概述
近年来,大规模语言模型(LLM)在理解和生成人类语言方面取得了显著的飞跃,这些进步不仅推动了语言学和计算机编程的发展,还为多个领域带来了创新的突破。特别是模型如GPT-3和PaLM,它们通过吸收海量文本数据,已经能够掌握复杂的语言模式。人工智能技术的迅猛发展不断推动着LLM的进化,并加速了这一领域的专业创新。这些进步是随着模型规模的扩大、数据量的增加以及计算能力的提升而逐步实现的,其中许多尖端模型都基于变压器(Transformer)架构,并采用了自我监督学习技术。
在医学领域,大规模语言模型的应用展现出了创新性和巨大的潜力。它们通过分析庞大的医学文献和整合新知识,有潜力为医学界带来革命性的认识。研究人员正在积极探索如何利用这些模型来补充医学专业知识,并提升医疗服务的质量。
然而,这一新兴技术领域也面临着不小的挑战。例如,人们质疑大规模语言模型是否能够以专家水平处理医学知识,以及它们是否可能产生误导性信息。了解这些技术的潜力和局限,对于在医学领域负责任地应用语言模型至关重要。
本文聚焦于谷歌的Gemini模型,深入探讨了大规模语言模型在医疗领域的应用潜力与挑战。Gemini作为一个先进的多模态语言模型,本文通过一系列严格的基准测试,对其能力进行了全面的评估,旨在揭示其在医疗领域的长处与短板。
研究结果证实了Gemini在理解多样医学主题方面的卓越能力,同时也指出了它在需要深层次专业知识的领域中的局限性。本文深入分析了Gemini及其他大规模语言模型在医疗领域的应用前景,并强调了它们的优势与面临的挑战,期望能为讨论人工智能技术在医疗领域未来发展提供有益的视角。
Gemini
这里将深入探讨Gemini模型的结构、性能,并讨论如何评估其推理能力。Gemini模型采用了尖端的多模态架构,并且充分利用了谷歌先进的TPU(张量处理单元)硬件,以实现复杂的分析和推理任务。
项目地址:https://github.com/promptslab/rosettaeval
