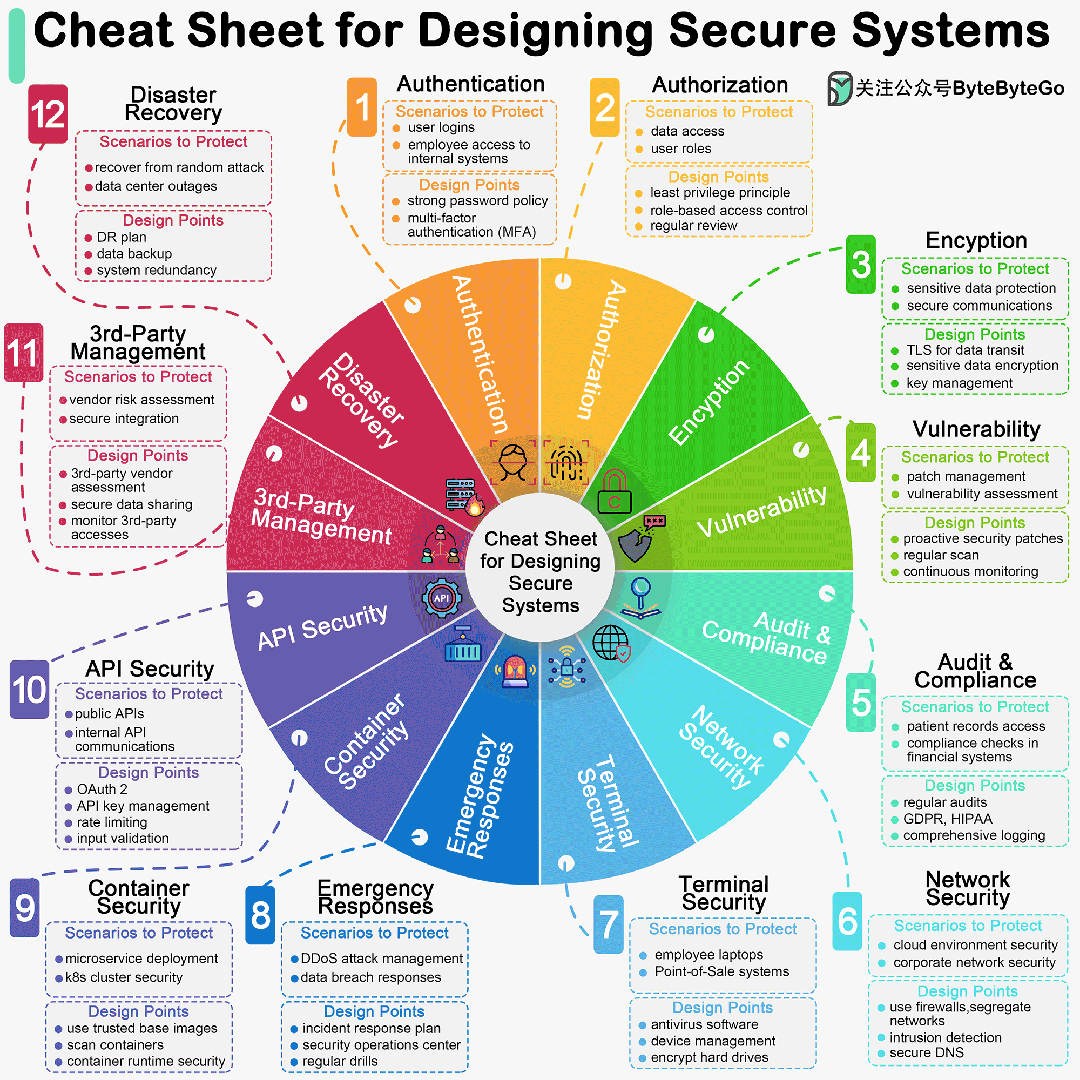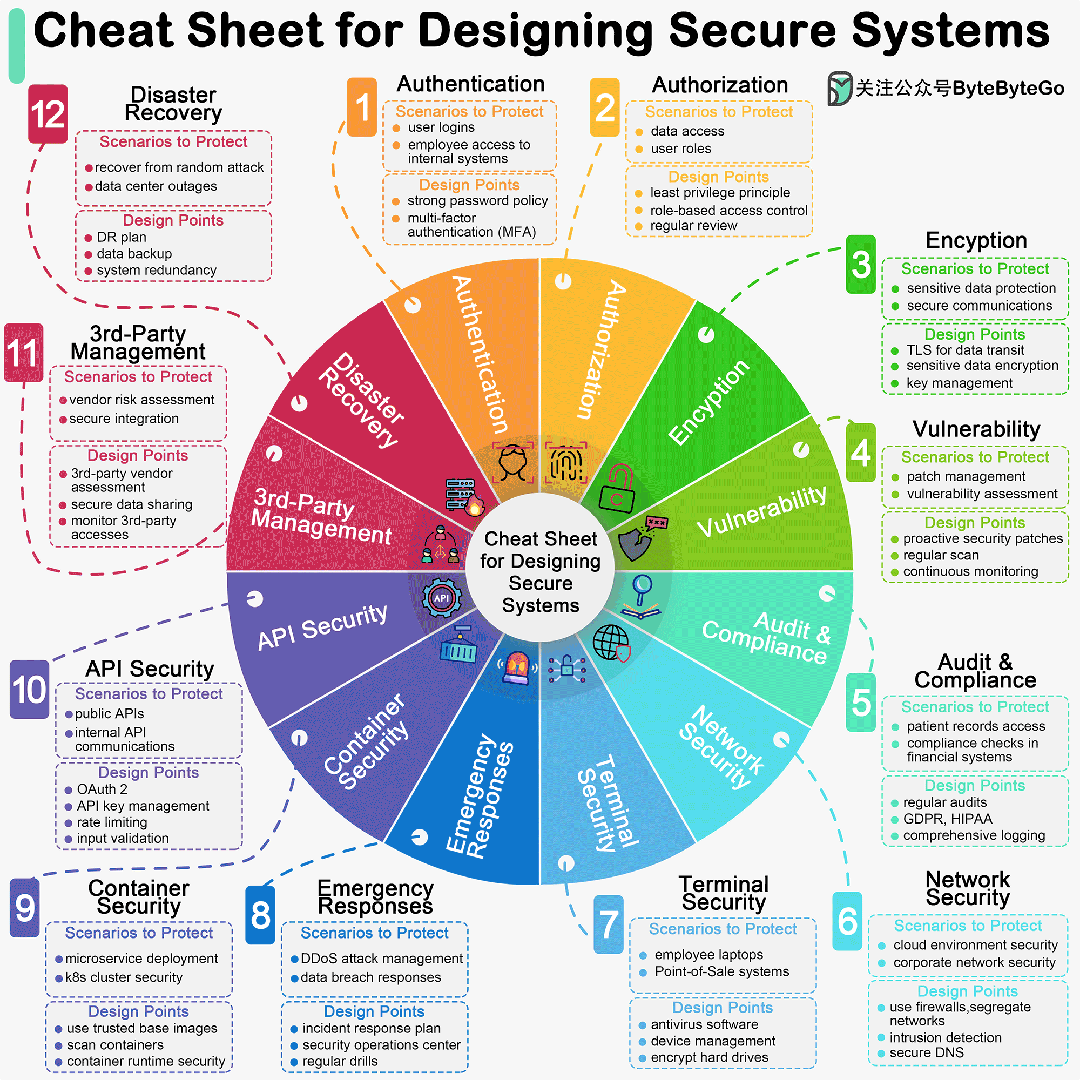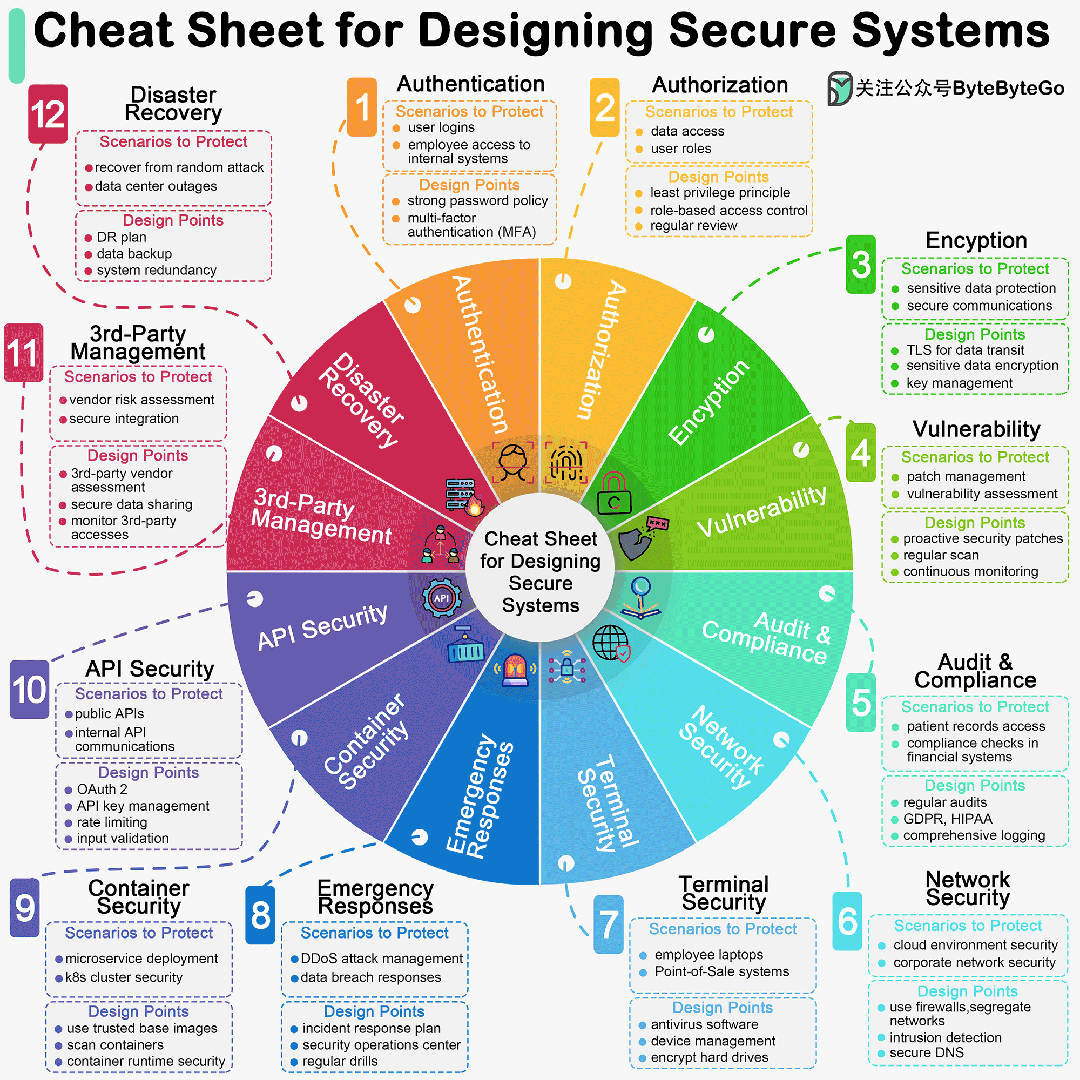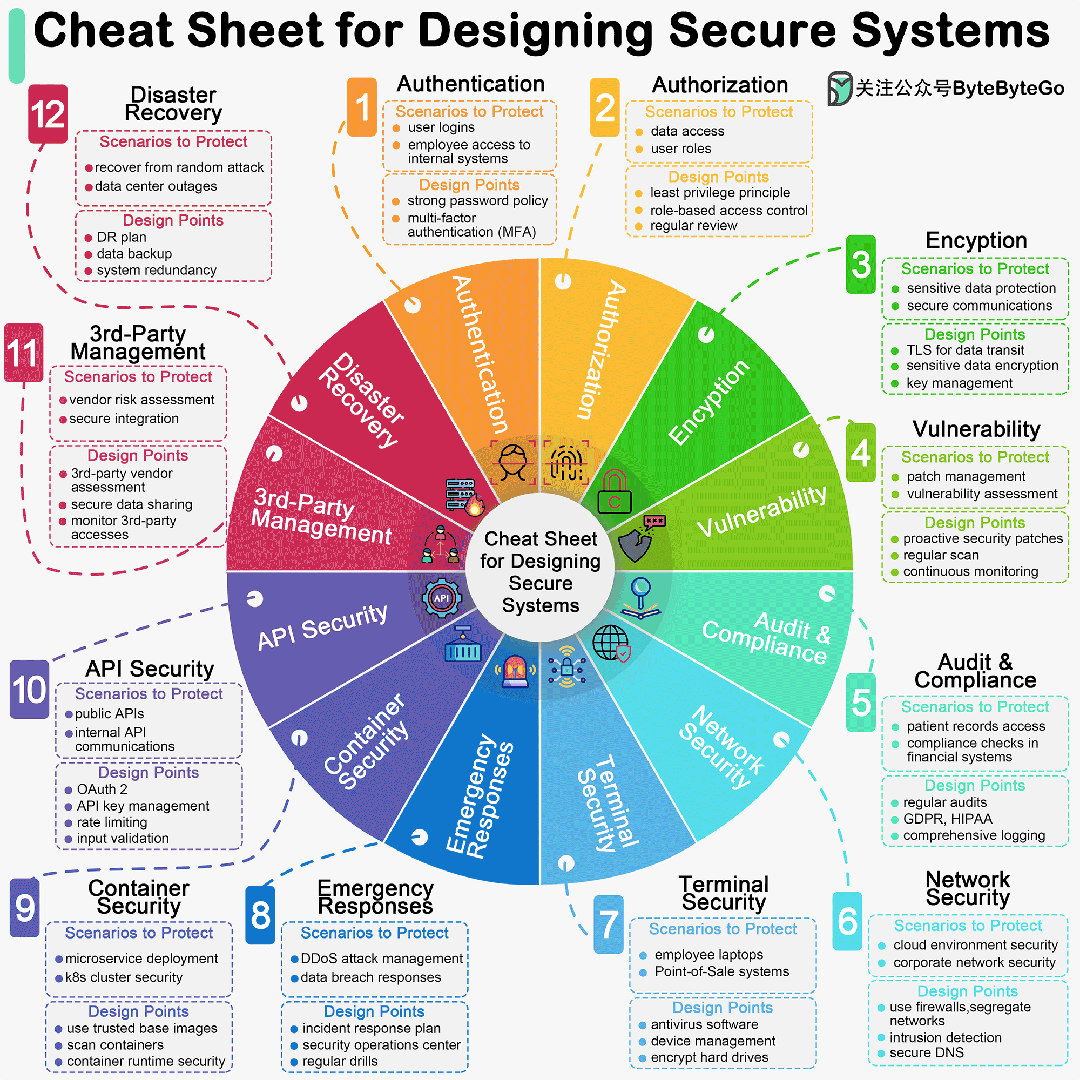
百度智能云千帆大模型平台(百度智能云千帆大模型平台 ModelBuilder)作为面向企业开发者的一站式大模型开发平台,自上线以来受到了广大开发者、企业的关注。至今已经上线收纳了超过 70 种预置模型服务,用户可以快速的调用,并部署不同的模型以寻求最适合自身业务的方案。平台提供了全流程大模型开发工具链,为成千上万的应用提供了稳定的大模型平台服务。
1 千帆 SDK 简介
在平台的基础能力之上,我们围绕大模型工具链设计了一套 SDK (https://github.com/baidubce/bce-qianfan-sdk),充分结合千帆平台的数据、模型训练、评估、部署推理等全栈 AI 能力,让开发者优雅且便捷的访问千帆大模型平台,获得更原生的模型生产开发使用体验。同时我们也提供了大模型工具链的最佳实践,降低开发者使用和学习的门槛。
相较于从千帆 Web 前端控制台构建和发布模型,使用 SDK 的方式可以使整体使用流程更贴近开发者传统的习惯。和原生调用 PaddlePaddle、PyTorch 等发起任务类似,使用代码完成全部的数据处理、洞察分析、清理增强、模型训练、参数调优、评估发布的一整套模型开发使用等流程。
此外,相较于 API 使用,SDK 封装性更好。平台层面 API 主要是一些原子性的操作接口,更符合平台的全功能设计。而 SDK 基于各业务模块进行完整逻辑封装,例如快速的鉴权集成、本地的数据集操作、训练任务 Pipeline,以方便用户更简单、更专注于工具链中的各流程中。
以模型训练为例,直接使用 API 我们可能需要涉及到数十个函数调用,而使用使用 SDK 仅需要三步即可完成一个简单的模型训练流程。此外 SDK 内置了一些额外的开发工具,并提供丰富的 cookbook,帮助用户更好上手。
