文章目录
- ReplacingMegreTree 引擎
- 数据一致性实现方式
- 1.ReplacingMegreTree 引擎
- 2.ReplacingMegreTree 引擎 + 手动合并
- 3.ReplacingMegreTree 引擎 + FINAL 查询
- 4.ReplacingMegreTree 引擎 + 标记 + GroupBy
- 5.允许偏差
前言:在大数据中,基本上所有组件都要求做到数据的一致性,因为大多数环境都是分布式的情况,如果数据无法做到一致,最终在进行分析计算时,导致指标出现问题,影响业务。
本篇文章将探讨在 ClickHouse 中实现数据一致性的几种方式。
ReplacingMegreTree 引擎
在 ClickHouse 中,推荐使用 ReplacingMegreTree 作为确保数据一致性的引擎。
与传统的 MergeTree 引擎相比,ReplacingMergeTree 允许更新已有的数据,而不是简单地追加新数据。当有新数据插入到表中时,它会删除排序键值相同的重复项,替换旧数据。
当有新数据替换旧数据时,旧数据并不会被立即删除,而是被标记为过时的版本。它定期会触发数据块合并操作,此时才会将历史数据进行删除,只保留新版本数据,优化性能、减少存储空间,做到最终一致性。
只有在触发合并操作后,数据才会发生真正的替换操作,在这之前,你查询到的都是历史版本数据。
数据一致性实现方式
1.ReplacingMegreTree 引擎
如果我们仅仅依赖 ReplacingMegreTree 引擎是无法做到数据一致性的,虽然它可以做到最终一致性,但是在未进行数据合并前,它可能存在重复数据。
而且官方说明,合并时间是无法预测的,也就是说我们并不知道它具体什么时候会发生合并操作。
那么为什么数据的合并时间无法预测呢?
-
数据量和数据分布不确定性:合并操作的时间受到数据量和数据分布的影响。如果数据量较大,合并操作可能需要花费更长的时间。此外,数据的分布情况也会影响合并操作的时间,例如数据块的大小和数量、数据块之间的差异等。
-
系统负载和资源竞争:合并操作需要消耗系统资源,包括 CPU、内存、磁盘等。当系统处于高负载状态时,合并操作可能需要等待资源空闲才能执行,这会导致合并操作的时间不确定。
2.ReplacingMegreTree 引擎 + 手动合并
虽然我们无法预知 ReplacingMegreTree 合并的具体时间,但是我们可以提前触发手动合并。
在新数据写入后,通过如下语句,主动执行合并:
OPTIMIZE TABLE table_name FINAL;
# 完成语法
OPTIMIZE TABLE [db.]name [ON CLUSTER cluster] [PARTITION partition | PARTITION ID 'partition_id'] [FINAL] [DEDUPLICATE [BY expression]]
但是手动合并会付出很大的代价,官方建议不要使用 OPTIMIZE TABLE ... FINAL,因为它用于管理(测试),而不是日常操作。