论文地址:https://arxiv.org/pdf/2402.07023.pdf
双子座架构
- 基础架构:Gemini模型基于先进的Transformer解码器,能够处理长达32,000个标记的上下文。这种设计使其能够理解和生成复杂的语言结构。
- 多模态能力:模型能够无缝整合文本、图形和音频数据,这在处理医学信息时尤为重要,因为医学数据经常包含图像(如X光片、CT扫描)和文本(如病历、研究论文)。
- 可靠性与效率:Gemini的设计注重减少硬件故障和数据失真,提高了模型的可靠性和效率。
医学标杆
- MultiMedQA:这是一个评估临床推理能力的医学质量保证数据集,包含了如USMLE(美国医学执照考试)和NEET-PG(印度研究生医学入学考试)等考试中的问题,这些问题需要广泛的跨学科知识。
- MedQA和MedMCQA:这些数据集分别来自美国和印度的医学许可考试,提出了具有挑战性的临床推理问题。
- PubMedQA:包含1,000个问题,这些问题综合了研究摘要中的见解,用于评估模型在封闭领域的推理能力。
- MMLU:这是一个测试基础科学知识与医学理解整合能力的广泛领域数据集,也是一个全面的医学问答数据集,用于测试医学推理能力。
特殊基准
- Med-HALT:这是一个评估潜在危险推理倾向的基准,基于“首先,不造成伤害”这一医学原则设计。它通过推理幻觉测试(RHT)和记忆幻觉测试(MHT)来评估模型的逻辑分析能力,并在适当的时候承认不确定性。
- 视觉问答(VQA)基准:使用来自《新英格兰医学杂志》(NEJM)图像挑战赛的100道多项选择题,评估Gemini的多模态推理能力。这包括图像理解、医学知识回忆和逐步推理的测试。
性能评估
通过上述基准测试,Gemini展示了其创新方法如何解决医疗领域的复杂问题。这些测试不仅证明了Gemini的推理能力,还突出了其在处理医疗信息方面的准确性和可靠性。
