在使用IDE开发STM32程序时,IDE一般都会提供优化等级设置的选项,例如下图中KEIL软件优化等级的设置。
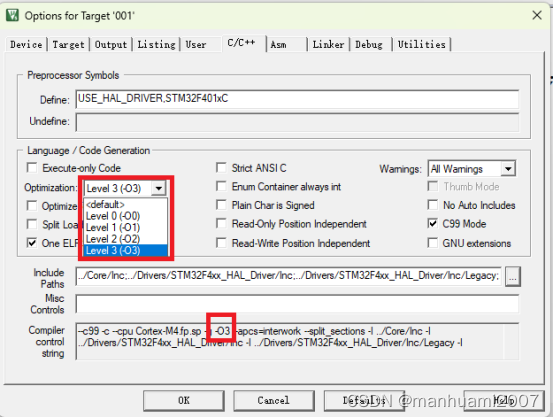
从上图中也可以看出,设置不同的优化等级,实际上是修改了编译器的编译参数。这个编译器是由ARM公司提供的C/C++编译器armclang或者armcc。编译器提供了不同的优化等级,能够优化由用户代码生成的目标代码。这里的优化主要针对4个方面:
- 代码的运行效率
- 生成的目标代码的体积
- 调试信息是否完整准确
- 生成目标代码的构建时间长短
针对以上4点,编译器提供了不同的参数,以满足不同的需求,见下表所示

从上表可知,在keil软件中能够选择的O0、O1、O2和O3,针对的是目标代码的运行效率,等级越高,对目标代码的优化就越多,运行效率就越高。不过在提高了运行效率的同时,会使其它几个方面的变差,比如会增加目标代码的体积、调试信息失真,以及需要更长的编译时间。
下面针对O0、O1、O2和O3这几个等级,分别介绍它们的特点和区别。(部分涉及到编译优化方法的名词会在最后的附录中进行解释,遇到不理解的名词可以查看文章最后的附录)
O0等级
该等级为最小的优化等级,关闭了大多数的优化措施。这种情况生成的固件和用户编写的代码几乎是对应的,因此用户在调试代码的时候,能够根据源代码更快的定位到编译后的位置。
在O0这个优化等级下,不会对代码进行优化,不会删除用户的死代码(dead code,死代码指的是编写了但是没有用到的代码,也包括不起作用的代码),不会删除没有使用的变量,能够读到各个函数完整的栈信息(不理解这句话的,可以向下看O1等级的第4条,对比一下就理解了)。
O1等级
该等级实现受限的优化。在这个模式下会对用户代码进行优化,同时尽量不影响用户的调试信息。与O0的不同之处如下:
- 调试的断点不能设置到死代码上,因为死代码会被优化掉;
- 有的临时变量,虽然还在其作用域中,但是也会被清除,比如这个变量在后面没有再用到,而且其所在的栈的位置被调用的子函数占用了,那么在返回时这个变量可能不会恢复。
- 死代码也就是没有作用的代码会被移除,比如没有被调用的函数,或者这个函数对外部没有任何影响的(no side-effects ),以下面这个代码为例,这个函数用到的全是临时变量,而且也没有返回值的,那么这个函数就不会对外接产生任何影响,也就认为没有任何作用,就会被优化掉。
void add_fake(){
int a=1,b=2;
int c = a+b;
}
- 由于尾调用的存在,回溯(backtrace)可能无法提供从源代码阅读中期望的函数调用栈。尾调用如下面的代码中语句return add(a,b),这个语句就是尾调用,尾调用是一种在函数末尾直接调用另一个函数的优化技术,它的特点是当前函数在调用另一个函数后不会保留任何上下文或返回地址,而是直接跳转到被调用函数的执行。在支持尾调用优化的编程语言或环境中,这种优化可以减少栈帧的数量,提高程序的执行效率。然而,正因为尾调用优化的存在,当程序出现错误或需要回溯时,传统的回溯技术可能无法准确地展示函数调用的完整栈。这是因为尾调用不会创建新的栈帧,而是重用了当前栈帧,这可能导致回溯结果中缺少某些函数调用的信息,或者函数的调用顺序看起来与源代码中的顺序不符。
void test(){
int a=1,b=2;
return add(a,b);
}
在这个优化等级下,进行的优化比较少,主要是针对死代码和没有用的变量进行了优化,生成的目标代码的结构和源代码区别不大,因此对用户的调试没多大影响。而且因为O1删除了死代码,因此其生成的代码体积要小于O0等级的。
O2等级
