作者介绍:10年大厂数据\经营分析经验,现任大厂数据部门负责人。
会一些的技术:数据分析、算法、SQL、大数据相关、python
欢迎加入社区:码上找工作
作者专栏每日更新:
LeetCode解锁1000题: 打怪升级之旅
python数据分析可视化:企业实战案例
1. 引言
在数据驱动的时代,排序算法无处不在,它们是计算机科学的基石之一。无论是在大数据分析、数据库管理、搜索引擎优化,还是在日常软件开发中,有效的排序都是提高效率和性能的关键。但是,排序不仅仅是将数据元素排列成有序序列那么简单,它是一种基础而强大的数据操作,影响着数据结构的选择和算法设计的整体策略。
为什么排序重要?
排序问题的重要性主要体现在以下几个方面:
- 数据检索:在排序的数据集上进行搜索比在未排序的数据集上更高效(比如,二分搜索法的前提是数据已排序)。
- 数据结构优化:许多数据结构(如优先队列、搜索树等)在内部使用排序机制来提高各种数据操作的效率。
- 信息可视化:在数据分析和科学计算中,排序是数据预处理的重要步骤,有助于识别趋势、异常和模式。
- 算法优化:许多更复杂的算法(如集合操作或数据库联接操作)的性能可以通过先对数据进行排序来显著提升。
排序的实际应用
实际应用中,排序算法的选择可能会根据具体情况而有很大差异。例如:
- 在实时系统中,如交易系统,我们可能更倾向于使用时间复杂度最优的排序算法来保证快速响应。
- 在处理极大数据集的分布式系统中,如使用Hadoop或Spark的环境,排序算法必须能有效地分布在多个节点上处理。
- 在有严格内存限制的嵌入式系统中,空间效率也许是选择排序算法的决定性因素。
通过探索各种排序算法的性能特点和适用场景,我们不仅可以对它们的工作原理有一个系统的了解,还可以根据实际需要选择或者设计出最适合的算法。
2. 排序算法的分类
- 比较类排序:基于比较元素之间的大小关系来进行排序。
- 非比较类排序:不通过比较来决定元素间的顺序。
3. 常见的排序算法详解
算法思维导图概览

3.1 冒泡排序 (Bubble Sort)
①工作原理
- 遍历列表:从列表的第一个元素开始,比较相邻的两个元素。
- 比较和交换:如果一对元素是逆序的(即,左边的元素比右边的元素大),则交换它们的位置。
- 重复步骤:遍历整个列表,对每一对相邻元素执行步骤2,重复此过程,每次循环结束时,最大的元素会被放置在其最终位置上。
- 终止条件:当遍历列表时没有进行任何交换时,说明列表已经完全排序,此时算法结束。
②案例分析 力扣2
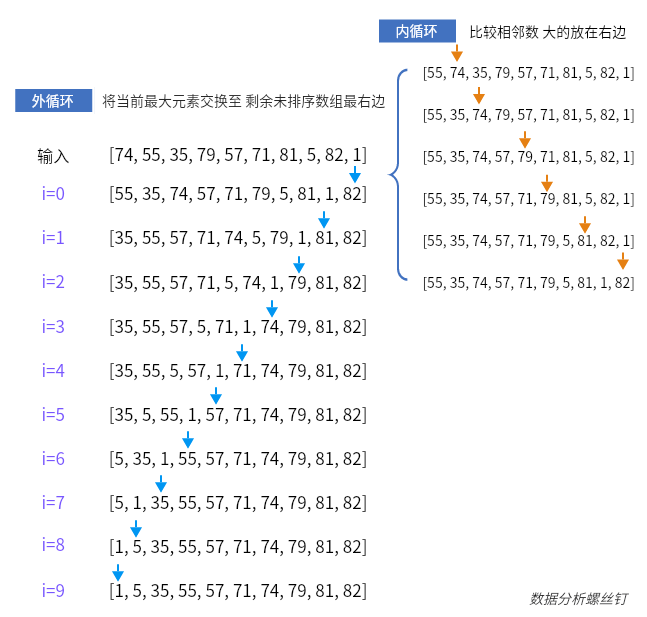
对输入的数组进行冒泡排序,输出排序后的数组
输入:[74,55,35,79,57,71,81,5,82,1]
输出:[1,5,35,55,57,71,74,79,81,82]。
内循环(比较与交换):算法从数组的第一个元素开始,比较相邻的元素对 (j, j+1)。如果 j 位置的元素大于 j+1 位置的元素(对于升序排序),则这两个元素的位置会被交换。这一过程一直重复,直到到达数组的末尾。每完成一轮内循环,都能保证这一轮中最大的元素被"冒泡"到其最终位置(即数组的最右端)。
要注意的优化:防止已经排序的重复执行,通过增加一个标志位 flag ,若在某轮「内循环」中未执行任何交换操作,则说明数组已经完成排序,直接返回结果即可。这个在已经排序好的情况下 可以减少不必要的比较
外循环(迭代排序的过程):外循环控制内循环的重复执行,每执行完一次内循环后,排序的范围就减少一个元素(因为每次内循环都会将当前未排序部分的最大元素放到正确的位置)。外循环持续进行,直到整个数组排序完成。
动态图

