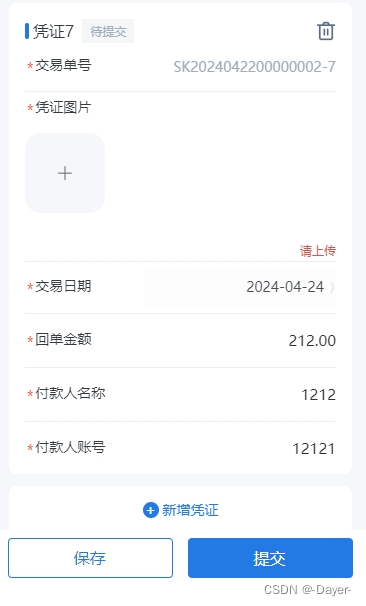
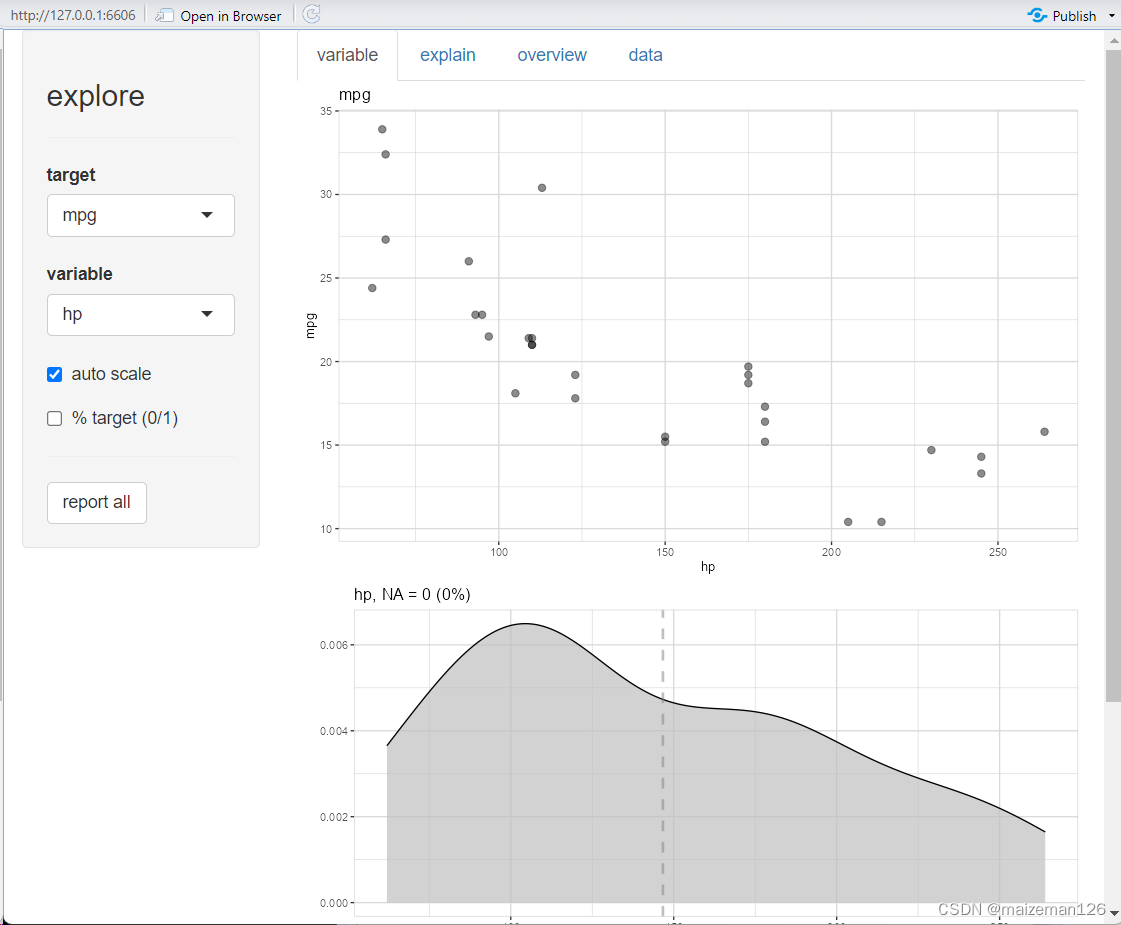
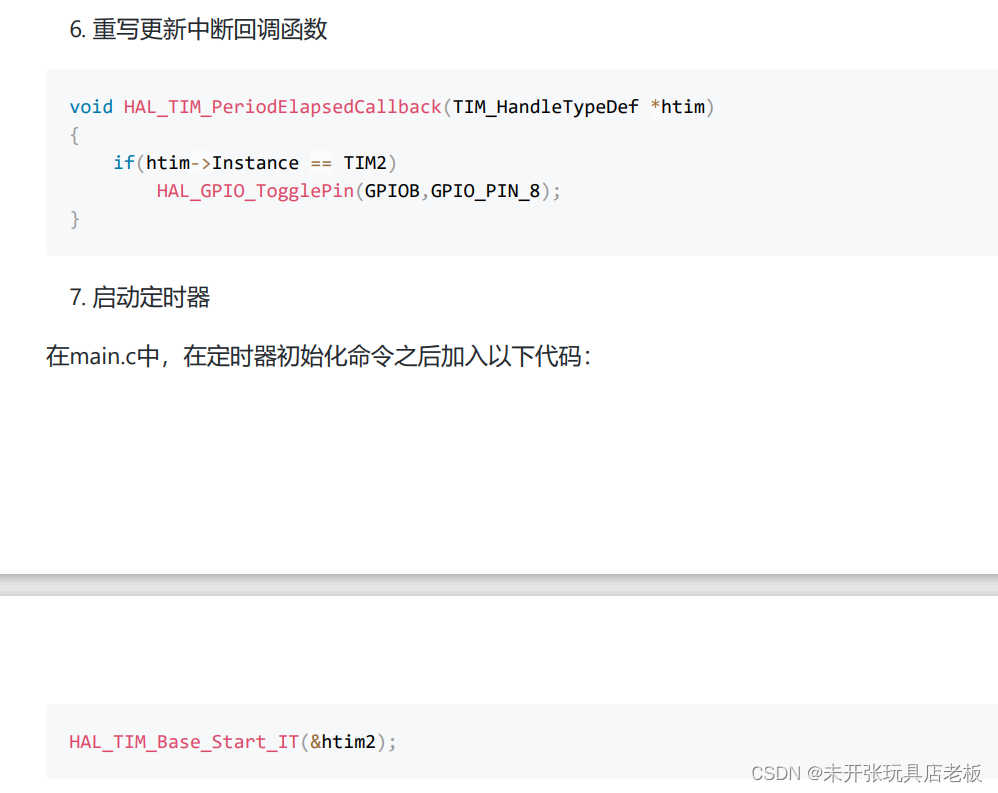
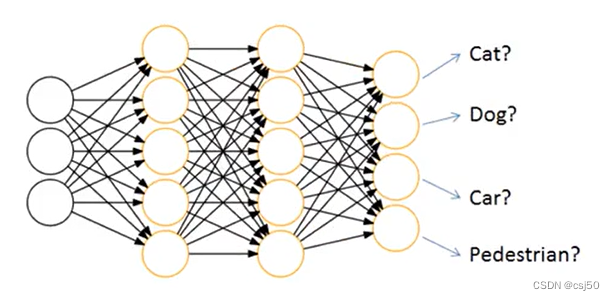
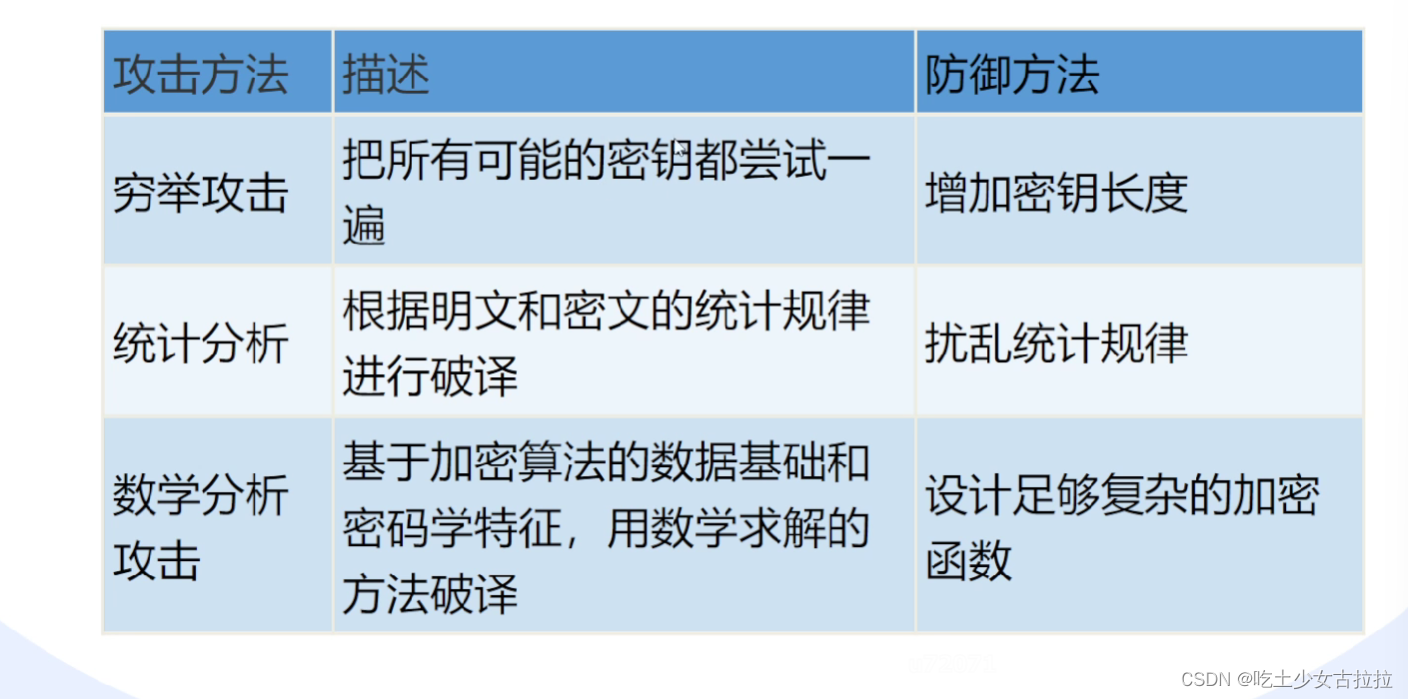
实验准备:
1.下载conda
2.配置环境C:\ProgramData\miniconda3\Scripts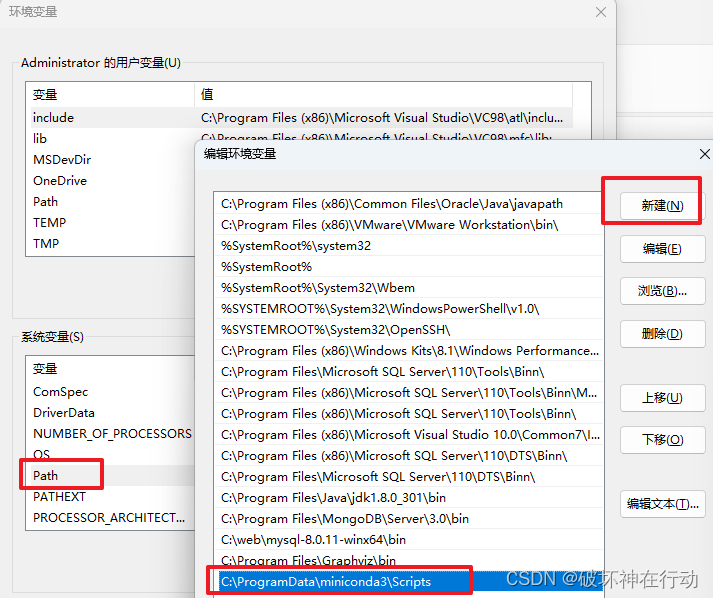
3.创建文件夹panda进入虚拟环境qq
激活虚拟环境:activate qq
启动jupyter lab(python语言环境编译):jupyter lab

4.panda下载
(1)官网panda下载:pandas - Python Data Analysis Library (pydata.org)
(2)虚拟环境的panda下载


一、panda练习1(电影数据库查询)
#导入panda,以pd为简写
import pandas as pd
#读取文件
pd.read_csv('movies.csv')1.简单的数据查询
描述:该部分基本为对DataFrame进行的操作,并没有修改csv文件中的内容
常用方法:head、tail、len()、shape(行列)、size、dypes、iloc[](查看第几条数据) 、loc[](获取数据详细信息)、sort_values(by=[' ' , ' ']).head()、sort_index()_head()注:ascending = False(对于数据进行降序排列的参数设置)
# 创建DataFrame对象movies,设置
movies = pd.read_csv('movies.csv', index_col='Title')
