文章目录
- ClickHouse 副本
- 支持副本的引擎
- 配置高可用副本
- 副本应用
- 1.副本表概述
- 2.创建副本表
- 3.写入模拟数据
- 4.副本验证
- 扩展 —— 在 Zookeeper 中查看副本表信息
ClickHouse 副本
ClickHouse 通过副本机制,可以将数据拷贝存储在不同的节点上。这样,如果一个节点发生故障,数据仍然可以从其他节点中获取,确保系统的可用性。
支持副本的引擎
在 ClickHouse 中,并不是所有的引擎都支持副本,而副本有专门的引擎,在官网中可以看到:
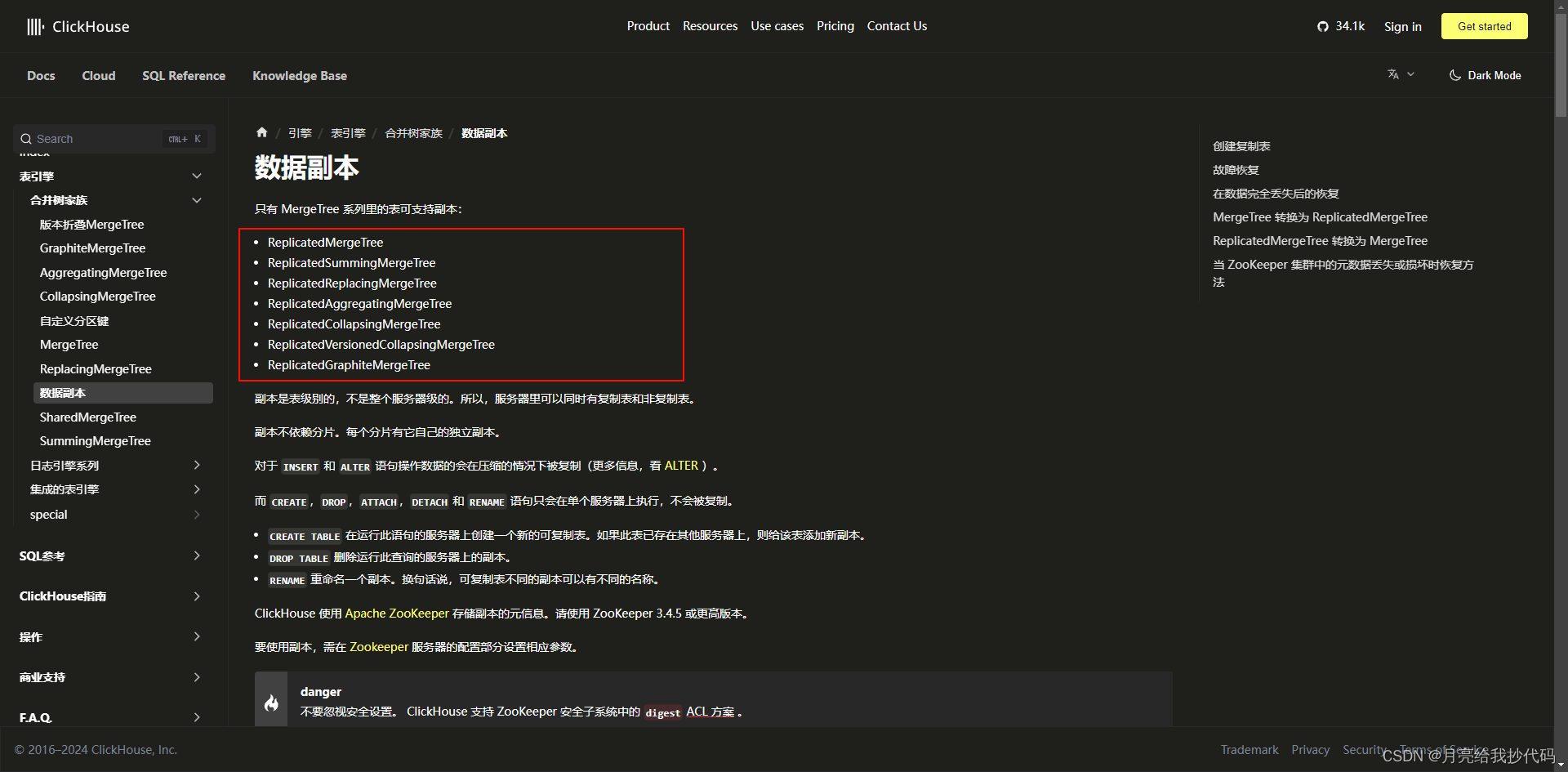
其中只有 MergeTree 家族中的引擎支持副本,并且需要在原引擎的基础上,加上副本前缀 Replicated。
还需要注意,副本都是表级别的,并不是相对于服务器而言,一般是哪个表需要创建副本,就对哪个表使用副本引擎。
注意,副本只能同步数据,并不能同步表结构,所以我们需要在副本同步时,先创建对应的表。
配置高可用副本
说到高可用,那必然是少不了 Zookeeper,数据协调和存储还得看 Zookeeper。
通过以引擎参数的形式提供 ZooKeeper 集群的名称和路径,ClickHouse 支持将副本的元信息存储在备用 ZooKeeper 集群上。也就是说,支持将不同数据表的元数据存储在不同的 ZooKeeper 集群上。
