目录
- TCP/IP协议
- 协议格式
- 传输层重点协议
- UDP协议
- UDP协议端格式
- UDP的特点
- TCP协议
- TCP协议端格式
- TCP的特点
TCP/IP协议
协议格式
应用层(后端开发必知必会):这一层也有很多现成的协议(后面还会重点介绍HTTP协议,这是做网站必备的)也有很多时候,是需要程序员自己定义协议的
客户端,需要给服务器发起一个请求,服务器收到请求之后,就给客户端返回一个响应
以下以外卖软件举例
客户端和服务器之间的沟通有很多种形式,因此需要在开发设计这个程序的时候,就需要提前做好良好的规划。这里的设计是非常灵活的,最主要的是要有一个固定的标准
举例:
做出如下设计:
- 明确当前请求和响应中包含哪些信息(根据需求来的)
请求:用户身份,用户当前位置…
响应:商家的名称,图片,好评率,距离你的位置,评分…
- 明确具体的请求和响应的格式
请求:
示例1:
请求:1234,80,100\n
所谓的“明确格式”就是看你按照啥样的方式,构造出一个字符串后续这个字符串就可以作为 tcp 或者 udp 的 payload 进行传输
另一方面服务器就可以对这个字符串进行解析,解析出 逗号 前面的是userld,逗号后面的是经度纬度
响应:
魏家凉皮,1.jpg,98%,1km,4.7\n
杨国福,2.jpg,99%,1.2km,4.8\n
\n
这个时候就构造出了一个响应这样的字符串,客户端就可以按照这样的格式来进行解析了
实际上,上述这样的格式约定,咋搞都行。任意进行约定的,只要保证,客户端和服务器遵守同一个约定即可
实例2:

实际上,以上的格式约定,咋样都行,任意进行约定的,只要保证,客户端和服务器遵守同一个约定即可。请求和响应的具体的数据组织形式,是非常灵活的。只要程序员想都行,只要客户端和服务器使用的是相同的规则即可
自定义协议:
- 明确传递的信息是有啥
- 约定好信息按照啥样的格式组织成(二进制)字符串
介绍几个通用重要的协议格式:
- xml
是以成对的标签,来表示“键值对”信息,同时标签支持嵌套,就可以构成一些更复杂的树形结构数据
//请求
<request>
<userld>1234<userld>
<position>100 80</position>
<request>
//响应
<response>
<shops>
<shop>
<name>魏家原皮</name>
<image>1.jpg</image>
<distance>1km</distance>
<rate>96%<rate
<star>4.7</star>
</shop>
<shop>
<name>杨国福麻辣烫《name>
<image>2.jpg</image>
<distance>1km</distance>
<rate>96%<rate>
<star>4.7</star>
</shop>
<shops>
<response>
优点:xml非常清晰的把结构化数据表示出来了
缺点:表示数据需要引入大量的标签,看起来繁琐,同时也会占用不少的网络带宽(国内最贵的硬件资源,就是网络带宽)
xml越来越少了,有一些新的单体xml
- json(最流行的一种数据组织格式)
本质上也是键值对,看起来,比xml格式要干净不少
请求:
{
userld:1234
position: "10080"
}
响应:
[
{
name:魏家凉皮
image:1.jpg
distance:"1km
rate:96%
star:4.7
},
{
name:杨国福琳辣烫
image:2.jpg,
distance:1km
rate:96%
star:4.7
}
]
**优势:**相比于xml,表示的数据简洁很多,可读性非常好,方便程序员观察中间结果,为方便调试问题
**劣势:**终究是要花费一定的带宽来传输key的名字
当前最主流使用的一种网络传输数据的格式,未来在实际开发中会经常用到json格式的数据。
json对于换行并不敏感,如果这些内容全放在同一行,也是完全合法的
一般网络传输的时候,会对json进行压缩(去掉不必要的换行和空格),同时把所有数据放到一行去,整体占用的带宽就更降低了(影响到可读性)
也有很多现成的json格式化工具
- protobuffer(主要用于对于性能要求更高的场景)
谷歌提出的一套二进制的数据序列化方式。使用二进制的方式,约定某几个字节,表示哪个属性,最大程度的节省空间(不必传输key,根据位置和长度,区分每个属性的)