③代码示例
def bubble_sort(arr):
n = len(arr)
for i in range(n):
# 标记变量,用于优化检测是否有元素交换
swapped = False
# 最后的元素已经放置好了,每次迭代可以减少一次
for j in range(0, n-i-1):
# 从头到尾进行比较,不断交换直到最大的数“冒泡”到最后
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
swapped = True
# 如果在某次遍历中没有数据交换,表示已经完成排序,可以提前退出
if not swapped:
break
使用冒泡排序算法的示例代码体现了算法的直接性和简洁性,但在处理大数据集时,更高效的算法通常是更好的选择。
④算法分析
时间复杂度
- 最好情况复杂度:(O(n))。当列表已经完全排序时,只需要进行一次遍历,如果没有发生交换,则排序完成。
- 平均情况复杂度:(O(n^2))。每个元素都需要与其余的( n-1 )个元素比较,并可能需要交换。
- 最坏情况复杂度:(O(n^2))。当列表完全逆序时,每个元素都需进行( n-1 )次比较和交换。
空间复杂度
- 空间复杂度:(O(1))。冒泡排序是原地排序算法,除了原始列表,只需要常数级别的额外空间。
3.2 快速排序 (Quick Sort)
快速排序是由英国计算机科学家托尼·霍尔在1960年代提出的一种高效的排序算法。它使用分治策略来把一个序列分为两个子序列,具有较小的元素和较大的元素。
①工作原理
- 选择基准值:在数据集中,选择一个元素作为“基准”(pivot)。
- 分区操作:重新排列数据,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
- 递归排序:递归地将小于基准值元素的子序列和大于基准值元素的子序列排序。
快速排序的效率在于它可以在划分数组的同时进行排序。
②案例分析 力扣912
给你一个整数数组 nums,请你将该数组升序排列。
示例 1:
输入:nums = [5,2,3,1]
输出:[1,2,3,5]
示例 2:
输入:nums = [5,1,1,2,0,0]
输出:[0,0,1,1,2,5]

③代码示例
class Solution:
def sortArray(self, nums):
"""
主函数,调用快速排序函数对数组进行排序
:param nums: List[int] 需要排序的整数数组
:return: List[int] 排序后的数组
"""
def quickSort(low, high):
"""
快速排序的递归函数
:param low: int 数组的起始索引
:param high: int 数组的结束索引
"""
if low < high:
pi = partition(low, high)
quickSort(low, pi - 1)
quickSort(pi + 1, high)
def partition(low, high):
"""
对数组进行分区,返回基准点索引
:param low: int 分区的起始索引
:param high: int 分区的结束索引
:return: int 基准点的索引
"""
pivot = nums[high] # 选取最后一个元素作为基准
i = low - 1 # 小于基准的元素的索引
for j in range(low, high):
if nums[j] < pivot:
i += 1
nums[i], nums[j] = nums[j], nums[i] # 交换元素
nums[i+1], nums[high] = nums[high], nums[i+1] # 将基准元素放到正确位置
return i + 1
quickSort(0, len(nums) - 1) # 从整个数组的范围开始排序
return nums
快速排序因其优异的平均性能和简单的实现成为了排序算法的首选,尤其是在处理大型数据集时。
④算法分析
- 时间复杂度:
- 最好情况:(O(n \log n)),通常的情况下是所有排序算法中最快的。
- 平均情况:(O(n \log n))。
- 最坏情况:(O(n^2)),当数据已经是正序或者逆序时。
- 空间复杂度:
- (O(\log n)),主要是递归造成的栈空间的使用。
3.3 归并排序 (Merge Sort)
①工作原理
- 分解:递归地把当前序列平均分割成两半。
- 解决:递归地解决每个子序列。
- 合并:将两个排序好的子序列合并成一个最终的排序序列。
②案例分析 力扣912
继续用力扣(LeetCode)上“912. 排序数组”问题可以使用归并排序解决。由于归并排序效率高并且稳定,特别适用于大数据集排序。

