像发生了幻觉一样
| 时间点 | 事务A | 事务B |
|---|---|---|
| 1 | 开启事务A | |
| 2 | 开启事务B | |
| 3 | 查询id<3的所有记录,共三条 | |
| 4 | 插入一条记录 id=2 | |
| 5 | 提交事务 | |
| 6 | 查询id<3的所有记录,共4条 |
不可重复读与幻读的区别:
不可重复读的重点是修改(这是操作的某一行) 幻读的重点在于新增或者删除(而它是操作整个表)
解决:
不可重复读:只需要锁住满足条件的行(通俗的讲就是将某一行锁住,不让修改数据) 幻读:需要锁住表(将整个表锁住,不让添加行数)
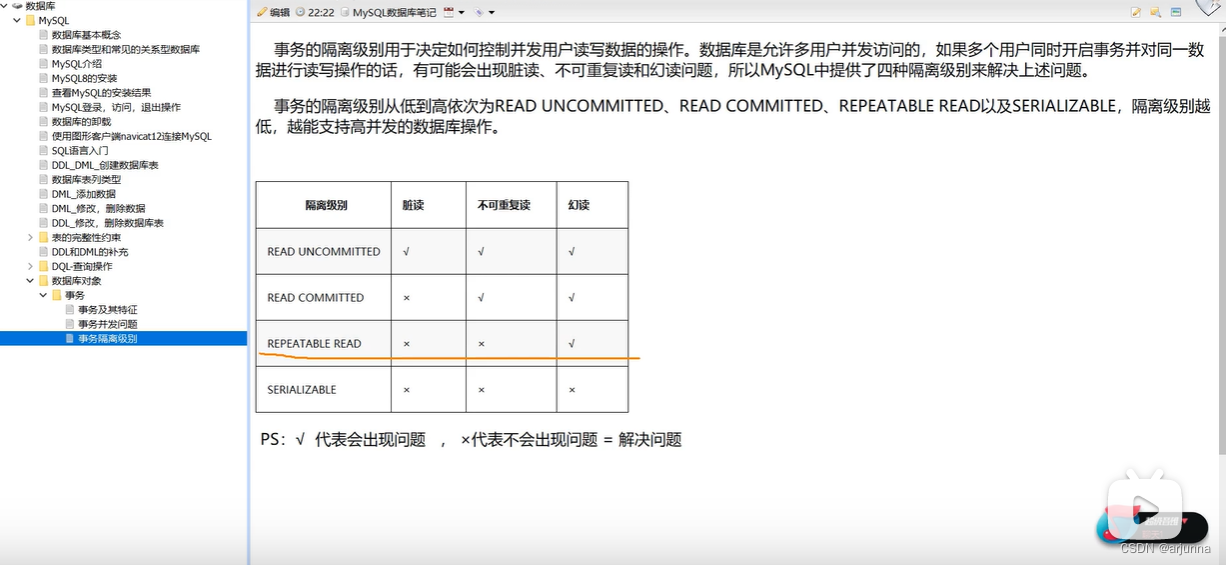
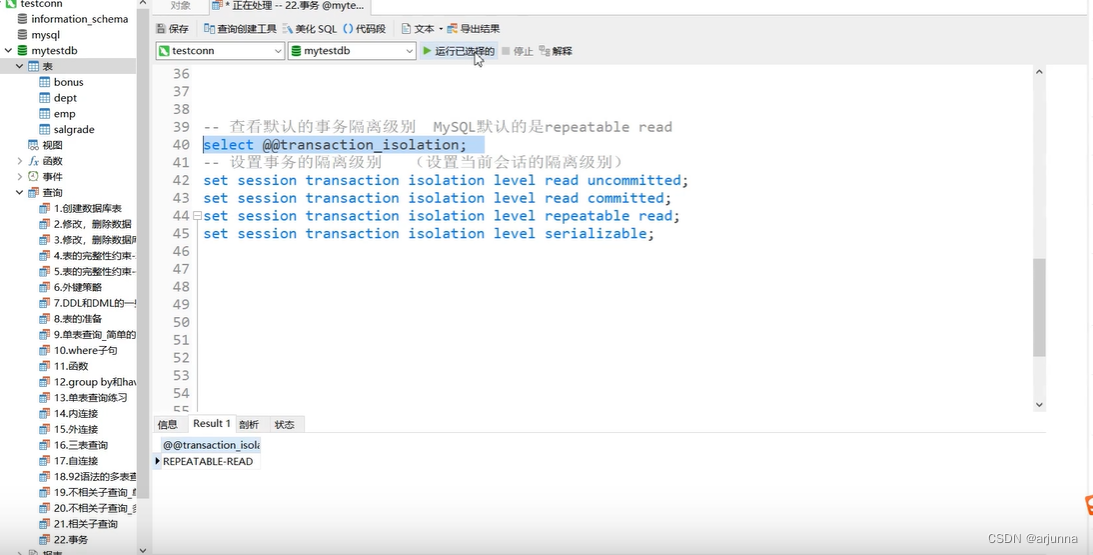
查看隔离级别 SELECT @@transaction_isolation; 先设置隔离级别(一共四个级别) set SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; 再开启事务 START TRANSACTION; 再进行操作数据
4、视图(view)
1、视图的概念
视图的本质:就是一个查询语句,是一个虚拟的表,不存在的表,你查看视图,其实就是查看视图对应的sql语句
视图是一个从单张或多张基础数据表或其他视图中构建出来的虚拟表。 同基础表一样,视图也包含了一系列带有名称的列和行数据,但是数据库中只是存放视图的定义,也就是动态检索数据的查询语句,而不是存放视图中的数据,这些数据依旧存放构建视图的基础表中。 只有当用户使用视图才去数据库请求相对应的数据,即视图中的数据是在引用视图时动态生成的,因此视图中的数据依赖于构建视图的基础表

2、视图的好处
简化用户操作:视图可以使用户将注意力集中在所关心的数据上,而不需要关心数据表的结构、与其他表的关联条件以及查询条件 对机密数据提供了保护:有了视图,就可以在设计数据库应用系统时,对不同的用户定义不同的视图,避免加密数据
3、sql展示
创建单表视图 CREATE view demo AS SELECT sid,sname,sgender,sclass FROM stu 查询视图,只显示你想展示出来的数据 SELECT * FROM demo 在视图中插入数据(此处插入数据会直接插到真实的学生表里面) INSERT INTO demo (sid,sname,sgender,sclass) VALUES(null,'韩信','男','d119'); CREATE OR REPLACE view demo(此处代码是如果不存在就创建,存在就替换) AS SELECT sid,sname,sgender,sclass FROM stu WITH CHECK OPTION(此处代码是检验) 创建多表视图: CREATE OR REPLACE view demo2 AS SELECT a.sid,a.sage,a.sname,a.sgender,a.sclass,b.cname FROM stu a JOIN city b ON a.cid=b.cid WHERE a.sage>18 SELECT * FROM