节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学,针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
汇总合集
《大模型面试宝典》(2024版) 发布!
《大模型实战宝典》(2024版) 发布!
Llama 3 近期重磅发布,发布了 8B 和 70B 参数量的模型,LMDeploy 对 Llama 3 部署进行了光速支持,同时对 LMDeploy 推理 Llama 3-8B 进行了测试,在公平比较的条件下推理效率是 vLLM 的 1.8 倍。
本文将分为以下几个部分来介绍,如何使用 LMDeploy来部署 Llama 3(以 InternStudio 的环境为例)。
-
环境、模型准备
-
LMDeploy Chat CLI 工具
-
LMDeploy 模型量化(lite)
-
LMDeploy 服务(serve)
-
LMDeploy Llama 3 推理测速
-
使用 LMDeploy 运行视觉多模态大模型 Llava-Llama-3
技术交流
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了算法岗面试与技术交流群, 想要进交流群、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2040。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:技术交流
方式②、添加微信号:mlc2040,备注:技术交流+CSDN
用通俗易懂的方式讲解系列
-
重磅来袭!《大模型面试宝典》(2024版) 发布!
-
重磅来袭!《大模型实战宝典》(2024版) 发布!
-
用通俗易懂的方式讲解:不用再找了,这是大模型最全的面试题库
-
用通俗易懂的方式讲解:这是我见过的最适合大模型小白的 PyTorch 中文课程
-
用通俗易懂的方式讲解:一文讲透最热的大模型开发框架 LangChain
-
用通俗易懂的方式讲解:基于 LangChain + ChatGLM搭建知识本地库
-
用通俗易懂的方式讲解:基于大模型的知识问答系统全面总结
-
用通俗易懂的方式讲解:ChatGLM3 基础模型多轮对话微调
-
用通俗易懂的方式讲解:最火的大模型训练框架 DeepSpeed 详解来了
-
用通俗易懂的方式讲解:这应该是最全的大模型训练与微调关键技术梳理
-
用通俗易懂的方式讲解:Stable Diffusion 微调及推理优化实践指南
-
用通俗易懂的方式讲解:大模型训练过程概述
-
用通俗易懂的方式讲解:专补大模型短板的RAG
-
用通俗易懂的方式讲解:大模型LLM Agent在 Text2SQL 应用上的实践
-
用通俗易懂的方式讲解:大模型 LLM RAG在 Text2SQL 上的应用实践
-
用通俗易懂的方式讲解:大模型微调方法总结
-
用通俗易懂的方式讲解:涨知识了,这篇大模型 LangChain 框架与使用示例太棒了
-
用通俗易懂的方式讲解:掌握大模型这些优化技术,优雅地进行大模型的训练和推理!
-
用通俗易懂的方式讲解:九大最热门的开源大模型 Agent 框架来了
1. 环境,模型准备
1.1 环境配置
# 如果你是 InternStudio 可以直接使用
# studio-conda -t lmdeploy -o pytorch-2.1.2
# 初始化环境
conda create -n lmdeploy python=3.10
conda activate lmdeploy
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia
安装 LMDeploy 最新版
pip install -U lmdeploy
1.2 Llama3 的下载
安装 git-lfs 依赖
conda install git
apt-get install git-lfs
git-lfs install
下载模型
mkdir -p ~/model
cd ~/model
git clone https://code.openxlab.org.cn/MrCat/Llama-3-8B-Instruct.git Meta-Llama-3-8B-Instruct
或者软链接 InternStudio 中的模型
mkdir -p ~/model
ln -s /root/share/new_models/meta-llama/Meta-Llama-3-8B-Instruct ~/model/Meta-Llama-3-8B-Instruct
2. LMDeploy Chat CLI 工具
直接在终端运行:
conda activate lmdeploy
lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct
3. LMDeploy 模型量化(lite)
本部分内容主要介绍如何对模型进行量化。主要包括 W4A16 量化和 KV INT8、INT4 量化。
3.1 设置最大 KV Cache 缓存大小
模型在运行时,占用的显存可大致分为三部分:模型参数本身占用的显存、KV Cache 占用的显存,以及中间运算结果占用的显存。LMDeploy 的 KV Cache 管理器可以通过设置 --cache-max-entry-count 参数,控制 KV 缓存占用剩余显存的最大比例。默认的比例为 0.8。