总体来说,Gemini模型的评估显示了其在医学领域的应用潜力,同时也揭示了在实际应用中可能遇到的挑战。随着进一步的研究和发展,Gemini和其他类似的大规模语言模型有望成为医学专业人员的有力辅助工具,帮助他们提供更高质量的医疗服务。
实验结果
这里分析 Gemini 在 MultiMedQA、Med-HALT 幻觉和医学视觉问题解答 (VQA) 基准测试中的表现,并将其与其他模型进行比较。
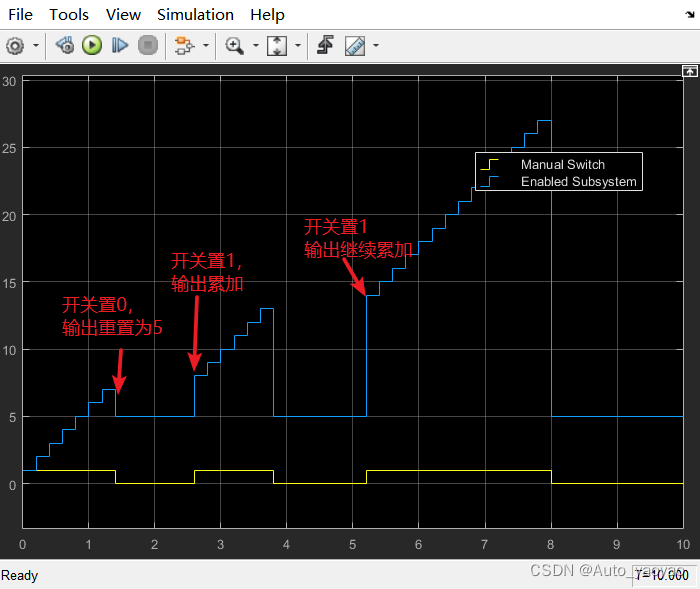
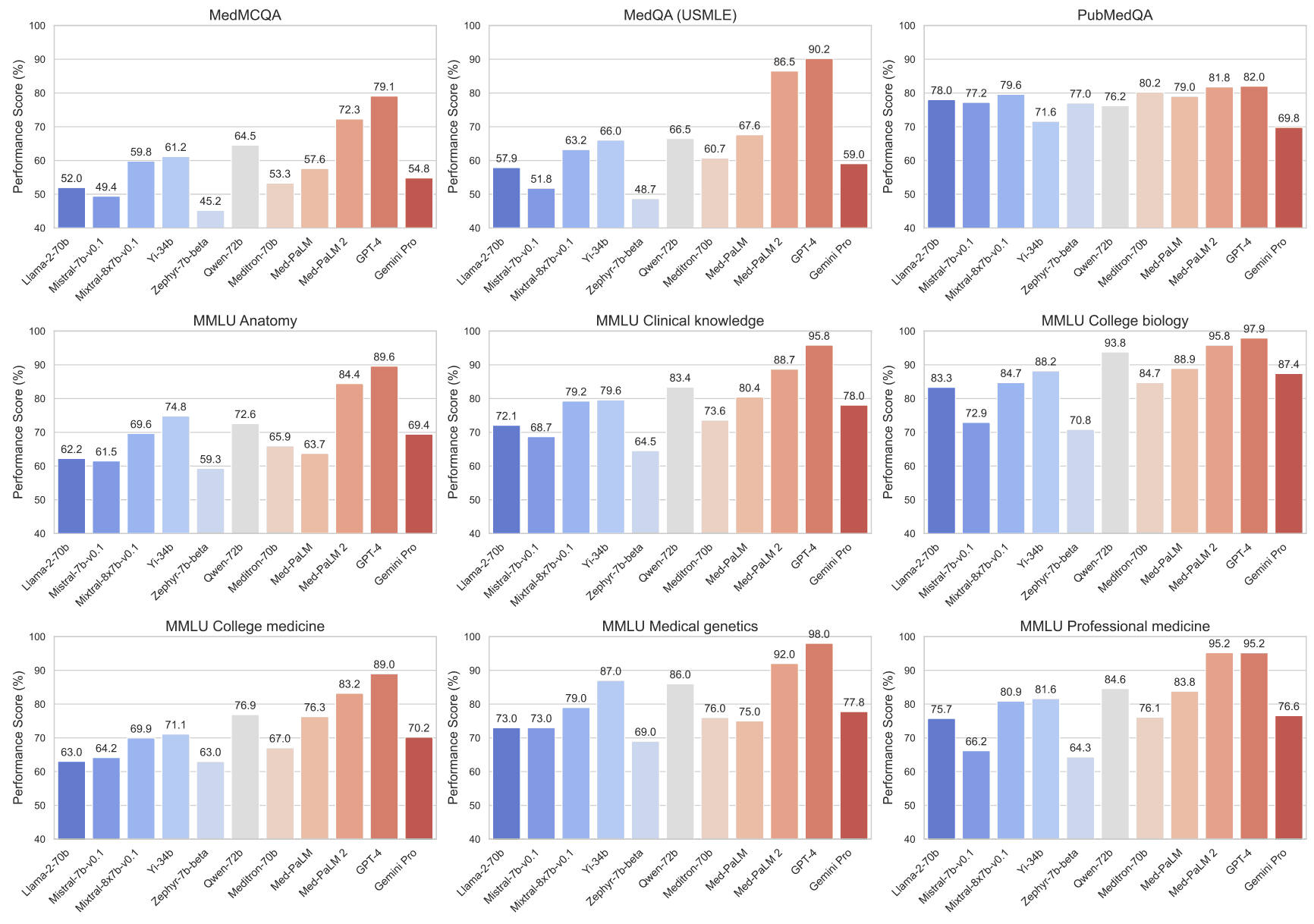
首先,让我们看看 Gemini 在 MultiMedQA 基准测试中的表现。下图显示了 Med-PaLM 2、GPT-4 和 GeminiPro的 MultiMedQA 分数。 Gemini Pro 在各种医疗主题的 MultiMedQA 基准中都取得了显著的成绩。
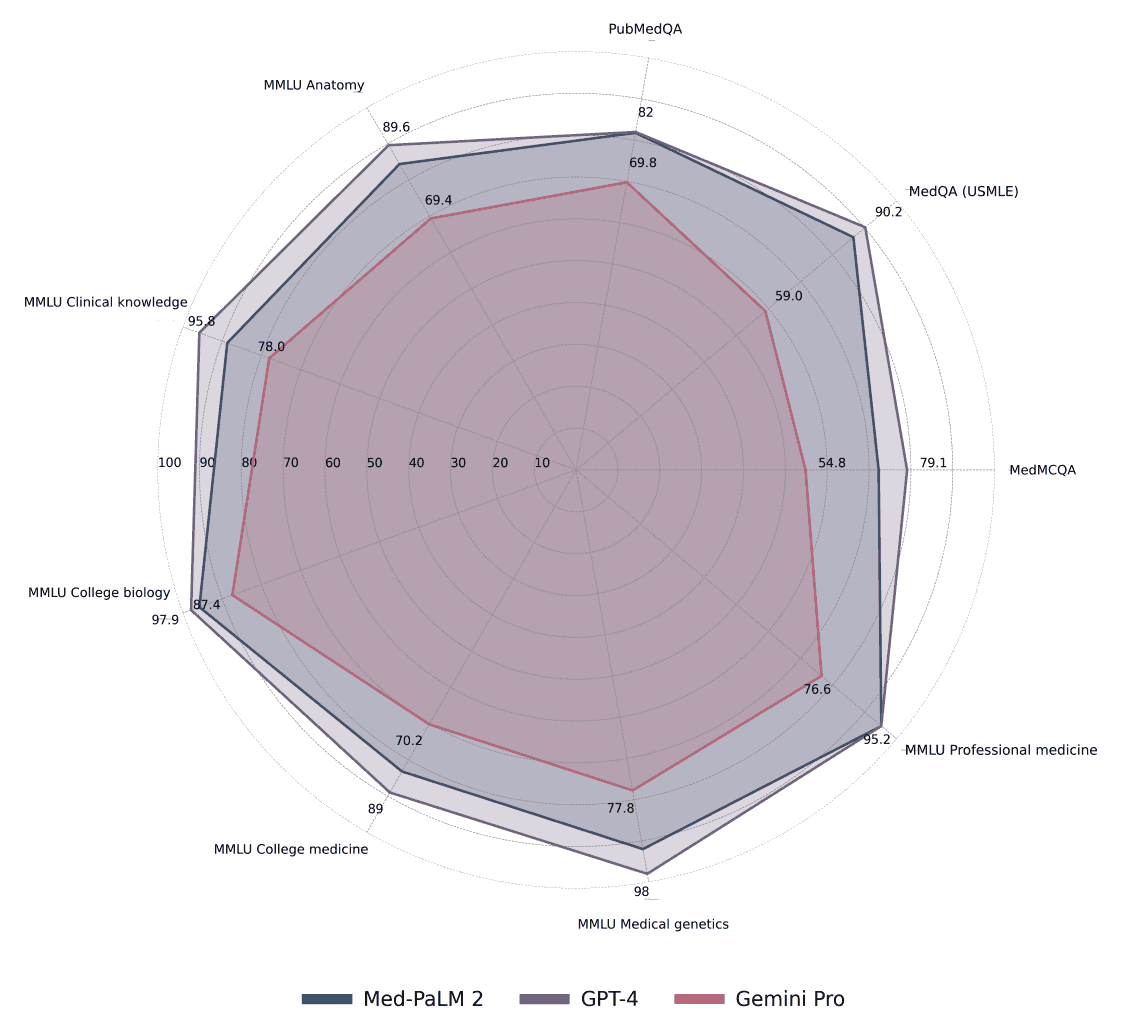
下表还将 Gemini Pro 的结果与 Flan-PaLM、Med-PaLM 和 Med-PaLM 2 的结果进行了比较。Gemini Pro 在 MedQA(USMLE)数据集上的得分率为 67.0%,是 MedPA-LM2 的最高分(高达 86.5%),以及 86.1% 的 GPT-4(5-shot),与 GPT-4 的最高分(高达 86.5%)无法相比。这一巨大差异表明,Gemini Pro 在处理复杂、多步骤的美国国家医学考试式问题方面的能力还有待提高。

MedMCQA 数据集的覆盖范围也很广,是一个特别具有挑战性的环境:Gemini Pro 在 MedMCQA 数据集上的得分率为 62.2%,与排行榜上的其他模型相比差距很大。例如,ER 和 best 在 Med-PALM 2 上的得分都达到了 72.3%,表明其在此环境下具有更强的理解和处理能力。此外,GPT-4 模型(包括基础版和 5 连拍版)的表现也很出色,得分率在 72.4% 到 73.7% 之间。这些结果表明,要在 Gemini MedMCQA 数据集上取得更好的性能,还有一定的改进空间。