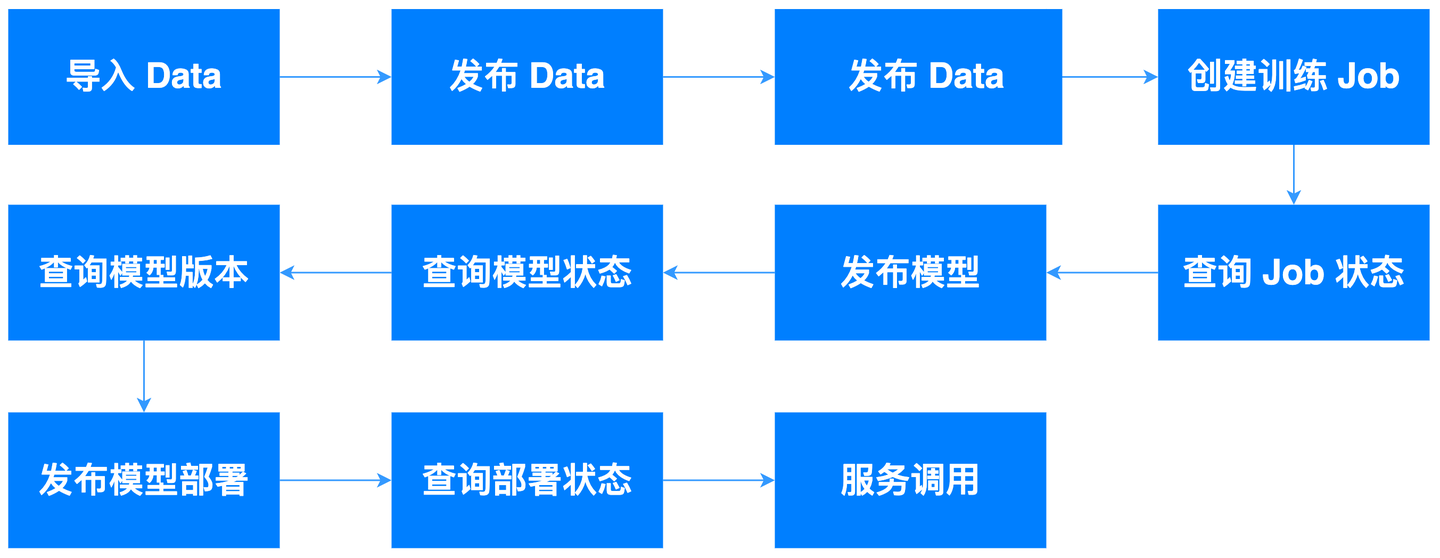

2 千帆 SDK 能力详述
千帆 SDK 诞生的目的就是为了让开发者更贴近大模型。区别于传统的机器学习,深度学习,千帆 SDK 更专注于 Prompt 调整、推理超参搜索、训练数据准备、模型微调、大模型能力评估等关键点,致力于用简单的方式,让 LMOps 的迭代闭环。
千帆 SDK 提供的核心能力包含三大部分:大模型推理,大模型训练,以及 AI 开发工具和框架:
-
大模型推理:实现了对文心大模型系列、开源大模型等模型推理的接口封装,支持 Chat、Completion、Embedding 等,同时也提供了 Prompt 调优,超参搜索等附加能力,以帮助优化推理效果。
-
大模型训练:基于平台能力支持端到端的大模型训练过程,包括训练数据,精调/预训练等。
-
AI 开发工具和框架:提供了通用的 Prompt/Debug/Client 等常见 AI 开发工具和基于千帆特性适配常见的中间层拓展能力框架。

其中,千帆 SDK 通过如下功能实现了相关的能力:
1. Dataset:数据集模块
Dataset 基于 PyArrow 实现,具有高性能、高兼容性等特点:
-
多种数据源加载:支持本地数据集、千帆数据集、BOS 数据集、Hugging Face 数据集等众多数据源。
-
多种格式加载:支持 JSONL、JSON、CSV、文件目录地址等格式。
-
多种处理清洗算子:支持千帆平台,本地等数十种数据处理的清理算子
2. Trainer:训练模块
基于千帆平台 PaaS 能力,提供稳定、可监控、多模型的训练能力:
-
支持 SFT、PostPretrain
-
支持数十种基础模型
-
支持多种自定义参数调节
-
支持训练评估指标
3. Evaluation:评估模块
提供了多种评估方式的自由选择,包括千帆、OpenCompass 等预置的评估逻辑,同时支持本地自定义评估逻辑。