我这里配置两个副本,也就是说一共在三台机器上部署,一共有三份数据,充分保障 ClickHouse 中数据的安全、稳定性。
Zookeeper 和 ClickHouse 的搭建可以看我写的下面两篇文章:
-
HBase 分布式搭建(其中有Zookeeper集群部署的详细过程)
-
ClickHouse 单机安装及基础知识与 Spark 应用
在部署完 Zookeeper 分布式以及 ClickHouse 单机版(每台机器都要安装)后,就可以进行 ClickHouse 副本的配置了。
修改 ClickHouse 配置文件
在其中添加 Zookeeper 集群的信息,先修改一台机器的配置,然后再进行分发同步。
# 请先切换到 root 账户
su root
# 进入到 ClickHouse 的配置文件目录
cd /etc/clickhouse-server
# 修改配置默认的配置文件
vim config.xml
进入文本编辑器,输入 :/zookeeper 快速定位到:
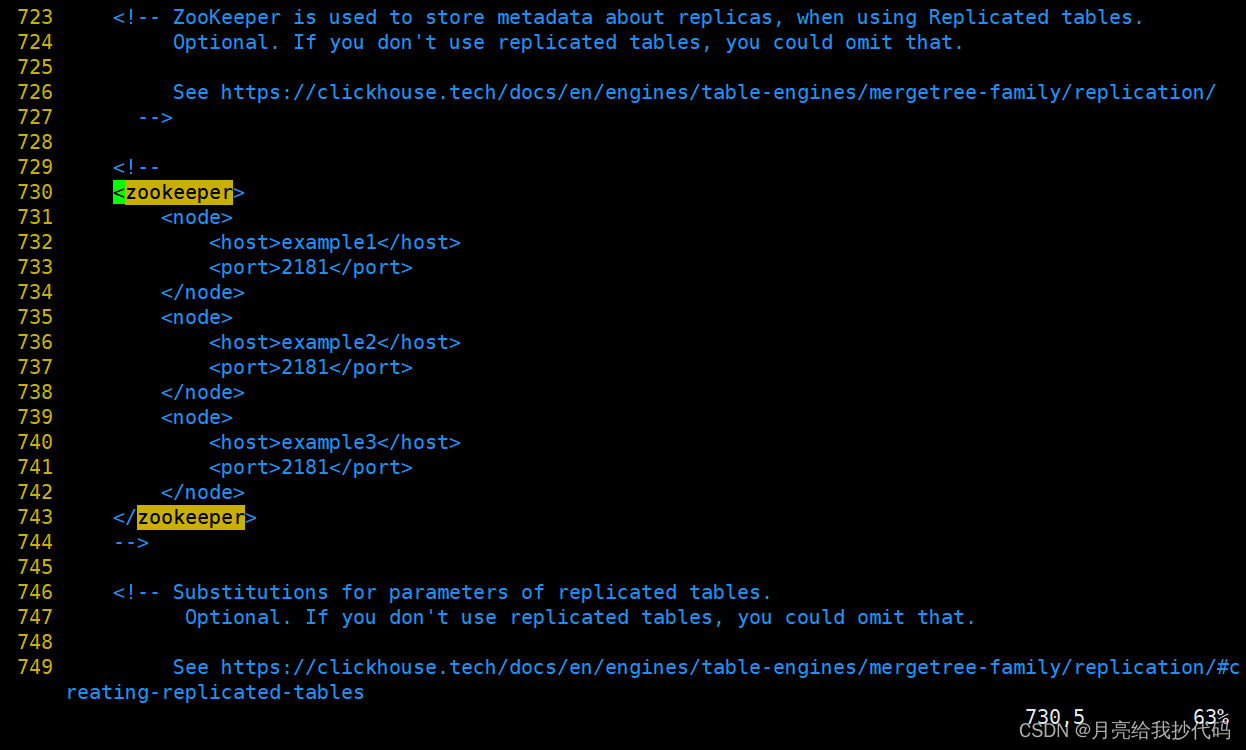
填写你的 Zookeeper 信息,如下所示:
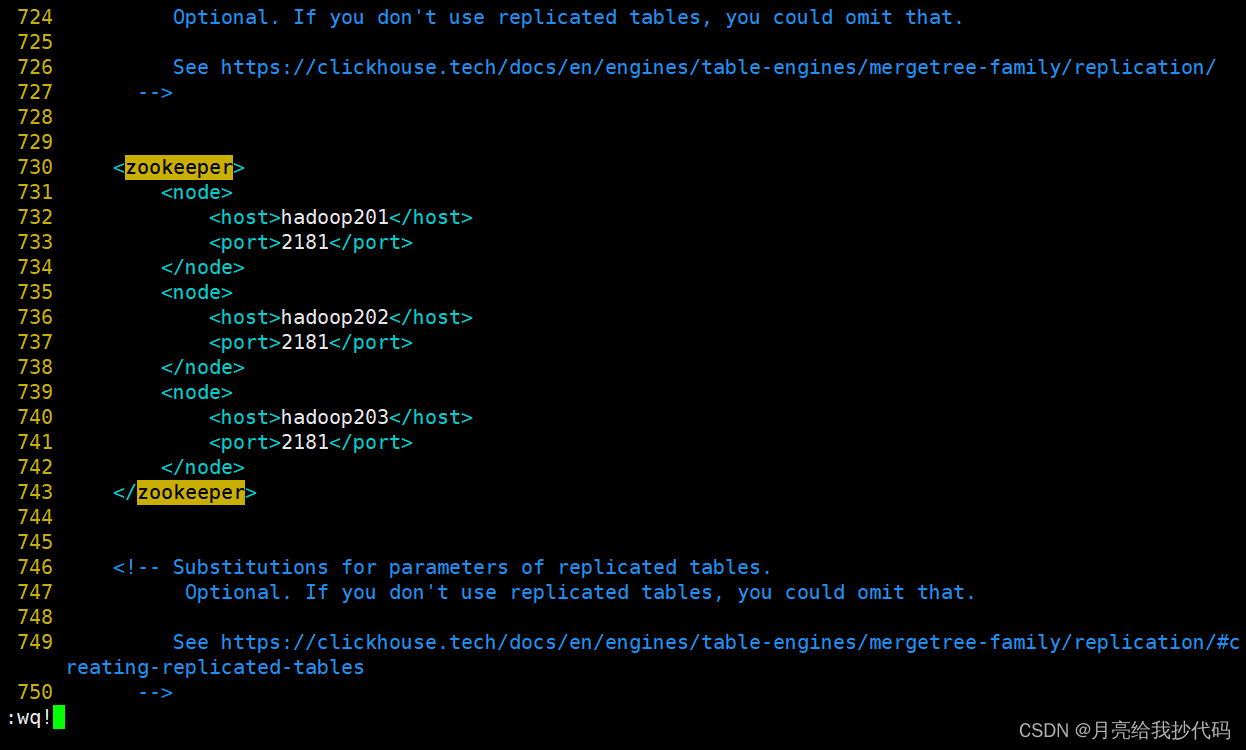
修改完成后,同步该文件到其它两台机器。分发完成后,重启每台机器的 Zookeeper、ClickHouse。
