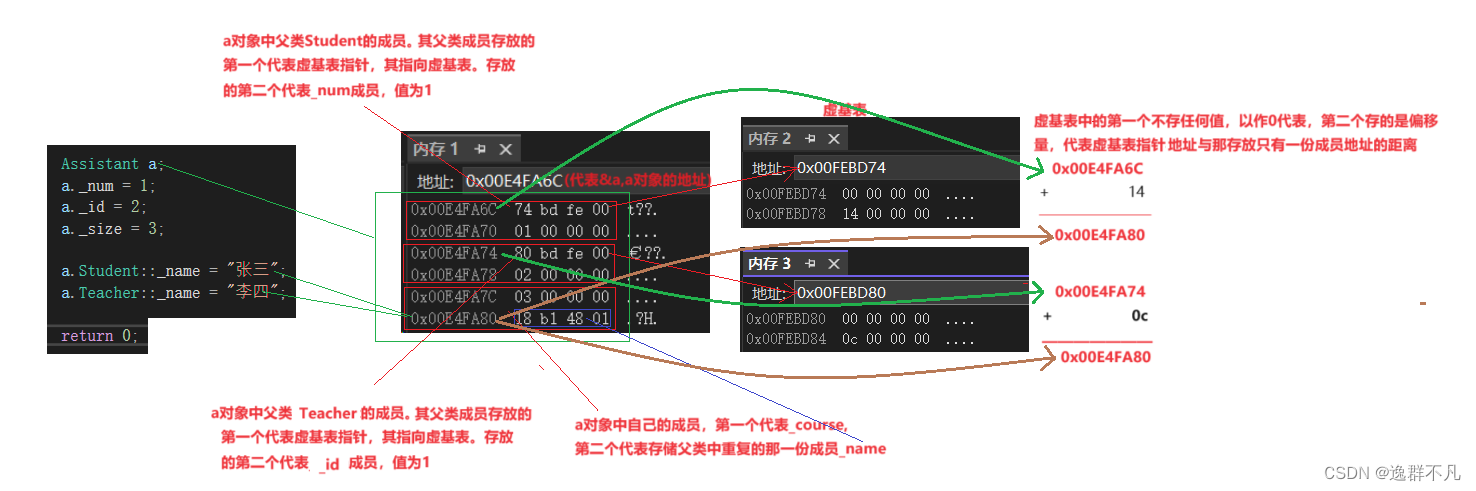
Aurora 8B/10B IP 支持 Kintex®
-7, Virtex
®
-7 FPGA GTP 和 GTH 收发器,Artix
®
-7 FPGA GTP 收发器, Zynq®
-7000 GTP and GTP 收发器。Aurora 8B/10B IP core 可以工作于单工或者全双工模式。IP CODE的使用也非常简单,支持 AMBA®总线的 AXI4-Stream 协议。

Aurora 8B/10B IP core 具备很多优点,当一条通道联通的时候,它会自动初始化这条通路,并
且以帧或者数据流的方式,发送一些测试数据。而且在正常通信的过程中,可以发送任意大小的帧,以及数据可以再任何时候中断。传输过程中有效数据字节之间的间隙会自动填充空闲,以保持锁定并防止过多的电磁干扰。流量控制可用于降低传入数据的速率或通过通道发送简短的高优先级消。Stream 流传输是单一的,无限的帧。 在没有数据的情下,传送空闲以保持链接活着。 Aurora 8B/10B 内核使用 8B/10B 编码规则检测单位和大多数多位错误。 过多的位错误,断开连接或设备故障导致内核复位并尝试重新初始化新通道。
Aurora 8B/10B IP 的用途:
1)、芯片到芯片的链路:
替换高速串行连接的芯片之间的并联连接可以显着减少 PCB 上所需的迹线和层数。 核心提供
了使用 GTP,GTX 和 GTH 收发器所需的逻辑,FPGA 资源成本最低。
2)、板对板和背板连接:
IP CORE 使用标准的 8B / 10B 编码,使其与现有的电缆和背板硬件标准兼容。 Aurora 8B / 10B
内核可以在线速率和通道宽度上进行缩放,以便在新的高性能系统中使用便宜的传统硬件。
3)
、单向连接(单向):
Aurora 协议提供了替代方法执行单向通道初始化,使 GTP,GTX 和 GTH 收发器在没有反向通道
的情况下使用,并降低由于未使用的全双工资源而造成的成本。

Lane Logic(通道逻辑):
每个 GTP,GTX 或 GTH 收发器(以下称为收发器)由通道逻辑模块的实例驱动,其初始化每个
单独的收发器并处理控制字符的编码和解码以及错误检测。
Global Logic(全局逻辑):
全局逻辑模块执行通道初始化的绑定和验证阶段。 在运行期间,模块会生成 Aurora 协议所需
的随机空闲字符,并监视所有通道逻辑模块的错误。
RX User Interface(RX 接收端口):
AXI4-Stream RX 接收端口将数据从通道移动到应用程序,并执行流量控制功能。
TX User Interface(TX 发送端口):AXI4-Stream TX 发送端口将数据从应用程序移动到通道,并执行流量控制 TX 功能。 标准时钟补偿模块嵌入在内核中。 该模块控制时钟补偿(CC)字符的周期性传输。
Latency(延迟):
通过 Aurora 8B/10B 内核的延迟是由通过协议引擎(PE)和收发器的流水线延迟引起的。 随
着 AXI4-Stream 接口宽度的增加,PE 流水线延迟增加。 收发器延迟取决于所选收发器的特性和属性。本节概述了 Aurora 8B/10B 核 心 AXI4-Stream 用 户 端 口 对 于 2-byte-per-lane 和
4-byte-per-lane 设计的 user_clk 周期的预期延迟。 为了说明延迟,Aurora 8B/10B 模块被分为收
发器逻辑和协议引擎(PE)逻辑,其在 FPGA 可编程逻辑中实现。
注意:这些数字不包括由于 Aurora 8B / 10B 通道的每一侧之间的串行连接长度而引起的延迟。
下图说明了默认配置的数据路径的延迟。延迟可以根据设计中使用的收发器和 IP 配置而有所不同。

从s_axi_tx_tvalid到m_axi_rx_tvalid的两字节成帧设计的最小延迟在默认核心配置的功能
仿真中大约为 37 个 user_clk 周期如下图所示

从s_axi_tx_tvalid到m_axi_rx_tvalid的默认四字节帧设计的最小延迟在功能仿真中大约为
41 个 user_clk 周期。 流水线延迟被设计为保持时钟速度。如果没有依赖关系,请检查延迟是否可以通过其他可选功能添加。
Throughput(吞吐量):
Aurora 8B/10B 核心吞吐量取决于收发器的数量和线速度。 单通道设计到 16 通道设计的吞吐
量分别为 0.4Gb/s 到 84.48Gb/s。 通过 Aurora 8B/10B 协议编码和 0.5Gb/s 至 6.6 Gb/s 线路速率范围的 20%开销来计算吞吐量。












![[Android]引导页](https://img-blog.csdnimg.cn/direct/ccdb8bf0faee443893f71e8339b0b78c.png)