PubMedQA 数据集也使用是/否/表格式,这给二元和三元问题带来了独特的挑战;Gemini Pro 在该数据集上的得分率为 70.7%,Med-PaLM 2 的最高得分率为 81.8%,而 5GPT-4-base 为 80.4%。这种性能差异表明,Gemini Pro 需要提高处理二元和三元回答的能力,以及处理科学文献和临床领域问题的能力。
此外,在 MMLU 临床知识数据集上,Gemini Pro 的表现不如 Med-PaLM 2 和 5-shot GPT-4 等最先进的模型。GPT-4-base都达到了 88.7%。在分析特定子域时,这一趋势依然存在。在医学遗传学评估中,Gemini Pro 的准确率为 81.8%,而 5 发GPT-4-base 的正确率为 97.0%。同样,在解剖学评估中,Gemini Pro 的准确率为 76.9%,但比 5 发GPT-4 base85.2% 的准确率低 8%。在专业医学和大学生物学等其他类别中也存在类似的性能差距,Gemini Pro 无法赶上顶级模型。此外,在大学医学类别中,Gemini Pro 的得分率为 79.3%,显示出合理的能力,但与 Med-PaLM 2 和 GPT-4 变体等模型的顶级性能相比还有差距。这些结果表明,Gemini Pro 在处理医疗数据方面具有很强的基本能力,其架构也很有潜力。不过,从 Med-PaLM 2 和 GPT-4 等机型的最佳性能来看,显然还有改进的余地。
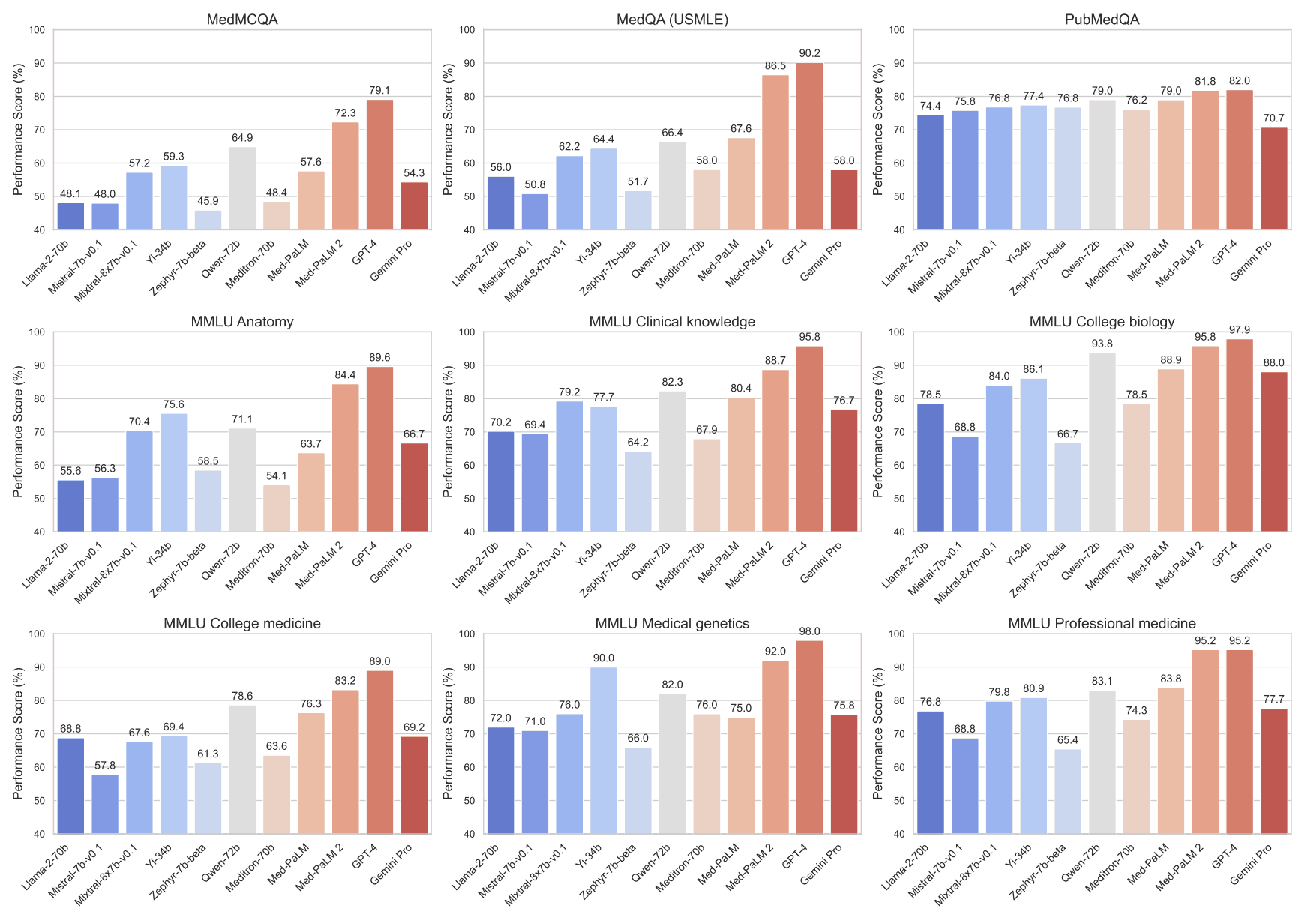
