目录
一、len函数的常见应用场景:
二、len函数使用注意事项:
三、如何用好len函数?
1、len函数:
1-1、Python:
1-2、VBA:
2、推荐阅读:
个人主页:神奇夜光杯-CSDN博客

一、len函数的常见应用场景:
len函数在Python中非常常用,它可以帮助我们获取各种数据类型的长度或大小,常见的应用场景有:
1、字符串处理:当你需要知道一个字符串的长度时,可以使用len()函数,这在验证用户输入、处理文本数据或进行字符串操作时非常有用。
2、列表和元组操作:当你需要知道一个字符串的长度时,可以使用len()函数,这在验证用户输入、处理文本数据或进行字符串操作时非常有用。
3、字典操作:字典是Python中存储键值对的数据结构,len()函数可以用于获取字典中的键值对数量,这在统计字典大小或进行迭代操作时非常有用。
4、集合操作:集合用于存储唯一的元素,使用len()函数可以方便地获取集合中元素的数量,这在检查集合大小、比较集合或进行集合运算时非常有用。
5、自定义对象:如果你创建了自定义对象,并希望len()函数能够返回该对象的某种属性或状态的“长度”,你可以在自定义类中实现`__len__()`方法。
6、文件和输入/输出:在处理文件或进行输入/输出操作时,len()函数可以用来获取读取或写入的数据长度,这对于监控数据传输、检查文件大小或进行数据处理时非常有用。
7、循环和迭代控制:在循环中,有时候需要根据序列的长度来控制循环的次数,len()函数在这里可以发挥重要作用。
8、动态分配空间:在某些需要动态分配空间的情况下,如创建特定长度的列表或数组时,len()可以用于预先知道需要多少空间。
9、调试和日志记录:在开发过程中,len()函数可以用于调试,帮助开发者了解数据的大小或结构;同时,它也可以用于日志记录,记录数据的大小变化。
10、性能分析和优化:在性能分析和优化过程中,了解数据结构的大小可以帮助你确定算法的效率,使用len()函数可以方便地获取数据的大小,从而进行性能分析和比较。
11、结合其他函数和方法使用:len()函数可以与Python中的其他函数和方法结合使用,以实现更复杂的操作。例如,你可以使用len()与条件语句、循环结构、列表推导式等结合,以完成各种任务。
总之,len()函数在Python编程中的应用非常广泛,几乎在任何需要知道对象大小或长度的场景中都可以使用。

二、len函数使用注意事项:
在Python中使用len()函数时,有一些注意事项需要牢记,以确保正确使用并避免潜在的问题。以下是一些关键的注意事项:
1、数据类型支持:len()函数只适用于那些定义了`__len__()`方法的对象,这通常包括序列类型(如字符串、列表、元组、字节和字节数组)和集合类型(如字典、集合和冻结集合),如果你尝试对不支持长度计算的对象使用len()函数,将会引发TypeError异常。
2、返回值类型:len()函数始终返回一个整数,表示对象的长度或元素数量,如果对象没有长度(例如整数或浮点数),则不能使用len()函数。
3、对象的实时状态:len()函数返回的是对象在调用时的长度或大小,如果对象在调用len()函数之后被修改(例如,列表的元素被添加或删除),那么你需要再次调用len()函数来获取新的长度。
4、性能考虑:对于非常大的对象,使用len()函数可能会导致性能问题,因为它可能需要遍历整个对象来确定长度,在处理大数据集时,请考虑其他可能的性能优化方法。
5、空对象:对于空对象(如空字符串、空列表或空字典),len()函数将返回0,这有助于在编写代码时检查对象是否为空。
6、自定义对象:如果你想对自定义对象使用len()函数,你需要在类中实现`__len__()`方法,这个方法应该返回一个整数,表示对象的“长度”或“大小”。
