选基座 —> 扩词表 —> 采样&切分数据 —> 设置学习参数 —> 训练 —> 能力测评)
基座google/flan-t5
T5 模型:NLP Text-to-Text 预训练模型超大规模探索 - 知乎相信大多 NLP 相关者,在时隔 BERT 发布近一年的现在,又被谷歌刚发布的 T5 模型震撼到了。又是一轮屠榜,压过前不久才上榜自家的ALBERT,登上 GLUE 榜首。当然,最大的冲击还是财大气粗,bigger and bigger,但翻…![]() https://zhuanlan.zhihu.com/p/88438851
https://zhuanlan.zhihu.com/p/88438851
Why Text-to-Text?
首先为什么叫 T5 模型,因为是 Transfer Text-to-Text Transformer 的简写,和 XLNet 一样也不在芝麻街玩了,也有说法是吐槽谷歌 T5 Level(高级软件工程师)。
Transfer 来自 Transfer Learning,预训练模型大体在这范畴,Transformer 也不必多说,那么 Text-to-Text 是什么呢。那就是作者在这提出的一个统一框架,靠着大力出奇迹,将所有 NLP 任务都转化成 Text-to-Text (文本到文本)任务。

举几个例子就明白了,比如英德翻译,只需将训练数据集的输入部分前加上“translate English to German(给我从英语翻译成德语)” 就行。假设需要翻译"That is good",那么先转换成 "translate English to German:That is good." 输入模型,之后就可以直接输出德语翻译 “Das ist gut.”
再比如情感分类任务,输入"sentiment:This movie is terrible!",前面直接加上 “sentiment:”,然后就能输出结果“negative(负面)”。
最神奇的是,对于需要输出连续值的 STS-B(文本语义相似度任务),居然也是直接输出文本,而不是加个连续值输出头。以每 0.2 为间隔,从 1 到 5 分之间分成 21 个值作为输出分类任务。比如上图中,输出 3.8 其实不是数值,而是一串文本,之所以能进行这样的操作,应该完全赖于 T5 模型强大的容量。
通过这样的方式就能将 NLP 任务都转换成 Text-to-Text 形式,也就可以用同样的模型,同样的损失函数,同样的训练过程,同样的解码过程来完成所有 NLP 任务。其实这个思想之前 GPT2 论文里有提,上斯坦福 cs224n 时 Socher 讲的 The Natural Language Decathlon 也有提。
Architecture:The Best One
首先作者们先对预训练模型中的多种模型架构(Transformer)进行了比对,最主要的模型架构可以分成下面三种。

第一种,Encoder-Decoder 型,即 Seq2Seq 常用模型,分成 Encoder 和 Decoder 两部分,对于 Encoder 部分,输入可以看到全体,之后结果输给 Decoder,而 Decoder 因为输出方式只能看到之前的。此架构代表是 MASS(今年WMT的胜者),而 BERT 可以看作是其中 Encoder 部分。
第二种, 相当于上面的 Decoder 部分,当前时间步只能看到之前时间步信息。典型代表是 GPT2 还有最近 CTRL 这样的。
第三种,Prefix LM(Language Model) 型,可看作是上面 Encoder 和 Decoder 的融合体,一部分如 Encoder 一样能看到全体信息,一部分如 Decoder 一样只能看到过去信息。最近开源的 UniLM 便是此结构。
上面这些模型架构都是 Transformer 构成,之所以有这些变换,主要是对其中注意力机制的 Mask 操作。

通过实验作者们发现,在提出的这个 Text-to-Text 架构中,Encoder-Decoder 模型效果最好。于是乎,就把它定为 T5 模型,因此所谓的 T5 模型其实就是个 Transformer 的 Encoder-Decoder 模型。
Objectives:Search,Search,Search
之后是对预训练目标的大范围探索,具体做了哪些实验,下面这张图就能一目了然。

总共从四方面来进行比较。
第一个方面,高层次方法(自监督的预训练方法)对比,总共三种方式。
- 语言模型式,就是 GPT-2 那种方式,从左到右预测;
- BERT-style 式,就是像 BERT 一样将一部分给破坏掉,然后还原出来;
- Deshuffling (顺序还原)式,就是将文本打乱,然后还原出来。

其中发现 Bert-style 最好,进入下一轮。
第二方面,对文本一部分进行破坏时的策略,也分三种方法。
- Mask 法,如现在大多模型的做法,将被破坏 token 换成特殊符如 [M];
- replace span(小段替换)法,可以把它当作是把上面 Mask 法中相邻 [M] 都合成了一个特殊符,每一小段替换一个特殊符,提高计算效率;
- Drop 法,没有替换操作,直接随机丢弃一些字符。

