文章目录
- 1. 前言
- 2. UDF与宏及静态表的对比
- 3. 深入理解UDF
- 4. 实现自定义UDF
1. 前言
在大数据技术栈中,Apache Hive 扮演着数据仓库的关键角色,它提供了丰富的数据操作功能,并通过类似于 SQL 的 HiveQL 语言简化了对 Hadoop 数据的处理。然而,内置函数库虽强大,却未必能满足所有特定的业务逻辑需求。此时,用户定义函数(User-Defined Functions,UDF)的重要性便凸显出来。
Hive UDF(User-Defined Function)是Hive中的一种扩展机制,它允许用户通过编写自定义的Java代码来扩展Hive的功能,实现Hive内置函数无法提供的一些特定数据处理逻辑。
2. UDF与宏及静态表的对比
除了UDF可以自定义输入和输出还有例如静态表,宏定义的方式也可以实现类似的操作,举个例子:在数据中筛选出已达到退休年龄的员工。
UDF 示例
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public class RetirementStatusUDF extends UDF {
public Text evaluate(int age) {
return new Text(age >= 60 ? "已达到退休年龄" : "未达到退休年龄");
}
}
-- 添加UDF的jar包到Hive
ADD JAR /path/to/udf.jar;
-- 创建临时函数
CREATE TEMPORARY FUNCTION retirement_status AS 'com.example.RetirementStatusUDF';
-- 使用UDF进行查询
SELECT name, age, retirement_status(age) AS status
FROM employee_static;
静态表
CREATE TABLE employee_static (
age INT,
flag STRING -- 'retired' 或 'active'
);
-- 查询已达到退休年龄的员工
SELECT a.*
FROM employee_data a
JOIN employee_static b
ON a.age = b.age AND b.flag = 'retired';
宏定义
drop temporary macro if exists get_retired;
create temporary macro get_retired(age bigint)
if (
age is not null,
case
when age >= 60 then '退休'
when age <= 60 then '未退休'
else null
end,
null
);
使用UDF(用户定义函数)的原因与宏和静态表的功能有所不同,它们各自适用于不同的场景和需求。以下是使用UDF的几个关键原因:
| 特性/方法 | UDF(用户定义函数) | 宏(Macro) | 静态表(Static Table) |
|---|---|---|---|
| 定义 | 允许用户通过编写自定义的Java代码来扩展Hive的功能,实现特定的数据处理逻辑。 | 在Hive中,宏是一种用户定义的快捷方式,用于封装一系列HiveQL语句,以便在查询中重复使用。 | 预先定义和填充的数据集,其结构和内容在创建后通常保持不变。 |
| 使用场景 | 适用于执行Hive内置函数不支持的特定数据处理逻辑,如复杂的业务规则或算法。 | 主要用于简化和重用HiveQL查询语句,提高代码的可读性和易维护性。 | 适用于存储已知的、不变的数据集,供多次查询使用,无需每次重新计算。 |
| 灵活性 | 高,可以根据需求定制数据处理流程。 | 中等,主要用于简化复杂的查询,但不具备动态处理能力。 | 低,结构和内容一旦定义,通常不发生变化。 |
| 性能 | 可优化,Hive执行UDF时会进行优化,性能接近内置函数。 | 取决于宏定义的查询的复杂性,可能提高或降低性能。 | 预先计算,查询时性能较高,适合重复查询相同数据集。 |
| 重用性 | 高,一旦创建和注册,可以在不同的Hive会话中重复使用。 | 高,宏可以定义一次并在多个查询中重复使用。 | 中等,表结构和数据不变,适用于重复查询相同数据集的场景。 |
| 实时性 | 支持实时数据处理,每次调用UDF时根据输入动态执行计算。 | 不直接支持实时数据处理,主要用于查询语句的封装。 | 不支持实时数据处理,通常是预先计算和存储的。 |
| 适应性 | 强,可以快速适应新的数据处理需求。 | 中等,需要修改宏定义以适应新的需求。 | 弱,结构和数据固定,不适合频繁变化的数据需求。 |
| 示例应用 | 用于实现如复杂数学计算、自定义字符串处理、数据清洗等。 | 用于封装复杂的查询模板,如多步骤的数据转换过程。 | 用于存储配置数据、参考数据或不需要频繁更新的数据。 |
选择使用UDF、宏还是静态表应基于具体的业务需求、数据特性和性能考虑。每种方法都有其独特的优势和适用场景。
3. 深入理解UDF
Hive UDF可以分为三种主要类型:UDF、UDAF和UDTF。
- UDF (User-Defined Function):
- 标量函数,用于一对一(one-to-one)的映射,即对单个数据项进行操作并返回单个结果。
- 例如,字符串处理(
upper,substr)、数学计算(sqrt)、日期时间转换等。
- UDAF (User-Defined Aggregate Function):