7、可变/不可变对象:对于可变对象(如列表),len()返回的是当前状态下的长度,如果你之后修改了对象(例如添加或删除元素),你需要再次调用len()函数来获取新的长度,对于不可变对象(如字符串或元组),一旦创建,它们的长度就不会改变,所以len()函数的返回值也不会变。
总之,只有遵循这些注意事项,你才能更有效地使用len()函数,并避免在Python编程中遇到常见的问题。

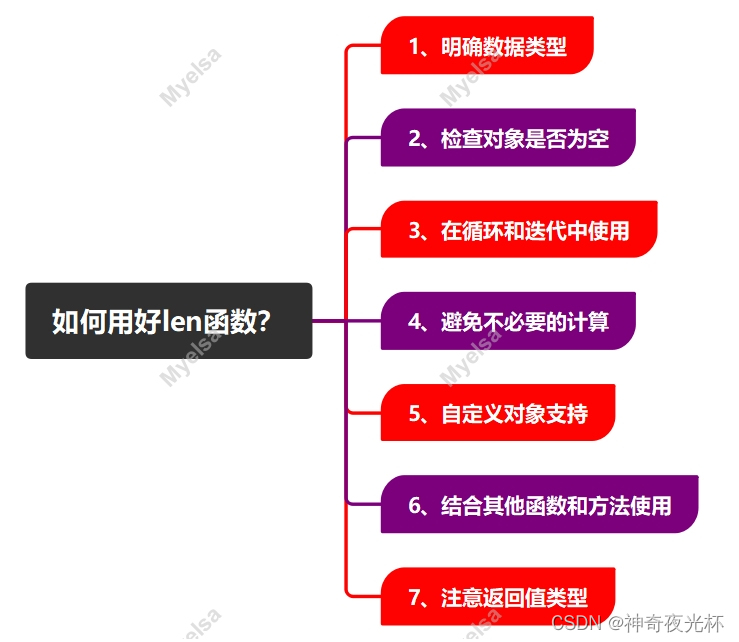
三、如何用好len函数?
要用好Python中的len()函数,首先要明确它的作用:返回对象的长度或项目数。为了充分发挥len()函数的功能,可以遵循以下几个建议:
1、明确数据类型:在使用len()函数之前,确保你了解对象的数据类型,虽然len()函数可以用于多种数据类型,但不同的数据类型可能有不同的解释。例如,对于字符串,len()返回字符数;对于列表或元组,返回元素数量;对于字典,返回键值对的数量。
2、检查对象是否为空:使用len()函数可以快速检查一个对象是否为空,如果len()返回0,那么对象就是空的,这对于条件判断和循环控制非常有用。
3、在循环和迭代中使用:在编写循环或迭代时,可以使用len()函数来确定需要迭代的次数。例如,在遍历列表或字符串时,你可以使用len()来确定循环的次数。
4、避免不必要的计算:虽然len()函数通常很快,但如果你在一个循环中多次调用它来获取相同的长度,那么这可能会导致不必要的性能开销,在这种情况下,最好将长度存储在一个变量中,并在循环中使用这个变量。
5、自定义对象支持:如果你正在处理自定义对象,并希望len()函数能够返回对象的某种长度或大小,你可以在自定义类中实现`__len__()`方法,这样,当你对该对象调用len()函数时,Python会自动调用你定义的`__len__()`方法。
6、结合其他函数和方法使用:len()函数可以与Python中的其他函数和方法结合使用,以实现更复杂的操作。例如,你可以使用len()`与条件语句、循环结构、列表推导式等结合,以完成各种任务。
7、注意返回值类型:len()函数始终返回一个整数,确保你在使用返回值时考虑到这一点,避免将其与其他非整数类型混淆。
1、len函数:
1-1、Python:
# 1.函数:len
# 2.功能:用于获取可迭代对象的长度或元素个数
# 3.语法:len(s)
# 4.参数:s,要获取其长度或者元素个数的对象
# 5.返回值:返回可迭代对象的长度或元素个数
# 6.说明:
# 7.示例:
# 利用dir()函数获取函数的相关内置属性和方法
print(dir(len))
# ['__call__', '__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__',
# '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__name__',
# '__ne__', '__new__', '__qualname__', '__reduce__', '__reduce_ex__', '__repr__', '__self__', '__setattr__', '__sizeof__',
# '__str__', '__subclasshook__', '__text_signature__']
# 利用help()函数获取函数的文档信息
help(len)
# 应用一:字符串处理
# 示例1:获取字符串长度
string1 = "Hello, World!"
