传奇开心果博文系列
- 系列博文目录
- Python深度学习库技术点案例示例系列
- 博文目录
- 前言
- 一、深度学习在自动驾驶方面的应用介绍
- 二、目标检测和识别示例代码
- 三、路况感知示例代码
- 四、行为预测示例代码
- 五、路径规划示例代码
- 六、自动驾驶控制示例代码
- 七、感知融合示例代码
- 八、高精度地图构建示例代码
- 九、强化学习示例代码
- 十、对抗性攻击防御示例代码
- 十一、模型优化和加速示例代码
- 十二、知识点归纳
系列博文目录
Python深度学习库技术点案例示例系列
博文目录
前言

深度学习在自动驾驶领域的应用非常广泛,它可以帮助车辆感知周围环境、做出决策和规划行驶路径。深度学习在自动驾驶领域的应用可以提高车辆的感知能力、决策能力和自主行驶能力,从而实现更加安全、高效和舒适的自动驾驶体验。深度学习在自动驾驶领域的应用不断拓展和深化,为实现更加智能、安全和可靠的自动驾驶技术提供了强大的支持。随着深度学习算法的不断发展和优化,相信自动驾驶技术将会取得更大的突破和进步。
一、深度学习在自动驾驶方面的应用介绍


以下是深度学习在自动驾驶方面的一些主要应用:
-
目标检测和识别:深度学习模型可以通过分析车辆周围的摄像头图像或激光雷达数据,识别和跟踪其他车辆、行人、交通标识等道路上的目标物体。
-
路况感知:深度学习可以帮助车辆识别道路的标线、交通信号灯、路口、障碍物等,从而帮助车辆更好地理解周围环境和规划行驶路径。
-
行为预测:通过分析其他车辆和行人的行为模式,深度学习模型可以预测它们的未来动作,从而帮助车辆做出更加智能的决策。
-
路径规划:深度学习可以帮助车辆规划最佳的行驶路径,考虑到交通状况、道路限速、交通规则等因素,以确保安全和高效的行驶。
-
自动驾驶控制:深度学习可以帮助车辆实现自动驾驶的控制,包括加速、制动、转向等操作,以实现完全无人驾驶或辅助驾驶功能。
-
感知融合:深度学习可以帮助车辆将来自不同传感器(如摄像头、激光雷达、雷达等)的数据进行融合,提高对周围环境的感知能力和准确性。
-
高精度地图构建:深度学习可以通过车载传感器获取的数据,帮助车辆构建高精度的地图,包括道路几何、交通标识、路口信息等,以支持自动驾驶决策和路径规划。
-
强化学习:深度学习结合强化学习技术,可以帮助车辆通过与环境的交互学习最优的驾驶策略,不断优化驾驶行为和决策。
-
对抗性攻击防御:深度学习可以用于检测和防御对自动驾驶系统的对抗性攻击,保障车辆的安全性和可靠性。
-
模型优化和加速:针对自动驾驶系统中的深度学习模型,需要进行模型优化和加速,以满足实时性和效率的要求。