4. Client:命令行 Client 工具
提供了便捷的命令调用多模型、Debug、发起训练、数据集加载上传等操作。
5. Extensions:扩展功能,第三方框架适配
提供了结合 LangChain、Semantic-Kernel、OpenAI 等第三方生态以实现 AI APP 的扩展能力。
3 SDK 案例实践:法律大模型的构建与落地
案例背景:当前的通用模型,例如文心大模型、GPT、Llama 等,虽然在各种通用任务上都表现出了一定效果,但是如法律或医学,模型在领域特定知识方面仍存在不足。由于实际应用中的不同场景,例如咨询、解释分析等对于模型输出的风格和回答的要求不同,需要模型能够有较为适配的推理和解决问题的能力。这些问题在纯粹的调整 Prompt 以及 RAG 等方式的指导下是很难达到较好的效果,因此需要对模型进行 SFT 精调后进行实际业务应用。
-
什么是 SFT:SFT,即 Supervised Fine Tuning,监督微调。监督微调是指利用预训练的神经网络模型,并在少量监督数据上进行针对特定任务的重新训练的技术。千帆大模型平台上,预置了文心大模型系列、Llama 系列、BLOOM、ChatGLM 等众多可选的大模型。除此之外,也支持 HuggingFace Transformers 的自定义上传模型进行训练微调。
案例目标:使用 SDK 完成一个最简单的 LMOps,适用于垂域模型开发场景。案例通过 SFT 精调,结合相应法律领域数据集,让模型在法律场景比较好的表现效果。在阅读完本案例后,用户若有兴趣,可以访问文章最下方 SDK 项目链接,进行更多的实践。
本文参考了 reference 的部分实现思路。 本案例重点在于介绍如何通过 SDK 实现垂类领域构建,不对最终效果做保证。以下步骤中都基于 Python SDK。更多语言支持(Go、Java、JavaScript 等)可在文章最后一节获取。
STEP 0 : 引入千帆 Python SDK 和配置鉴权