demo2 创建统计视图; CREATE OR REPLACE view demo3 AS SELECT b.cname,COUNT(b.cid),AVG(sage),MIN(sage),MAX(sage) FROM stu a JOIN city b GROUP BY b.cid SELECT * FROM demo3 基于视图的视图 CREATE OR REPLACE view demo3 as select * from demo2 where sid=1;
5、存储过程
1、什么是存储过程
SQL基本是一个命令实现一个处理,是所谓的非程序语言。 在不能编写流程的情况下,所有的处理只能通过一个个命令来实现。 当然,通过使用连接及子查询,即使使用SQL单一的命令也能实现一些高级的处理,但是,其局限性是显而易见的。 例如,在sql中就很难实现针对不同条件进行不同处理以及循环等功能 这时就出现了存储过程概念:简单的说,存储过程就是在数据库中保存(stored)的一系列命令(procedure)的集合。也可以是相互之间有关系的SQL命令组织在一起的一个小程序
2、存储过程的优点
1、提高执行性能。存储过程执行效率之所以会增高,在于普通是SQL语句,每次都会对语法分析,编译,执行,而存储过程只是在第一次执行语法分析,编译,执行,以后都是对结果进行调用 2、可减轻网络负担。使用存储过程,复杂的数据库操作也可以在数据库服务器中完成,只需要从客户端(或应用程序)传递给数据库必要的参数就行,比起需要多次传递SQL命令本身,这大大减轻网络负担 3、可将数据库的处理黑匣子化。应用程序中完全不用考虑存储过程的内部详细处理,只需要知道调用哪个储存过程就可以了
定义一个没有返回值 存储过程
实现:模糊查询
创建存储过程(无返回值的函数)
CREATE PROCEDURE myprocedure(name VARCHAR(20))
BEGIN
if name is NULL or name="" then
select * from stu;
ELSE
select * from stu where sname like CONCAT('%',name,'%');
end if;
END
删除存储过程
drop PROCEDURE myprocedure
调用存储过程
call myprocedure(null)
call myprocedure('张')
创建存储过程(带返回值的函数)
参数前面的in可以省略不写
FOUND_ROWS()是mysql定义的函数,返回查询结果的条数
CREATE PROCEDURE myprocedure2(in name VARCHAR(20),out num int(3))
BEGIN
if name is NULL or name="" then
select * from stu;
ELSE
select * from stu where sname like CONCAT('%',name,'%');
end if;
SELECT FOUND_ROWS() INTO num;
END
调用函数
CALL myprocedure2(null,@num)
SELECT @num
第七章
1、什么是jdbc?