高等优化。这个等级优化后的目标代码和源代码不会一一对应,这是因为使用了类似于循环展开、程序内联、常量折叠、公共子表达式消除、死代码消除、向量化等编译优化措施,优化了生成的代码结构。因此在调试的时候可能会发现无法很好的定位到源代码对应的目标代码的位置,不利于对源代码的调试。O2等级使用了O1等级的所有优化方法,同时还使用了:
- 由于源代码中的多个位置可能映射到目标代码中的同一个点,以及编译器可能进行的更激进的指令调度,源代码到目标代码的映射可能是多对一的关系。这意味着从目标代码回溯到源代码可能不是直接的或明确的。
- 编译器在优化过程中进行的指令调度,如果允许跨越序列点,可能会导致在特定点报告的变量值与直接从源代码中预期的值之间存在不匹配。因此在分析编译后的代码或调试程序时,需要特别注意编译器优化可能引入的这种复杂性。
- 编译器会自动内联函数。
O3等级
这个等级会对用户代码进行最大的优化。这个等级下的优化除了包含O2等级的优化,还包含:
- 通过包括循环展开在内的高级标量优化,可以在较小代码尺寸代价下获得显著的性能提升。通过循环展开和其他高级标量优化,通常可以获得显著的性能提升,因为减少了循环控制和分支预测的开销,并可能提高了数据访问的局部性。但也会增加编译生成目标代码的构建时间。这要求开发者在权衡性能提升和构建时间之间做出决策。
- 更激进的内联和自动内联。编译器会更加积极地选择更多的函数进行内联,而不仅仅是那些显然可以带来性能提升的函数。这种更激进的做法可能会增加代码的大小,但通常可以带来更好的性能。编译器通常会基于一系列因素(如函数大小、调用频率、函数的复杂度等)来决定是否要进行内联。
编译器对代码的优化,会使目标代码的结构和源代码的结构相差很大,因此使得用户在通过源代码进行调试的时候,有更糟糕的体验。因此ARM公司不推荐在这种优化等级下使用调试功能。
总结
从上面的内容可以知道,更高的优化等级会使用更多的编译优化技术,对用户的源代码进行优化,从而使得生成的目标代码的结构与源代码的结构区别很大,这样就不利于用户对代码的调试。
因此在前期编写代码时,最好将优化等级设置为O0和O1,这样能够更方便的进行调试,相比于O0,ARM公司更推荐使用O1等级,因为O1等级会进行一部分优化而且对调试影响不大。而后期要交付产品的时候,为了追求代码的运行效率,可以将优化等级调整到O2和O3。
附录-常用的编译优化手段
在上面的文章中,提到了很多的编译优化方法,平时没接触处过编译的知识,所以会不好理解,下面对上面提到的优化方法,以及一些其它的常用优化方法进行列举和解释。
- 尾调用是一种在函数末尾直接调用另一个函数的优化技术,它的特点是当前函数在调用另一个函数后不会保留任何上下文或返回地址,而是直接跳转到被调用函数的执行。在支持尾调用优化的编程语言或环境中,这种优化可以减少栈帧的数量,提高程序的执行效率。然而,正因为尾调用优化的存在,当程序出现错误或需要回溯时,传统的回溯技术可能无法准确地展示函数调用的完整栈。这是因为尾调用不会创建新的栈帧,而是重用了当前栈帧,这可能导致回溯结果中缺少某些函数调用的信息,或者函数的调用顺序看起来与源代码中的顺序不符。
- 源代码到目标代码的映射:在编译过程中,源代码(即程序员编写的代码)会被转换成目标代码(即机器可以直接执行的代码)。这种转换通常是通过一系列步骤完成的,包括词法分析、语法分析、语义分析、优化和代码生成等。
- 多个源代码位置映射到一个目标代码点:这通常发生在编译器进行优化时。例如,某些在源代码中明显分开的操作可能在目标代码中合并成一个。或者,源代码中的某些变量或常量可能在编译时被优化或消除,导致它们在目标代码中不再有明显的对应。
- 指令调度是编译器优化技术的一种,其主要目的是重新排列指令以提高执行效率。更激进的指令调度可能意味着编译器会更大胆地重新排列或合并源代码中的指令,以生成更高效的目标代码。这同样可能导致源代码和目标代码之间的映射关系变得复杂。