③代码示例
class Solution:
def sortArray(self, nums: List[int]) -> List[int]:
# 如果数组长度大于1,则继续分解
if len(nums) > 1:
# 找到中间索引,进行分割
mid = len(nums) // 2
# 分割成两个子数组
L = nums[:mid]
R = nums[mid:]
# 递归排序两个子数组
self.sortArray(L)
self.sortArray(R)
i = j = k = 0
# 合并两个有序子数组
while i < len(L) and j < len(R):
if L[i] < R[j]:
nums[k] = L[i]
i += 1
else:
nums[k] = R[j]
j += 1
k += 1
# 将剩余的元素复制到原数组中
while i < len(L):
nums[k] = L[i]
i += 1
k += 1
while j < len(R):
nums[k] = R[j]
j += 1
k += 1
# 返回排序后的数组
return nums
④算法分析
- 时间复杂度:归并排序在最好、最坏和平均情况下都具有 (O(n \log n)) 的时间复杂度。
- 空间复杂度:由于需要与原数组同等长度的存储空间来存储合并后的数组,所以空间复杂度为 (O(n))。
- 稳定性:归并排序是一种稳定的排序算法,因为合并操作不会改变相同元素之间的相对顺序。
归并排序尤其适合用于链表类型的数据结构,或者大型数据集合中,因为它能够提供稳定且一致的性能。
3.4 堆排序 (Heap Sort)
堆排序是基于堆数据结构的一种比较排序算法。堆是一种近似完全二叉树的结构,且满足堆积性质:即任意节点的值总是不大于(或不小于)其子节点的值。
①工作原理
- 建立堆:将给定无序数组构造成一个最大堆(或最小堆)。
- 交换元素:将堆顶元素(最大值或最小值)与数组末尾元素交换,并将堆的有效大小减一。
- 恢复堆:将新的未排序的堆顶元素调整到合适位置,以重新满足堆的性质。
- 重复步骤:重复步骤2和3,直到堆的有效大小为1,此时数组已经排序完成。
②力扣案例分析
在力扣(LeetCode)上,题号为“215. 数组中的第K个最大元素”可以通过堆排序的方式来解决。堆排序非常适合用于解决此类问题,因为它可以在O(N log N)的时间内排序,同时可以在O(N)时间内构建堆,而且堆结构使得它能以O(log N)时间找到最大或最小值。

③代码示例
class Solution:
def sortArray(self, nums: List[int]) -> List[int]:
# 建立最大堆
def heapify(arr, n, i):
largest = i
l = 2 * i + 1
r = 2 * i + 2
if l < n and arr[l] > arr[largest]:
largest = l
if r < n and arr[r] > arr[largest]:
largest = r
if largest != i:
arr[i], arr[largest] = arr[largest], arr[i]
heapify(arr, n, largest)
# 主函数,调用堆排序
n = len(nums)
# 建立堆
for i in range(n // 2 - 1, -1, -1):
heapify(nums, n, i)
# 一个个交换元素
for i in range(n-1, 0, -1):
nums[i], nums[0] = nums[0], nums[i]
heapify(nums, i, 0)
return nums
④算法分析
- 时间复杂度:堆排序的时间复杂度为O(N log N),其中N是数组的长度。这是因为建立堆的过程是O(N),而进行N次调整的过程是O(N log N)。
- 空间复杂度:堆排序是原地排序,不需要额外的存储空间,所以空间复杂度为O(1)。
- 稳定性:堆排序是不稳定的排序算法,因为在调整堆的过程中,无法保证相同元素的相对顺序不变。
附件
部分动态图片来自:https://github.com/hustcc/JS-Sorting-Algorithm