大语言模型基础之GPT
- GPT简介
- 1. 无监督预训练
- 2. 有监督下游任务微调
- GPT-4体系结构
- 1. GPT-4的模型结构
- 2. GPT-4并行策略
- 3. GPT-4中的专家并行
- GPT-4的特点
- 参考连接
以ELMo为代表的动态词向量模型开启了语言模型预训练的大门,此后,出现了以GPT和BERT为代表的基于Transformer的大规模预训练模型。利用丰富的训练语料、自监督的预训练人物及Transformer等深度神经网络结构,预训练语言模型具备了通用且强大的自然语言表示能力,能够有效地学习到词汇、语法和语义信息。将预训练模型应用于下游人物时,不需要了解太多的人物细节,不需要设计特定的神经网络结构,只需要“微调”预训练模型,即使用具体任务的标注数据在预训练语言模型上进行监督训练,就可以取得显著的性能提升。
GPT简介
OpenAI公司在2018年提出的生成式预训练语言模型(Generative Pre-Training, GPT)是典型的生成式预训练语言模型之一。GPT的模型结构如下所示:
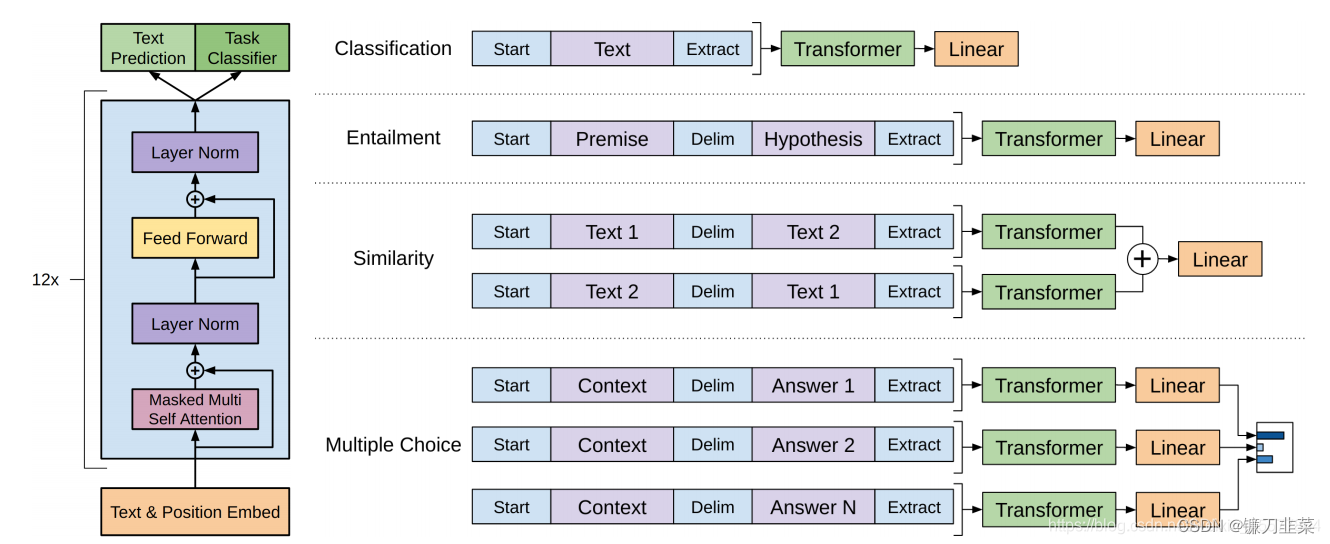
它是由多层Transformer组成的单向语言模型,主要分为输入层、编码层和输出层三部分。直观上如下图所示:
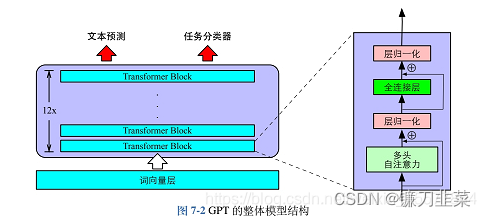
GPT 使用 Transformer的 Decoder 结构,并对 Transformer Decoder 进行了一些改动,原本的 Decoder 包含了两个 Multi-Head Attention 结构,GPT 只保留了 Mask Multi-Head Attention。
接下来重点介绍GPT的无监督预训练、有监督下游任务以及基于HuggingFace的预训练语言实践。
1. 无监督预训练
GPT采用生成式预训练方法,单向意味着模型只能从左到右或从右到左对文本序列建模,所采用的Transformer结果和解码策略保证了输入文本每个位置只能依赖过去时刻的信息。
具体而言,假设我们无标记的语料库里面有一句话是
μ
=
{
u
1
,
u
2
,
.
