1. 依赖
hbase => hbase 集群搭建
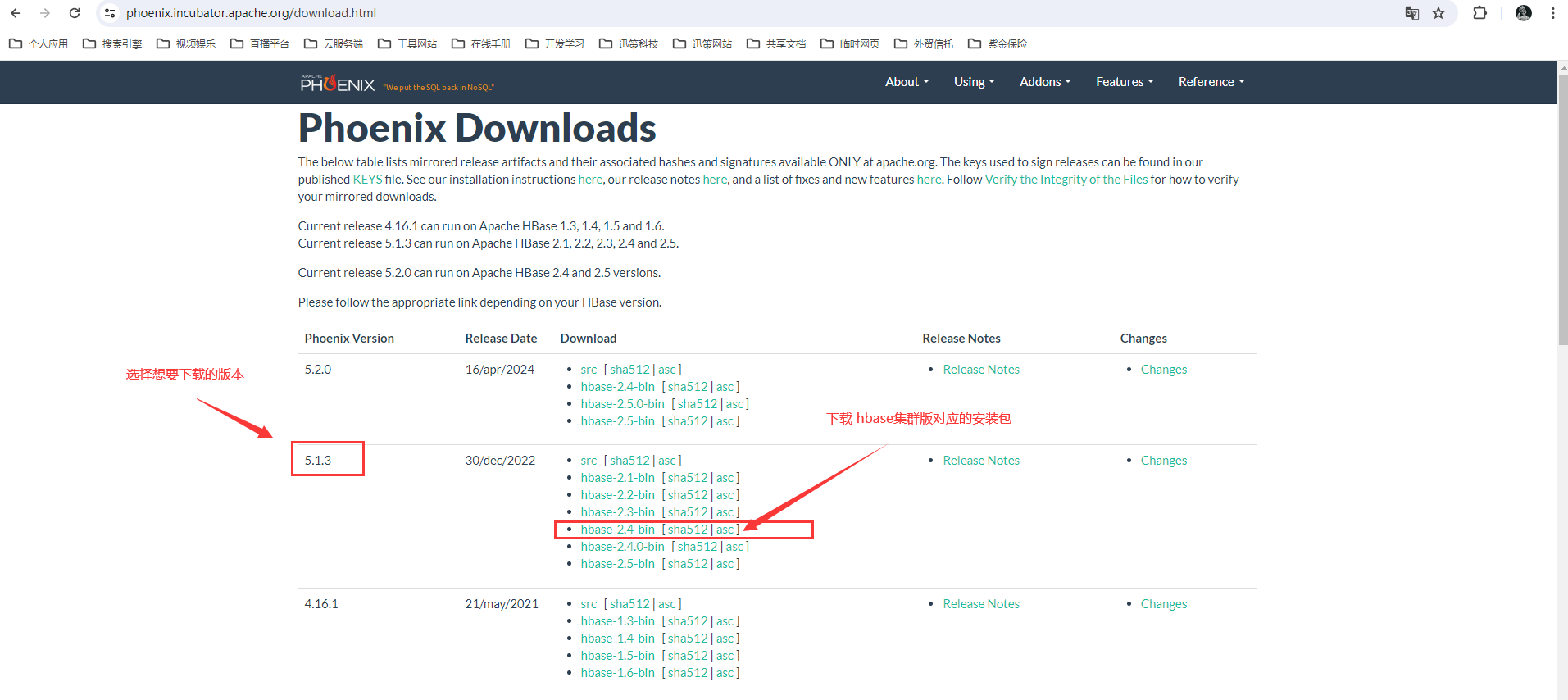
2. 下载安装包
点击下载
ps:该网页在内网可能打不开,遇到该情况有条件的可以打开 VPN 在下载
3. 上传解压
使用工具将安装包上传的服务器上
笔者这里选择 上传到 /opt/software 目录,解压到 /opt/module 这两个目录可以随意选择
tar -zxvf phoenix-hbase-2.4-5.1.3-bin.tar.gz -C /opt/module
cd /opt/module
mv phoenix-hbase-2.4-5.1.3-bin phoenix
4. 安装服务器
phoenix 是依赖于 hbse 集群的,可以说只是 hbase 的皮肤
安装只需要将服务包放到 hbase 的 lib 依赖库里即可,注意一台集群都需要拷贝到位,可以先拷贝一台,借助分发脚本分发
cd /opt/module/phoenix
cp phoenix-server-hbase-2.4-5.1.3.jar /opt/module/hbase/lib/
xsync.sh /opt/module/hbase/lib
PS:拷贝完成后一定要重启 hbase 集群
5. 客户端连接
# 第一次启动需要较长的时间,请耐心等待,这里的参数是 zookeepeer 集群连接
cd /opt/module/phoenix
./bin/sqlline.py mitchell-101,mitchell-102,mitchell-103:2181
# 测试命令,查看所有表,如果安装成功,我们应该能看到很多系统表
!table

6. JDBC 连接
6.1. 客户端依赖
下方的依赖包目前在公共的中央仓库是不存在的,只有一些低版本的依赖,我们无法使用
这里我们只能将安装包解压出来的客户端安装到我们的 maven 中,如果有仓库的可以上传仓库
笔者这边选择安装到本地仓库
1,将解压后目录中的 客户端 下载到本地(如下图)
2,使用 maven 命令安装
mvn install:install-file -DgroupId=org.apache.phoenix -DartifactId=phoenix-client -Dversion=2.4-5.1.3 -Dpackaging=jar -D file=phoenix-client-hbase-2.4-5.1.3.jar
3,在项目中使用
<!-- phoenix 客户端依赖 -->
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-client</artifactId>
<version>2.4-5.1.3</version>