此轮获胜的是 Replace Span 法,类似做法如 SpanBERT 也证明了有效性。
当当当,进入下一轮。
第三方面,到底该对文本百分之多少进行破坏呢,挑了 4 个值,10%,15%,25%,50%,最后发现 BERT 的 15% 就很 ok了。这时不得不感叹 BERT 作者 Devlin 这个技术老司机直觉的厉害。
接着进入更细节,第四方面,因为 Replace Span 需要决定对大概多长的小段进行破坏,于是对不同长度进行探索,2,3,5,10 这四个值,最后发现 3 结果最好。
终于获得了完整的 T5 模型,还有它的训练方法。
- Transformer Encoder-Decoder 模型;
- BERT-style 式的破坏方法;
- Replace Span 的破坏策略;
- 15 %的破坏比;
- 3 的破坏时小段长度。
到此基本上 T5 预训练就大致说完了,之后是些细碎探索。
Models
最后就是结合上面所有实验结果,训练了不同规模几个模型,由小到大:
- Small,Encoder 和 Decoder 都只有 6 层,隐维度 512,8 头;
- Base,相当于 Encoder 和 Decoder 都用 BERT-base;
- Large,Encoder 和 Decoder 都用 BERT-large 设置,除了层数只用 12 层;
- 3B(Billion)和11B,层数都用 24 层,不同的是其中头数量和前向层的维度。
11B 的模型最后在 GLUE,SuperGLUE,SQuAD,还有 CNN/DM 上取得了 SOTA,而 WMT 则没有。看了性能表之后,我猜想之所以会有 3B 和 11B 模型出现,主要是为了刷榜。看表就能发现

词表扩充

tokenizer有两种常用形式:WordPiece和BPE
1.1WordPiece
WordPiece 很好理解,就是将所有的「常用字」和「常用词」都存到词表中,
当需要切词的时候就从词表里面查找即可。

bert-base-chinese tokenizer 可视化
上述图片来自可视化工具 [ tokenizer_viewer]。
如上图所示,大名鼎鼎的 BERT 就使用的这种切词法。
当我们输入句子:你好世界,
BERT 就会依次查找词表中对应的字,并将句子切成词的组合。

BERT 切词测试图
当遇到词表中不存在的字词时,tokenizer 会将其标记为特殊的字符 [UNK]:

Out of Vocabulary(OOV)情况
1.2 Byte-level BPE(BBPE)
WordPiece 的方式很有效,但当字词数目过于庞大时这个方式就有点难以实现了。
对于一些多语言模型来讲,要想穷举所有语言中的常用词(穷举不全会造成 OOV),
既费人力又费词表大小,为此,人们引入另一种方法:BBPE。
BPE 不是按照中文字词为最小单位,而是按照 unicode 编码 作为最小粒度。
对于中文来讲,一个汉字是由 3 个 unicode 编码组成的,
因为平时我们不会拆开来看(毕竟中文汉字是不可拆分的),所以我一开始对这个概念也不太熟悉。
我们来看看 LLaMA 的 tokenizer 对中文是如何进行 encode 的:

LLaMa tokenizer 中文测试
上述图片来自可视化工具 [ tokenizer_viewer]。
可以看到,「编码」两个字能够被正常切成 2 个字,
但「待」却被切成了 3 个 token,这里的每个 token 就是 1 个 unicode 编码。

LLaMA tokenizer 查找结果,「待」不在词表中,「编」「码」在词表中
通过 token 查找功能,我们可以发现「编」「码」在词表中,但「待」不在词表中。
但任何 1 个汉字都是可以由 unicode 表示(只是组合顺序不同),因此「待」就被切成了 3 个 token。
| BBPE 的优势 | 不会出现 OOV 的情况。不管是怎样的汉字,只要可以用 unicode 表示,就都会存在于词表中。 |
| BBPE 的劣势 | 模型训练起来将会更吃力一些。毕竟像「待」这样的汉字特定 unicode 组合其实是不需要模型学习的,但模型却需要通过学习来知道合法的 unicode 序列。 |
通常在模型训练不够充足的时候,模型会输出一些乱码(不合法的 unicode 序列):
游泳池是杭州西湖的一个游泳池,���1.3 词表扩充
为了降低模型的训练难度,人们通常会考虑在原来的词表上进行「词表扩充」,
也就是将一些常见的汉字 token 手动添加到原来的 tokenizer 中,从而降低模型的训练难度。
我们对比 [Chinese-LLaMA] 和 [LLaMA] 之间的 tokenizer 的区别:

Chinese LLaMA 和 原始LLaMA 之间 tokenizer 的区别
上述图片来自可视化工具 [ tokenizer_viewer]。
我们可以发现:Chinese LLaMA 在原始 tokenizer 上新增了17953 个 tokens,且加入 token 的大部分为汉字。
而在 [BELLE] 中也有同样的做法:
在 120w 行中文文本上训练出一个 5w 规模的 token 集合,
并将这部分 token 集合与原来的 LLaMA 词表做合并,
最后再在 3.2B 的中文语料上对这部分新扩展的 token embedding 做二次预训练。

《Towards Better Instruction Following Language Models for Chinese》 Page-4
数据
主要讲一些数据预处理的工作,这也是数据环节最重要的一环,其旨在得到一个高质量的数据。
(1)Data sampling
数据采样是一个最基本的手段,最容易想到的上采样一些高质量来源的数据,下采样一些低质量的数据。当然这也和最终想要一个什么样的模型有关,比如 Meta AI就是想训练一个science的大模型,所以其主要就是采样用一些paper的数据等等。甚至可以训练一个分类器来过滤数据。
在 [gpt3] 的训练过程中,存在多个训练数据源,论文中提到:对不同的数据源会选择不同采样比例:

GPT3 Paper Page-9
通过「数据源」采样的方式,能够缓解模型在训练的时候受到「数据集规模大小」的影响。
从上图中可以看到,相对较大的数据集(Common Crawl)会使用相对较大的采样比例(60%),
这个比例远远小于该数据集在整体数据集中所占的规模(410 / 499 = 82.1%),
因此,CC 数据集最终实际上只被训练了 0.44(0.6 / 0.82 * (300 / 499))个 epoch。
而对于规模比较小的数据集(Wikipedia),则将多被训练几次(3.4 个 epoch)。
这样一来就能使得模型不会太偏向于规模较大的数据集,从而失去对规模小但作用大的数据集上的学习信息。
数据预处理主要指如何将「文档」进行向量化。
通常来讲,在 Finetune 任务中,我们通常会直接使用 truncation 将超过阈值(2048)的文本给截断,
但在 Pretrain 任务中,这种方式显得有些浪费。
以书籍数据为例,一本书的内容肯定远远多余 2048 个 token,但如果采用头部截断的方式,
则每本书永远只能够学习到开头的 2048 tokens 的内容(连序章都不一定能看完)。
因此,最好的方式是将长文章按照 seq_len(2048)作分割,将切割后的向量喂给模型做训
(2)Data cleaning
对数据进行清洗和重新格式化,比如删除HTML代码或标记等等。此外,对于某些项目,还会纠正拼写错误、处理跨领域同形异义词,或者删除有偏见/有害言论等等,不过一些其他项目认为模型应该看到真实文本世界,并自动学会处理拼写错误和有害内容,所以不采用后面这些处理。
(3)Non-standard textual components handling
该部分就是需要把非文本的部分转化为文本,比如表情包等等
(4)Data deduplication
数据去重,比如常用的LSH。
(5) Downstream task data removal
数据泄漏就是怕测试数据集不小心正好在训练集中,所以可以使用下游任务数据移除方法(如n-grams)来删除在测试数据集中也存在的部分训练数据。
预训练步骤
Pretraining 的思路很简单,就是输入一堆文本,让模型做 Next Token Prediction 的任务,这个很好理解。
训练一个拥有数十亿参数的语言模型是一个高度实验性的过程,需要进行大量的试错成本。所以可以从训练一个更小的模型开始,确保流程都没问题且有效果,然后逐渐扩大到模型的参数量。随着规模的扩大,会出现一些需要新的需要解决的问题。
(1)Model Architecture
为了降低试错成本,可以借鉴一些已经成功模型的框架比如GPT3的模型框架比如GPT-NeoX-20B、OPT-175B都是在GPT3的模型框架的基础上做了一些优化。
(2)Experiments and Hyperparameter Search
预训练过程涉及大量实验,这里面有大量的超参,比如:权重初始化、位置嵌入、优化器、激活函数、学习率、权重衰减、损失函数、序列长度、层数、注意力头数、参数数量、稠密层与稀疏层、batchsize和dropout等等。
这里一般会结合手动试错和自动超参数优化(HPO)的方式,来寻找最佳的配置组合以实现最佳性能。典型的需要进行自动搜索的超参数包括学习率、batchsize、dropout等。
但是毕竟训练一个百亿参数的模型是非常耗费资源的,所以不可能全部无脑搜索参数,这里可以借鉴一些已有的工作,此外,还有一些超参数需要在训练时进行调整,以平衡学习效率和训练收敛性:
学习率:前期线性增加,然后再衰减。 batchsize开始时使用较小,然后逐渐增加到较大的size。