.
.
,
u
n
}
\mu=\{u_1,u_2,...,u_n\}
μ={u1,u2,...,un},GPT的模型参数是
Θ
\Theta
Θ,作者设计了下面的目标函数来最大化
L
1
(
μ
)
L_1(\mu)
L1(μ):
L
1
(
μ
)
=
∑
i
log
P
(
u
i
∣
u
i
−
k
,
.
.
.
,
u
i
−
1
;
Θ
)
L_1(\mu)=\sum_i\log{P(u_i|u_{i-k},...,u_{i-1};\Theta)}
L1(μ)=i∑logP(ui∣ui−k,...,ui−1;Θ)
式中,k是上下文窗口的大小。这个式子的本质是让模型看到前面k个词,然后预测下一个词是什么,再根据真实的下一个词来计算误差,并使用随机梯度下降来训练。即希望模型能够根据前k个词更好地预测下一个词。
GPT首先在输入层将给定的文本序列映射为稠密的向量: v i = v i t + v i p v_i=v_i^t+v_i^p vi=vit+vip其中, v i t v_i^t vit是词 u i u_i ui的词向量, v i p v_i^p vip是词 u i u_i ui的位置向量, v i v_i vi为第i个位置的单词经过模型输入层(第0层)后的输出。GPT模型的输入层与神经网络语言模型的不同之处在于其需要添加位置向量。这是因为Transformer结构自身无法感知位置导致的,因此需要来自输入层的额外位置信息。
经过输入层编码,模型得到表示向量序列
v
=
v
1
,
.
.
.
,
v
n
v=v_1, ..., v_n
v=v1,...,vn,随后将
v
v
v送入模型编码层。编码层由L个Transformer模块组成,在自注意力机制的作用下,每一层的每个表示向量都会包含之前位置表示向量的信息,使每个表示向量都具备丰富的上下文信息,而且,经过多层编码,GPT就能得到每个单词层次化的组合式表示,其计算过程表示为:
h
(
L
)
=
Transformer-Block
(
L
)
(
h
(
0
)
)
h^{(L)}=\text{Transformer-Block}^{(L)}(h^{(0)})
h(L)=Transformer-Block(L)(h(0))
其中,
h
(
L
)
∈
R
d
×
n
h^{(L)}\in R^{d\times n}
h(L)∈Rd×n表示第L层的表示向量序列,n为序列长度,d为模型隐藏层维度,L为模型总层数。
GPT模型的输出层基于最后一层的表示
h
(
L
)
h^{(L)}
h(L),预测每个位置上的条件概率,其计算过程可以表示为
P
(
w
i
∣
w
1
,
.
.
.
,
w
i
−
1
)
=
Softmax
(
W
e
h
i
(
L
)
+
b
o
u
t
)
P(w_i|w_1,...,w_{i-1})=\text{Softmax}(W^eh_i^{(L)}+b^{out})
P(wi∣w1,...,wi−1)=Softmax(Wehi(L)+bout)
其中
W
e
∈
R
∣
V
∣
×
d
W^e\in R^{|V|\times d}
We∈R∣V∣×d为词向量矩阵,
∣
V
∣
|V|
∣V∣为词表大小。
单向语言模型按照阅读顺序输入文本序列
u
u
u,用常规语言模型目标优化
u
u
u的最大似然估计,使之能根据输入历史序列对当前词做出准确的预测:
L
P
T
(
u
)
=
−
∑
i
=
1
n
log
P
(
u
i
∣
u
0
,
.
.
.
,
u
i
−
1
;
θ
)
L^{PT}(u)=-\sum_{i=1}^n\log{P(u_i|u_0,...,u_{i-1};\theta)}
LPT(u)=−i=1∑nlogP(ui∣u0,...,ui−1;θ)
其中
θ
\theta
θ代表模型参数。
也可以基于马尔可夫假设,只使用部分过去词进行训练。预训练时通常使用随机梯度下降法进行反向传播,优化该负对数似然函数。
2. 有监督下游任务微调
通过无监督语言模型预训练,使得GPT 模型具备了一定的通用语义表示能力。下游任务微调(Downstream Task Fine-tuning)的目的是在通用语义表示的基础上,根据下游任务的特性进行适配。
下游任务通常需要利用有标注数据集进行训练,数据集使用 D D D进行表示,每个样例由输入长度为n的文本序列 x = x 1 x 2 . . . x n x=x_1x_2...x_n x=x1x2...xn和对应的标签 y y y构成。
输入首先通过Transformer Block,然后通过一个线性层(参数为
W
y
W_y
Wy)和Softmax得到最终的输出,计算真实标签上面的概率:
P
(
y
∣
x
1
,
.