它是sun公司开发的一组接口,用于连接数据库,执行与数据库相关的各种操作
2、不同的数据库提供商对这一组接口,进行了不同的实现,称为数据库驱动
--如果使用的数据库类型不同,要导入的数据库驱动也不一样
3、在操作jdbc时,用完的资源一定要释放
释放顺序是:
1、resultset--数据结果集
2、PreparedStatement---语句执行对象
3、Connection--连接对象
1、jdbc的使用
1、创建java工程
2、创建文件夹 lib
3、导入数据库驱动 mysql-connector-java-5.1.37-bin.jar
4、构建jar到项目中
lin->右键>build path->add
5、编写测试类
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
public class demo {
/*
* 添加测试*/
public static void main(String[] args) throws Exception{
// TODO Auto-generated method stub
//1、指定数据库驱动(可省略)
Class.forName("com.mysql.jdbc.Driver");
//2、指定数据库连接信息(localhost:3306可省略)
String url="jdbc:mysql://localhost:3306/d118?useUnicode=true&characterEncoding=UTF-8";
/*String url="jdbc:mysql:///d118?useUnicode=true&characterEncoding=UTF-8";*/
//3、产生数据库连接 Connection
Connection con= DriverManager.getConnection(url,"root","123456");
//4、编写要执行的sql语句
String sql="insert into stu values(null,'海月' ,20,'女','d118','78532569856','2023-01-05',5,null)";
//5、通过连接产生sql语句执行对象,用于加载、编译、执行sql语句
PreparedStatement pst=con.prepareStatement(sql);
//6、执行语句,返回受影响的行数(执行成功的行数)
int rows=pst.executeUpdate();
if (rows>0) {
System.out.println("【执行成功】");
}else {
System.out.println("执行失败!");
}
//释放资源
pst.close();
con.close();
}
}
jdbc几个重要方法
1、Connection
数据库连接对象
作用:与数据库建立连接
产生方式:Connection con= DriverManager.getConnection(url,"root","123456");
重要方法:PreparedStatement pst=con.prepareStatement(sql);
通过连接产生sql语句的执行对象
con.close();
关闭连接
2、PreparedStatement
SQ语句执行对象
作用:用于加载、编译、执行sql语句
产生方式:PreparedStatement pst=con.prepareStatement(sql);
重要方法:pst.setObject(个数,变量)
用于给sql语句中?赋值
int rows=pst.executeUpdate();
该方法用于执行:增、删、改,但不能执行查询,它返回执行成功的行数
ResultSet rs=pst.executeQuery();
该方法用于查询,并且返回查询到的结果集
pst.close();
关闭连接
3、ResultSet
数据结果集
作用:用于保存查询的结果
产生方式:ResultSet rs=pst.executeQuery();
数据结果集的特点:
1、数据结果集是根据查询语句得到的数据生成的一个结构,包含所有查询结果
2、在数据结果集中,有一个光标,光标指向结果集中的哪一行,这一行数据才能被读取
3、一开始时,光标指向的是第一行之前的位置,这一个位置没有任何数据。
重要方法:
rs.next()------让光标向下移动一位。该方法返回的结果是一个blooean 型,如果光标可以向下移动并且能得到数据,就会返回 true,否则就会返回fasle,
/*第一种方式:用列的名称获取*/
int val=rs.getInt("列的名称");
获得光标指定的这一行,指定列的值,返回一个int型
String val=rs.getString("列的名称")
获得光标指定的这一行,指定列的值,返回一个string
/*第二种方式:用列的编号*/(编号从1开始)
int val=rs.getInt("列的编号");
int val=rs.getInt(1);
String val=rs.getString(2)
rs.close();------关闭数据集

2、基于jdbc的增删改
1、增加数据
#1、要在sql语句中拼接,如果是字符数据,必须在变量名的两边用单引号包裹起来(不推荐) String sql="insert into stu values(null,'"+name+"','"+score+"')"; #2、更加简介的方法,如果有参数可以用?占位符 String sql="insert into stu values(null,'?','?')"; //此句在中间 PreparedStatement pst=con.prepareStatement(sql); #给?动态赋值(?从1开始) pst.setString(1,name);//给第一个?赋值 pst.setInt(2,score);//给第二个?赋值 但是还有一个问题,一旦数据类型匹配错误也会报错,那么下面这种方法就解决了这个问题 #3、设置赋值时设定参数类型为obj,不管什么类型都不会报错(应用最多) pst.setobject(1,name); pst.setobject(2,score);
2、修改数据
//修改数据
int age=22;
//修改数据(把id为9的年龄该为22)
String sql="update stu set sage=? where sid=9";
//此句在中间
PreparedStatement pst=con.prepareStatement(sql);