- 聚合函数,用于多对一(many-to-one)的映射,即对多行数据进行聚合操作并返回单个结果。
- 例如,自定义的求和(
sum)、平均值(avg)、最大值(max)、最小值(min)等。
- UDTF (User-Defined Table-Generating Function):
- 表生成函数,用于一对多(one-to-many)的映射,即对单个数据项进行操作并返回多行结果。
- 例如,
explode函数可以将数组或Map类型的列拆分成多行。
| 类别简称 | 全称 | 描述 | 示例 |
|---|---|---|---|
| UDF | User-Defined Function | 用于实现一对一的映射,即一个输入对应一个输出。 | 将字符串转换为大写。 |
| UDAF | User-Defined Aggregate Function | 用于实现一对多的映射,即多个输入对应一个输出。 | 计算某个字段的总和或平均值。 |
| UDTF | User-Defined Table-Generating Function | 用于实现一对多的行生成,即一个输入可以产生多行输出。 | 将数组或映射类型的字段展开成多行数据。 |
这些UDF类型允许开发者根据特定的数据处理需求,编写和实现自定义的函数逻辑,从而扩展Hive的数据处理能力。通过使用UDF、UDAF和UDTF,用户可以在Hive中实现更加复杂和定制化的数据处理任务。
实现一个UDF通常涉及以下步骤:
- 编写UDF类:在Java中创建一个类,实现Hive UDF接口的相应方法。对于标量UDF,这通常是
evaluate方法。 - 编译与打包:将UDF类编译成Java字节码,并打包成JAR文件。
- 上传JAR包:将JAR文件上传到HDFS或其他Hive可以访问的文件系统中。
- 注册UDF:在Hive会话中使用
ADD JAR和CREATE TEMPORARY FUNCTION命令注册UDF。 - 使用UDF:在Hive查询中调用注册的UDF,就像调用内置函数一样。

4. 实现自定义UDF
在深入探讨Hive UDF的实现之前,让我们首先确保开发环境的准备妥当。对于UDF的编写,推荐使用Maven来配置Java项目,这样可以方便地管理依赖和构建过程。以下是配置Java开发环境的一个示例,包括使用的版本信息和Maven设置:
Apache Maven 3.9.6
Java version: 1.8.0_211,
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>project202401</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hadoop.version>3.1.1.7.1.7.2000-305</hadoop.version>
<hive.version>3.1.3000.7.1.7.2000-305</hive.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>5.10.1</version>
<scope>test</scope>
</dependency>
</dependencies>
<repositories>
<repository>
<id>central</id>
<name>Maven Central</name>
<url>https://repo1.maven.org/maven2/</url>
</repository>
<repository>
<id>cloudera</id>
<name>Cloudera Repository</name>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
</project>
下面是一个Hive UDF(用户定义函数)的示例,该UDF的作用是将传入的字符串转换为大写形式。我将对代码进行注释,并解释其工作流程:
import org.apache.hadoop.io.Text; // 引入Hadoop的Text类,用于处理字符串
import org.apache.hadoop.hive.ql.exec.UDF; // 引入Hive的UDF类
@SuppressWarnings({"deprecation", "unused"}) // 忽略警告,例如未使用的警告或过时API的警告
public class UpperCaseUDF extends UDF { // 定义一个名为UpperCaseUDF的类,继承自UDF
/**
* 该方法重写了UDF类中的evaluate方法,是UDF的核心。
* 它接收一个Text类型的数据,然后返回转换为大写的Text类型数据。
*
* @param line Text类型的输入数据
* @return 转换为大写的Text类型的数据
*/
public Text evaluate(final Text line) {
// 检查传入的Text是否为非空且内容不为空字符串
if (null != line && !line.toString().equals("")) {
// 将Text转换为String,并使用String的toUpperCase方法转换为大写
String str = line.toString().toUpperCase();
// 将大写字符串重新设置回Text对象,并返回
line.set(str);
return line;