length = len(string1)
print(f"The length of the string '{string1}' is {length}.")
# The length of the string 'Hello, World!' is 13.
# 示例2:比较两个字符串的长度
string2 = "Python"
string3 = "Java"
if len(string2) > len(string3):
print(f"'{string2}' is longer than '{string3}'.")
elif len(string2) < len(string3):
print(f"'{string2}' is shorter than '{string3}'.")
else:
print(f"'{string2}' and '{string3}' are the same length.")
# 'Python' is longer than 'Java'.
# 示例3:处理字符串切片并获取长度
string4 = "myelsaiswonderful"
substring = string4[2:6] # Slicing the string from index 2 to 5 (excluding 6)
substring_length = len(substring)
print(f"The substring '{substring}' of '{string4}' has a length of {substring_length}.")
# The substring 'elsa' of 'myelsaiswonderful' has a length of 4.
# 示例4:统计字符串中某个字符的出现次数(通过转换为列表并计算长度)
string5 = "mississippi"
char_to_count = "i"
count = len([char for char in string5 if char == char_to_count])
print(f"The character '{char_to_count}' appears {count} times in '{string5}'.")
# The character 'i' appears 4 times in 'mississippi'.
# 示例5:处理字符串中的空格并获取非空格字符的长度
string6 = "Hello, World! "
string6_without_spaces = ''.join(string6.split()) # Remove spaces
length_without_spaces = len(string6_without_spaces)
print(f"The length of '{string6}' without spaces is {length_without_spaces}.")
# The length of 'Hello, World! ' without spaces is 12.
# 应用二:列表和元组操作
# 示例1:获取列表长度
my_list = [1, 2, 3, 4, 5]
list_length = len(my_list)
print(f"The length of the list {my_list} is {list_length}.")
# The length of the list [1, 2, 3, 4, 5] is 5.
# 示例2:比较两个列表的长度
list1 = [1, 2, 3]
list2 = ['a', 'b', 'c', 'd']
if len(list1) > len(list2):
print(f"List {list1} is longer than list {list2}.")
elif len(list1) < len(list2):
print(f"List {list1} is shorter than list {list2}.")
else:
print(f"Lists {list1} and {list2} are the same length.")
# List [1, 2, 3] is shorter than list ['a', 'b', 'c', 'd'].
# 示例3:处理列表切片并获取长度
fruits = ['apple', 'banana', 'cherry', 'date', 'elderberry']
sliced_fruits = fruits[1:4] # Slicing the list from index 1 to 3 (excluding 4)
sliced_length = len(sliced_fruits)
print(f"The sliced list {sliced_fruits} has a length of {sliced_length}.")
# The sliced list ['banana', 'cherry', 'date'] has a length of 3.
# 示例4:列表中添加元素并查看长度变化
numbers = [1, 2, 3]
print(f"Initial length of the list {numbers} is {len(numbers)}.")
numbers.append(4) # Add an element to the list
print(f"After adding an element, the length of the list {numbers} is {len(numbers)}.")
# Initial length of the list [1, 2, 3] is 3.
# After adding an element, the length of the list [1, 2, 3, 4] is 4.
# 示例5:使用列表推导式并获取长度
squares = [x**2 for x in range(5)] # List comprehension to create a list of squares
squares_length = len(squares)
print(f"The list {squares} of squares has a length of {squares_length}.")