//给?赋值
pst.setobject(1,age);
3、删除数据
//删除数据
int id=12;
//删除数据,id为12的学生信息
String sql="delete from stu where sid=?";
//此句在中间
PreparedStatement pst=con.prepareStatement(sql);
//给?赋值
//删除数据
pst.setObject(1, id);
3、基于jdbc的查询
查询全部用法:
package select;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class demo {
/*
* 读取单条数据,以及多条
* */
public static void main(String[] args) throws Exception {
//指定连接数据库信息
String url="jdbc:mysql:///d118?useUnicode=true&characterEncoding=UTF-8";
//产生数据库连接
Connection con= DriverManager.getConnection(url,"root","123456");
//执行语句
String sql="select * from stu";
//通过连接产生sql语句执行对象,加载、编译、执行sql语句
PreparedStatement pst=con.prepareStatement(sql);
//执行查询,得到数据结果集
ResultSet rs=pst.executeQuery();
------------------------------------------------单行数据
/*光标向下移动一行
rs.next();
//存数据结果集中,获得光标指定的某一行的某一列的值
int id=rs.getInt("sid");
String name=rs.getString("sname");
int age=rs.getInt("sage");
System.out.println(id+"\t"+name+"\t"+age);
这是读取单行数据的用法*/
------------------------------------------------全部数据
/*这是获得全部数据(rs.next()返回的是boolean类型,如果取不到数据会返回false)*/
while (rs.next()) {
int id=rs.getInt("sid");
String name=rs.getString("sname");
int age=rs.getInt("sage");
System.out.println(id+"\t"+name+"\t"+age);
}
rs.close();
pst.close();
con.close();
}
}
按主键查询
int id=11;
//执行语句
String sql="select * from stu where sid=?";
//通过连接产生sql语句执行对象,加载、编译、执行sql语句
PreparedStatement pst=con.prepareStatement(sql);
//给?赋值
pst.setObject(1,id);
//执行查询,得到数据结果集
ResultSet rs=pst.executeQuery();
if(rs.next()) {//此处用if,只会有一条数据
int id=rs.getInt("sid");
String name=rs.getString("sname");
int age=rs.getInt("sage");
System.out.println(id+"\t"+name+"\t"+age);
}
4、数据库的dao模式
DAO: Date Access Object(数据访问对象)
#在开发中与数据库交互的层次,称为“数据访问层”-----dao层
dao层的作用:用于执行与数据库相关操作
#dao层的命名规范:
如果是对stu表进行操作,一般会编写一个对应的实体类,用于封装stu对象的信息
例如:
数据表----stu
实体类------Stu
所在包:org.java.entity
它对应的dao类就是-----StuDao
org.java.dao
在项目中使用jdbc的基本流程:
1、创建java工程
2、导入数据库驱动 mysql-connector-java-5.1.37-bin.jar
3、将驱动构建到项目中
lin->右键>build path->add
4、创建项目的基本结构
org.java.dao
org.java.enty
org.jav.demo
5、创建实体类与数据表的结构对应
6、编写dao类
7、编写测试类
完整代码分为三部分:
1、stu实体类
2、studao交互层
3、studemo测试类
实体类
package enty;
public class Stu {
/*
* 学生实体类
* */
private int id;//编号
private String name;//姓名
private int score;//分数
public Stu() {
super();
}
public Stu(int id, String name, int score) {
super();
this.id = id;
this.name = name;
this.score = score;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
@Override
public String toString() {
return id + "\t" + name + "\t" + score ;
}
}
交互层
package dao;
import java.sql.*;
import java.util.ArrayList;
import java.util.List;
import enty.Stu;
public class StuDao {
/*
* 学生表与数据库交互层
* */
private Connection con;//数据库连接
private PreparedStatement pst;//通过连接产生sql语句,用来加载、编译、执行
private ResultSet rs;//返回的数据结果集
//编写公共方法
//连接数据库的方法