用户下载并安装千帆 SDK,在开发项目中引入 SDK 包并配置好鉴权,进入下一步开发。详情可参考快速启动指南:qianfan · PyPI
STEP 1 : 使用千帆 SDK 进行数据加载和模型训练
首先通过 SDK 引入 SFT 需要的法律问答数据集。此处引用了参考案例中的数据集文件 legal_advice.json(可以在文章最后一节获取)。
from qianfan.dataset import (
Dataset,
DataTemplateType,
DataStorageType,
)
from qianfan import config
data_file = "/xxx/xxx/legal_advice.jsonl"
# 这一步需要用户自行将数据集从json转换成jsonl,并转换成平台适配的Prompt+Response数据集格式
ds = Dataset.load(data_file=data_file)
qianfan_dataset_name = "lawyera"
bos_bucket_name = "sdk-test"
bos_bucket_file_path = "/sdk_ds1/" # your_bos_bucket_file_path
# 上传数据集文件到千帆平台
qf_ds = ds.save(
qianfan_dataset_create_args={
"name": qianfan_dataset_name,
"template_type": DataTemplateType.NonSortedConversation,
"storage_type": DataStorageType.PrivateBos,
"storage_id": bos_bucket_name,
"storage_path": bos_bucket_file_path,
}
)
下一步创建精调训练任务并运行。这里使用了 SDK Trainer 类型中的 LLMFinetune。它内部组装了 SFT 所需要的基本 Pipeline, 用于串联数据 -> 训练 -> 模型发布 -> 服务调用等步骤,提供更简化的训练能力。