原因是,使用该查询时,它会尝试将指定表计划外的数据部分合并到一个原来的数据部分中。在此过程中,ClickHouse 读取所有数据部分,解压缩、合并、压缩为单个部分,然后重写回对象存储,造成巨大的 CPU 和 IO 消耗。这一优化会重写单个部分,即使它们已经合并为单个部分,所以代价很大,日常避免使用。
3.ReplacingMegreTree 引擎 + FINAL 查询
在进行查询时,添加 FINAL 后缀,如下所示:
SELECT * FROM test FINAL;
当指定 FINAL 时,ClickHouse 会在返回结果之前完全合并数据。但它限制引擎,只适用于从 ReplacingMergeTree、SummingMergeTree、AggregatingMergeTree、CollapsingMergeTree 和 VersionedCollapsingMergeTree 表中选择数据。
FINAL 查询在 v20.5.2.7 之前是单线程操作,十分缓慢,在这之后的版本都是并行执行的,默认采用 16 线程数,如果机器不能满足这么多线程,则默认使用当前机器最大线程数。我们也可以指定线程数运行该语句:
SELECT * FROM test FINAL settings max_threads = n;
当然,它会比日常的查询慢很多,主要原因有:
-
数据是在查询执行期间才进行合并的。
-
除了查询中指定的列之外,还会读取主键列的数据。
-
需要额外的计算和内存资源,因为只有在查询时才会进行合并,所有操作都是在内存中进行的。你虽然可以在查询中使用 FINAL 获得最终所需的结果,但是要注意资源的消耗。
4.ReplacingMegreTree 引擎 + 标记 + GroupBy
在创建表时,我们可以增加一列作为标记,记录该值是否被删除或更新。通过两个字段来完成这一操作:
-
标记列:使用特殊值标识该行数据是否被删除,例如:
0表示存在,1表示过期。 -
时间戳:标记列只能确保数据是否被删除,并不能标识是否发生过更新操作。所以我们可以借助数据中本身存在的时间戳来选择最新的数据,从而避免重复数据,做到数据一致性。
在日常开发中推荐使用这种方式来保证数据的一致性。
实现案例
假设有一个表存储用户的信息,包括用户ID、用户名、邮箱和标记列表示是否被删除。
首先,创建表
CREATE TABLE users (
id UInt32,
name String,
email String,
is_deleted UInt8,
event_time DateTime
) ENGINE = ReplacingMergeTree(event_time)
ORDER BY (id, event_time);
在这个表中,我使用了 ReplacingMergeTree 引擎,并指定了 event_time 字段作为排序键,以确保数据的时间顺序。is_deleted 字段表示该行数据是否被删除,0 表示存在,1 表示被删除。
接下来,插入一些测试数据:
INSERT INTO users VALUES