不过在训练这么大且复杂的大模型,就像其他任何足够大且复杂的项目一样,随时可能会出现各种问题。
(3)Hardware Failure
在训练过程中,硬件可能会随时出现一些故障问题,这个时候不得不手动进行自动重新启动,这个时候可以以保存的最后一次checkpoint热启继续训练,同时记得把故障的节点进行隔离。
(4)Training Instability
训练的稳定性也是一个最常见的基本挑战。在训练模型时学习率和权重初始化等超参数会直接影响模型的稳定性。比如当loss开始学崩时,同样可以从较早的checkpoint降低学习率然后重新开始训练。
模型越大loss越可能发生波动也就是学崩,目前还没有系统性的全面分析,下面是一些实践经验来提高模型收敛。
(a)Batch size: 在GPU资源允许的情况下,把size开到最大。
(b)Batch Normalization: 在mini-batch内对激活层归一化。
(c)Learning Rate Scheduling: 较高的学习率可能会导致loss振荡或发散,从而导致损失波动。可以随时间递减学习率以,即逐渐减小模型参数的更新幅度,提高稳定性。常见的schedules包括step decay等等。不过事先很难确定要使用哪种学习率,但可以使用不同的学习率schedules方式来观察模型的反应。
(d)Weight Initialization: 好的模型权重初始化可以直接帮助模型最后的收敛,最常见的就是高斯噪声初始化,或者在Transformer模型中使用T-Fixup初始化。
(e)Model training starting point: 如果已经有一个在相关任务中训练好的预训练模型,那么可以基于其热启,这样可以大大提高模型的收敛。
(f)Regularization: 一些正则化技术比如dropout、权重衰减和L1/L2正则化,这些都可以通过减少过拟合和提高泛化能力来帮助模型更好地收敛。
(g)Data Augmentation: 通过数据增强对训练数据进行扩充也可以帮助模型更好地泛化并减少过拟合。
(h)Hot-swapping during training: 在训练奔溃的时候,可以手动调整optimizers和activation激活函数,甚至这个过程需要一整个团队全天候监控,然后看到学崩后就要看情况想办法应对性的调整。
(i)Other simple strategies mitigating the instability issue when encountered: 如果学崩,可以跳过loss波动期间出现的一些batch数据(这是因为当前特定batch数据与当前特定模型参数的组合导致了loss波动),即从之前的checkpoint重新热启开始训。
另外需要千万注意的就是确保保存和保留最终模型训练环境和checkpoint。这样,如果将来需要重新执行某些操作或复制某些内容,就可以接着做了。
同时还可以尝试一些消融研究。这可以帮助了解将模型的某些部分移除可能会对性能产生何种影响。消融研究可以大幅减小模型的大小,同时仍保留大部分模型的预测性能。
模型评估
训练好了模型,接下来就是评估模型了,通常会有很多benchmark数据集以评估其在逻辑推理、翻译、自然语言推理、问答等方面的能力。一些数据集如下:

另外评估中还有一个术语n-shot学习,比如常见的就是Zero-shot、One-shot、Few-shot。
扩展补充:
硬件(并行化)
- Techniques for Parallelization
并行化技术主要就是大规模利用GPU来进行并行化任务
(1)Data Parallelism
这是最常见的并行化手段,它主要是把数据分成多个块,然后每个节点就可以在本地独立的跑各自的数据任务,最后再和其他节点通信,进而汇总最后的结果;它的好处就是计算效率高,每个节点可以独自计算自己的任务且这种方法易于实现,但是缺点就是内存要求较高,因为它需要把模型在每个节点都完整的copy一份。

(2)Tensor Parallelism
张量并行就是将大型矩阵乘法分解为较小的子矩阵计算,然后使用多个GPU同时执行这些计算。这样可以通过异步性和减少节点之间的通信开销来加快训练时间。张量并行的好处是它具有提高了内存效率,但是缺点就是它在每次前向和反向传播中引入了额外的通信,因此需要较高通信带宽。

(3)Pipeline parallelism and model parallelism
Pipe并行和模型并行可以尽可能减少通信,显著的提高训练速度。如果对比上述张量并行来看的话,Pipe并行和模型并行属于“层间并行”,而张量并行属于“层内并行”,具体来说模型并行是将模型分割到多个GPU上,并对每个模型使用相同的数据;因此,每个GPU处理的是模型的一部分,而不是数据的一部分。同时这两种方法的缺点是:并行的程度受到模型深度的限制,因此无法无限扩展。