- 指令调度允许跨越序列点:在编译过程中,指令调度是一种优化技术,用于重新安排程序中指令的执行顺序,以改善程序性能。序列点(sequence points)是程序中特定的点,在这些点上,所有之前的副作用(如变量值的改变)都必须完成,并且这些变化对后续代码可见。然而,在某些情况下,编译器可能会进行更激进的优化,允许指令跨越这些序列点进行调度。
- 可能导致变量值的不匹配:当指令调度跨越序列点时,这可能会导致在源代码中看起来应该按特定顺序执行的操作在实际的目标代码中不再保持这个顺序。因此,如果在某个特定点检查一个变量的值,可能会发现该值与从源代码直接阅读时所期望的值不匹配。
- 内联函数(Inline Function)是一种编译器优化技术,用于减少函数调用的开销。当一个函数被声明为内联时,编译器会尝试在调用该函数的地方直接插入(或“内联”)该函数的代码,而不是进行常规的函数调用。这可以消除函数调用的开销,包括参数传递、栈帧的创建和销毁等,从而可能提高程序的执行效率。当编译器“自动内联函数”时,它会自动决定哪些函数应该被内联,而不需要程序员显式地指定。这通常基于函数的尺寸、调用频率和其他一些因素。需要注意的是,过度使用内联可能会导致代码膨胀,从而可能增加指令缓存的未命中率和其他负面影响,所以编译器在内联函数时会进行权衡。同时,有些函数可能不适合内联,例如那些有循环或复杂控制流的函数。因此,尽管编译器可以自动内联函数,但程序员仍然需要了解内联的优缺点,并在必要时通过编译器选项或特定的代码标记来控制内联行为。
- 高级标量优化:标量优化是针对单个变量或数据项的优化,而不是针对向量或数组。高级标量优化通常涉及复杂的算法转换和代码变换,以改进程序的执行效率。
- 循环展开:循环展开是一种常用的优化技术,它通过减少循环次数并复制循环体中的代码,来减少循环的控制开销。例如,一个原本执行四次迭代的循环可以被展开成四份独立的代码,每份代码执行一次原循环体中的操作。
- 常量折叠:在编译时,如果编译器能够确定某个表达式的结果是一个常量,那么它会在编译时直接计算出这个常量值,并将其替换到代码中的相应位置。
- 常量传播:如果一个变量的值在编译时已知且是常量,编译器可能会用这个常量值替换掉所有对该变量的引用。
- 公共子表达式消除:如果一个表达式在程序中多次出现,并且每次出现时其值都没有变化,编译器会识别出这是一个公共子表达式,并只计算一次,存储结果,然后在需要的地方使用这个存储的结果。
- 死代码消除:编译器会检测代码中永远不会被执行的部分(死代码),并将其从最终的可执行文件中移除。
- 复写传播:编译器会识别出两个或多个变量实际上持有相同的值,并用一个变量来替换它们。
- 指令重排:编译器会重新排列指令的顺序,以减少数据依赖、提高缓存利用率或利用处理器的指令并行能力。
- 寄存器分配:编译器会智能地为变量分配寄存器,以减少内存访问次数,提高程序性能。
- 轮廓分析(Profile Guided Optimization):编译器使用程序运行时的轮廓信息(例如,哪些代码路径被频繁执行)来指导优化过程。这通常涉及到在程序运行时收集数据,并在后续的编译过程中使用这些数据。
- 类型优化:编译器可能会利用类型信息来优化代码,例如通过减少不必要的类型转换或使用特定的指令集来优化特定类型的数据处理。
- 向量化和并行化:编译器会尝试将代码转换为向量操作(即一次处理多个数据元素),并利用多核处理器进行并行处理,以提高计算密集型任务的性能。







![[Java]线程生命周期与线程通信](https://img-blog.csdnimg.cn/direct/4f64d89615ac435aa43328fa42559192.png)