</dependency>
6.2. 简单示例
package com.mitchell.mus.tests.main;
import java.sql.*;
import java.util.Properties;
public class PhoneixTests {
public static void main(String[] args) throws SQLException {
// 声明地址和参数配置
String jdbcUrl = "jdbc:phoenix:mitchell-101,mitchell-102,mitchell-103:2181";
Properties properties = new Properties();
// 获取连接
Connection conn = DriverManager.getConnection(jdbcUrl, properties);
// 获取操作对象
Statement statement = conn.createStatement();
// 执行语句并获取返回结果
ResultSet resultSet = statement.executeQuery("select * from system.catalog");
// 打印返回的结果
while (resultSet.next()) {
String tableName = resultSet.getString("TABLE_NAME");
String columnName = resultSet.getString("COLUMN_NAME");
System.out.println(tableName + "." + columnName);
}
// 关闭连接
resultSet.close();
statement.close();
conn.close();
}
}
7. 启用二级索引
7.1. 修改配置
cd /opt/module/hbase/conf/
vim hbase-site.xml
添加下方配置
<!-- 设置编解码器,通过在 WAL 日志中添加索引信息,是 phoenix 二级索引的前置配置 -->
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
PS:记得分发到所有集群节点,然后重启集群
7.2. 全局索引
-- 创建表,必须要主键,支持联合主键
CREATE TABLE IF NOT EXISTS HB_USER (
ID INTEGER PRIMARY KEY,
NAME VARCHAR,
AGE INTEGER
);
-- 新增/修改
UPSERT INTO HB_USER (ID, NAME, AGE) VALUES (1, '张三', 30);