副本应用
1.副本表概述
官方给出的副本表创建示例:
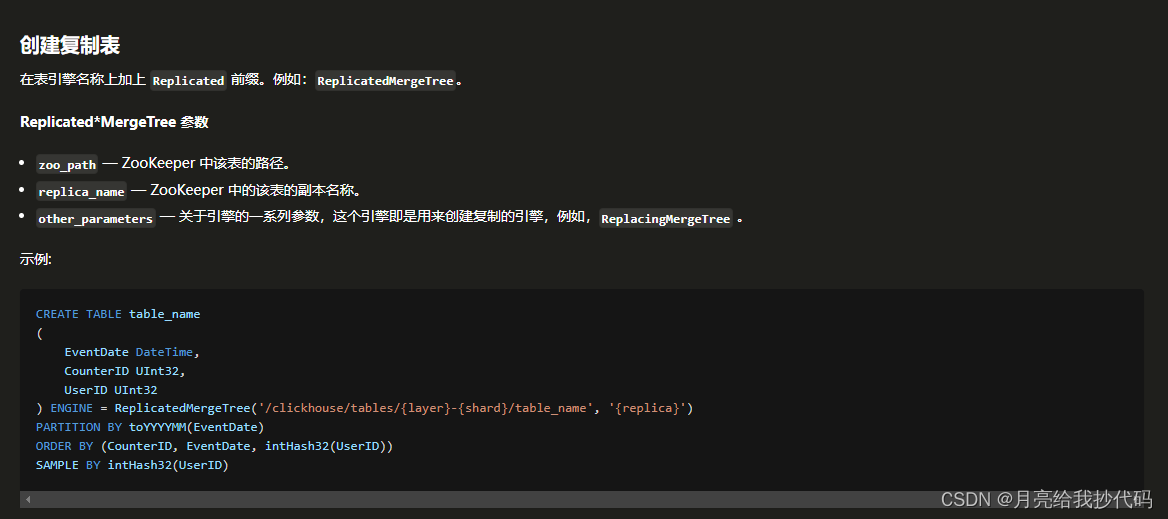
副本表示例 SQL:
CREATE TABLE table_name
(
EventDate DateTime,
CounterID UInt32,
UserID UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/table_name', '{replica}')
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID);
其中副本表引擎在创建时,需要传入两个参数:ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/table_name', '{replica}')
参数说明
-
参数一:指定在 ZooKeeper 中存储的路径,推荐模板:
/clickhouse/tables/{layer}-{shard}/{database}/{table},其中{layer}-{shard}表示分片标识信息,大多数情况下,只需要写入一个占位符。 -
参数二:ZooKeeper 中该表的副本名称,该值必须与其它机器不同!