此处精调基础模型选择了 ENIIE-Speed。除 EB 系列外,SDK 也支持平台上其他的第三方模型精调。
from qianfan.trainer import LLMFinetune
from qianfan.trainer.configs import TrainConfig
trainer = LLMFinetune(
train_type="ERNIE-Speed",
dataset=ds,
train_config=TrainConfig(
peft_type="LoRA",
epoch=10,
learning_rate=0.0002,
lora_rank=8,
max_seq_len=4096,
)
)
trainer.run()
m = trainer.output["model"]STEP 2: 使用 Evalution 模块实现模型评估
精调完模型后,使用 SDK 进行模型评估来衡量精调效果的参考。
这里使用了 qianfan.evaluation.evaluator 模块中的裁判员评估器(QianfanRefereeEvaluator)。使用大模型对被评估大模型的回答打分,可以自定打分 prompt,打分步骤等信息。
from qianfan.evaluation.evaluator import QianfanRefereeEvaluator, QianfanRuleEvaluator
from qianfan.evaluation.consts import QianfanRefereeEvaluatorDefaultMetrics, QianfanRefereeEvaluatorDefaultSteps, QianfanRefereeEvaluatorDefaultMaxScore
from qianfan.evaluation import EvaluationManager
your_app_id = xxxxx
