一般单线程爬数据太慢了话,就采用多线程。
一般要根据两种情形来选择
- 自定义线程
- 线程池
往往最关键的地方在,多个线程并发执行后,是否需要线性的返回结果。也就是先调用的线程,返回的结果要在前面。
或者说,某个对象不能进行并行调用,必须等所有线程执行完后,再线性执行。
自定义线程
导入Thread这个类
from threading import Thread
自定义MyThread再进行继承
class MyThread(Thread):
def __init__(self, id):
Thread.__init__(self)
self.id = id
self.result=None
def run(self):
self.result=f"结果为:{self.id}"
def get_result(self):
return self.result
要想调用的话,就直接新建后,进行start调用,默认走MyThead的run()函数
thd1 = MyThread(1)
thd2 = MyThread(2)
thd3 = MyThread(3)
thd1.start()
thd2.start()
thd3.start()
print(thd1.get_result()) #输出为 结果为:1
print(thd2.get_result()) #输出为 结果为:2
print(thd2.get_result()) #输出为 结果为:3
如果要等所有的线程执行完后,主程序再往下走,可以进行join调用
thd1 = MyThread(1)
thd2 = MyThread(2)
thd3 = MyThread(3)
thd1.start()
thd2.start()
thd3.start()
thd1.join()
thd2.join()
thd3.join()
# 全部线程执行完后,才进行下面的部分
print(thd1.get_result()) #输出为 结果为:1
print(thd2.get_result()) #输出为 结果为:2
print(thd2.get_result()) #输出为 结果为:3
线程池
线程池比自定义线程要更加简单,线程池会自动帮你管理里面的线程,还能自定义容量
下面是导入并创建线程池
from concurrent.futures import ThreadPoolExecutor
threadPool = ThreadPoolExecutor(max_workers=5)
max_workers表示最多允许 5个线程同时执行,如果有更多的线程就阻塞,直到里面的池子里面能再加入
线程池调用
def add(a,b):
print(a+b)
return a+b
threadPool=ThreadPoolExecutor(max_workers=5)
threadPool.submit(add,1,1)
threadPool.submit(add,1,2)
threadPool.submit(add,1,3)
threadPool.submit(add,2,1)
threadPool.submit(add,2,2)
threadPool.submit(add,2,3)
threadPool.submit(add,3,1)
threadPool.submit(add,3,2)
threadPool.submit(add,3,3)
假如说,现在需要threadPool的返回结果,这时候需要用到as_completed
from concurrent.futures import ThreadPoolExecutor, as_completed
def add(a,b):
print(a+b)
return a+b
threadPool=ThreadPoolExecutor(max_workers=5)
thread_list=[]
for i in range(3):
for j in range(3):
thread=threadPool.submit(add,i,j)
thread_list.append(thread)
for mission in as_completed(thread_list):
print(mission.result())
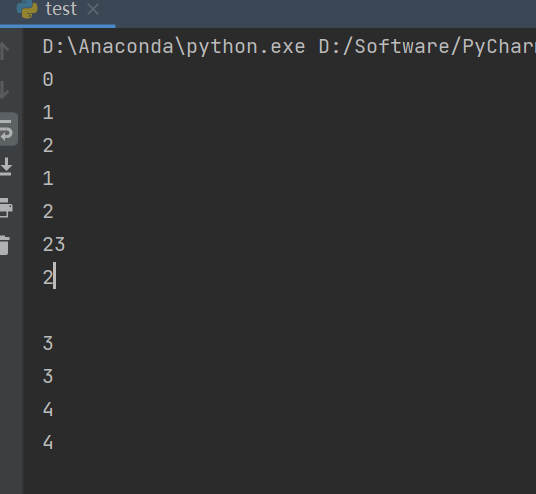
最后注意as_completed(thread_list)是利用thread_list里面的线程的返回的结果来创建一个迭代器,一旦有一个线程return,就将它的结果加入到迭代器后面
也就是,as_completed只能保证能取到结果,不能保证按次序返回,如果要按次序的话,就利用自定义线程