(1, 'Alice', 'alice@example.com', 0, '2024-04-25 08:00:00'),
(2, 'Bob', 'bob@example.com', 0, '2024-04-25 09:00:00'),
(3, 'Charlie', 'charlie@example.com', 0, '2024-04-25 10:00:00');
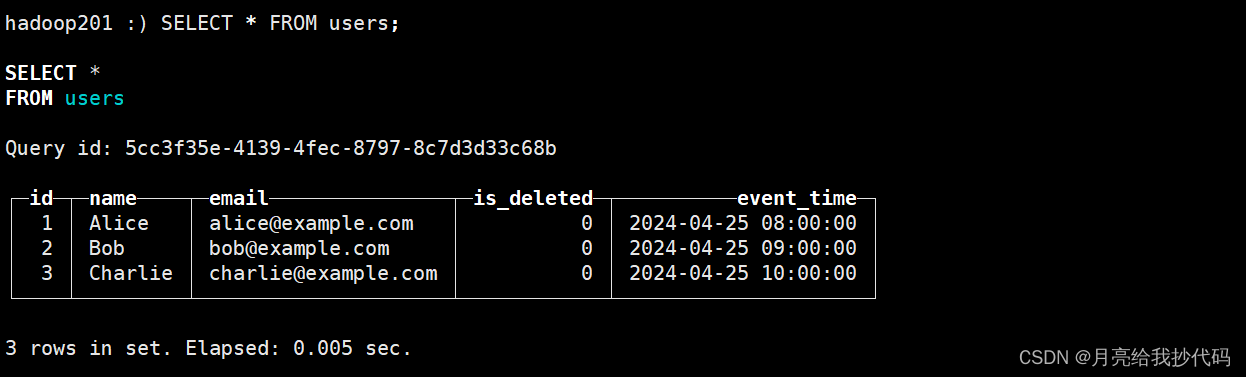
进行查询:
SELECT * FROM users;
现在,来模拟更新和删除操作的增量写入,假设用户 Bob 的邮箱地址被更新,用户 Charlie 被删除:
-- 更新 Bob 的邮箱地址
INSERT INTO users VALUES
(2, 'Bob', 'new_bob@example.com', 0, '2024-04-25 11:00:00');
-- 删除 Charlie
INSERT INTO users VALUES
(3, 'Charlie', '', 1, '2024-04-25 12:00:00');
增量写入后,表中的数据如下所示:
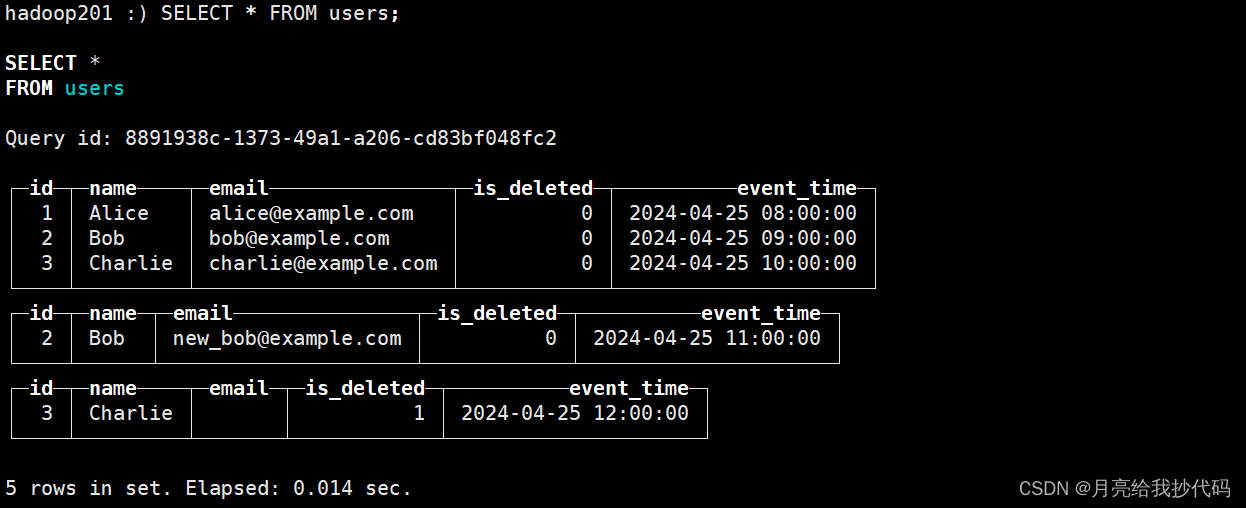
可以看到,这种情况就出现了重复数据。
但是,我们现在可以使用标记以及 Group By 语句查询每个用户的最新信息,手动过滤失效信息:
SELECT
id,
argMax(name,event_time) name,
argMax(email,event_time) email,
argMax(is_deleted,event_time) is_deleted,
max(event_time) max_event_time
FROM
users
GROUP BY
id
HAVING
is_deleted = 0;
按照用户 ID 进行分组,按 event_time 字段当前的最大值,取对应行所有字段的数据。
这里需要注意的是,最后取 event_time 最大值时,重命名字段必须与之前不同,否则会报错。
例如 max(event_time) event_time 这种写法是错误的,因为该列已经被其它聚合函数 argMax 引用了。
在 ClickHouse 中,可以使用
argMax函数来获取满足指定条件的某个字段的最大值所在行对应的另一个字段的值。argMax 函数通常与 GROUP BY 结合使用,以便在每个分组中找到满足条件的最大值对应的其他字段的值。
运行结果如下:
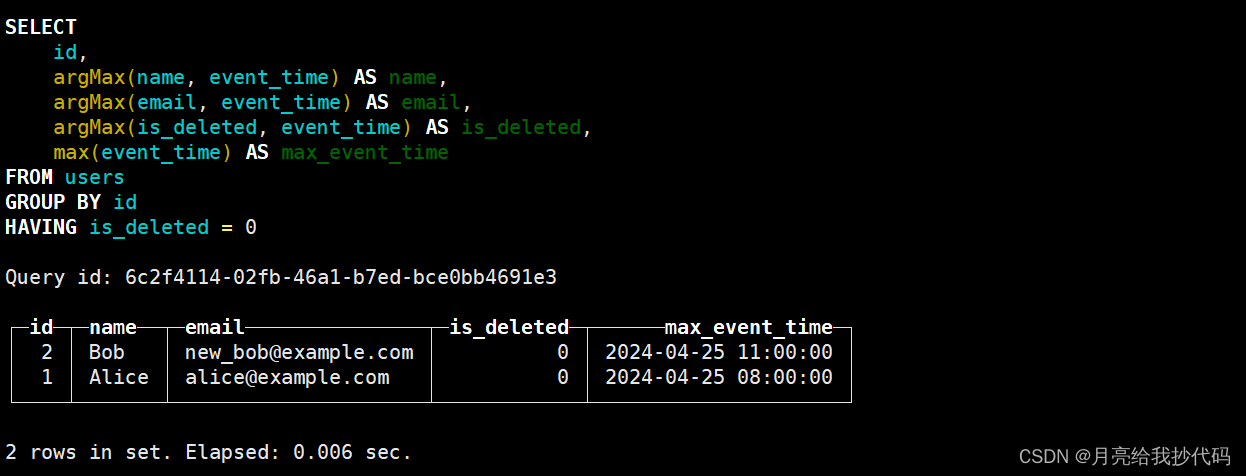
可以看到,我们成功的过滤掉了失效数据(用户 Bob 的邮箱地址被更新,用户 Charlie 被删除)
5.允许偏差
当我们在对某个指标进行计算时,并不关心该指标最终特别准确的值,或者说允许偏差一点,重复的数据量并不大,不会对总体造成影响。
那么这种情况我们就不需要去确保该份数据的一致性,只需要确保最终一致性即可,此时选用 ReplacingMegreTree 引擎作为数据去重方案即可,不用大费周章的去花时间设计。