qianfan_evaluators = [
QianfanRefereeEvaluator(
app_id=your_app_id,
prompt_metrics=QianfanRefereeEvaluatorDefaultMetrics,
prompt_steps=QianfanRefereeEvaluatorDefaultSteps,
prompt_max_score=QianfanRefereeEvaluatorDefaultMaxScore,
),
]
test_ds = Dataset.load(qianfan_dataset_id="ds-xxxx")
em = EvaluationManager(qianfan_evaluators=qianfan_evaluators)
result = em.eval([m], test_ds)
任务结束后,SDK 会返回 JSON 格式的评估结果,也可以在平台上看到可视化报告:


STEP 3 :服务部署
在完成模型的评估后,可以对 SFT 精调后模型有一个简单的体感评估,如果效果不错,可以直接用 SDK 发布成模型服务:
from qianfan.model import Service, Model, DeployConfig
from qianfan.model.consts import ServiceType
from qianfan.resources.console.consts import DeployPoolType
sft_svc: Service = m.deploy(DeployConfig(
name="speed_law",
endpoint_prefix="speed_laq",
replicas=1, # 副本数,
pool_type=DeployPoolType.PrivateResource, # 私有资源池
service_type=ServiceType.Chat,
))至此,我们可以就成功完成了模型 SFT 精调并发布了更适用于法律场景的大模型服务。
