从 HTML 文件中提取文本内容是数据抓取中的一个常见任务,你可以将提取的文本信息用于编制报告、进行数据分析或其他处理。本文分享如何使用免费 Java API 从HTML 文件中提取文本内容。
安装免费Java库:
要通过Java提取HTML文本,需要用到Free Spire.Doc for Java免费库。以下提供两种安装方式:
1. 通过Maven仓库安装:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.cn/repository/maven-public/</url>
</repository>
</repositories>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc.free</artifactId>
<version>5.2.0</version>
</dependency>2. 下载Free Spire.Doc for Java库,解压后手动将Spire.Doc.jar添加到程序中。
使用Java从HTML文件中提取文本内容
基本步骤:
- 导入需要的类库;
- 通过 loadFromFile() 方法加载HTML文件;
- 通过 getText() 方法获取HTML文件中的文本内容。
- 创建一个 FileWriter 对象,将提取的文本内容写入一个txt文件中
示例代码:
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import java.io.FileWriter;
import java.io.IOException;
public class ExtractTextFromHTML {
public static void main(String[] args) throws IOException {
//创建Document对象
Document doc = new Document();
//加载一个HTML文件
doc.loadFromFile("input.html", FileFormat.Html);
//获取HTML文件中的文本
String text = doc.getText();
//将文本写入TXT文件
FileWriter fileWriter = new FileWriter("提取HTML文本.txt");
fileWriter.write(text);
fileWriter.close();
}
}
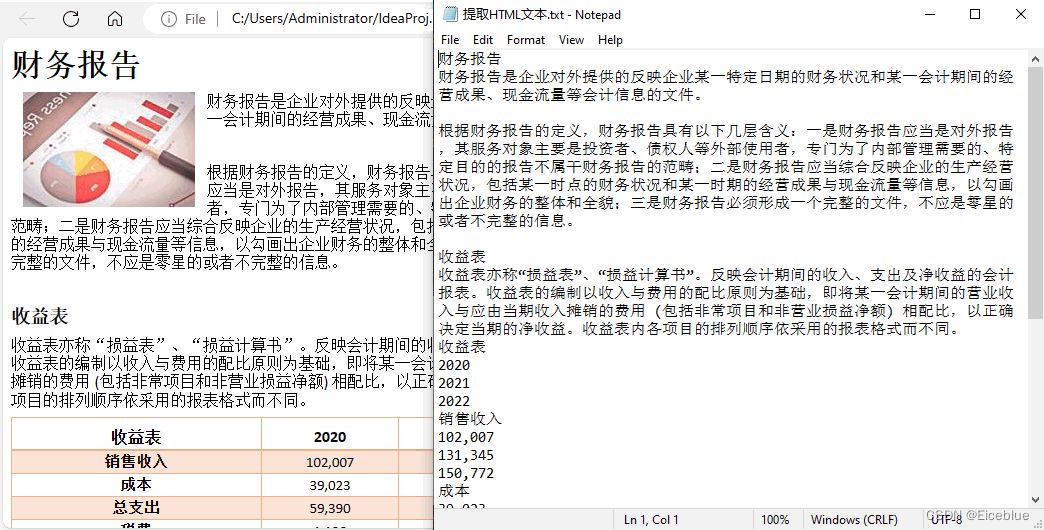
运行结果 :
参考文章:
Java: Extract Text from HTMLUse Spire.Doc for Java to extract text from an HTML file or a URL easily, without the need for any third-party libraries.![]() https://www.e-iceblue.com/Tutorials/Java/Spire.Doc-for-Java/Program-Guide/Conversion/Java-Extract-Text-from-HTML.html在实际应用中,有问题可前往论坛讨论。
https://www.e-iceblue.com/Tutorials/Java/Spire.Doc-for-Java/Program-Guide/Conversion/Java-Extract-Text-from-HTML.html在实际应用中,有问题可前往论坛讨论。