private Connection link(){
try {
//1、指定数据库驱动(可省略)
Class.forName("com.mysql.jdbc.Driver");
//2、指定数据库连接信息(localhost:3306可省略)
String url="jdbc:mysql://localhost:3306/d118?useUnicode=true&characterEncoding=UTF-8";
con=DriverManager.getConnection(url,"root","123456");
} catch (Exception e) {
e.printStackTrace();
}
return con;//返回成功连接的对象
}
//关闭连接的方法
private void close() {
try {
if (rs!=null)rs.close();
if (pst!=null)pst.close();
if (con!=null)con.close();
} catch (Exception e) {
e.printStackTrace();
}
}
//添加学生的方法
public boolean add(String name,int score) {
try {
//编写sql语句
String sql="insert into stuDemo values(null,?,?)";
//编译sql语句
pst=link().prepareStatement(sql);
pst.setObject(1, name);
pst.setObject(2, score);
return pst.executeUpdate()>0;
} catch (Exception e) {
e.printStackTrace();
}finally {
close();
}
return false;//默认添加失败
}
//修改学生的方法
public boolean update(int id,String name,int score) {
try {
//编写sql语句
String sql="update stuDemo set name=?,score=? where id=?";
//编译sql语句
pst=link().prepareStatement(sql);
pst.setObject(1, name);
pst.setObject(2, score);
pst.setObject(3, id);
return pst.executeUpdate()>0;
} catch (Exception e) {
e.printStackTrace();
}finally {
close();
}
return false;//默认修改失败
}
//删除学生的方法
public boolean delete(int id) {
try {
//编写sql语句
String sql="delete from stuDemo where id="+id;
//编译sql语句
pst=link().prepareStatement(sql);
return pst.executeUpdate()>0;
} catch (Exception e) {
e.printStackTrace();
}finally {
close();
}
return false;//默认删除失败
}
//查询全部学生
public List<Stu> selectAll() {
List<Stu> list=new ArrayList<Stu>();//创建学生集合
try {
//编写sql语句
String sql="select * from stuDemo";
//编译sql语句
pst=link().prepareStatement(sql);
rs=pst.executeQuery();
while (rs.next()) {//读取表中所有学生
Stu stu=new Stu();
stu.setId(rs.getInt(1));
stu.setName(rs.getString(2));
stu.setScore(rs.getInt(3));
list.add(stu);//将表中的学生存入到集合中
}
} catch (Exception e) {
e.printStackTrace();
}finally {
close();
}
return list;
}
}
测试类
package demo;
import java.util.List;
import java.util.Scanner;
import dao.StuDao;
import enty.Stu;
public class stuDemo {
private StuDao sdao=new StuDao();
Scanner sc=new Scanner(System.in);
/*
*
* 学生类的测试类
* */
public static void main(String[] args) {
new stuDemo().init();
}
private void init() {
System.out.println("学生管理系统");
System.out.println("1、添加学生");
System.out.println("2、查看学生");
System.out.println("3、修改学生");
System.out.println("4、删除学生");
System.out.print("请选择:");
switch (sc.nextInt()) {
case 1:
add();
break;
case 2:
show();
break;
case 3:
update();
break;
case 4:
delete();
break;
default:
System.out.println("【页面走丢了...】");
break;
}
}
private void show() {
System.out.println("******************查询学生************************");
List<Stu> list=sdao.selectAll();//接受返回的学生集合
System.out.println("编号\t名称\t成绩");
// 遍历集合
list.forEach(k->System.out.println(k));
}
public void add() {