# The list [0, 1, 4, 9, 16] of squares has a length of 5.
# 示例6:获取元组长度
my_tuple = (10, 20, 30, 40, 50)
tuple_length = len(my_tuple)
print(f"The length of the tuple {my_tuple} is {tuple_length}.")
# The length of the tuple (10, 20, 30, 40, 50) is 5.
# 示例7:比较元组与列表的长度
my_tuple = ('a', 'b', 'c')
my_list = ['x', 'y', 'z']
if len(my_tuple) == len(my_list):
print(f"The tuple {my_tuple} and the list {my_list} are the same length.")
else:
print(f"The tuple {my_tuple} and the list {my_list} are not the same length.")
# The tuple ('a', 'b', 'c') and the list ['x', 'y', 'z'] are the same length.
# 应用三:字典操作
# 示例1:获取字典的长度(键的数量)
my_dict = {'a': 1, 'b': 2, 'c': 3}
dict_length = len(my_dict)
print(f"The length of the dictionary {my_dict} is {dict_length}.")
# The length of the dictionary {'a': 1, 'b': 2, 'c': 3} is 3.
# 示例2:比较两个字典的长度
dict1 = {'x': 10, 'y': 20}
dict2 = {'a': 1, 'b': 2, 'c': 3, 'd': 4}
if len(dict1) > len(dict2):
print(f"Dictionary {dict1} has more keys than {dict2}.")
elif len(dict1) < len(dict2):
print(f"Dictionary {dict1} has fewer keys than {dict2}.")
else:
print(f"Dictionaries {dict1} and {dict2} have the same number of keys.")
# Dictionary {'x': 10, 'y': 20} has fewer keys than {'a': 1, 'b': 2, 'c': 3, 'd': 4}.
# 示例3:添加键值对到字典并查看长度变化
person = {'name': 'Myelsa', 'age': 18}
print(f"Initial length of the dictionary {person} is {len(person)}.")
person['city'] = 'New York' # Add a key-value pair to the dictionary
print(f"After adding a key-value pair, the length of the dictionary {person} is {len(person)}.")
# Initial length of the dictionary {'name': 'Myelsa', 'age': 18} is 2.
# After adding a key-value pair, the length of the dictionary {'name': 'Myelsa', 'age': 18, 'city': 'New York'} is 3.
# 示例4:移除字典中的键值对并查看长度变化
person = {'name': 'Myelsa', 'age': 18, 'city': 'Guangzhou'}
print(f"Initial length of the dictionary {person} is {len(person)}.")
del person['city'] # Remove a key-value pair from the dictionary
print(f"After removing a key-value pair, the length of the dictionary {person} is {len(person)}.")
# Initial length of the dictionary {'name': 'Myelsa', 'age': 18, 'city': 'Guangzhou'} is 3.
# After removing a key-value pair, the length of the dictionary {'name': 'Myelsa', 'age': 18} is 2.
# 示例5:获取字典中值的数量(不考虑重复)
my_dict = {'a': 1, 'b': 2, 'c': 1, 'd': 3}
values_set = set(my_dict.values()) # Convert values to a set to remove duplicates
values_count = len(values_set)
print(f"The number of unique values in the dictionary {my_dict} is {values_count}.")
# The number of unique values in the dictionary {'a': 1, 'b': 2, 'c': 1, 'd': 3} is 3.
# 示例6:比较两个字典是否有相同数量的键值对
dict3 = {'e': 5, 'f': 6}
dict4 = {'g': 7, 'h': 8, 'i': 9}
if len(dict3) == len(dict4):
print(f"Dictionaries {dict3} and {dict4} have the same number of key-value pairs.")
else:
print(f"Dictionaries {dict3} and {dict4} do not have the same number of key-value pairs.")