} else {
// 如果传入的Text为null或空字符串,则返回一个新的空Text对象
return new Text();
}
}
}
在Hive的较新版本中,推荐使用GenericUDF而不是直接继承UDF。以下是使用GenericUDF实现的UpperCaseUDF2的示例代码,以及对代码的详细解释和工作流程分析:
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.StringObjectInspector;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.hive.ql.udf.UDFType;
@UDFType(deterministic = true, stateful = false) // 标注UDF的特性,确定性且无状态
public class UpperCaseUDF2 extends GenericUDF { // 继承自GenericUDF
private StringObjectInspector inputOI; // 输入对象检查员,用于检查输入类型
private StringObjectInspector outputOI; // 输出对象检查员,用于定义输出类型
/**
* initialize方法在UDF首次执行时被调用,用于初始化UDF。
* @param arguments 传入的参数对象检查员数组
* @return 输出对象检查员
* @throws UDFArgumentException 如果输入参数不符合预期,抛出异常
*/
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
// 确保传入的参数是字符串类型
if (arguments == null || arguments.length == 0) {
throw new UDFArgumentException("arguments array is null or empty.");
}
if (!(arguments[0] instanceof StringObjectInspector)) {
// 如果不是字符串类型,抛出Hive异常
throw new UDFArgumentException("The input to UpperCaseUDF2 must be a string");
}
// 将输入参数的对象检查员赋值给局部变量
inputOI = (StringObjectInspector) arguments[0];
// 定义输出对象检查员为可写的字符串对象检查员
outputOI = PrimitiveObjectInspectorFactory.writableStringObjectInspector;
// 返回输出对象检查员
return outputOI;
}
/**
* evaluate方法定义了UDF的实际逻辑,即如何将输入转换为输出。
* @param arguments 包含延迟计算的输入对象的数组
* @return 转换后的大写文本
* @throws HiveException 如果在执行过程中遇到Hive异常
*/
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
// 从延迟对象中获取输入字符串
Text line = (Text) arguments[0].get();
// 如果输入不为空,则转换为大写
if (line != null && !line.toString().isEmpty()) {
return new Text(line.toString().toUpperCase());
}
// 如果输入为空,返回空字符串
return new Text();
}
/**
* getDisplayString方法返回UDF的可读字符串表示,用于Hive日志和解释计划。
* @param strings 输入参数的字符串表示,通常由Hive自动生成
* @return UDF的可读字符串表示
*/
@Override
public String getDisplayString(String[] strings) {
// 返回UDF的名称,用于解释计划和日志
return "UpperCaseUDF2()";
}
}
add jar URL/project202401-1.0-SNAPSHOT.jar;
create temporary function UpperCaseUDF as 'com.xx.hive.udf.UpperCaseUDF';
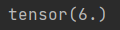
select UpperCaseUDF('Hive Is Fun') a ;
HIVE IS FUN
通过以上步骤,我们能够创建出高效、可靠的Hive UDF,以满足特定的数据处理需求。UDF的开发不仅需要关注功能的实现,还要重视性能优化和代码的可维护性。正确地使用UDF可以显著提升数据处理的效率,为用户提供强大的数据操作能力。
因为篇幅有限,后面两种自定义UDF,会在下一篇博文展开叙述。






![[Algorithm][前缀和][和为K的子数组][和可被K整除的子数组][连续数组][矩阵区域和]详细讲解](https://img-blog.csdnimg.cn/direct/62502bb9feed47ea98b3674669cc7d45.png)