优点:节省带宽,最大化效率
缺点:二进制数据,无法肉眼直接观察,不方便调试,使用起来比较复杂
- 除了以上三种,还有很多序列化方式的。
学习一个协议,当然要掌握协议的特性,还需要理解报文格式
传输层重点协议
负责数据能够从发送端传输接收端。
UDP协议
UDP协议端格式
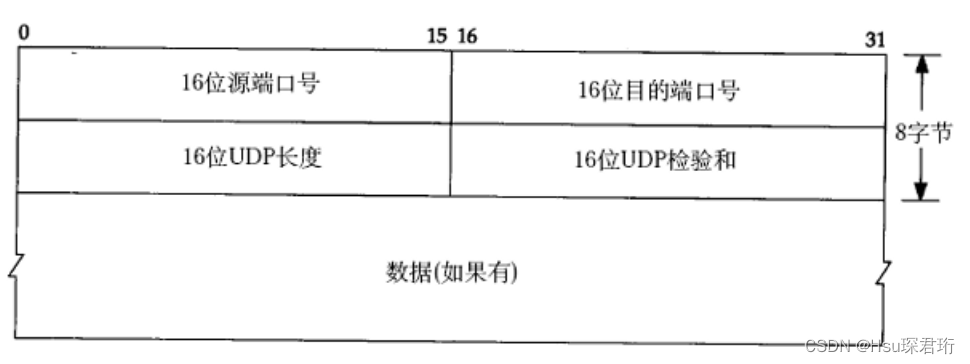
- 16位UDP长度,表示整个数据报(UDP首部+UDP数据)的最大长度;
- 如果校验和出错,就会直接丢弃;
其实这图不算准确,是为了排版方便做的妥协,以下才是整个UDP数据报图文结构

网络传输的过程中,收到外界干扰,数据可能出错。本质上是光信号/电信号/电磁波
UDP的校验和具体是咋实现的?使用了一种简单粗暴的CRC校验算法(循环冗余校验和)
- 把UDP数据报中每个字节都依次进行累加
- 把累加结果保存到2个字节的变量中,加着加着,可能就溢出了,但无所谓,所有字节都加一遍,最终就得到了校验和
- 传输数据的时候,就把原始数据和校验和一起传递过去
- 接收方收到数据时,同时也收到了发送端送过来的校验和(旧的校验和),接收方按照同样的方式再算一遍,得到新的校验和
- 如果新的和旧的相同,就视为数据传输过程中是正确的,如果不同,就视为数据传输过程中数据出错了
UDP的特点
UDP传输的过程类似于寄信
- 无连接
客户端在开始就直接send,服务器在开始就直接receive没有进行连接
-
不可靠
-
面向数据报
//客户端
DatagramPacket requestPacket=new DatagramPacket(request.getBytes(),request.getBytes().length,
InetAddress.getByName(serverIp),serverPort);
//客户端
DatagramPacket responsePacket=new DatagramPacket(new byte[4096],4096);
都是packet
- 全双工
//客户端
socket.send(requestPacket);
//客户端
socket.receive(responsePacket);
-
缓冲区
-
大小受限
TCP协议
TCP,即Transmission Control Protocol,传输控制协议。人如其名,要对数据的传输进行一个详细的控制。
TCP是一个最重要的协议,用的特别多(HTTP也是基于TCP)
TCP协议端格式
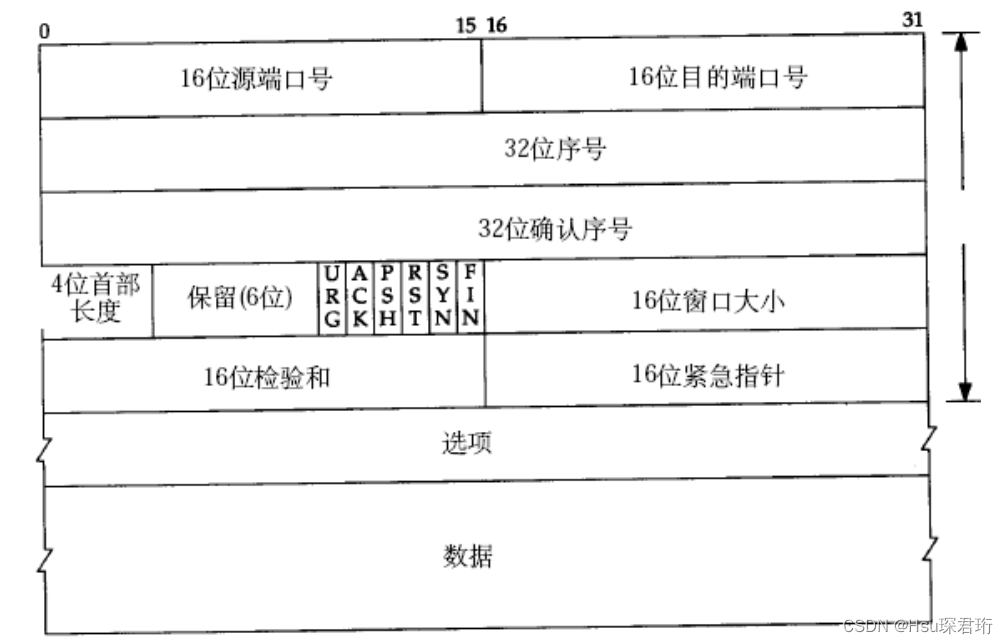
- 源/目的端口号:表示数据是从哪个进程来,到哪个进程去;
端口号属于哪一层中的概念?传输层
- 32位序号/32位确认号:后面详细讲;
- 4位TCP报头长度(除了数据光看头部的长度):表示该TCP头部(TCP头部是变长的)有多少个32位bit(有多少个4字节),4位表示的范围是0~15,但单位是4字节;所以TCP头部最大长度是15 * 4 = 60(需要使用首部长度,来确认,报头到哪里就结束了,载荷数据从哪里开始)
- 6位标志位(每个1bit,表示非常重要的含义):
- URG:紧急指针是否有效
- ACK:确认号是否有效
- PSH:提示接收端应用程序立刻从TCP缓冲区把数据读走
- RST:对方要求重新建立连接;我们把携带RST标识的称为复位报文段
- SYN:请求建立连接;我们把携带SYN标识的称为同步报文段
- FIN:通知对方,本端要关闭了,我们称携带FIN标识的为结束报文段
- 16位窗口大小:后面再说
- 16位校验和:发送端填充,CRC校验。接收端校验不通过,则认为数据有问题。此处的检验和不光包含TCP首部,也包含TCP数据部分。
- 16位紧急指针:标识哪部分数据是紧急数据;
- 40字节头部选项:暂时忽略;
TCP的特点
- 有连接
- 可靠传输(最核心的特性)
- 面向字节流
- 全双工
- 缓冲区
- 大小限制
可靠传输是内核实现的,写代码是感知不到的。
TCP对数据传输提供的管控机制,主要体现在两个方面:安全和效率。
这些机制和多线程的设计原则类似:保证数据传输安全的前提下,尽可能的提高传输效率。
![[iOS]CocoaPods安装和使用](https://img-blog.csdnimg.cn/direct/cc42417e4af84707b6741df16c17fe91.png)