当然了还可以把上面的并行技术进行打包组合,一并利用起来,比如NVIDIA提出来的PTD-P方法是在多机之间利用pipeline parallelism,在单机多卡上面利用tensor parallelism和Data Parallelism;为了将这些技术更加方便的用到深度深度学习领域,一些深度学习框架比如TensorFlow, Torch等等都进行了很好的支持。
(4) Gradient accumulation
梯度累计是将多个batch的梯度进行累计,然后统一更新,其减少了多GPU之间的通信。
(5) Asynchronous stochastic gradient descent optimization
其主要思路就是每次计算一个很小的batch,然后把梯度收集好,然后等到最后需要更新模型参数的时候再把这些梯度发回到servers。
(6) Micro-batching
Micro-batching就是把非常小的small mini-batches组合成大batch,这个idea也越来越受欢迎。
BERT
什么是BERT? - 知乎BERT的全称为Bidirectional Encoder Representation from Transformers,是一个预训练的语言表征模型。它强调了不再像以往一样采用传统的单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练,而是采…![]() https://zhuanlan.zhihu.com/p/98855346
https://zhuanlan.zhihu.com/p/98855346
BERT 最主要是开创性地提出同时用 Masked Language Model (掩语言模型) 和 Next Sentence Prediction(下句预测)两个任务,加上大量的数据,来预训练出一个大型的 Transformer 模型。
而这个模型,也就是今天的主角 BERT。
BERT 输入部件
既然要各自 finetune,那便得先了解 BERT 这头大肥猪的主要部位。
首先是最关键的输入部分,之后大部分 finetune 和这部分联系很大。

自上向下一一可知,BERT 输入最主要组成部分便是,词(token 这里姑且理解为词)向量、段(segment)向量、位置向量。
词向量很好理解,也是模型中关于词最主要信息所在;
段向量是因为 BERT 里有下句预测任务,所以会有两句拼接起来,上句与下句,上句有上句段向量,下句则有下句段向量,也就是图中A与B。此外,句子末尾都有加[SEP]结尾符,两句拼接开头有[CLS]符;
而位置向量则是因为 Transformer 模型不能记住时序,所以人为加入表示位置的向量。
之后这三个向量拼接起来的输入会喂入BERT模型,输出各个位置的表示向量。

BERT 输出部件
介绍完BERT的输入,实际上BERT的输出也就呼之欲出了,因为Transformer的特点就是有多少个输入就有多少个对应的输出,如下图:

BERT的输出
C为分类token([CLS])对应最后一个Transformer的输出,TiT_i 则代表其他token对应最后一个Transformer的输出。对于一些token级别的任务(如,序列标注和问答任务),就把TiT_i 输入到额外的输出层中进行预测。对于一些句子级别的任务(如,自然语言推断和情感分类任务),就把C输入到额外的输出层中,这里也就解释了为什么要在每一个token序列前都要插入特定的分类token。
到此为止,BERT的输入输出都已经介绍完毕了,更多具体的细节可以到原论文中察看。
BERT的预训练任务
实际上预训练的概念在CV(Computer Vision,计算机视觉)中已经是很成熟了,应用十分广泛。CV中所采用的预训练任务一般是ImageNet图像分类任务,完成图像分类任务的前提是必须能抽取出良好的图像特征,同时ImageNet数据集有规模大、质量高的优点,因此常常能够获得很好的效果。
虽然NLP领域没有像ImageNet这样质量高的人工标注数据,但是可以利用大规模文本数据的自监督性质来构建预训练任务。因此BERT构建了两个预训练任务,分别是Masked Language Model和Next Sentence Prediction。
3.1 Masked Language Model(MLM)
MLM是BERT能够不受单向语言模型所限制的原因。简单来说就是以15%的概率用mask token ([MASK])随机地对每一个训练序列中的token进行替换,然后预测出[MASK]位置原有的单词。然而,由于[MASK]并不会出现在下游任务的微调(fine-tuning)阶段,因此预训练阶段和微调阶段之间产生了不匹配(这里很好解释,就是预训练的目标会令产生的语言表征对[MASK]敏感,但是却对其他token不敏感)。因此BERT采用了以下策略来解决这个问题:
首先在每一个训练序列中以15%的概率随机地选中某个token位置用于预测,假如是第i个token被选中,则会被替换成以下三个token之一
1)80%的时候是[MASK]。如,my dog is hairy——>my dog is [MASK]
2)10%的时候是随机的其他token。如,my dog is hairy——>my dog is apple
3)10%的时候是原来的token(保持不变,个人认为是作为2)所对应的负类)。如,my dog is hairy——>my dog is hairy
再用该位置对应的 TiT_i 去预测出原来的token(输入到全连接,然后用softmax输出每个token的概率,最后用交叉熵计算loss)。
该策略令到BERT不再只对[MASK]敏感,而是对所有的token都敏感,以致能抽取出任何token的表征信息。这里给出论文中关于该策略的实验数据:
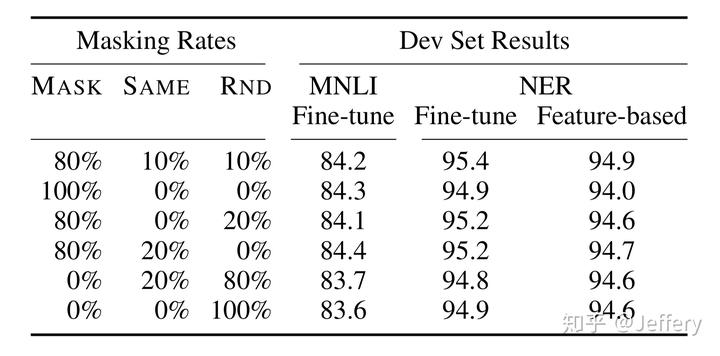
多种策略的实验结果
3.2 Next Sentence Prediction(NSP)
一些如问答、自然语言推断等任务需要理解两个句子之间的关系,而MLM任务倾向于抽取token层次的表征,因此不能直接获取句子层次的表征。为了使模型能够有能力理解句子间的关系,BERT使用了NSP任务来预训练,简单来说就是预测两个句子是否连在一起。具体的做法是:对于每一个训练样例,我们在语料库中挑选出句子A和句子B来组成,50%的时候句子B就是句子A的下一句(标注为IsNext),剩下50%的时候句子B是语料库中的随机句子(标注为NotNext)。接下来把训练样例输入到BERT模型中,用[CLS]对应的C信息去进行二分类的预测。
3.3 预训练任务总结
最后训练样例长这样:
Input1=[CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
Label1=IsNext
Input2=[CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label2=NotNext
把每一个训练样例输入到BERT中可以相应获得两个任务对应的loss,再把这两个loss加在一起就是整体的预训练loss。(也就是两个任务同时进行训练)
可以明显地看出,这两个任务所需的数据其实都可以从无标签的文本数据中构建(自监督性质),比CV中需要人工标注的ImageNet数据集可简单多了。
BERT、GPT、T5
- BERT,是一个Transformer encoder结构(双向attention),把input从文本空间映射到向量空间
- GPT,是一个Transformer decoder结构,给定一个向量空间的向量,GPT将会把这个向量映射到文本空间
- T5是BERT+GPT模型
面试
1.学习率warmup
use cosine learning rate schedule with initial and final learning rates of 1e−4 and 1e−5
参数设置:
lr_scheduler_type: 'linearwarmupcosinelr'
init_lr: 0.0001 # 1e-4
min_lr: 0.00001 # 1e-5
lr_decay_rate: 0.9
warmup_lr: 0.00001 # 1e-5
warmup_steps: 1000解释:
lr_scheduler_type (学习率调度器类型): 使用了'linearwarmupcosinelr'类型的学习率调度器。这种调度器首先进行线性预热,然后根据余弦函数来动态地调整学习率。
init_lr (初始学习率): 设置为0.0001 (或1e-4)。在训练开始时,学习率从这个初始值开始,并随着训练的进行而调整。
min_lr (最小学习率): 设置为0.00001 (或1e-5)。学习率调度器会使学习率衰减到这个最小值以下,以确保在训练的后期阶段保持模型的稳定性。
lr_decay_rate (学习率衰减率): 设置为0.9。这个参数决定了学习率在每个周期结束后的衰减率。
warmup_lr (预热学习率): 设置为0.00001 (或1e-5)。在学习率调度器中,预热学习率指的是在预热阶段开始时的学习率值。
warmup_steps (预热步数): 设置为1000。这个参数定义了预热阶段持续的步数,即模型在预热阶段逐渐增加学习率的步数。总结:
使用Warmup预热学习率的方式,即先用最初的小学习率训练,然后每个step增大一点点,直到达到最初设置的比较大的学习率时(注:此时预热学习率完成),采用最初设置的学习率进行训练(注:预热学习率完成后的训练过程,学习率是衰减的),有助于使模型收敛速度变快,效果更佳。
刚刚开始的时候,模型对数据的“分布”理解为零,或者是说“均匀分布”(初始化一般都是以均匀分布来初始化);在第一轮训练的时候,每个数据对模型来说都是新的,随着训练模型会很快地进行数据分布修正,这时候学习率就很大,很有可能在刚刚开始就会导致过拟合,后期需要要通过多轮训练才能拉回来。当训练了一段时间(比如两轮、三轮)后,模型已经对每个数据过几遍了,或者说对当前的batch而言有了一些正确的先验,较大的学习率就不那么容易会使模型学偏,所以可以适当调大学习率。这个过程就也就是warmup。
那后期为什么学习率又要减小呢?这就是我们正常训练时候,学习率降低有助于更好的收敛,当模型学习到一定的程度,模型的分布就学习的比较稳定了。如果还用较大的学习率,就会破坏这种稳定性,导致网络波动比较大,现在已经十分接近了最优了,为了靠近这个最优点,就要用很小的学习率了
2.混合精度训练use_amp
We use gradient checkpointing to improve training throughput and save memory, and train all models in a mixed precision setting, using float-32 for numerically unstable operations, e.g. layer normalization, and bfloat-168, otherwise.
use_amp (是否使用混合精度训练): 设置为True解释:
在训练过程中采用了混合精度训练的设置。混合精度训练是一种同时使用单精度浮点数 (float32) 和半精度浮点数 (bfloat16) 的训练方式。在这种设置下,作者使用了单精度浮点数来处理数值不稳定的操作,例如层归一化 (layer normalization),而在其他情况下则使用了半精度浮点数。这样可以在保持数值稳定性的同时,提高训练的速度和效率。
问题1:为什么使用混合精度训练
答:
混合精度训练是一种通过同时使用单精度浮点数(float32)和半精度浮点数(float16)来加速训练的技术。以下是使用混合精度训练的一些优势和原因:
-
减少内存占用:半精度浮点数需要的内存空间比单精度浮点数少一半,因此使用混合精度训练可以大大减少模型和梯度所需的内存空间,特别是对于大型模型而言,这一点尤为重要。
-
加速计算速度:半精度浮点数的计算速度比单精度浮点数更快,因为它们需要更少的位数来表示数值。这意味着在使用混合精度训练时,模型的计算速度会更快,训练时间更短。
-
保持数值稳定性:虽然半精度浮点数的数值范围相对较小,可能会导致数值精度下降,但通过使用梯度缩放等技术,可以有效地解决数值稳定性的问题,确保模型训练的收敛性和准确性
综上所述,使用混合精度训练可以在不牺牲模型准确性的前提下,显著加速模型训练过程,降低资源消耗,从而更高效地进行深度学习模型的训练和优化。
问题2:“通过使用梯度缩放等技术,可以有效地解决数值稳定性的问”,梯度缩放是什么技术
答:
在混合精度训练中,通常会将部分计算转换为半精度浮点数 (bfloat16),以提高计算速度和节省内存。然而,半精度浮点数的数值范围相对较小,可能会导致数值的溢出或下溢问题,从而影响模型的训练效果。
梯度缩放通过在反向传播过程中对梯度进行缩放,以保持梯度的数值范围在一个合理的范围内,从而提高数值稳定性。具体来说,梯度缩放会在计算梯度时乘以一个缩放因子,使梯度的数值范围适合于半精度浮点数的表示范围。这样可以避免梯度的溢出或下溢问题,并保证模型训练的稳定性和收敛性。
梯度缩放的缩放因子通常由模型的参数更新量决定,可以根据参数更新量的大小来动态地调整缩放因子。通过梯度缩放技术,可以有效地解决混合精度训练中的数值稳定性问题,使模型训练更加稳定和可靠。
问题3:为什么不直接使用半精度进行训练,反而使用混合精度
答:
尽管半精度浮点数(float16)在训练中可以提供计算速度上的加速和内存消耗的减少,但在某些情况下,直接使用半精度可能会导致数值稳定性的问题,从而影响模型的训练效果。混合精度训练通过同时使用半精度浮点数(float16)和单精度浮点数(float32),兼顾了速度和数值稳定性,是一种更加全面和稳健的训练方法。以下是一些原因:
-
数值稳定性:在某些情况下,直接使用半精度浮点数可能会导致梯度消失或爆炸等数值稳定性问题,特别是对于深度较大的神经网络或者训练较长的模型,这种问题可能更加显著。混合精度训练通过同时使用单精度浮点数来处理梯度等容易受数值影响的计算,从而提高了数值稳定性。
-
数值范围:半精度浮点数的数值范围相对较小,可能会限制模型的表示能力,尤其是对于参数较大或梯度较大的情况。使用混合精度训练可以在需要时自动转换为单精度浮点数,以适应不同的数值范围,提高模型的表示能力和训练效果。
-
梯度累积:在某些训练策略中,需要对梯度进行累积,以在一定周期内更新模型参数。直接使用半精度浮点数进行梯度累积可能会导致精度损失,从而影响模型的训练效果。混合精度训练可以在需要时自动转换为单精度浮点数,以保持训练的准确性和稳定性。
综上所述,混合精度训练综合考虑了速度和数值稳定性的因素,是一种更加全面和稳健的训练方法,适用于大型模型和复杂任务的训练过程。
问:为什么层归一化数值不稳定,要用单精度浮点数
答:
层归一化在计算过程中可能会涉及到除法操作,而除法操作对数值的稳定性要求较高。在深度学习模型的训练中,由于梯度的反向传播过程涉及到除法操作,可能会出现数值不稳定的情况,特别是当分母接近零时,会出现梯度爆炸或梯度消失等问题。这种情况在层归一化中尤为突出,因为它需要计算输入数据的均值和方差,并对数据进行归一化操作。
单精度浮点数 (float32) 提供了更高的数值精度和范围,相比之下,半精度浮点数 (bfloat16) 在表示大范围数值时可能会丢失一些精度。因此,在涉及到除法等数值不稳定操作时,使用单精度浮点数可以更好地保持数值的稳定性,避免数值的溢出或不稳定情况。这就是为什么在层归一化等数值不稳定操作中,作者选择使用单精度浮点数来提高数值稳定性和模型训练的效果。
3.梯度检查点gradient_checkpointing
We use gradient checkpointing to improve training throughput and save memory, and train all models in a mixed precision setting, using float-32 for numerically unstable operations, e.g. layer normalization, and bfloat-168, otherwise.
enable_gradient_checkpointing (是否启用梯度检查点): 设置为True,可能是为了减少内存使用。问题1:什么是梯度检查点
答:
梯度检查点是一种优化技术,旨在减少内存占用和提高训练速度。在深度学习模型的训练中,通常需要存储计算图中的中间结果,以便在反向传播时使用。然而,存储完整的计算图可能会消耗大量的内存,尤其是在模型较大或训练批次较大的情况下。
梯度检查点技术通过在计算图中存储部分中间结果而不是完整的计算图,来减少内存占用。具体来说,它将计算图分割成多个阶段,并在每个阶段存储部分计算结果。在反向传播过程中,只需要在需要时重新计算存储的部分结果,而不需要存储整个计算图。这样可以显著减少内存占用,并提高训练的速度和效率。
问题2:作用
答:
-
节省内存: 通过只存储计算图中的部分中间结果,梯度检查点技术可以显著减少内存占用,特别是对于大型模型和大批次训练数据而言,节省的内存空间可以非常可观。
-
提高训练速度: 减少内存占用可以降低模型训练过程中的内存访问开销,从而提高训练的速度和吞吐量。此外,在反向传播过程中只需重新计算部分中间结果,而不需要重新计算整个计算图,也可以加快训练的速度
问题3:“在反向传播过程中只需重新计算部分中间结果,而不需要重新计算整个计算图”,可以举个例子说明吗
答:
当使用梯度检查点技术时,在反向传播过程中只需重新计算部分中间结果,而不需要重新计算整个计算图。让我们通过一个简单的示例来说明这一点:
假设我们有一个简单的深度学习模型,由两个隐藏层组成,每个隐藏层都有若干神经元。在前向传播过程中,我们需要计算每一层的输出,并将其作为下一层的输入。在反向传播过程中,我们需要计算损失函数相对于每个参数的梯度,以便进行参数更新。在常规的计算图中,我们需要存储每一层的中间结果以便在反向传播时使用。
使用梯度检查点技术,我们可以在计算图的某些阶段存储部分中间结果,而不是整个计算图。例如,我们可以在第一个隐藏层的输出处存储中间结果,然后在第二个隐藏层的输入处重新计算该中间结果。这样,在反向传播过程中,我们只需重新计算第一个隐藏层的输出处的中间结果,而不需要重新计算整个计算图。
具体来说,假设我们的模型包含以下计算步骤:
- 输入数据经过第一个隐藏层,得到第一个隐藏层的输出。
- 第一个隐藏层的输出经过第二个隐藏层,得到最终输出。
- 计算损失函数并进行反向传播。
在使用梯度检查点技术时,我们可以在第一个隐藏层的输出处存储中间结果。在反向传播过程中,我们只需重新计算第一个隐藏层的输出处的中间结果,而不需要重新计算整个计算图。这样可以减少内存占用和计算时间,提高训练效率。
4.最大范数max_norm
max_norm (最大范数): 设置为5max_norm 参数用于控制梯度裁剪的阈值。梯度裁剪是一种用于应对梯度爆炸问题的技术,在深度学习训练中非常常见。当梯度值过大时,梯度下降算法可能会导致参数更新过大,使得模型的训练变得不稳定甚至无法收敛。
设置 max_norm 参数为 5 意味着梯度的范数(也就是梯度向量的长度)将被限制在 5 以内。具体来说,如果某个参数的梯度的范数大于 5,那么该参数的梯度将会被重新缩放,使其范数等于 5。这样做的目的是防止梯度爆炸问题的发生,保持模型训练的稳定性
假设我们有一个简单的神经网络模型,包含一个隐藏层和一个输出层。训练过程中使用了反向传播算法来更新模型参数。在某一次迭代中,我们计算了隐藏层和输出层的梯度,并准备使用这些梯度来更新模型参数。