STEP 4 : 使用 SDK Client 快速验证模型效果
SDK 内置了一个命令行工具,能够在终端直接与千帆平台进行交互。例如与大模型对话、发起训练任务、预览数据集等等。在这里我们用 CLI 工具快速调用模型,来比较模型在 SFT 前后针对法律问题的回答效果。
以下是使用 CLI 工具分别同时请求两组四个不同模型服务得到的效果。这 4 个模型分别为 Qianfan-Chinese-Llama-2-7B、ERNIE-Speed , 和基于这两个基础模型 SFT 微调得到的模型服务(Qianfan-Chinese-Llama-2-7B --> k0m9yafh_dalegal01,ERNIE-Speed --> x898pbzh_speed_law)。基于此可以快速的进行模型效果的验证。可以看到 SFT 后的模型回答明显更简短且部分回答带上了律师人设,更适用于法律咨询的场景。

更多参考
-
SDK 项目链接:GitHub - baidubce/bce-qianfan-sdk: Provide best practices for LMOps, as well as elegant and convenient access to the features of the Qianfan MaaS Platform. (提供大模型工具链最佳实践,以及优雅且便捷地访问千帆大模型平台) (包含 Python、Go、Java 等多语言 SDK)
-
SDK Cookbooks 链接:bce-qianfan-sdk/cookbook at main · baidubce/bce-qianfan-sdk · GitHub
-
千帆平台 SFT 最佳实践:SFT最佳实践 - 千帆大模型平台 | 百度智能云文档
-
SFT 参考案例:GitHub - AndrewZhe/lawyer-llama: 中文法律LLaMA (LLaMA for Chinese legel domain),https://arxiv.org/abs/2305.15062