此外,还进行了与开源大规模语言模型的对比分析。在此,我们使用了一系列最先进的模型,包括 Llama-2-70b、Mistral-7bv0.1、Mixtral-8x7b-v0.1、Yi-34b、Zephyr-7b-beta、Qwen-72b 和 Meditron-70b,以评估它们的零-射和 FewShot 的能力。通过使用 MultiMedQA 基准进行标准化分析,评估了 Zero-Shot 和 FewShot 的能力,以量化已发布的 L-large 语言模型的能力和局限性。下图分别显示了 Zero-Shot 和 FewShot 的性能。
(零投篮命中率)。
(少儿摄影表演)。
跨数据集的性能:我们在一系列医学数据集上测试了许多开源模型,以评估它们的四射和零射能力;在五射学习基准中,Qwen-72b 的表现始终如一。Qwen-72b的灵活性和从少量优秀实例中吸收知识的能力表明,它在特定医学知识领域的广泛人工智能能力与特定医学专业知识的细微要求之间架起了一座桥梁。
零拍与四拍提示:零拍与四拍训练结果的比较揭示了基于例子的训练对模型性能的重要性 Yi-34b 和 Qwen-72b 等大规模语言模型表明,引入少量例子就能明显改善性能。这些结果表明,基于示例的学习在提高模型的准确性和推理性能方面发挥着重要作用,尤其是在医学等专业领域。
针对特定模型的见解:评估结果表明,在不同的医学问题类型和数据集上,每个模型都表现出独特的优缺点;Gemini Pro 在多个数据集上表现出一致的性能,并具有很强的适用于不同情况的能力,但在某些领域,尤其是 Yi-34b 等模型的效果不佳。另一方面,Mixtral-7b-v0.1 等模型在 PubMedQA 数据集中显示出巨大的潜力,可以对科学文章进行有效的分析和推断。此外,Mixtral-8x7b-v0.1 在 MMLU 临床知识和 MMLU 大学生生物学上的表现尤为突出,显示了其吸收复杂医学信息的能力;Qwen-72b 处理多种类型医学问题的能力很强,无需事先举例;Mixtral-8x7b-v0.1 处理各种医学问题的能力也很强,无需事先举例。该模型在 MMLU 大学生物数据集上的表现无与伦比,准确率高达 93.75%,并能很好地理解复杂的生物概念。
总结