下面通过几个例子,来看一下调整 --cache-max-entry-count 参数的效果。首先保持不加该参数(默认0.8),运行 Llama3-8b 模型。
lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct/
新建一个终端运行。
# 如果你是InternStudio 就使用
# studio-smi
nvidia-smi
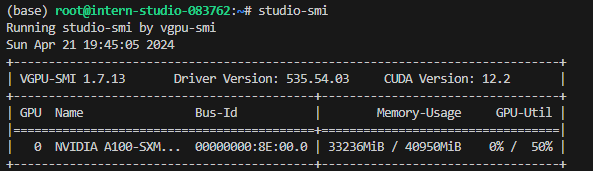
此时模型的占用为 33236M。下面,改变`–cache-max-entry-count`参数,设为 0.5。
lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct/ --cache-max-entry-count 0.5
新建一个终端运行。
# 如果你是InternStudio 就使用
# studio-smi
nvidia-smi
看到显存占用明显降低,变为 26708 M。
下面来一波“极限”,把 --cache-max-entry-count 参数设置为 0.01,约等于禁止 KV Cache 占用显存。
lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct/ --cache-max-entry-count 0.01
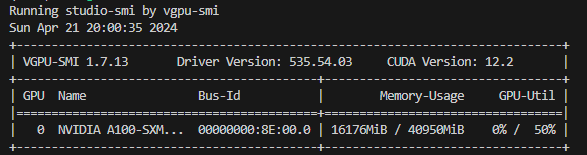
然后与模型对话,可以看到,此时显存占用仅为 16176M,代价是会降低模型推理速度。
3.2 使用 W4A16 量化权重
仅需执行一条命令,就可以完成模型量化工作。
lmdeploy lite auto_awq \
/root/model/Meta-Llama-3-8B-Instruct \
--calib-dataset 'ptb' \
--calib-samples 128 \
--calib-seqlen 1024 \
--w-bits 4 \
--w-group-size 128 \
--work-dir /root/model/Meta-Llama-3-8B-Instruct_4bit
运行时间较长,请耐心等待。量化工作结束后,新的 HF 模型被保存到 Meta-Llama-3-8B-Instruct_4bit 目录。下面使用 Chat 功能运行 W4A16 量化后的模型。
lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct_4bit --model-format awq
为了更加明显体会到 W4A16 的作用,我们将 KV Cache 比例再次调为 0.01,查看显存占用情况。
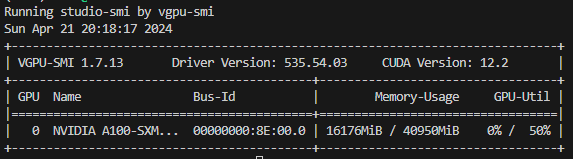
lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct_4bit --model-format awq --cache-max-entry-count 0.01
可以看到,显存占用变为 16176MB,明显降低。
3.3 在线量化 KV
自 v0.4.0 起,LMDeploy KV 量化方式有原来的离线改为在线。并且,支持两种数值精度 int4、int8。量化方式为 per-head per-token 的非对称量化。它具备以下优势:
-
量化不需要校准数据集。
-
kv int8 量化精度几乎无损,kv int4 量化精度在可接受范围之内。
-
推理高效,在 llama2-7b 上加入 int8/int4 kv 量化,RPS 相较于 fp16 分别提升近 30% 和 40%。
-
支持 volta 架构(sm70)及以上的所有显卡型号:V100、20系列、T4、30系列、40系列、A10、A100 等等。
通过 LMDeploy 应用 kv 量化非常简单,只需要设定 quant_policy 参数。LMDeploy 规定 qant_policy=4表示 kv int4 量化,quant_policy=8 表示 kv int8 量化。
4. LMDeploy服务(serve)
在前面的章节,我们都是在本地直接推理大模型,这种方式成为本地部署。在生产环境下,我们有时会将大模型封装为 API 接口服务,供客户端访问。
4.1 启动 API 服务器
通过以下命令启动 API 服务器,推理 Meta-Llama-3-8B-Instruct 模型:
lmdeploy serve api_server \
/root/model/Meta-Llama-3-8B-Instruct \
--model-format hf \
--quant-policy 0 \
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1
其中,model-format、quant-policy 这些参数是与第三章中量化推理模型一致的;server-name 和 server-port 表示 AP I服务器的服务 IP 与服务端口;tp 参数表示并行数量(GPU 数量)。
通过运行以上指令,我们成功启动了 API 服务器,请勿关闭该窗口,后面我们要新建客户端连接该服务。
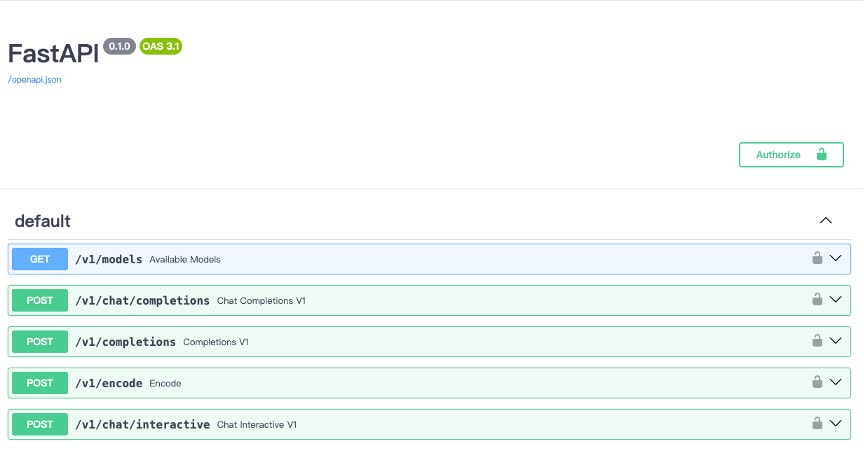