二、目标检测和识别示例代码
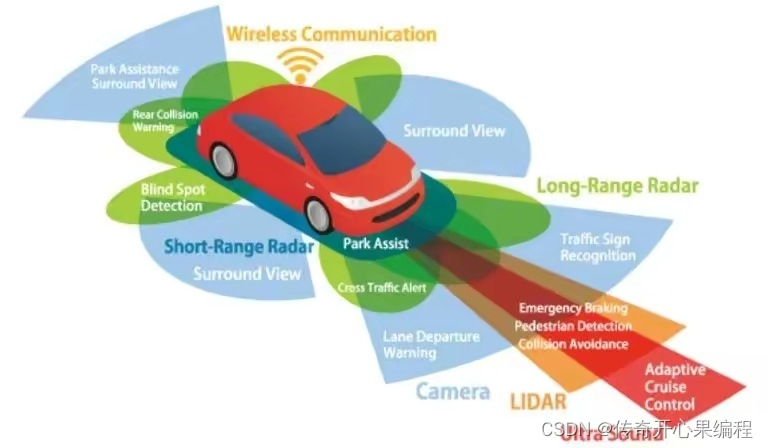
以下是一个简单的示例代码,演示如何使用深度学习模型进行目标检测和识别,识别和跟踪道路上的目标物体(如车辆、行人、交通标识):
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 使用OpenCV加载已经训练好的目标检测模型,如YOLO、SSD、Faster R-CNN等
net = cv2.dnn.readNet("pretrained_model.weights", "pretrained_model.cfg")
# 加载类别标签
classes = []
with open("classes.txt", "r") as f:
classes = [line.strip() for line in f.readlines()]
# 读取测试图像
image = cv2.imread("test_image.jpg")
height, width, _ = image.shape
# 将图像转换为blob格式,用于输入深度学习模型
blob = cv2.dnn.blobFromImage(image, 1/255, (416, 416), swapRB=True, crop=False)
net.setInput(blob)
# 运行目标检测模型
outs = net.forward(net.getUnconnectedOutLayersNames())
# 解析模型输出,获取检测结果
for out in outs:
for detection in out:
scores = detection[5:]
class_id = np.argmax(scores)
confidence = scores[class_id]
if confidence > 0.5:
center_x = int(detection[0] * width)
center_y = int(detection[1] * height)
w = int(detection[2] * width)
h = int(detection[3] * height)
x = int(center_x - w/2)
y = int(center_y - h/2)
# 在图像上绘制边界框和类别标签
cv2.rectangle(image, (x, y), (x+w, y+h), (255, 0, 0), 2)
cv2.putText(image, classes[class_id], (x, y-5), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
# 显示检测结果
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.show()
请注意,这只是一个简单的示例代码,实际应用中可能需要根据具体的深度学习模型和数据集进行相应的调整和优化。您可以根据自己的需求选择合适的目标检测模型和数据集,以实现更准确和高效的目标检测和识别。
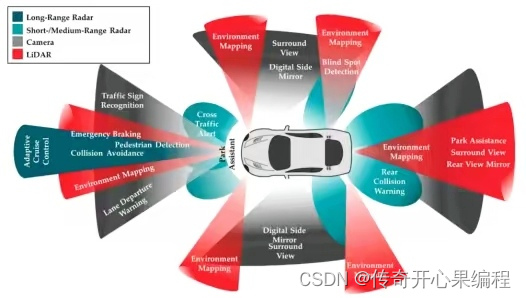
使用OpenCV加载已经训练好的目标检测模型,如YOLO示例代码
以下是一个简单的示例代码,演示如何使用OpenCV加载已经训练好的目标检测模型(如YOLO),并在图像上进行目标检测:
import cv2
import numpy as np
# 加载已经训练好的目标检测模型(如YOLO)
net = cv2.dnn.readNet("yolov3.weights", "yolov3.cfg")
# 获取模型输出层信息
layer_names = net.getLayerNames()
output_layers = [layer_names[i[0] - 1] for i in net.getUnconnectedOutLayers()]
# 读取测试图像
image = cv2.imread("object_detection_image.jpg")
height, width, channels = image.shape
# 将图像转换为blob格式,用于输入深度学习模型
blob = cv2.dnn.blobFromImage(image, 0.00392, (416, 416), (0, 0, 0), True, crop=False)
net.setInput(blob)
# 运行目标检测模型
outs = net.forward(output_layers)
# 解析模型输出,获取检测结果
class_ids = []
confidences = []
boxes = []
for out in outs:
for detection in out:
scores = detection[5:]
class_id = np.argmax(scores)
confidence = scores[class_id]
if confidence > 0.5: # 设置置信度阈值
# 获取目标框的中心坐标、宽度和高度
center_x = int(detection[0] * width)
center_y = int(detection[1] * height)
w = int(detection[2] * width)
h = int(detection[3] * height)
# 计算目标框的左上角坐标
x = int(center_x - w / 2)
y = int(center_y - h / 2)
class_ids.append(class_id)
confidences.append(float(confidence))
boxes.append([x, y, w, h])
# 非极大值抑制,去除重叠框
indices = cv2.dnn.NMSBoxes(boxes, confidences, 0.5, 0.4)
# 在图像上绘制检测结果
colors = np.random.uniform(0, 255, size=(len(class_ids), 3))
for i in indices:
i = i[0]
box = boxes[i]
x, y, w, h = box
color = colors[i]
cv2.rectangle(image, (x, y), (x + w, y + h), color, 2)
cv2.putText(image, str(class_ids[i]), (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
# 显示目标检测结果
cv2.imshow("Object Detection", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
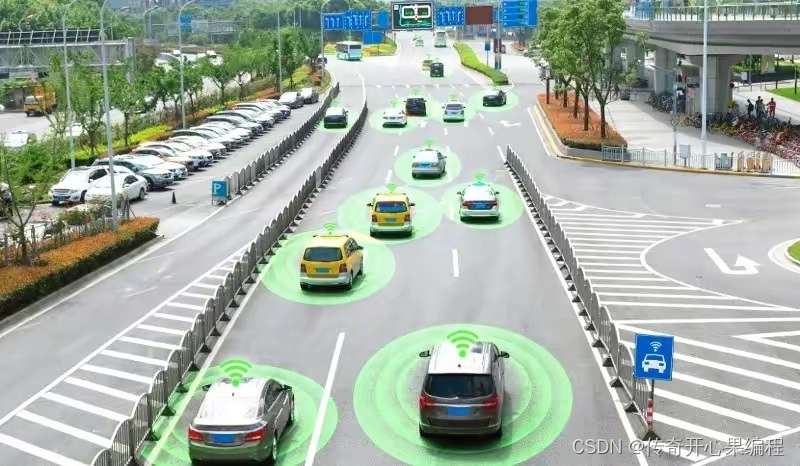
使用OpenCV加载已经训练好的目标检测模型,如SSD示例代码
以下是一个简单的示例代码,演示如何使用OpenCV加载已经训练好的目标检测模型(如SSD),并在图像上进行目标检测:
import cv2
# 加载已经训练好的目标检测模型(如SSD)
net = cv2.dnn.readNetFromTensorflow("ssd_mobilenet_v2_coco.pb", "ssd_mobilenet_v2_coco.pbtxt")
# 读取测试图像
image = cv2.imread("object_detection_image.jpg")
# 构建blob,用于输入深度学习模型
blob = cv2.dnn.blobFromImage(image, size=(300, 300), swapRB=True, crop=False)
net.setInput(blob)
# 运行目标检测模型
detections = net.forward()
# 在图像上绘制检测结果
for i in range(detections.shape[2]):
confidence = detections[0, 0, i, 2]
if confidence > 0.5: # 设置置信度阈值
class_id = int(detections[0, 0, i, 1])
box = detections[0, 0, i, 3:7] * np.array([image.shape[1], image.shape[0], image.shape[1], image.shape[0]])
(startX, startY, endX, endY) = box.astype("int")
# 绘制目标框和类别标签
cv2.rectangle(image, (startX, startY), (endX, endY), (0, 255, 0), 2)
label = "{}: {:.2f}%".format(class_id, confidence * 100)
cv2.putText(image, label, (startX, startY - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
# 显示目标检测结果
cv2.imshow("Object Detection", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
使用OpenCV加载已经训练好的目标检测模型,如Faster R-CNN示例代码
以下是一个简单的示例代码,演示如何使用OpenCV加载已经训练好的目标检测模型(如Faster R-CNN),并在图像上进行目标检测:
import cv2
# 加载已经训练好的目标检测模型(如Faster R-CNN)
net = cv2.dnn.readNetFromTensorflow("faster_rcnn_inception_v2_coco.pb", "faster_rcnn_inception_v2_coco.pbtxt")
# 读取测试图像
image = cv2.imread("object_detection_image.jpg")
# 构建blob,用于输入深度学习模型
blob = cv2.dnn.blobFromImage(image, size=(300, 300), swapRB=True, crop=False)
net.setInput(blob)
# 运行目标检测模型
detections = net.forward()
# 在图像上绘制检测结果
for i in range(detections.shape[2]):
confidence = detections[0, 0, i, 2]
if confidence > 0.5: # 设置置信度阈值
class_id = int(detections[0, 0, i, 1])
box = detections[0, 0, i, 3:7] * np.array([image.shape[1], image.shape[0], image.shape[1], image.shape[0])
(startX, startY, endX, endY) = box.astype("int")
# 绘制目标框和类别标签
cv2.rectangle(image, (startX, startY), (endX, endY), (0, 255, 0), 2)
label = "{}: {:.2f}%".format(class_id, confidence * 100)
cv2.putText(image, label, (startX, startY - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
# 显示目标检测结果
cv2.imshow("Object Detection", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
三、路况感知示例代码