# 查看前4行数据
movies.head(4)
# 查看最后6行数据
movies.tail(6)
# 查询总共有多少条数据
len(movies)
# 通过panda的DataFrame获取数据的形状:行数、列数
movies.shape
# 查询一共有多少个单元格(cell)
movies.size
# 验证
# 一共782行数据,每行有4个属性,除了作为index的Title
782 * 4
# 查询每一列的数据类型
movies.dtypes
# 查看第500条数据
movies.iloc[499]
# 通过 index label 获取 DataFrame 中的数据
# 现在的 index 是 Title(《阿甘正传》)
movies.loc['Forrest Gump']
# 通过index label可以检索出具有相同index label的数据记录
# 但是,通常尽量让每条数据的index label是唯一的,
# 这样可以加速数据定位
movies.loc['101 Dalmatians']
# 对DataFrame中的数据按照year以降序方式重新排序
# head()用来现实前5条数据
movies.sort_values(by='Year', ascending=False).head()
# 根据多个列的值进行排序
# 默认按照升序排序
movies.sort_values(by=['Studio', 'Year']).head()
# 按照index进行排序
movies.sort_index().head()2.实际应用
# 找出哪家电影公司拥有最多最高票房的电影
# 使用Series:只有一列数据
# pandas在Series中保留DataFrame的索引
# 由于数据太多,默认只显示前5条和后5条数据
# Studio制片厂
movies['Studio']