# Dictionaries {'e': 5, 'f': 6} and {'g': 7, 'h': 8, 'i': 9} do not have the same number of key-value pairs.
# 应用四:集合操作
# 示例1:获取集合的长度(元素数量)
my_set = {1, 2, 3, 4, 5}
set_length = len(my_set)
print(f"The length of the set {my_set} is {set_length}.")
# The length of the set {1, 2, 3, 4, 5} is 5.
# 示例2:比较两个集合的长度
set1 = {1, 2, 3}
set2 = {4, 5, 6, 7}
if len(set1) > len(set2):
print(f"Set {set1} has more elements than {set2}.")
elif len(set1) < len(set2):
print(f"Set {set1} has fewer elements than {set2}.")
else:
print(f"Sets {set1} and {set2} have the same number of elements.")
# Set {1, 2, 3} has fewer elements than {4, 5, 6, 7}.
# 示例3:添加元素到集合并查看长度变化
my_set = {1, 2, 3}
print(f"Initial length of the set {my_set} is {len(my_set)}.")
my_set.add(4) # Add an element to the set
print(f"After adding an element, the length of the set {my_set} is {len(my_set)}.")
# Initial length of the set {1, 2, 3} is 3.
# After adding an element, the length of the set {1, 2, 3, 4} is 4.
# 示例4:移除集合中的元素并查看长度变化
my_set = {1, 2, 3, 4}
print(f"Initial length of the set {my_set} is {len(my_set)}.")
my_set.remove(3) # Remove an element from the set
print(f"After removing an element, the length of the set {my_set} is {len(my_set)}.")
# Initial length of the set {1, 2, 3, 4} is 4.
# After removing an element, the length of the set {1, 2, 4} is 3.
# 示例5:计算两个集合的并集并获取长度
set1 = {1, 2, 3}
set2 = {3, 4, 5}
union_set = set1.union(set2) # Get the union of two sets
union_length = len(union_set)
print(f"The union of {set1} and {set2} is {union_set} and its length is {union_length}.")
# The union of {1, 2, 3} and {3, 4, 5} is {1, 2, 3, 4, 5} and its length is 5.
# 示例6:计算两个集合的交集并获取长度
set1 = {1, 2, 3}
set2 = {3, 4, 5}
intersection_set = set1.intersection(set2) # Get the intersection of two sets
intersection_length = len(intersection_set)
print(f"The intersection of {set1} and {set2} is {intersection_set} and its length is {intersection_length}.")
# The intersection of {1, 2, 3} and {3, 4, 5} is {3} and its length is 1.
# 应用五:自定义对象
# 示例1:自定义一个字符串列表类,并实现__len__()方法
class StringList:
def __init__(self, strings):
self.strings = strings
def __len__(self):
return len(self.strings)
def __str__(self):
return str(self.strings)
# 创建一个StringList对象
my_list = StringList(['apple', 'banana', 'cherry'])
# 使用len()函数获取StringList对象的长度
length = len(my_list)
print(f"The length of the StringList {my_list} is {length}.")
# The length of the StringList ['apple', 'banana', 'cherry'] is 3.
# 示例2:自定义一个学生类,每个学生有多个课程,计算学生选课数量
class Student:
def __init__(self, name, courses):
self.name = name
self.courses = courses
def __len__(self):
return len(self.courses)
def __str__(self):
return f"{self.name} has {len(self.courses)} courses."
# 创建一个Student对象
student = Student("Myelsa", ["Math", "Science", "English"])
# 使用len()函数获取Student对象的课程数量
num_courses = len(student)
print(f"The number of courses for {student} is {num_courses}.")
# The number of courses for Myelsa has 3 courses. is 3.
# 示例3:自定义一个点集类,计算点集中点的数量
class PointSet:
def __init__(self, points):
self.points = points
def __len__(self):
return len(self.points)
def __str__(self):
return str(self.points)
# 创建一个PointSet对象
point_set = PointSet([(1, 2), (3, 4), (5, 6)])
# 使用len()函数获取PointSet对象的点数量
num_points = len(point_set)
print(f"The number of points in the PointSet {point_set} is {num_points}.")
