目录
SQL及定义域概念
SQL是什么
定义域
关系简介
关系的定义
关系的封闭性
关系模型简介
关系模型
谓词逻辑
运算基础
SQL的加减乘除
SQL的除法1
SQL的除法2
SQL的除法3
三值逻辑
NULL的危害
消除NULL
SQL及定义域概念
SQL是什么
Structured Query Language:SQL作为一种操作命令集,是具有数据定义和数据操纵等多种功能的数据库语言。
1.数据定义:又称为“DDL语言”,定义数据库的逻辑结构,包括定义数据库、基本表、视图和索引4部分。
2.数据操纵:又称为“DML语言”,包括插入、删除和更新三种操作。
3.数据查询:又称为“DQL语言”,包括数据查询操作。
4.数据控制:又称为“DCL语言”,对用户访问数据的控制有基本表和视图的授权及回收。
5.事务控制:又称为“TCL语言”,包括事务的提交与回滚。
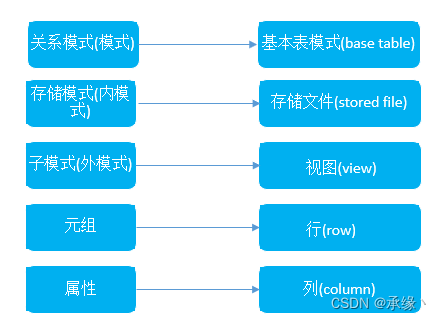
SQL数据库的数据体系结构基本上是三级结构,但使用的术语和传统关系模型术语不同。在SQL中:
备注:
人们为数据库设计了一个严谨的体系结构,数据库领域公认的标准结构是三级模式结构,它包括外模式、概念模式、内模式,有效地组织、管理数据,提高了数据库的逻辑独立性和物理独立性。用户级对应外模式,概念级对应概念模式,物理级对应内模式,使不同级别的用户对数据库形成不同的视图。所谓视图,就是指观察、认识和理解数据的范围、角度和方法,是数据库在用户“眼中"的反映,很显然,不同层次(级别)用户所“看到”的数据库是不相同的。
定义域
现在的 DBMS 具备简单的定义域功能,将数据库比作编程语言的话,现在的 DBMS 相当于只能使用系统定义好的类型,不能由用户自定义类型的编程语言。
主要是字符型、数值型等叫作标量类型的数据类型。因为它们对属性的取值范围有约束,所以尽管有局限性,但是标量类型也是定义域的一种。不能往声明为 INTEGER 型的列中插入 “abc” 这样的字符串。
我们还可以使用 CHECK 约束,执行比针对声明为标量类型的列进行的约束更为严格的约束。
例如:
CREATE TABLE CUSTOMER (
CU_SN CHAR(6) NOT NULL,
CU_NAME VARCHAR(12),
CU_AGE INT2 NULL CONSTRAINT CKC_CUSTOMER_AGE CHECK (CU_AGE > 0 and CU_AGE < 150), CU_GENDER CHAR(1) NULL CONSTRAINT CKC_CUSTOMER_GENDER CHECK (CU_GENDER IN ('U','F','M’))
);
备注:
标量类型(Scalar type)是相对复合类型(Compound type)来说的:标量类型只能有一个值,而复合类型可以包含多个值。复合类型是由标量类型构成的。
整数类型(int、short、long等)、字符类型(char、wchar_t等)、枚举类型(enum)、小数类型(float、double等)、布尔类型(bool)都属于标量类型,一份标量类型的数据只能包含一个值。
结构体(struct)、数组、字符串都属于复合类型,一份复合类型的数据可以包含多个标量类型的值,也可以包含其他复合类型的值。
关系简介
关系的定义
关系的定义可以用下面这个公式表示(关系用符号 R 表示,属性用符号 Ai 表示,属性的定义域用符号 Di 表示):
R ⊆ (D1×D2×D3 ··· ×Dn)
这个公式读作:关系 R 是定义域 D1, D2, …, Dn 的笛卡儿积的子集。
假设我们有三个属性:a1、a2、a3,然后我们描述一下它们的定义域(数学中函数的定义域,是属性的取值集合),属性 a1 可以取 1 种值,属性 a2 可以取 2 种值,属性 a3 可以取 3 种值。各属性对应的定义域分别叫作 d1、d2、d3,即:
d1 = { 1 }
d2 = { 男 , 女 }
d3 = { 红 , 绿 , 黄 }
使用这 3 个定义域生成关系时,最大的元组数是6,笛卡儿积(R1):
上面关系 R1 就是笛卡儿积。笛卡儿积是指“使用各个属性的定义域生成的组合数最多的集合”。因此通过上面 3 个定义域生成的所有关系Rn,都是这个笛卡儿积的子集。
例如除了 R1,我们还可以定义 R2,将R2 定义成由“R1 中的第 1 行和第 2 行”组成的关系。需要注意的是,元组个数为 0 的关系也是满足定义的(空集)。
关系的关系:

关系的封闭性
关系是集合的一种,他还有一个很重要的性质即“封闭性”(closure property):运算的输入和输出都是关系,换句话来说,就是“保证关系世界永远封闭”的性质。
SQL 中有各种各样的关系运算符。除了最初的投影、选择、并、差等基本运算符,SQL 后来又增加了许多非常方便的运算符,多亏了关系的封闭性,这些运算的输出才可以直接作为其他运算的输入。
因此,我们可以把各种操作组合起来使用,比如对选择后的集合求差等。这个性质也是子查询和视图等重要技术的基础。
关系的封闭性与 UNIX 中管道的概念很像,UNIX 中的文件也一样具有封闭性,可以作为各种命令的输入或者输出。
因此,可以像 cat sefon.txt | sort +1 | more 这样将命令组合在一起来编写脚本。这种写法让 UNIX 的脚本编程变得非常灵活。
在 UNIX 系统中,从设备到控制台,一切都可以当作“文件”来处理。因为从外观上来看,设备只不过是 /dev 目录下的一个普通文件而已。这是 UNIX 系统追求文件的封闭性的结果。表达 UNIX 设计理念的词语之一就是“泛文件主义”,即“一切皆文件主义” 。
在关系模型中,关系对关系运算符也是封闭的。
从 SQL 中 SELECT 子句的输入输出都是表”也能得到证明。SELECT 子句其实就是以表(关系)为参数,返回值为表(关系)的函数。有时 SELECT 子句查询不到一条数据,然而这时会返回“空集”,而不是不返回任何内容。
仿照 UNIX 起名字的话,关系数据库的这个特性可以叫作“泛关系主义”。
综上所述,UNIX 的文件通过对 Shell 命令封闭实现了非常灵活的功能。同样地,关系通过对关系运算封闭,使 SQL 具有了非常强大的表达能力。
关系模型简介
关系模型
关系是集合的一种,关系模型是以数学中的集合论为基础的。
关系模型的创始人E.F. Codd(1923—2003),他发表了两篇论文:
1969 《大型数据库中关系存储的可推导性、冗余与一致性》
1970 《大型共享数据库的关系模型》
上述两篇论文主要贡献可以归纳为以下三点:
1. 定义了关系运算(relational calculus)。
2. 定义了关系代数(relational algebra)。
3. 采用谓词逻辑作为数据库操作的基础。
关系数据库采用的数据模型是关系模型,其实反过来说可能更合适,即数据库采用了关系模型,因此才被称为关系数据库。
备注:
正式的关系模型术语 非正式的日常用语
关系(relation) 表(table)
元组(tuple) 行(row)或记录(record)
势(cardinality) 行数(number of rows)
属性(attribute) 列(column)或字段(field)
度(degree) 列数(number of columns)
定义域(domain) 列的取值集合(pool of legal values)
谓词逻辑
谓词逻辑作为数据库操作的基础:
谓词是一种特殊的函数,返回值都是 true、false 或者 unknown,谓词逻辑提供谓词是为了判断命题(可以理解成陈述句)的真假。
例如一张表中,一条数据name age为张三 35,我们可以认为这样一个命题:张三年龄是35,表通常可以认为是行的合集,从谓词的角度来看,也是命题的合集(陈述句的合集)。
平时使用的 WHERE 子句,其实也可以看成是由多个谓词组 合而成的新谓词。只有能让 WHERE 子句的返回值为真的命题,才能从表(命 题的合集)中查询到。“x = y”或“x BETWEEN y”等谓词可以取的参数是例如“9”或者“字符串”等。
运算基础
SQL的加减乘除
数学中会根据“对于什么运算是封闭的”这样的标准,将集合分为各种类型。这些对某种运算封闭的集合在数学上称为“代数结构”。其中,按照对四则运算是否封闭,可以把集合分为下面几类:
群(group):对加法和减法(或者乘法和除法)封闭。
环(ring):对加法、减法、乘法封闭。
域(filed):对加法、减法、乘法、除法封闭,即可以自由进行四则运算。
关于“群”的具体示例,简单的说例如整数集,因为任何两个整数之间进行加法或者减法运算,结果一定还是整数。整数集也是环,但却不是域,比如 1÷2 的结果是小数,不满足封闭性。
如果将整数集扩展成有理数集或者实数集的话,那么结果就满足域的条件了。这是因为,使用实数自由地进行四则运算后,运算结果还是实数。
SQL 中的集合运算符可以实现,关系支持加法(UNION)运算和减法(EXCEPT)运算,因此满足群的条件。关系还支持相当于乘法运算的 CROSS JOIN,所以也满足环的条件。最后一个除法,关系中没有除法运算符,但是他有除法运算的定义。因此,关系也满足域的条件。从满足运算相关特征的观点来看,关系可以理解为“能自由进行四则运算的集合”。
C.J. Date 和 Joe Celko 之所以非常重视除法运算,是因为一方面它的实用性高,另一方面他们深知只有定义了除法,关系才有资格成为域。
SQL的除法1
关系的除法实际上是一个关系的某些元素真包含另一个关系的某些元素的问题。
设关系 R 除以关系 S 的结果为关系 T ,则 T 包含所有在 R 中但不在 S 中的属性及其值,且 T 的元组与 S 的元组的所有组合都在 R 中。