System.out.println("******************添加学生************************");
System.out.println("请输入学生姓名及成绩(空格隔开):");
boolean flag= sdao.add(sc.next(), sc.nextInt());
if (flag) {
System.out.println("【添加成功】");
}else {
System.out.println("【添加失败】");
}
System.out.print("1、继续 2、返回上一级:");
if (sc.nextInt()==1) {
add();
}else {
init();
}
}
public void update() {
System.out.println("******************修改学生************************");
System.out.println("请输入要修改的学生id:");
int id=sc.nextInt();
System.out.println("请输入该学生的新名字:");
String name=sc.next();
System.out.println("请输入该学生的新成绩:");
int score=sc.nextInt();
boolean flag=sdao.update(id, name, score);
if (flag) {
System.out.println("【修改成功】");
}else {
System.out.println("【修改失败】");
}
System.out.print("3秒后返回主界面...");
try {
Thread.sleep(3000);
init();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public void delete() {
System.out.println("******************删除学生************************");
System.out.println("请输入要修改的学生id:");
int id=sc.nextInt();
boolean flag=sdao.delete(id);
if (flag) {
System.out.println("【删除成功】");
}else {
System.out.println("【删除失败】");
}
System.out.print("3秒后返回主界面...");
try {
Thread.sleep(3000);
init();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
5、jdbc常见错误
com.mysql.jdbc.Driver-------驱动包没有构建到项目中 no value specified for parameter 2---第二个?没有赋值 access denied for user 'root'@'localhost----密码错误 communications link failure -------mysql服务没有开启
第八章
数据库连接池的使用-----使用jdbctemplate模板简化数据库操作
1、数据库连接池的使用
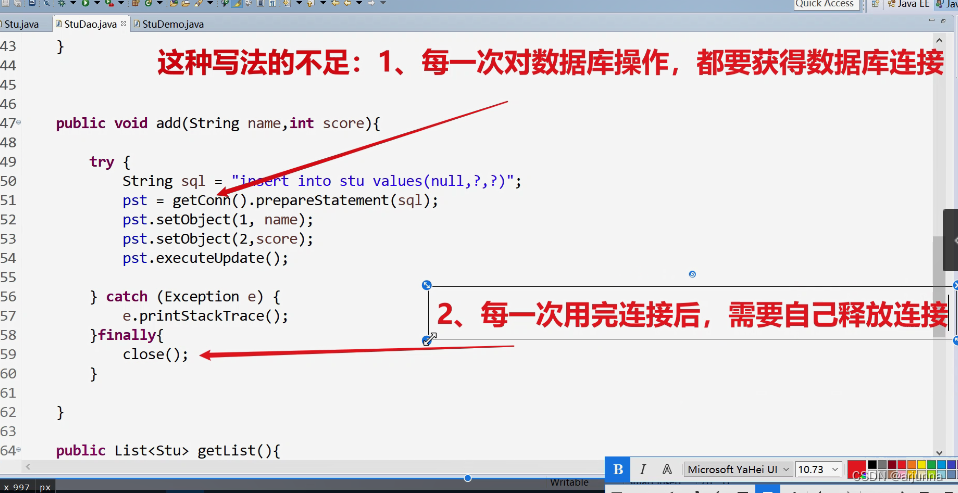
为了解决频繁创建连接,频繁销毁连接的问题,jdbc提供一种“”数据库连接池的机制
#数据库连接池的特点:
配置好数据库连接池后,系统会提前创建一定数量的链接,放在连接池中。
关闭时,数据库连接并不会真的销毁,而是回到连接池中,其他用户可以继续使用
#连接池解决了:数据库连接对象可以重复使用的问题(提高性能)
initialSize=5
#初始连接数,程序一启动,就会向内存中的连接池放入5个数据库连接
maxActive=10
#最大连接数
maxWait=3000 (毫秒)
#如果连接池的连接数已经到达最大值,就不会再产生新的连接,此时如果需要连接数据库, 就 需要等待其他用户将用完的连接进行释放
#当调用连接对象的close方法,连接 就会回到连接池中
数据库连接池的分类:
dbcp c3p0,druid
目前使用最好的是阿里巴巴的druid连接池
druid:德鲁依连接池的测试
1、创建java工程
2、导入druid的相关jar(依赖) druid-1.0.9.jar以及mysql-connector-java-5.1.37
3、创建一个源文件夹 sourceFolder命名为:conf,用于存储配置文件
配置文件 druid.properties
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql:///d118
username=root
password=123456
initialSize=5
maxActive=10
maxWait=5000
4、编写测试类

测试代码:
package demo;
import java.io.InputStream;
import java.sql.Connection;
import java.util.Properties;
import javax.sql.DataSource;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.pool.DruidDataSourceFactory;
public class firstDemo {
public static void main(String[] args) throws Exception{
//1、加载指定的属性文件,获得输入流
InputStream in=firstDemo.class.getClassLoader().getResourceAsStream("druid.properties");
//2、创建一个属性类,用于记载输入流的配置信息
Properties pro=new Properties();
//3、属性类从输入流中加载配置信息
pro.load(in);
//4、产生druid数据源(数据连接池)(pool结尾的)
DataSource ds= DruidDataSourceFactory.createDataSource(pro);
//5、通过连接池,获得连接
for (int i = 0; i <10; i++) {