# The number of points in the PointSet [(1, 2), (3, 4), (5, 6)] is 3.
# 应用六:文件和输入/输出
# 示例1:读取文件内容并计算其长度
# 打开文件并读取所有内容
with open('file.txt', 'r', encoding='utf-8') as file:
content = file.read()
# 计算文件内容的长度
content_length = len(content)
print(f"The length of the file content is: {content_length} characters.")
# The length of the file content is: 39 characters.
# 示例2:逐行读取文件并计算行数
# 打开文件并逐行读取
with open('file.txt', 'r', encoding='utf-8') as file:
lines = file.readlines()
# 计算行数(即列表长度)
num_lines = len(lines)
print(f"The number of lines in the file is: {num_lines}.")
# The number of lines in the file is: 6.
# 示例3:从用户输入读取字符串并计算其长度
# 从用户获取输入
user_input = input("Enter a string: ")
# 计算输入字符串的长度
input_length = len(user_input)
print(f"The length of your input is: {input_length} characters.")
# Enter a string: myelsa
# The length of your input is: 6 characters.
# 示例4:将文件内容读入列表并计算列表中元素的数量
# 打开文件并读取所有行,将每行转换为整数并添加到列表中
with open('file.txt', 'r', encoding='utf-8') as file:
data_list = [int(line.strip()) for line in file]
# 计算列表中元素的数量
num_elements = len(data_list)
print(f"The number of elements in the list is: {num_elements}.")
# The number of elements in the list is: 6.
# 应用七:循环和迭代控制
# 示例1:使用len()和for循环遍历列表
my_list = [1, 2, 3, 4, 5]
# 使用len()获取列表长度,并使用for循环遍历列表
for i in range(len(my_list)):
print(my_list[i])
# 1
# 2
# 3
# 4
# 5
# 示例2:使用len()和while循环遍历字符串
my_string = "Hello, Python!"
index = 0
# 使用len()获取字符串长度,并使用while循环遍历字符串
while index < len(my_string):
print(my_string[index])
index += 1
# H
# e
# l
# l
# o
# ,
#
# P
# y
# t
# h
# o
# n
# !
# 示例3:使用len()和列表推导式(迭代控制)
my_list = [1, 2, 3, 4, 5]
# 使用len()和列表推导式创建一个新列表,包含原列表中每个元素的平方
squared_list = [x ** 2 for x in my_list if x < len(my_list)]
print(squared_list)
# [1, 4, 9, 16]
# 示例4:使用len()和enumerate()函数遍历列表同时获取索引和值
my_list = ['apple', 'banana', 'cherry']
# 使用enumerate()和len()来遍历列表,并打印索引和值
for index, item in enumerate(my_list):
print(f"Index {index} has value {item}")
# 也可以使用range()和len()来达到相同的效果
for index in range(len(my_list)):
print(f"Index {index} has value {my_list[index]}")
# Index 0 has value apple
# Index 1 has value banana
# Index 2 has value cherry
# Index 0 has value apple
# Index 1 has value banana
# Index 2 has value cherry
# 示例5:使用len()控制循环次数以处理嵌套列表
nested_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# 使用len()来控制外部循环,遍历嵌套列表的每一个子列表
for i in range(len(nested_list)):