.
.
,
x
n
)
=
softmax
(
h
l
n
W
y
)
P(y|x_1,...,x_n)=\text{softmax}(h_l^nW_y)
P(y∣x1,...,xn)=softmax(hlnWy)
其中
h
l
n
h_l^n
hln表示第
l
l
l个block的最终输出,
W
y
W_y
Wy是fine-tuning的权重。
通过对整个标注数据集
D
D
D优化如下目标函数精调下游任务
L
F
T
(
D
)
=
−
∑
x
,
y
log
P
(
y
∣
x
1
.
.
.
x
n
)
L^{FT}(D)=-\sum_{x,y}\log{P(y|x_1...x_n)}
LFT(D)=−x,y∑logP(y∣x1...xn)
在微调过程中,下游任务针对任务目标进行优化,很容易使得模型遗忘预训练阶段所学习的通用语义知识表示,从而损失模型的通用性和泛化能力,导致出现灾难性遗忘(Catastrophic Forgetting)问题。
因此,通常采用混合预训练任务损失和下游微调损失的方法来缓解,即由两个目标函数:
- 给定一个序列,让模型预测序列未来的词
- 给定完整的序列,让模型预测序列未来的标号。
L
=
L
F
T
(
D
)
+
λ
L
P
T
(
D
)
L = L^{FT}(D)+\lambda L^{PT}(D)
L=LFT(D)+λLPT(D)
其中
λ
\lambda
λ的取值为[0, 1],用于调节预训练任务的损失占比。
GPT-4体系结构
先说结论:
- GPT-4(Generative Pre-trained Transformer 4)是 OpenAI 发布的最新 GPT 系列模型。它是一个大规模多模态模型,相比 GPT-3.5 / ChatGPT,GPT-4 可以接受图像和文本两种形式的输入,产生文本输出。