Connection con=ds.getConnection();
System.out.println(i+"----"+con);
con.close();//返回连接池
}
}
}
2、jdbctemplate
数据库连接池可以提升程序性能
如何简化jdbc的操作? 后期我们会学习一些持久层的框架来简化数据库操作,例如:mybatis,tkmybatis,mybatis-plus 现阶段我们可以使用jdbctemplate模板机制简化数据库操作 jdbctemplate是spring框架提供的一种简化jdbc操作的持久层技术,目前我们只是采用jdbctemplate简化数据库操作,不涉及到任何spring知识点
jdbctemplate模板的使用步骤:
1、创建java工程
2、导入依赖(jar)
1、mysql
2、druid
3、springjdbc
3、创建源文件夹放配置文件 sourceFolder命名为:conf,用于存储配置文件
4、将druid.properties导入到源文件夹中 ->conf
5、编写一个jdbcytil工具类,用于产生druid连接池(只需要编写一次,以后复制就可以了)
org.java.demo
org.java.entity
org.java.dao
org.java.util--------->工具包
6、编写实体类与数据表结构对应
7、编写dao层
8、编写测试类
创建工具类
package util;
import java.io.InputStream;
import java.util.Properties;
import javax.sql.DataSource;
import com.alibaba.druid.pool.DruidDataSourceFactory;
/*
* jdbc工具类,用于产生数据源
*
* */
public class JdbcUtil {
//数据源
private static DataSource ds;
//静态块,一加载创建连接池
static {
try {
//创建输入流,加载指定属性文件
InputStream in=JdbcUtil.class.getClassLoader().getResourceAsStream("druid.properties");
//创建属性类
Properties pro=new Properties();
//加载输入流中的配置信息
pro.load(in);
//关闭流
in.close();
//产生数据源
ds=DruidDataSourceFactory.createDataSource(pro);
} catch (Exception e) {
e.printStackTrace();
}
}
//静态方法调用该方法,即可获得数据源
public static DataSource getDs() {
return ds;
}
}
dao层
package dao;
import java.util.List;
import org.springframework.jdbc.core.BeanPropertyRowMapper;
import org.springframework.jdbc.core.JdbcTemplate;
import enty.Stu;
import util.JdbcUtil;
public class stuDao {
/*
* 使用jdbctemplate模板创建的dao类
*
* */
//创建jdbctemplate
private JdbcTemplate jt=new JdbcTemplate(JdbcUtil.getDs());
//添加的方法
public void add(String name,int score) {
String sql="insert into stuDemo values(null,?,?)";
//执行sql语句(增删改都是同一个方法,只是语句不同)
jt.update(sql,name,score);
}
//修改的方法
public void update(Integer id,String name,int score) {
String sql=("update stuDemo set name=?,score=? where id=?");
//执行sql语句(增删改都是同一个方法,只是语句不同)
jt.update(sql,name,score,id);
}
//删除的方法(返回受影响行数,大于0说明删除成功)
public boolean del(Integer id) {
String sql=("delete from stuDemo where id=?");
//执行sql语句(增删改都是同一个方法,只是语句不同)
return jt.update(sql,id) >0;
}
//查询全部
public List<Stu> selAll() {
String sql="select * from stuDemo";
//返回时,只需要指定每一条数据要封装成什么类型的对象进行返回
return jt.query(sql, new BeanPropertyRowMapper<>(Stu.class));
}
}
1、查询全部(返回的list集合)
//增删改的方法只需要该查询语句就可以,关键的是查询
jt.query()---------它的返回结果一定是List<对象>
jt.query(执行语句,返回类型,参数1,参数2)
jt.queryForObject---该方法返回一个对象
jt.queryForList()-------他返回的类型是一个List<Map>
jt.queryForMap()-------他返回的类型是一个Map
//如果是单表操作,一般List<stu>这种方式,可读性好
//如果是多表操作,一般list<map>这种方式更方便
//查询全部
1、要把查询到的一条记录中所有字段赋值给对象中的属性,要求如下:
字段名需要与属性名相同
public List<Stu> selAll() {
String sql="select * from stuDemo";
//返回时,只需要指定每一条数据要封装成什么类型的对象进行返回
return jt.query(sql, new BeanPropertyRowMapper<>(Stu.class));
2、而当字段名与属性名不同时,可以起别名来解决此问题
public List<Stu> selAll2() {
//联合stu表和score成绩表 起的别名与属性名一致也能运行成功