R 与 S 中发生重叠的属性是 Y ,除数 S 中 S.y 的取值有 {q1, q2} ,再考虑被除数 R 中,R.y中包含 S.y 即 {q1, q2} 的元素有 {p1, p2} ,其中 p1 对应的 R.Y 真包含 {q1, q2} , p2 对应的 R.y 直接等于 {q1, q2}。
因此,R÷S的值就是关系T:

SQL的除法2
以下有两张表,欲求shopitems中商铺卖的产品包含items表中所有数据的店铺:

SQL的除法3
还是刚刚的两张表,只选择没有剩余商品的店铺(店铺1和店铺3中有窗帘,但是我们的items表中并没有窗帘,于是我们将上步骤的结果中的店铺1去掉):

三值逻辑
为了兼容 NULL,关系数据库选择了允许空值(unknown)的三值逻辑来代替标准的二值逻辑。
一般逻辑学中,命题只包含“真”和“假”这两个可能值。而三值逻辑除了这两个值,还增加了表示“未知”状态的第三个值。
NULL的危害
1、在指定 IS NULL、IS NOT NULL 的时候,不会用到索引,因而SQL 语句执行起来性能低下。
2、如果四则运算以及 SQL 函数的参数中包含 NULL,会引起“NULL的传播”:
1 + NULL = NULL
2 - NULL = NULL
3 * NULL = NULL
4 / NULL = NULL
NULL / 0 = NULL
3、在接收 SQL 查询结果的宿主语言中,NULL 的处理方法没有统一标准。
4、与一般列的值不同,NULL 是通过在数据行的某处加上多余的位(bit)来实现的, NULL 会使程序占据更多的存储空间,使得检索性能变差。
一行数据在磁盘上的存储格式应该是下面这样的:
假设有个表的5个字段:name address gender job school ,其中的gender是CHAR(1),其他的是VARCHAR(10~50不等)的字段类型,而除了第一个字段声明了NOT NULL的,其他4个字段都可能是NULL,则存储为:
变长字段长度列表 NULL值列表 头信息 column1=value1 column2=value2 ... columnN=valueN
具体这条数据“jack NULL m NULL xx_school”的存储为:
0x09 0x04 00000101 头信息 column1=value1 column2=value2 ... columnN=valueN
消除NULL
简单的几个消除 NULL 的方法:
(1) 首先分析能不能设置默认值。
(2) 仅在无论如何都无法设置默认值时允许使用 NULL,例如:
编号 :使用异常编号
名字 :使用“无名氏”
数值 :用 0 代替
日期 :用最大值或最小值代替,例如1900-01-01