# 统计每个Studio出现的次数,并显示排在前10的Studio
# 返回值为Series对象
movies['Studio'].value_counts().head(10)
# 通过规则过滤数据
# 找出 Universal Studio 发行的电影
movies[movies['Studio'] == 'Universal']
# 通过变量保存过滤规则
released_by_unviersal = (movies['Studio'] == 'Universal')
movies[released_by_unviersal].head()
# 通过多个条件过滤DataFrame中的行数据
# 找出2015年Universal Studio发行(released)的电影的各项数据
# released_by_universal(由环球发行)
released_by_unviersal = movies['Studio'] == 'Universal'
released_in_2015 = movies['Year'] == 2015
movies[released_by_unviersal & released_in_2015]
# 通过多个条件过滤DataFrame中的行数据
# 找出在2015发行或者是Universal Studio发行的电影的各项数据
released_by_unviersal = movies['Studio'] == 'Universal'
released_in_2015 = movies['Year'] == 2015
movies[released_by_unviersal | released_in_2015]
# 过滤出满足指定范围的数据
# 找出1975年之前发行的电影
before_1975 = movies['Year'] < 1975
movies[before_1975]
# 指定某个值的范围
mid_80s = movies['Year'].between(1983, 1986)
movies[mid_80s]
# 使用DataFrame的index进行过滤
# 找出所有在名字中包含 dark 的电影
# 将所有的title先转换为小写
has_dark_in_title = movies.index.str.lower().str.contains('dark')
movies[has_dark_in_title]
# grouping data
# 找出在所有电影中,哪个Studio的总收入最高
# pandas在导入数据时,包含了$和逗号,先把他们去掉
movies['Gross'].str.replace('$', '', regex=False).str.replace(',', '', regex=False)
# 再把文本类型的Gross转换为数字类型
movies['Gross'] = movies['Gross'].str.replace('$', '', regex=False).str.replace(',', '', regex=False).astype(float)
# 计算平均票房收入
movies['Gross'].mean()
# 计算每个电影制片厂的总票房
# groupby
studios = movies.groupby('Studio')
# 统计每个每个Studio发行了几步电影
studios['Gross'].count().head()
# 默认按照字母顺序排序
# 改为按照发行的电影数量降序排序
studios['Gross'].count().sort_values(ascending=False).head()
# 计算每个Studio发行电影的总票房
studios['Gross'].sum().head()
# 默认按照Studio的字母顺序排序
# 按照总票房顺序排序
studios['Gross'].sum().sort_values(ascending=False).head()