String sql="select a.sid id,sname name,b.socres score from stu a,score b where a.sid=b.sno";
//返回时,只需要指定每一条数据要封装成什么类型的对象进行返回
return jt.query(sql, new BeanPropertyRowMapper<>(Stu.class));
3、如果字段名中包含下划线,在将字段值赋值给属性时,系统将会把下划线去掉,然后将下划线首字母大写 例如数据库中字段名是stu_id,而当印射时系统会自动变成stuId(stu_id---->stuId)
2、根据id查询(返回的对象)
//根据id查询(如果没找到,返回null)
public Stu selId(int id) {
//用聚合查询来判断是否存在该id
//查询总人数
String sql="select count(*) from stuDemo where id=?";
//得到执行成功的行数
int rows=jt.queryForObject(sql, Integer.class,id);
if (rows==0) {
//说明不存在,返回空值
return null;
}else {
sql="select * from stuDemo where id=?";
//返回时,只需要指定每一条数据要封装成什么类型的对象进行返回
return jt.queryForObject(sql, new BeanPropertyRowMapper<>(Stu.class),id);
}
}
---------------测试类
//根据id查找
System.out.println(selId(1));
3、查询总人数
//聚合查询
public int selCount() {
//查询总人数
String sql="select count(*) from stuDemo ";
//返回的是一个数值
return jt.queryForObject(sql, Integer.class);
}
-----测试类
//查询总人数
System.out.println("学生总人数:"+selCount());
4、模糊查询
//带条件查询(模糊查询)
public List<Stu> selCondition(String name,int score) {
//查询stu表中所有带有参数name的姓名,以及分数在参数score以上的
String sql="SELECT * FROM studemo where name LIKE ? AND score>=? ";
return jt.query(sql, new BeanPropertyRowMapper<>(Stu.class),"%"+name+"%",score);
}
---测试类
//模糊查询
List<Stu> list=selCondition("三", 50);
list.forEach((k)->System.out.println(k));
5、查询全部(返回的map集合)
//将查询结果封装成map集合返回
public List<Map<String, Object>> selAllMap() {
//将个查询到的每一条数据,封装成map
String sql="select * from stuDemo";
return jt.queryForList(sql);
}
----测试类
//查询全部,返回的map
List<Map<String, Object>> list=selAllMap();
list.forEach((k)->System.out.println(k));
6、 根据id查询(返回的是map集合)
//根据id查询,返回的是map集合
public Map selId2(int id) {
String sql="select count(*) from stuDemo where id=?";
int rows=jt.queryForObject(sql, Integer.class,id);
if (rows==0) {
return null;
}else {
sql="select * from stuDemo where id=?";
return jt.queryForMap(sql,id);
}
}
---测试类
System.out.println(selId2(2));
7、多表联合查询(返回map集合)
//使用map多表连接
public List<Map<String, Object>> selAllMap2() {
//连接stu表,score表,city表,course表
String sql="SELECT a.sid id,a.sname name,c.cname cla,b.socres score,d.cname city FROM stu a,score b,course c,city d WHERE a.sid=b.sno AND b.cid=c.cid AND a.cid=d.cid";
return jt.queryForList(sql);
}
-----测试类
//查询全部2,返回四个表的联合查询
List<Map<String, Object>> list=selAllMap2();
list.forEach((k)->System.out.println(k));
优化多表查询
//这条sql语句太过繁琐 String sql="SELECT a.sid id,a.sname name,c.cname cla,b.socres score,d.cname city FROM stu a,score b,course c,city d WHERE a.sid=b.sno AND b.cid=c.cid AND a.cid=d.cid"; //我们可以创建先视图,而后对视图进行查询也一样 /*这是创建视图的语句 CREATE VIEW stuView AS SELECT a.sid id,a.sname name,c.cname cla,b.socres score,d.cname city FROM stu a,score b,course c,city d WHERE a.sid=b.sno AND b.cid=c.cid AND a.cid=d.cid */ //这是已经创建好的视图,我们直接引用,同样我们也可以对视图进行带条件查询 String sql="select * FROM stuView";