以下是一个简单的示例代码,演示如何使用深度学习模型进行路况感知,识别道路的标线、交通信号灯、路口、障碍物等,帮助车辆更好地理解周围环境和规划行驶路径:
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 使用OpenCV加载已经训练好的路况感知模型,如语义分割模型、实例分割模型等
net = cv2.dnn.readNet("road_perception_model.weights", "road_perception_model.cfg")
# 读取测试图像
image = cv2.imread("road_image.jpg")
height, width, _ = image.shape
# 将图像转换为blob格式,用于输入深度学习模型
blob = cv2.dnn.blobFromImage(image, 1/255, (416, 416), swapRB=True, crop=False)
net.setInput(blob)
# 运行路况感知模型
output = net.forward()
# 解析模型输出,获取路况信息
for i in range(len(output)):
# 处理模型输出,如语义分割结果、实例分割结果等
# 可根据具体模型输出的格式和内容进行相应的解析和处理
# 这里以语义分割结果为例,假设每个像素点对应一个类别标签
# 对每个像素点进行类别预测
for j in range(output[i].shape[0]):
for k in range(output[i].shape[1]):
class_id = np.argmax(output[i][j][k])
if class_id == 0: # 假设类别0表示道路标线
image[j][k] = [255, 255, 0] # 标记道路标线为黄色
elif class_id == 1: # 假设类别1表示交通信号灯
image[j][k] = [255, 0, 0] # 标记交通信号灯为红色
# 其他类别以此类推...
# 显示路况感知结果
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.show()
请注意,这只是一个简单的示例代码,实际应用中可能需要根据具体的路况感知模型和数据集进行相应的调整和优化。您可以根据自己的需求选择合适的路况感知模型和数据集,以实现更准确和高效的路况感知功能。

使用OpenCV加载已经训练好的路况感知模型,如语义分割模型示例代码
以下是一个简单的示例代码,演示如何使用OpenCV加载已经训练好的路况感知模型(如语义分割模型),并在图像上进行路况感知:
import cv2
# 加载已经训练好的路况感知模型(如语义分割模型)
net = cv2.dnn.readNetFromTensorflow("semantic_segmentation_model.pb")
# 读取测试图像
image = cv2.imread("road_image.jpg")
# 构建blob,用于输入深度学习模型
blob = cv2.dnn.blobFromImage(image, size=(320, 320), swapRB=True, crop=False)
net.setInput(blob)
# 运行路况感知模型
output = net.forward()
# 解析输出结果并生成语义分割图像
segmentation_map = output[0, 0]
# 根据语义分割图像生成可视化结果
mask = cv2.resize(segmentation_map, (image.shape[1], image.shape[0]))
mask = (mask > 0.5).astype('uint8') * 255
# 将语义分割结果叠加到原始图像上
result = cv2.addWeighted(image, 0.5, cv2.merge((mask, mask, mask)), 0.5, 0)
# 显示路况感知结果
cv2.imshow("Road Perception", result)
cv2.waitKey(0)
cv2.destroyAllWindows()

使用OpenCV加载已经训练好的路况感知模型,如实例分割模型示例代码
import cv2
# 加载已经训练好的路况感知模型(如实例分割模型)
net = cv2.dnn.readNetFromTensorflow("instance_segmentation_model.pb")
# 读取测试图像
image = cv2.imread("road_image.jpg")
# 构建blob,用于输入深度学习模型
blob = cv2.dnn.blobFromImage(image, size=(320, 320), swapRB=True, crop=False)
net.setInput(blob)
# 运行路况感知模型
output = net.forward()
# 解析输出结果并生成实例分割图像
num_classes = output.shape[1]
num_objects = output.shape[2]
for i in range(num_objects):
class_id = int(output[0, 0, i, 1])
confidence = output[0, 0, i, 2]
if confidence > 0.5: # 设置置信度阈值
box = output[0, 0, i, 3:7] * np.array([image.shape[1], image.shape[0], image.shape[1], image.shape[0])
(startX, startY, endX, endY) = box.astype("int")
# 绘制实例分割结果
cv2.rectangle(image, (startX, startY), (endX, endY), (0, 255, 0), 2)
label = "Class: {}, Confidence: {:.2f}".format(class_id, confidence)
cv2.putText(image, label, (startX, startY - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
# 显示路况感知结果
cv2.imshow("Road Perception", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
四、行为预测示例代码


以下是一个简单的示例代码,演示如何使用深度学习模型进行行为预测,通过分析其他车辆和行人的行为模式,预测它们的未来动作,从而帮助车辆做出更加智能的决策:
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 使用OpenCV加载已经训练好的行为预测模型
net = cv2.dnn.readNet("behavior_prediction_model.weights", "behavior_prediction_model.cfg")
# 读取测试图像
image = cv2.imread("behavior_image.jpg")
# 将图像转换为blob格式,用于输入深度学习模型
blob = cv2.dnn.blobFromImage(image, 1/255, (416, 416), swapRB=True, crop=False)
net.setInput(blob)
# 运行行为预测模型
output = net.forward()
# 解析模型输出,获取行为预测结果
for i in range(len(output)):
# 处理模型输出,获取其他车辆和行人的未来动作预测
# 可根据具体模型输出的格式和内容进行相应的解析和处理
# 这里以简单的示例为主,假设模型输出每个目标的动作类别标签
# 预测每个目标的动作类别
for j in range(output[i].shape[0]):
class_id = np.argmax(output[i][j])
if class_id == 0: # 假设类别0表示直行
print("目标{}预测为直行".format(j))
elif class_id == 1: # 假设类别1表示左转
print("目标{}预测为左转".format(j))
# 其他类别以此类推...
# 显示行为预测结果(这里只是打印预测结果,实际应用中可以根据需要进行相应的处理和展示)
请注意,这只是一个简单的示例代码,实际应用中可能需要根据具体的行为预测模型和数据集进行相应的调整和优化。您可以根据自己的需求选择合适的行为预测模型和数据集,以实现更准确和高效的行为预测功能。
五、路径规划示例代码

深度学习可以结合交通数据和地图信息,帮助车辆规划最佳的行驶路径。以下是一个简单示例代码,展示如何使用深度学习模型进行路径规划:
import cv2
import numpy as np
# 加载已经训练好的路径规划模型
net = cv2.dnn.readNetFromTensorflow("path_planning_model.pb")
# 读取地图图像
map_image = cv2.imread("map_image.jpg")
# 构建blob,用于输入深度学习模型
blob = cv2.dnn.blobFromImage(map_image, size=(320, 320), swapRB=True, crop=False)
net.setInput(blob)
# 运行路径规划模型
output = net.forward()
# 解析输出结果,得到最佳行驶路径
best_path = np.argmax(output)
# 在地图图像上绘制最佳行驶路径
# 这里只是一个简单示例,实际应用中可能需要根据具体情况进行路径绘制
# 可以使用OpenCV的绘制函数进行路径绘制
# 显示带有最佳行驶路径的地图图像
cv2.imshow("Map with Best Path", map_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
请注意,这只是一个简单的示例代码,实际应用中可能需要根据具体的路径规划模型和数据集进行相应的调整和优化。您可以根据自己的需求选择合适的路径规划模型和数据集,以实现更准确和高效的路径规划功能。

六、自动驾驶控制示例代码

以下是一个简单的示例代码,展示如何使用深度学习模型帮助车辆实现自动驾驶的控制,包括加速、制动、转向等操作:
import cv2
import numpy as np
# 加载已经训练好的自动驾驶控制模型
net = cv2.dnn.readNetFromTensorflow("autonomous_driving_control_model.pb")
# 读取车辆传感器数据,例如摄像头图像、雷达数据等
sensor_data = cv2.imread("sensor_data_image.jpg")
# 构建blob,用于输入深度学习模型
blob = cv2.dnn.blobFromImage(sensor_data, size=(320, 320), swapRB=True, crop=False)
net.setInput(blob)
# 运行自动驾驶控制模型
output = net.forward()
# 解析输出结果,得到控制指令(加速、制动、转向)
acceleration = output[0]
brake = output[1]
steering = output[2]
# 根据控制指令执行相应操作,这里只是一个简单示例
# 实际应用中可能需要与车辆控制系统进行接口对接
# 可以使用车辆控制库或者硬件接口进行控制操作
# 执行控制操作后,可以更新车辆状态、传感器数据等
# 显示自动驾驶控制结果
# 可以在图像上绘制控制指令,例如加速度、制动力、转向角度等
# 显示处理后的传感器数据图像
cv2.imshow("Processed Sensor Data", sensor_data)
cv2.waitKey(0)
cv2.destroyAllWindows()
请注意,这只是一个简单的示例代码,实际应用中可能需要根据具体的自动驾驶控制模型和数据集进行相应的调整和优化。在实际应用中,需要考虑与车辆控制系统的接口对接,以确保控制指令能够正确执行。

七、感知融合示例代码

以下是一个简单的示例代码,展示如何使用深度学习帮助车辆实现感知融合,将来自不同传感器的数据进行融合,提高对周围环境的感知能力和准确性:
import cv2
import numpy as np
# 加载已经训练好的感知融合模型
net = cv2.dnn.readNetFromTensorflow("sensor_fusion_model.pb")
# 读取来自不同传感器的数据,例如摄像头图像、激光雷达数据、雷达数据等
camera_data = cv2.imread("camera_data_image.jpg")
lidar_data = np.load("lidar_data.npy")
radar_data = np.load("radar_data.npy")
# 将不同传感器数据进行融合
# 可以将不同传感器数据拼接成一个输入blob,然后输入深度学习模型进行融合
# 这里只是一个简单示例,实际应用中可能需要根据具体情况进行数据处理和融合
# 构建blob,用于输入深度学习模型
# 这里假设将摄像头图像、激光雷达数据、雷达数据拼接成一个输入blob
combined_data = np.concatenate((camera_data, lidar_data, radar_data), axis=0)
blob = cv2.dnn.blobFromImage(combined_data, size=(320, 320), swapRB=True, crop=False)
net.setInput(blob)
# 运行感知融合模型
output = net.forward()
# 解析输出结果,得到融合后的感知结果
fusion_result = output[0]
# 根据融合后的感知结果进行后续处理,例如目标检测、路径规划等
# 显示感知融合结果
# 可以在图像上绘制检测到的目标、感知结果等信息
# 显示处理后的融合结果图像
cv2.imshow("Fusion Result", fusion_result)
cv2.waitKey(0)
cv2.destroyAllWindows()
请注意,这只是一个简单的示例代码,实际应用中可能需要根据具体的感知融合模型和数据集进行相应的调整和优化。在实际应用中,需要根据不同传感器的数据类型和特征进行适当的融合处理,以提高感知能力和准确性。
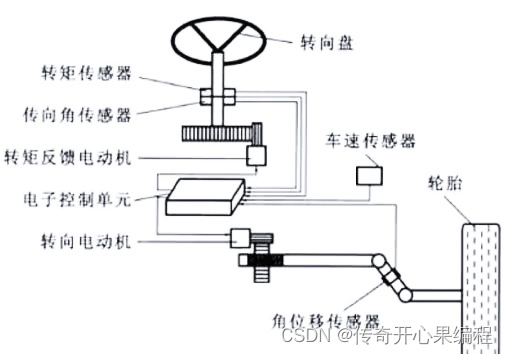
八、高精度地图构建示例代码

以下是一个简单的示例代码,展示如何使用深度学习帮助车辆构建高精度地图,包括道路几何、交通标识、路口信息等,以支持自动驾驶决策和路径规划:
import cv2
import numpy as np
# 加载已经训练好的地图构建模型
net = cv2.dnn.readNetFromTensorflow("map_building_model.pb")
# 读取车载传感器获取的数据,例如摄像头图像、激光雷达数据、雷达数据等
camera_data = cv2.imread("camera_data_image.jpg")
lidar_data = np.load("lidar_data.npy")
radar_data = np.load("radar_data.npy")
# 将传感器数据输入地图构建模型
# 可以将不同传感器数据拼接成一个输入blob,然后输入深度学习模型进行地图构建
# 这里只是一个简单示例,实际应用中可能需要根据具体情况进行数据处理和地图构建
# 构建blob,用于输入深度学习模型
# 这里假设将摄像头图像、激光雷达数据、雷达数据拼接成一个输入blob
combined_data = np.concatenate((camera_data, lidar_data, radar_data), axis=0)
blob = cv2.dnn.blobFromImage(combined_data, size=(320, 320), swapRB=True, crop=False)
net.setInput(blob)
# 运行地图构建模型
output = net.forward()
# 解析输出结果,得到构建的高精度地图
map_data = output[0]
# 根据构建的高精度地图进行后续处理,例如道路分割、交通标识识别、路口检测等
# 显示构建的高精度地图
# 可以在地图上绘制道路几何、交通标识、路口信息等
# 显示构建的高精度地图
cv2.imshow("High Precision Map", map_data)
cv2.waitKey(0)
cv2.destroyAllWindows()
请注意,这只是一个简单的示例代码,实际应用中可能需要根据具体的地图构建模型和数据集进行相应的调整和优化。在实际应用中,需要根据车载传感器获取的数据类型和特征进行适当的地图构建处理,以支持自动驾驶系统的决策和路径规划。
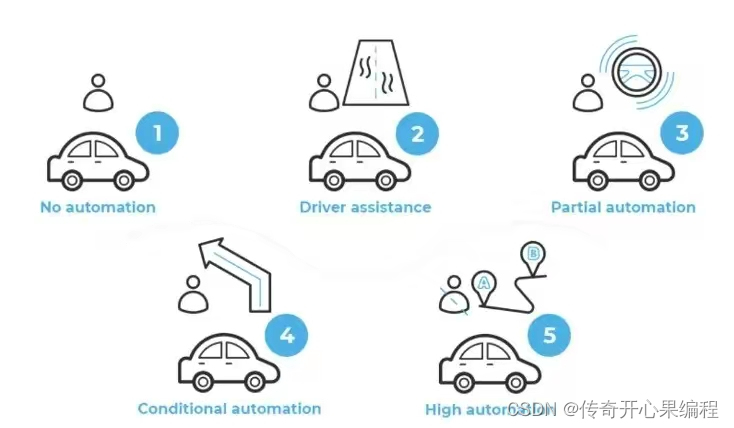
九、强化学习示例代码

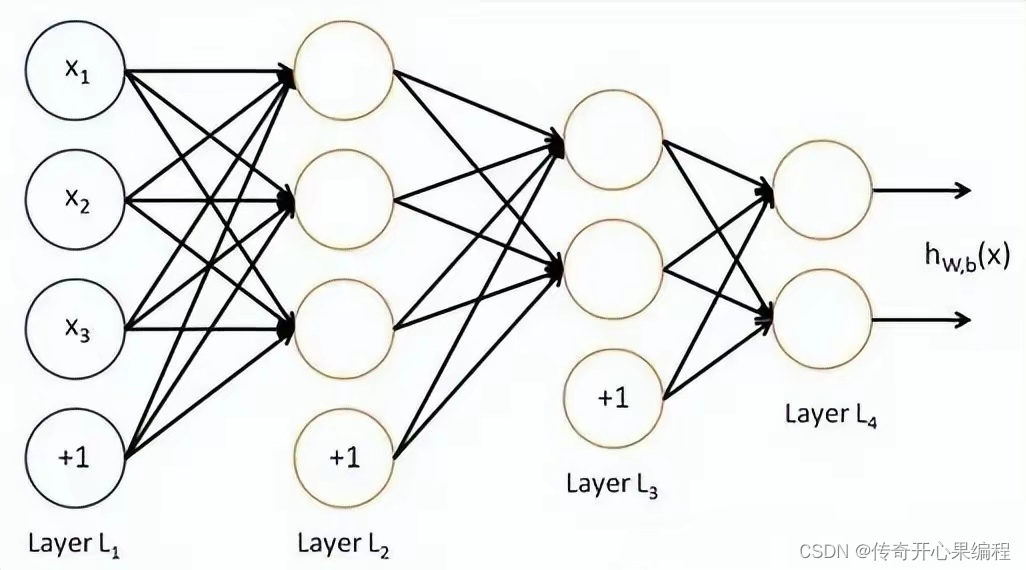
以下是一个简单的示例代码,展示如何使用深度学习结合强化学习技术,帮助车辆通过与环境的交互学习最优的驾驶策略,不断优化驾驶行为和决策:
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
# 定义强化学习模型
class ReinforcementLearningModel(tf.keras.Model):
def __init__(self, num_actions):
super(ReinforcementLearningModel, self).__init__()
self.dense1 = Dense(128, activation='relu')
self.dense2 = Dense(num_actions, activation='softmax')
def call(self, inputs):
x = self.dense1(inputs)
return self.dense2(x)
# 初始化强化学习模型
num_actions = 3 # 假设有3种驾驶策略
model = ReinforcementLearningModel(num_actions)
# 定义优化器和损失函数
optimizer = Adam(learning_rate=0.001)
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy()
# 模拟环境交互数据
# 这里假设环境交互数据为随机生成的示例数据
# 实际应用中需要根据具体的环境和任务收集真实的交互数据
state = np.array([0.1, 0.2, 0.3]) # 示例状态数据
reward = 1 # 示例奖励值
action = np.random.choice(num_actions) # 示例动作
# 训练强化学习模型
with tf.GradientTape() as tape:
logits = model(state.reshape(1, -1))
loss = loss_fn([action], logits)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# 在实际应用中,需要通过多次与环境的交互和训练,不断优化驾驶策略和决策
# 使用训练好的强化学习模型进行驾驶决策
# 这里假设输入状态数据为state,通过模型预测最优的驾驶动作
action_probabilities = model.predict(state.reshape(1, -1))
action = np.argmax(action_probabilities)
# 执行预测的驾驶动作,与环境交互,获得奖励,更新模型
# 在实际应用中,可以根据具体的场景和任务,调整模型结构、训练方法和参数,以获得更好的驾驶策略和决策效果
请注意,这只是一个简单的示例代码,实际应用中需要根据具体的驾驶场景和任务进行相应的调整和优化。强化学习在自动驾驶领域有着广泛的应用,通过与环境的交互学习最优的驾驶策略,可以帮助车辆实现更智能的自主驾驶能力。

十、对抗性攻击防御示例代码

对抗性攻击是指故意设计的输入样本,通过对深度学习模型的输入进行微小的扰动,使其产生错误的输出。在自动驾驶系统中,对抗性攻击可能导致严重的安全问题,因此需要采取相应的防御措施。以下是一个简单的示例代码,展示如何使用深度学习模型对抗性攻击进行检测和防御:
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import load_model
# 加载训练好的深度学习模型
model = load_model('autonomous_driving_model.h5')
# 定义对抗性攻击函数
def adversarial_attack(input_image, epsilon):
with tf.GradientTape() as tape:
tape.watch(input_image)
prediction = model(input_image)
loss = tf.keras.losses.MSE(tf.zeros_like(prediction), prediction)
gradient = tape.gradient(loss, input_image)
perturbation = epsilon * tf.sign(gradient)
adversarial_image = input_image + perturbation
return tf.clip_by_value(adversarial_image, 0, 1)
# 模拟对抗性攻击
# 这里假设输入图像为随机生成的示例数据
input_image = np.random.rand(1, 224, 224, 3)
epsilon = 0.1 # 对抗性攻击的扰动大小
# 生成对抗性样本
adversarial_image = adversarial_attack(tf.convert_to_tensor(input_image), epsilon)
# 检测对抗性攻击
prediction_original = model.predict(input_image)
prediction_adversarial = model.predict(adversarial_image)
if np.argmax(prediction_original) == np.argmax(prediction_adversarial):
print("未成功对抗")
else:
print("成功对抗")
# 在实际应用中,可以根据具体的深度学习模型和攻击场景,调整对抗性攻击函数的参数和策略,以提高对抗性攻击的检测和防御效果
在实际应用中,对抗性攻击的防御是一个复杂而重要的问题,需要综合考虑模型的鲁棒性、攻击者的能力和目标、攻击场景等因素。通过使用深度学习技术进行对抗性攻击的检测和防御,可以提高自动驾驶系统的安全性和可靠性。