- GPT-4的输出依旧是一个自回归的单词预测任务。技术上,GPT-4 采用了**专家混合(MoE)**技术,进一步增强模型的能力。
- 整体来说,GPT-4 在各种专业和学术基准上表现出了人类的水平,对于生成式的幻觉、安全问题均有较大的改善。
GPT4技术报告:GPT-4 Technical Report
1. GPT-4的模型结构
GPT-4 的体系结构由16个不同的专家模型组成,每个模型都有 111B 个参数,总计约 1.76 万亿个参数。除了更大的参数规模外,另一个重要的细节是 GPT-4 使用了专家混合(Mixture of Experts,简写为 MoE)架构,这意味着模型中的不同组件或“专家”协同工作,每个组件都有助于最终输出。
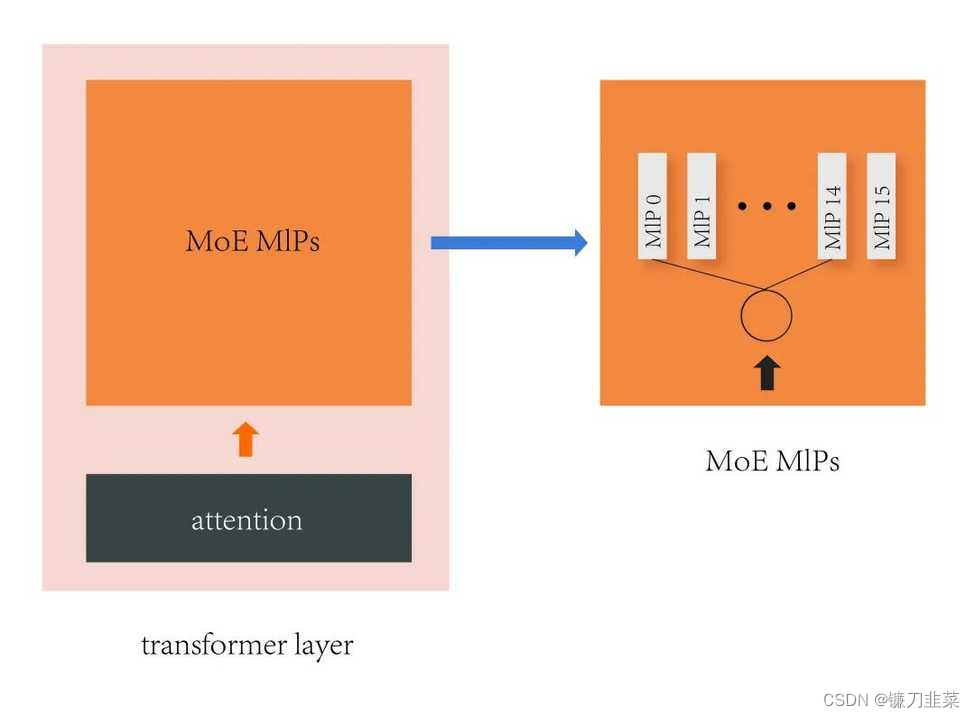
上图可视了采用 MoE 的 Transformer 层。在 GPT-4 中 Attention 的参数量有 55B,MoE 的参数量是 111B * 16,一共 120 层 Transformer。每个 token 会通过一个路由算法选择两个 MLP 进行计算,参数 seq_len 为 8k,每个 MLP 分到 1k 个 token。GPT-4 的模型宽度,深度基本和 GPT-3 (175B) 差不多,区别在于 MLP 的数量要多16倍。
2. GPT-4并行策略
GPT-4 训练采用的并行策略是:
- 张量并行:8
- 流水并行:16
- 数据并行:196
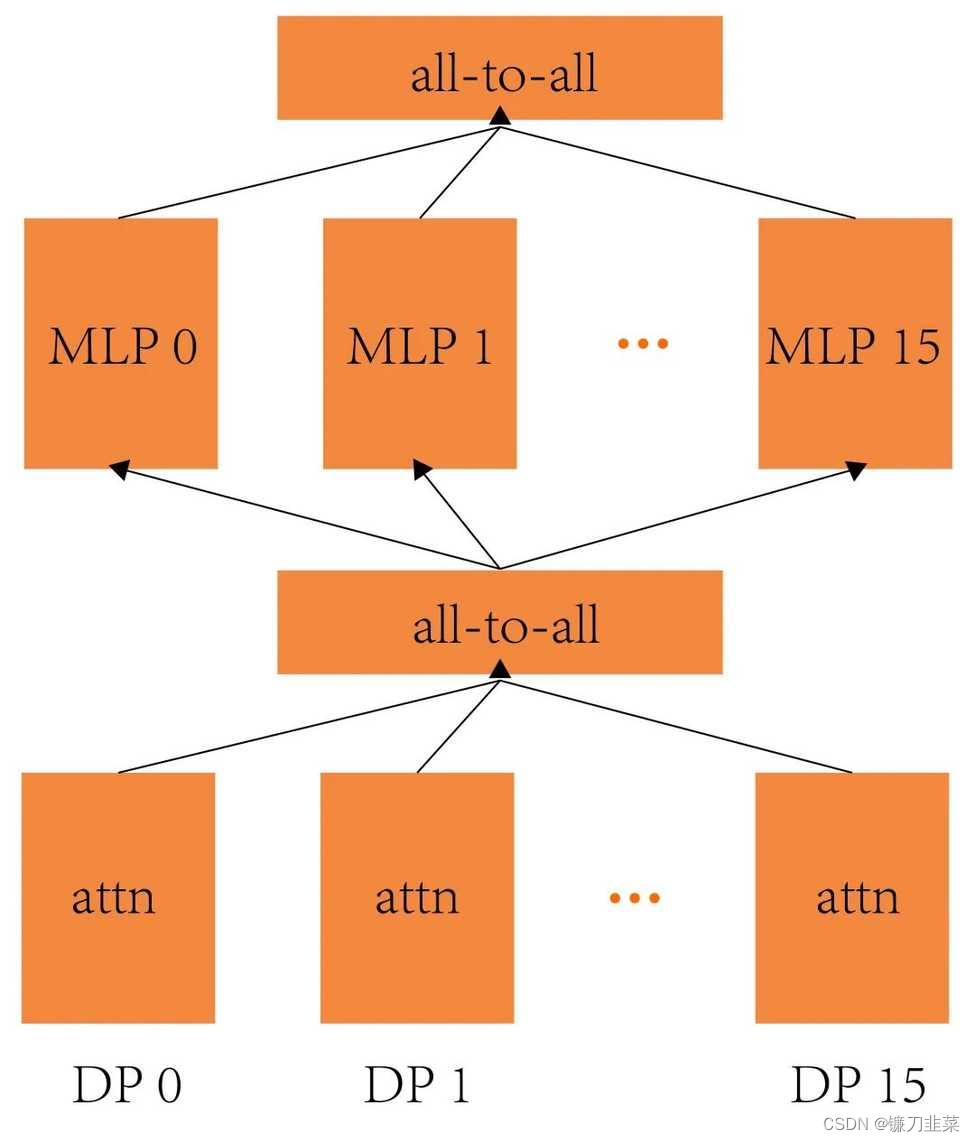
总计使用约 3125 台机器(25000 张 A100)进行训练。其中 batch size 为 60M token,seq_len 为 8k。张量并行和流水并行包含了 GPT-4 完整的模型参数,其结构如下:
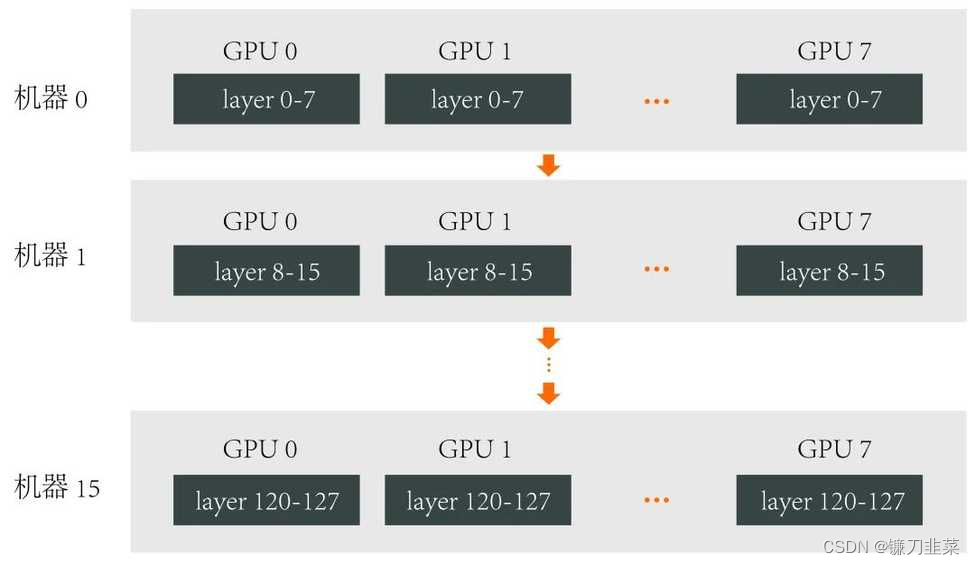
其中,张量并行通讯耗时占比小于 15%,PipeDream 流水线气泡占比 28% 左右,Interleaved 1F1B 流水线气泡占比 16% 左右。
3. GPT-4中的专家并行
专家混合(Mixture of Experts,简写为 MoE)是一种在模型增强的道路达到极限时采用的实用方法。运作原理很简单——由更简单的模型或“专家”组成一个小组,每个模型或专家都针对数据的特定方面,然后利用他们的集体智慧。
这就像处理一项复杂的任务。比如建造一所房子会招聘建筑师、工程师和室内设计师等专业人士,每个人都有自己独特的专业知识。类似地,MoE模型由多个“专家”组成,每个专家都精通某个特定领域,协作以提供增强的结果。如下图所示:
对于 MoE 模型进行并行训练,这里可以做一个初步的估计:按照目前最大的 8 路张量并行,16 路流水线并行计算,每个 GPU 上的参数量是 14B,假设用 FP32 的梯度,则参数和梯度需要占用 84 GB 的显存,目前市面上还没有能完整放下显卡。因此,GPT-4 大概率会使用专家并行(Expert Parallelism)技术来节省显存占用。
GPT-4的特点
- 具有图像理解能力,突破纯文字的模态,增加了图像模态的输入。
- 支持更长的上下文窗口,GPT-4 的 seq_len 为 8k,是 ChatGPT 上下文长度的2倍。
- 复杂任务处理能力大幅提升
- 改善幻觉、安全等局限性
参考连接
- 开源大语言模型(LLM)汇总
- GPT-4大模型硬核解读,看完成半个专家
- GPT模型总结【模型结构及计算过程_详细说明】
- LLM 系列超详细解读 (一):GPT:无标注数据的预训练生成式语言模型
- 深入浅出 GPT-4 的体系结构
- Hugging Face 中文预训练模型使用介绍及情感分析项目实战