论文对Gemini模型的功能进行了全面的基准测试,揭示了其在医疗领域的应用潜力,同时也指出了未来研究中需要解决的一些局限性。以下是对这些局限性的进一步讨论,以及它们对未来研究方向的影响:
局限性
-
Gemini Pro与Gemini Ultra:当前的评估仅限于Gemini Pro的功能,而没有充分利用更先进的Gemini Ultra功能。这意味着,对于模型的完整能力,我们的理解可能还不够全面。未来的研究可以通过访问Gemini Ultra的API,来探索其更高级的功能,从而获得更深入的理解。
-
长问题评分:在多个医学质量评估中,对较长问题的评分是一个重要的方面,但当前研究并未包括这一点。未来研究应该扩展到这一领域,以更全面地评估模型处理复杂查询的能力。
-
实时数据和先进技术:使用实时数据和如检索增强生成(RAG)等先进技术,可能会进一步提升模型的性能。未来的研究可以探索这些技术如何与Gemini模型结合,以提高其在医疗领域的应用效果。
-
VQA任务的样本量:视觉问答(VQA)任务中使用的样本量相对较少。未来的研究需要考虑更大的数据集,以更准确地评估模型的多模态推理能力。
解决局限性的重要性
解决上述局限性对于全面了解Gemini模型的潜力至关重要。它们将有助于为医疗应用开发更先进的人工智能工具,从而提高医疗服务的质量和效率。
Gemini模型的评估结果
研究还根据医疗领域的多个基准对Gemini模型进行了评估。结果显示,尽管Gemini在一系列医疗主题上表现出了良好的理解力,但在某些方面与其他领先模型相比还存在不足。特别是,模型在某些情况下可能会产生误导性的信息(幻觉),因此提高其可靠性和可信度是非常重要的。
人工智能与人类临床判断力
这项研究为医学多模态模型评估奠定了基础,并为促进未来发展提供了一个公共工具。最终,尽管人工智能技术在医疗领域具有巨大的潜力,但它无法取代人类的临床判断力和同理心。然而,精心设计的人工智能辅助工具可以提高医疗专业人员的专业技能,支持医学的治疗和服务使命。