# 使用len()来控制内部循环,遍历当前子列表的每一个元素
for j in range(len(nested_list[i])):
print(nested_list[i][j])
# 1
# 2
# 3
# 4
# 5
# 6
# 7
# 8
# 9
# 应用八:动态分配空间
# 示例1:根据输入字符串的长度动态创建列表
input_string = input("Enter a string: ")
# 使用len()获取输入字符串的长度,并创建一个相应长度的列表
list_length = len(input_string)
my_list = [None] * list_length
# 现在可以根据需要填充列表
for i in range(list_length):
my_list[i] = input_string[i]
print(my_list)
# Enter a string: myelsa
# ['m', 'y', 'e', 'l', 's', 'a']
# 示例2:根据一组数字动态创建和填充字典
numbers = input("Enter numbers separated by spaces: ").split()
# 使用len()获取数字的数量,并创建一个空字典
num_count = len(numbers)
my_dict = {}
# 根据数字的数量动态添加键值对到字典中
for i in range(num_count):
my_dict[i] = int(numbers[i])
print(my_dict)
# Enter numbers separated by spaces: 16
# {0: 16}
# 示例3:动态扩展列表以包含新元素
my_list = [1, 2, 3]
# 假设我们要添加一个新元素到列表末尾
new_element = 4
# 不需要直接使用len()来分配空间,Python列表会自动处理
my_list.append(new_element)
print(my_list)
# [1, 2, 3, 4]
# 应用九:调试和日志记录
# 示例1:使用print和len()进行基本调试
my_list = [1, 2, 3, 4, 5]
# 在调试时使用print和len()查看列表长度
print(f"The length of my_list is: {len(my_list)}")
# 对列表进行修改后,再次查看长度
my_list.append(6)
print(f"After appending an element, the length of my_list is: {len(my_list)}")
# The length of my_list is: 5
# After appending an element, the length of my_list is: 6
# 示例2:使用日志库(如logging)记录长度信息
import logging
# 配置日志记录器
logging.basicConfig(level=logging.INFO)
my_list = [1, 2, 3, 4, 5]
# 使用logging库记录列表长度
logging.info(f"The length of my_list is: {len(my_list)}")
# 对列表进行修改,并记录修改后的长度
my_list.append(6)
logging.info(f"After appending an element, the length of my_list is: {len(my_list)}")
# INFO:root:The length of my_list is: 5
# INFO:root:After appending an element, the length of my_list is: 6
# 示例3:在复杂函数中使用len()进行调试
import logging
def process_data(data):
# 假设data是一个列表,我们对其进行一些处理
processed_data = [x * 2 for x in data]
# 使用logging记录处理前和处理后的数据长度
logging.debug(f"Original data length: {len(data)}")
logging.debug(f"Processed data length: {len(processed_data)}")
return processed_data
# 示例数据
data = [1, 2, 3]
# 调用函数并记录日志
processed_data = process_data(data)
logging.info(f"Processed data: {processed_data}")
# 示例4:在异常处理中使用len()进行调试
import logging
def read_file_and_process(filename):
try:
with open(filename, 'r') as file:
lines = file.readlines()
# 使用len()检查是否读取到任何行
if len(lines) == 0:
raise ValueError("The file is empty.")
# 对读取到的行进行处理(此处仅为示例,未实际处理)
except FileNotFoundError:
logging.error(f"File {filename} not found.")