你也可以直接打开 http://{host}:23333 查看接口的具体使用说明,如下图所示。
注意,这一步由于 Server 在远程服务器上,所以本地需要做一下 ssh 转发才能直接访问。在你本地打开一个 cmd 窗口,输入命令如下:
ssh -CNg -L 23333:127.0.0.1:23333 root@ssh.intern-ai.org.cn -p 你的ssh端口号
ssh 端口号就是下面图片里的 39864,请替换为你自己的。

然后打开浏览器,访问 http://127.0.0.1:23333。
4.2 命令行客户端连接 API 服务器
在“4.1”中,我们在终端里新开了一个 API 服务器。
本节中,我们要新建一个命令行客户端去连接 API 服务器。首先通过 VS Code 新建一个终端。
激活 conda 环境:
conda activate lmdeploy
运行命令行客户端:
lmdeploy serve api_client http://localhost:23333
运行后,可以通过命令行窗口直接与模型对话。
4.3 网页客户端连接 API 服务器
关闭刚刚的 VSCode 终端,但服务器端的终端不要关闭。
运行之前确保自己的 gradio 版本低于 4.0.0。
pip install gradio==3.50.2
新建一个 VSCode 终端,激活 conda 环境。
conda activate lmdeploy
使用 Gradio 作为前端,启动网页客户端。
lmdeploy serve gradio http://localhost:23333 \
--server-name 0.0.0.0 \
--server-port 6006
打开浏览器,访问地址 http://127.0.0.1:6006
然后就可以与模型进行对话了!
拓展部分
5. LMDeploy Llama3 推理测速
使用 LMDeploy 在 A100(80G)推理 Llama-3-8B-Instruct,每秒请求处理数(RPS)高达 25,是 vLLM 推理效率的 1.8+ 倍。
它的 benchmark 方式如下:
克隆仓库
cd ~
git clone https://github.com/Shengshenlan/Llama3-XTuner-CN.git
下载测试数据
cd /root/lmdeploy
wget https://hf-mirror.com/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json
执行 benchmark 命令(如果你的显存较小,可以调低 --cache-max-entry-count)
python benchmark/profile_throughput.py \
ShareGPT_V3_unfiltered_cleaned_split.json \
/root/model/Meta-Llama-3-8B-Instruct \
--cache-max-entry-count 0.95 \
--concurrency 256 \
--model-format hf \
--quant-policy 0 \
--num-prompts 10000
结果是:
concurrency: 256
elapsed_time: 399.739s
first token latency(s)(min, max, ave): 0.068, 4.066, 0.285
per-token latency(s) percentile(50, 75, 95, 99): [0, 0.094, 0.169, 0.227]
number of prompt tokens: 2238364
number of completion tokens: 2005448
token throughput (completion token): 5016.892 token/s
token throughput (prompt + completion token): 10616.453 token/s
RPS (request per second): 25.016 req/s
RPM (request per minute): 1500.979 req/min
6. 使用 LMDeploy
运行视觉多模态大模型
Llava-Llama-3
6.1 安装依赖
pip install git+https://github.com/haotian-liu/LLaVA.git
6.2 运行模型
运行 touch /root/pipeline_llava.py 新建一个文件夹,复制下列代码进去:
from lmdeploy import pipeline, ChatTemplateConfig
from lmdeploy.vl import load_image
pipe = pipeline('xtuner/llava-llama-3-8b-v1_1-hf',
chat_template_config=ChatTemplateConfig(model_name='llama3'))
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
response = pipe(('describe this image', image))
print(response.text)
运行结果为: