一、TDenige简介
TDengine:是涛思数据面对高速增长的物联网大数据市场和技术挑战推出的创新性的大数据处理产品,它不依赖任何第三方软件,也不是优化或包装了一个开源的数据库或流式计算产品,而是在吸取众多传统关系型数据库、NoSQL数据库、流式计算引擎、消息队列等软件的优点之后自主开发的产品,在时序空间大数据处理上,有着自己独到的优势。
TDengine的模块之一是时序数据库。但除此之外,为减少研发的复杂度、系统维护的难度,其还提供缓存、消息队列、订阅、流式计算等功能,为物联网、工业互联网大数据的处理提供全栈的技术方案,是一个高效易用的物联网大数据平台。
二、对比Hadoop等大数据平台的优点
10倍以上的性能提升: 定义了创新的数据存储结构,单核每秒就能处理至少2万次请求,插入数百万个数据点,读出一千万以上数据点,比现有通用数据库快了十倍以上。
全栈时序数据处理引擎: 将数据库、消息队列、缓存、流式计算等功能融合一起,应用无需再集成Kafka/Redis/HBase/Spark等软件,大幅降低应用开发和维护成本。
与第三方工具无缝连接: 不用一行代码,即可与Telegraf, Grafana, EMQ X, Prometheus, Matlab, R集成。后续还将支持MQTT, OPC, Hadoop,Spark等, BI工具也将无缝连接。
硬件或云服务成本降至1/5: 由于超强性能,计算资源不到通用大数据方案的1/5;通过列式存储和先进的压缩算法,存储空间不到通用数据库的1/10。
强大的分析功能: 无论是十年前还是一秒钟前的数据,指定时间范围即可查询。数据可在时间轴上或多个设备上进行聚合。即席查询可通过Shell/Python/R/Matlab随时进行。
零运维成本、零学习成本: 安装、集群一秒搞定,无需分库分表,实时备份。标准SQL,支持JDBC,RESTful,支持Python/Java/C/C++/Go/Node.JS, 与MySQL相似,零学习成本。
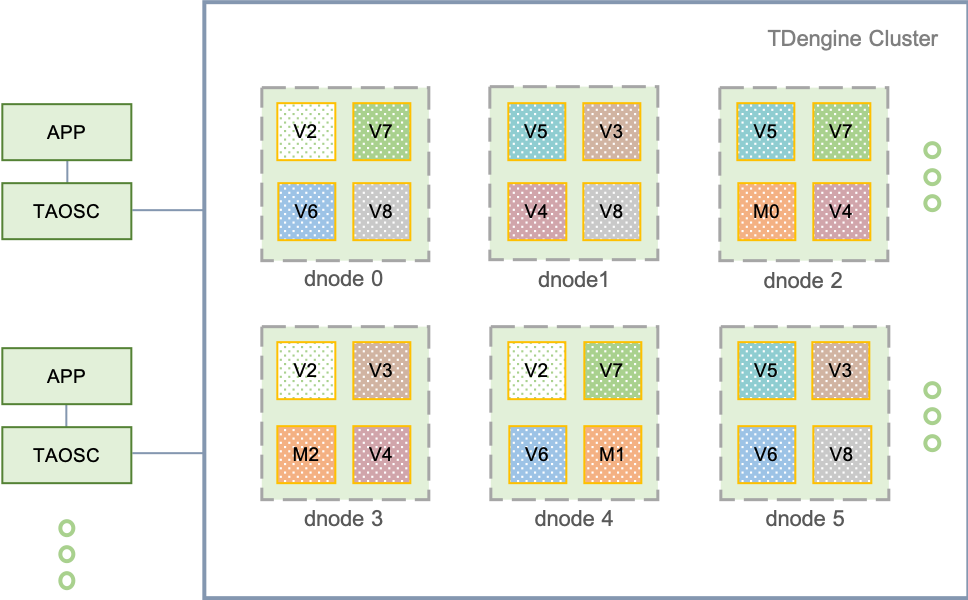
三、分布式架构的逻辑结构图
运行在一到多个物理节点上,逻辑上,它包含数据节点(dnode)、TDengine应用驱动(taosc)以及应用(app)。系统中存在一到多个数据节点,这些数据节点组成一个集群(cluster)。应用通过taosc的API与TDengine集群进行互动。
四、存储模型与数据分区、分片
存储: TDengine存储的数据包括采集的时序数据以及库、表相关的元数据、标签数据等,这些数据具体分为三部分:时序数据、标签数据、元数据。
数据分区: 通过vnode以及时间两个维度,对大数据进行切分,便于并行高效的管理,实现水平扩展。
数据分片: 对于海量的数据管理,为实现水平扩展,一般都需要采取分片(Sharding)分区(Partitioning)策略。TDengine是通过vnode来实现数据分片的,通过一个时间段一个数据文件来实现时序数据分区的。
负载均衡: 每个dnode都定时向 mnode(虚拟管理节点)报告其状态(包括硬盘空间、内存大小、CPU、网络、虚拟节点个数等),因此mnode了解整个集群的状态。基于整体状态,当mnode发现某个dnode负载过重,它会将dnode上的一个或多个vnode挪到其他dnode。在挪动过程中,对外服务继续进行,数据插入、查询和计算操作都不受影响。
五、TAOS数据库分布式安装
taos集群的每个数据节点是由End Point来唯一标识的,End Point是由FQDN(Fully Qualified Domain Name)外加Port组成,比如 h1.taosdata.com:6030。一般FQDN就是服务器的hostname,可通过Linux命令hostname -f获取(如何配置FQDN,请参考:一篇文章说清楚TDengine的FQDN)。端口是这个数据节点对外服务的端口号,缺省是6030,但可以通过taos.cfg里配置参数serverPort进行修改。一个物理节点可能配置了多个hostname, TDengine会自动获取第一个,但也可以通过taos.cfg里配置参数fqdn进行指定。如果习惯IP地址直接访问,可以将参数fqdn设置为本节点的IP地址。
FQDN(fully qualified domain name,完全限定域名)是internet上特定计算机或主机的完整域名。FQDN由两部分组成:主机名和域名。例如,假设邮件服务器的FQDN可能是mail.taosdata.com。主机名是mail,主机位于域名taosdata.com中。
DNS(Domain Name System),负责将FQDN翻译成IP,是互联网绝大多数应用的寻址方式。
第零步:规划集群所有物理节点的FQDN,将规划好的FQDN分别添加到每个物理节点的/etc/hostname;修改每个物理节点的/etc/hosts,将所有集群物理节点的IP与FQDN的对应添加好。【如部署了DNS,请联系网络管理员在DNS上做好相关配置】
vi /etc/hostname
# 将文件内容修改为node1
vi /etc/hosts
# 添加以下三行
10.211.55.14 node1
10.211.55.15 node2
10.211.55.16 node3
配置完成之后,我们可以在Linux中打开Terminal,使用ping hostname来验证是否配置生效。
root@node2:~# ping node1 -c 3
PING node1 (10.211.55.14) 56(84) bytes of data.
64 bytes from ubuntu (10.211.55.14): icmp_seq=1 ttl=64 time=0.028 ms
64 bytes from ubuntu (10.211.55.14): icmp_seq=2 ttl=64 time=0.035 ms
64 bytes from ubuntu (10.211.55.14): icmp_seq=3 ttl=64 time=0.054 ms
第一步:如果搭建集群的物理节点中,存有之前的测试数据、装过1.X的版本,或者装过其他版本的TDengine,请先将其删除,并清空所有数据。
**注意1:**因为FQDN的信息会写进文件,如果之前没有配置或者更改FQDN,且启动了TDengine。请一定在确保数据无用或者备份的前提下,清理一下之前的数据(rm -rf /var/lib/taos/*);
**注意2:**客户端也需要配置,确保它可以正确解析每个节点的FQDN配置,不管是通过DNS服务,还是 Host 文件。
第二步:建议关闭所有物理节点的防火墙,至少保证端口:6030 - 6042的TCP和UDP端口都是开放的。强烈建议先关闭防火墙,集群搭建完毕之后,再来配置端口;
第三步:在所有物理节点安装TDengine,且版本必须是一致的,但不要启动taosd。安装时,提示输入是否要加入一个已经存在的TDengine集群时,第一个物理节点直接回车创建新集群,后续物理节点则输入该集群任何一个在线的物理节点的FQDN:端口号(默认6030);
第四步:检查所有数据节点,以及应用程序所在物理节点的网络设置:
- 每个物理节点上执行命令
hostname -f,查看和确认所有节点的hostname是不相同的(应用驱动所在节点无需做此项检查); - 每个物理节点上执行
ping host, 其中host是其他物理节点的hostname, 看能否ping通其它物理节点; 如果不能ping通,需要检查网络设置, 或/etc/hosts文件(Windows系统默认路径为C:\Windows\system32\drivers\etc\hosts),或DNS的配置。如果无法ping通,是无法组成集群的; - 从应用运行的物理节点,ping taosd运行的数据节点,如果无法ping通,应用是无法连接taosd的,请检查应用所在物理节点的DNS设置或hosts文件;
- 每个数据节点的End Point就是输出的hostname外加端口号,比如h1.taosdata.com:6030
第五步:修改TDengine的配置文件(所有节点的文件/etc/taos/taos.cfg都需要修改)。假设准备启动的第一个数据节点End Point为 h1.taosdata.com:6030, 其与集群配置相关参数如下:
// firstEp 是每个数据节点首次启动后连接的第一个数据节点
firstEp cdh1.macro.com:6030
// 必须配置为本数据节点的FQDN,如果本机只有一个hostname, 可注释掉本配置
fqdn h1.taosdata.com
// 配置本数据节点的端口号,缺省是6030
serverPort 6030
// 使用场景,请参考《Arbitrator的使用》的部分
arbitrator cdh1.macro.com:6042
一定要修改的参数是firstEp和fqdn。在每个数据节点,firstEp需全部配置成一样,但fqdn一定要配置成其所在数据节点的值。其他参数如非必要尽量不做任何修改。
加入到集群中的数据节点dnode,涉及集群相关的下表11项参数必须完全相同,否则不能成功加入到集群中。
| 配置参数名称 | 含义 | |
|---|---|---|
| 1 | numOfMnodes | 系统中管理节点个数 |
| 2 | mnodeEqualVnodeNum | 一个mnode等同于vnode消耗的个数 |
| 3 | offlineThreshold | dnode离线阈值,超过该时间将导致Dnode离线 |
| 4 | statusInterval | dnode向mnode报告状态时长 |
| 5 | arbitrator | 系统中裁决器的end point |
| 6 | timezone | 时区 |
| 7 | locale | 系统区位信息及编码格式 |
| 8 | charset | 字符集编码 |
| 9 | balance | 是否启动负载均衡 |
| 10 | maxTablesPerVnode | 每个vnode中能够创建的最大表个数 |
| 11 | maxVgroupsPerDb | 每个DB中能够使用的最大vgroup个数 |
第六步:选择一个节点(可以是新开的节点,也可以是现有安装了taos Server的节点),安装客户端,请注意:客户端节点和服务节点需要保持同一版本。安装完成后,进入目录,执行install。最后,输入taos -h cdh2.macro.com,即可连接指定节点。
第七步:如果需要添加taos集群的节点,重复第三、第五步,并在客户端执行命令:create dnode "cdh1.mac ro.com";,即可将新节点添加到现有集群;或者在第三步,执行install的过程中,输入任意一个在线节点的FQDN:端口号(默认6030);即可。
至此,taos集群式安装完成。
六、数据的操作
参考官方文档:
TAOS SQL:https://www.taosdata.com/cn/documentation/taos-sql
高效写入数据:https://www.taosdata.com/cn/documentation/insert
高效查询数据:https://www.taosdata.com/cn/documentation/queries
(一)数据写入
如果一个数据库有N个副本,那一个虚拟节点组就有N个虚拟节点,但是只有一个是Master,其他都是slave。当应用将新的记录写入系统时,只有Master vnode能接受写的请求。如果slave vnode收到写的请求,系统将通知taosc需要重新定向。
1.1 插入一条记录
INSERT INTO tb_name VALUES (field_value, ...);
(向表tb_name中插入一条记录)
1.2 插入一条记录,数据对应到指定的列
INSERT INTO tb_name (field1_name, ...) VALUES (field1_value1, ...);
(向表tb_name中插入一条记录,数据对应到指定的列。SQL语句中没有出现的列,数据库将自动填充为NULL。主键(时间戳)不能为NULL。)
1.3 插入多条记录
INSERT INTO tb_name VALUES (field1_value1, ...) (field1_value2, ...) ...;
(向表tb_name中插入多条记录)
1.4 按指定的列插入多条记录
INSERT INTO tb_name (field1_name, ...) VALUES (field1_value1, ...) (field1_value2, ...) ...;
(向表tb_name中按指定的列插入多条记录)
1.5 向多个表插入多条记录
INSERT INTO tb1_name VALUES (field1_value1, ...) (field1_value2, ...) ...
tb2_name VALUES (field1_value1, ...) (field1_value2, ...) ...;
(同时向表tb1_name和tb2_name中分别插入多条记录)
更多测试案例见官方文档:
https://www.taosdata.com/cn/documentation/taos-sql#insert
(二)数据查询
2.1 语法:
SELECT select_expr [, select_expr ...]
FROM {tb_name_list}
[WHERE where_condition]
[INTERVAL (interval_val [, interval_offset])]
[SLIDING sliding_val]
[FILL fill_val]
[GROUP BY col_list]
[ORDER BY col_list { DESC | ASC }]
[SLIMIT limit_val [, SOFFSET offset_val]]
[LIMIT limit_val [, OFFSET offset_val]]
[>> export_file];
2.2 单表查询
SQL语句的解析和校验工作在客户端完成。解析SQL语句并生成抽象语法树(Abstract Syntax Tree, AST),然后对其进行校验和检查。以及向管理节点(mnode)请求查询中指定表的元数据信息(table metadata)。
在TDengine中引入关键词interval来进行时间轴上固定长度时间窗口的切分,并按照时间窗口对数据进行聚合,对窗口范围内的数据按需进行聚合。例如:
select count(*) from d1001 interval(1h);
针对d1001设备采集的数据,按照1小时的时间窗口返回每小时存储的记录数量。
在需要连续获得查询结果的应用场景下,如果给定的时间区间存在数据缺失,会导致该区间数据结果也丢失。TDengine提供策略针对时间轴聚合计算的结果进行插值,通过使用关键词Fill就能够对时间轴聚合结果进行插值。例如:
select count(*) from d1001 interval(1h) fill(prev);
针对d1001设备采集数据统计每小时记录数,如果某一个小时不存在数据,则返回之前一个小时的统计数据。TDengine提供前向插值(prev)、线性插值(linear)、NULL值填充(NULL)、特定值填充(value)。
2.3 多表聚合查询
TDengine对每个数据采集点单独建表,但在实际应用中经常需要对不同的采集点数据进行聚合。为高效的进行聚合操作,TDengine引入超级表(STable)的概念。超级表用来代表一特定类型的数据采集点,它是包含多张表的表集合,集合里每张表的模式(schema)完全一致,但每张表都带有自己的静态标签,标签可以多个,可以随时增加、删除和修改。 应用可通过指定标签的过滤条件,对一个STable下的全部或部分表进行聚合或统计操作,这样大大简化应用的开发。其具体流程如下图所示:

(三)缓存与持久化
3.1 缓存
TDengine采用时间驱动缓存管理策略(First-In-First-Out,FIFO),又称为写驱动的缓存管理机制。这种策略有别于读驱动的数据缓存模式(Least-Recent-Used,LRU),直接将最近写入的数据保存在系统的缓存中。当缓存达到临界值的时候,将最早的数据批量写入磁盘。一般意义上来说,对于物联网数据的使用,用户最为关心的是刚产生的数据,即当前状态。TDengine充分利用这一特性,将最近到达的(当前状态)数据保存在缓存中。
3.2持久化存储
TDengine采用数据驱动的方式让缓存中的数据写入硬盘进行持久化存储。当vnode中缓存的数据达到一定规模时,为了不阻塞后续数据的写入,TDengine也会拉起落盘线程将缓存的数据写入持久化存储。TDengine在数据落盘时会打开新的数据库日志文件,在落盘成功后则会删除老的数据库日志文件,避免日志文件无限制的增长。
四、连接器
C/C++ Connector: 通过libtaos客户端的库,连接TDengine服务器的主要方法
Java Connector(JDBC): 通过标准的JDBC API,给Java应用提供到TDengine的连接
Python Connector: 给Python应用提供一个连接TDengine服务器的驱动
RESTful Connector: 提供一最简单的连接TDengine服务器的方式
Go Connector: 给Go应用提供一个连接TDengine服务器的驱动
Node.js Connector: 给node应用提供一个连接TDengine服务器的驱动
C# Connector: 给C#应用提供一个连接TDengine服务器的驱动
Windows客户端: 自行编译windows客户端,Windows环境的各种连接器都需要它
具体配置及使用见官方文档:https://www.taosdata.com/cn/documentation/connector