except ValueError as e:
logging.error(e)
except Exception as e:
logging.error(f"An error occurred: {e}")
logging.debug(f"Number of lines read: {len(lines) if 'lines' in locals() else 'N/A'}")
# 调用函数,假设文件存在但为空
read_file_and_process('file.txt')
# 应用十:性能分析和优化
# 示例1:避免在循环中多次调用len()
# 不推荐的做法:在循环中多次调用len()
my_list = [1, 2, 3, 4, 5]
for i in range(len(my_list)):
print(len(my_list)) # 这里的len()调用是不必要的,因为列表长度不会改变
print(my_list[i])
# 推荐的做法:在循环外部调用len(),并存储结果
list_length = len(my_list)
for i in range(list_length):
print(list_length) # 使用之前存储的长度
print(my_list[i])
# 示例2:使用生成器代替列表以节省内存
# 使用列表推导式创建列表
my_list = [x * x for x in range(1000000)] # 这会立即创建一个大列表,占用大量内存
print(len(my_list)) # 使用len()获取长度
# 使用生成器表达式节省内存
my_generator = (x * x for x in range(1000000)) # 生成器不会立即创建所有元素,而是按需生成
print(sum(1 for _ in my_generator)) # 使用sum和生成器表达式计算元素数量,而不是len()
# 示例3:使用内置函数和库函数代替手动循环
# 使用循环和len()计算列表中所有元素的和
my_list = [1, 2, 3, 4, 5]
sum_manual = 0
for item in my_list:
sum_manual += item
print(sum_manual)
# 使用内置函数sum()代替循环,更高效
sum_builtin = sum(my_list)
print(sum_builtin)
# 对于更复杂的操作,考虑使用NumPy等库,它们针对数组操作进行了优化
import numpy as np
my_array = np.array(my_list)
sum_numpy = np.sum(my_array)
print(sum_numpy)
# 示例4:性能分析使用time模块测量执行时间
import time
# 示例函数,使用len()
def count_elements(data):
return len(data)
# 创建一个大型数据集
large_data = [x for x in range(1000000)]
# 使用time模块测量函数执行时间
start_time = time.time()
count = count_elements(large_data)
end_time = time.time()
print(f"Number of elements: {count}")
print(f"Execution time: {end_time - start_time} seconds")
# Number of elements: 1000000
# Execution time: 0.0 seconds
# 示例5:使用cProfile进行性能分析
import cProfile
# 示例函数,执行一些操作并返回长度
def process_data(data):
processed_data = [x * x for x in data]
return len(processed_data)
# 创建一个大型数据集
large_data = [x for x in range(100000)]
# 使用cProfile进行性能分析
cProfile.run('process_data(large_data)')
# 应用十一:结合其他函数和方法使用
# 示例1:验证列表长度是否符合预期
def validate_list_length(lst, expected_length):
if len(lst) != expected_length:
raise ValueError(f"Expected list length {expected_length}, but got {len(lst)}")
return lst
my_list = [1, 2, 3, 4]
try:
validate_list_length(my_list, 5)
except ValueError as e:
print(e)
# Expected list length 5, but got 4
# 示例2:使用map()函数和len()计算列表中每个字符串的长度
my_strings = ['hello', 'world', 'python']
lengths = list(map(len, my_strings))
print(lengths)
# [5, 5, 6]
# 示例3:使用filter()函数和len()筛选长度大于特定值的字符串
my_strings = ['a', 'apple', 'banana', 'c', 'cherry']
long_strings = list(filter(lambda s: len(s) > 1, my_strings))
print(long_strings) # 输出: ['apple', 'banana', 'cherry']
# ['apple', 'banana', 'cherry']
# 示例4:使用sorted()函数和len()按字符串长度排序
my_strings = ['apple', 'cherry', 'banana', 'grape']
sorted_by_length = sorted(my_strings, key=len)
print(sorted_by_length)
# ['apple', 'grape', 'cherry', 'banana']
# 示例5:使用reduce()函数和len()计算嵌套列表中所有字符串的总长度
from functools import reduce
nested_list = [['a', 'bc'], ['def', 'ghi'], ['jklmnop']]
total_length = reduce(lambda acc, lst: acc + sum(map(len, lst)), nested_list, 0)
print(total_length)
# 16
# 示例6:在数据清洗过程中使用len()去除空字符串
data = ['apple', '', 'banana', ' ', 'cherry']
cleaned_data = [item for item in data if len(item.strip()) > 0]
print(cleaned_data)
# ['apple', 'banana', 'cherry']1-2、VBA:
略,待后补。2、推荐阅读:
1、Python-VBA函数之旅-iter()函数
Python算法之旅:Algorithm
Python函数之旅:Functions
个人主页:https://blog.csdn.net/ygb_1024?spm=1010.2135.3001.5421