UPSERT INTO HB_USER (ID, NAME, AGE) VALUES (2, '李四', 40);
-- 创建全局索引
CREATE INDEX IX_USER ON HB_USER(AGE);
-- 通过查看执行计划确定索引是否生效
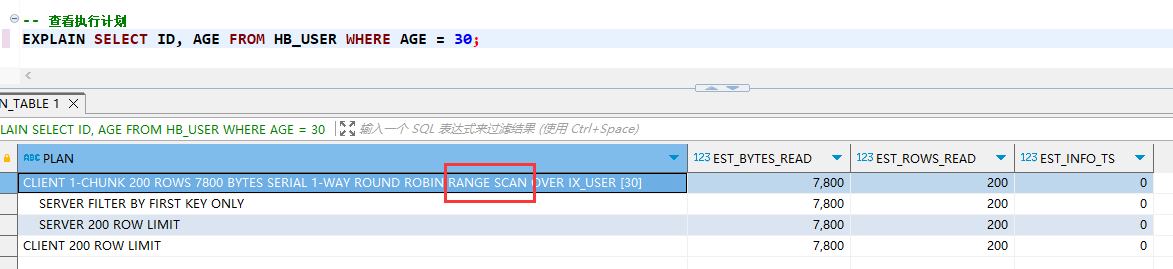
EXPLAIN SELECT ID, AGE FROM HB_USER WHERE AGE = 30;
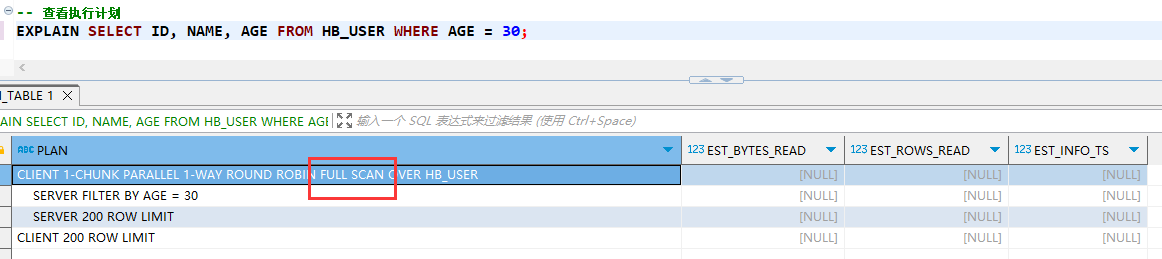
EXPLAIN SELECT ID, NAME, AGE FROM HB_USER WHERE AGE = 30;
全局索引会创建一张表,专门记录 索引字段 与 主键 的映射信息,查询的时候先查询索引表获取主键,在通过主键去取数据,从而提高查询效率,其比较适用于读多写少的应用场景。
但在查询时存在很大弊端:即想查询的字段如果不是索引字段的话,索引不会生效,比如例子中 id 主键,age 是索引,只查这两个字段索引可以生效,但是如果同时查询 name 的话索引就不生效了,如下图
7.3. 包含索引
为了解决全局索引的弊端,我们可以采取包含索引的方式,包含索引也是全局索引的一种,如果要使用全局索引建议使用包含索引
-- 删除索引
DROP INDEX IX_USER ON HB_USER;
-- 创建包含索引,本质上就是将想要和该索引字段一起查询的字段 INCLUDE 进去
CREATE INDEX IX_USER ON HB_USER(AGE) INCLUDE (NAME);
-- 查看执行计划
EXPLAIN SELECT ID, NAME, AGE FROM HB_USER WHERE AGE = 30;
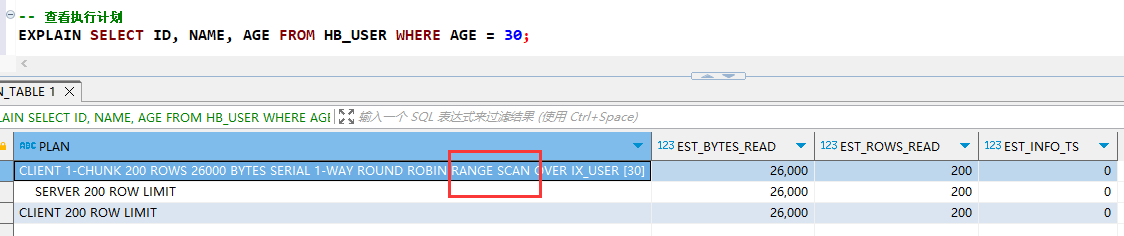
但是包含索引会让索引表的数据量变得很大
7.4. 本地索引(推荐)
本地索引不会创建表,数据都写在同一张表且是同一个 region 中,所以特别适合写操作频繁的表
-- 删除索引
DROP INDEX IX_USER ON HB_USER;
-- 创建本地索引
CREATE LOCAL INDEX IX_USER ON HB_USER(AGE);
-- 查看执行计划
EXPLAIN SELECT ID, NAME, AGE FROM HB_USER WHERE AGE = 30;
但是本地索引的查询性能要低于全局索引
![[Algorithm][前缀和][和为K的子数组][和可被K整除的子数组][连续数组][矩阵区域和]详细讲解](https://img-blog.csdnimg.cn/direct/62502bb9feed47ea98b3674669cc7d45.png)