十一、模型优化和加速示例代码

针对自动驾驶系统中的深度学习模型,进行模型优化和加速可以采用一些技术,例如模型压缩、量化、剪枝等。以下是一个简单的示例代码,演示如何使用TensorFlow对深度学习模型进行量化(Quantization):
import tensorflow as tf
from tensorflow.python.framework import graph_util
from tensorflow.tools.graph_transforms import TransformGraph
# 加载已经训练好的模型
model = tf.keras.models.load_model('path_to_your_trained_model.h5')
# 定义输入输出节点的名称
input_node = model.inputs[0].name.split(':')[0]
output_node = model.outputs[0].name.split(':')[0]
# 转换模型为TensorFlow的GraphDef格式
frozen_graph = graph_util.convert_variables_to_constants(
tf.compat.v1.Session(),
tf.compat.v1.get_default_graph().as_graph_def(),
[output_node])
# 定义转换操作,这里使用量化(Quantization)操作
transforms = ['quantize_weights', 'quantize_nodes']
# 应用转换操作到模型图中
transformed_graph = TransformGraph(frozen_graph, [input_node], [output_node], transforms)
# 保存量化后的模型
with tf.io.gfile.GFile('quantized_model.pb', 'wb') as f:
f.write(transformed_graph.SerializeToString())
print("量化后的模型已保存成功")
上述代码演示了如何使用TensorFlow对已训练好的深度学习模型进行量化,通过量化操作可以减少模型的存储空间和加快推理速度,从而提高模型在自动驾驶系统中的实时性和效率。实际应用中,可以根据具体的模型和需求选择合适的优化和加速技对于自动驾驶系统中的深度学习模型,常常需要进行模型优化和加速,以提高推理速度和减少计算资源消耗。以下是一个示例代码,演示如何使用 TensorFlow 中的模型优化工具 TensorFlow Lite 对深度学习模型进行优化和转换为适合在嵌入式设备上部署的轻量化模型:
import tensorflow as tf
# 加载已训练好的深度学习模型
model = tf.keras.models.load_model('autonomous_driving_model.h5')
# 转换模型为 TensorFlow Lite 模型
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()
# 保存 TensorFlow Lite 模型
with open('autonomous_driving_model.tflite', 'wb') as f:
f.write(tflite_model)
print("模型转换为 TensorFlow Lite 完成")
# 加载 TensorFlow Lite 模型进行推理
interpreter = tf.lite.Interpreter(model_path='autonomous_driving_model.tflite')
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# 输入数据预处理
input_data = preprocess_input(input_image)
# 设置输入数据
interpreter.set_tensor(input_details[0]['index'], input_data)
# 进行推理
interpreter.invoke()
# 获取输出结果
output_data = interpreter.get_tensor(output_details[0]['index'])
print("模型推理结果:", output_data)
通过将深度学习模型转换为 TensorFlow Lite 模型,可以实现模型的轻量化和优化,适合在嵌入式设备上部署和运行,从而提高自动驾驶系统的实时性和效率。在实际应用中,可以根据具体的模型和部署环境,调整模型优化和转换的参数,以达到最佳的性能和效果。
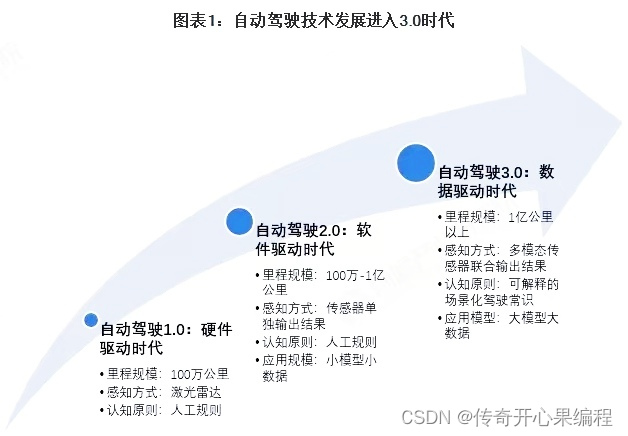
十二、知识点归纳



深度学习在自动驾驶领域有着广泛的应用,涉及多个方面的技术和知识点。以下是深度学习在自动驾驶领域的一些常见应用和相关知识点的归纳:
-
图像识别和分类:深度学习模型可以用于识别和分类道路标志、车辆、行人等图像信息,帮助车辆感知周围环境。
-
目标检测和跟踪:深度学习模型能够实现目标检测和跟踪,识别和跟踪道路上的车辆、行人、障碍物等目标。
-
语义分割:通过深度学习模型进行语义分割,将图像分割成不同的语义区域,有助于车辆理解道路和周围环境的结构。
-
路径规划和决策:深度学习模型可以用于路径规划和决策,根据感知到的环境信息和车辆状态,制定最优的驾驶策略。
-
强化学习:利用深度强化学习技术,训练自动驾驶系统在复杂环境下做出智能的决策,提高驾驶的安全性和效率。
-
对抗性攻击防御:深度学习模型可以用于检测和防御对自动驾驶系统的对抗性攻击,保障车辆的安全性和可靠性。
-
传感器融合:深度学习可以帮助实现多传感器数据的融合,提高车辆对周围环境的感知能力。
-
模型优化和加速:针对自动驾驶系统中的深度学习模型,需要进行模型优化和加速,以满足实时性和效率的要求。
以上是深度学习在自动驾驶领域的一些常见应用和相关知识点,深度学习技术的不断发展和应用将进一步推动自动驾驶技术的发展和应用。