在创建副本表时,它们可以存储在不同的库中,并不会影响副本的创建,只需要保证它们使用的是同一个 Zookeeper 路径即可。
2.创建副本表
除了副本名称外,其余都需要保持一致。
进入 ClickHouse
# 我没有配置账户与密码
clickhouse-client -m
在 机器1 中创建。
CREATE TABLE test_rp
(
EventDate DateTime DEFAULT now(),
CounterID UInt32,
UserID UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/test_rp', 'test_rp01')
PARTITION BY toYYYYMM(EventDate)
ORDER BY (EventDate);
在 机器2 中创建。
CREATE TABLE test_rp
(
EventDate DateTime DEFAULT now(),
CounterID UInt32,
UserID UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/test_rp', 'test_rp02')
PARTITION BY toYYYYMM(EventDate)
ORDER BY (EventDate);
在 机器3 中创建。
CREATE TABLE test_rp
(
EventDate DateTime DEFAULT now(),
CounterID UInt32,
UserID UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/test_rp', 'test_rp03')
PARTITION BY toYYYYMM(EventDate)
ORDER BY (EventDate);
3.写入模拟数据
往 机器1 中的表内插入一些模拟数据:
insert into test_rp (CounterID,UserID ) values (1,1001),(2,1002),(3,1003);
4.副本验证
数据插入完成后,分别在 机器1、机器2、机器3 上查询该表,检查副本是否创建成功。
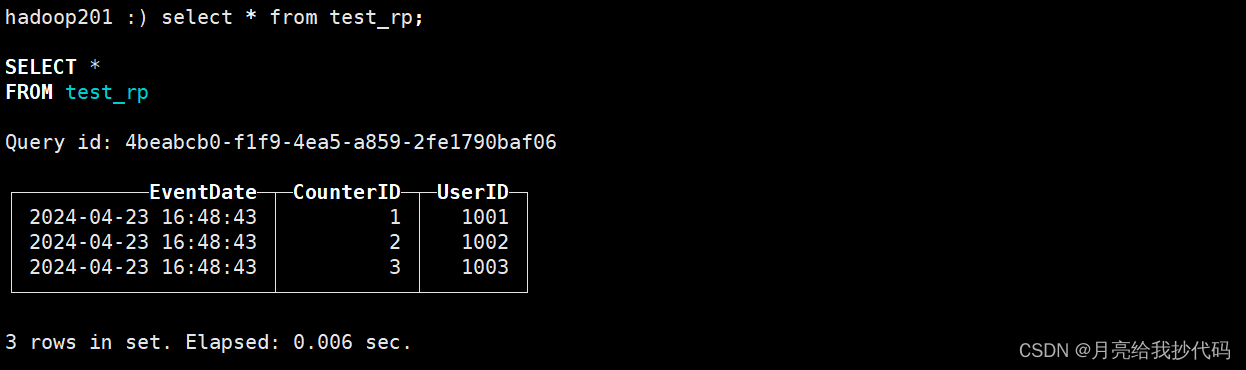
select * from test_rp;
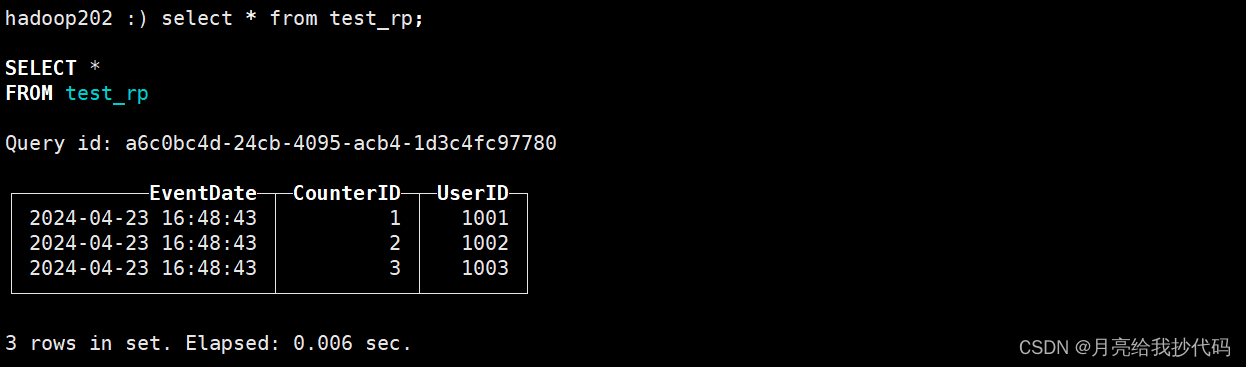
机器1 查询结果
我们数据是在 机器1 上写入的,所以它肯定有数据。
机器2 查询结果
副本同步成功。
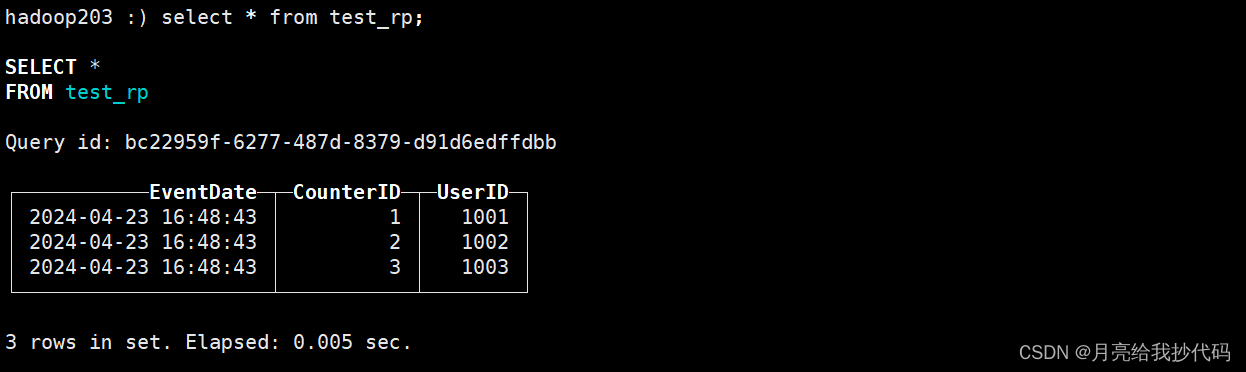
机器3 查询结果
副本同步成功。
各位也可以反过来测试,在其它机器上插入,然后在不同的机器上进行查询,我这里就不再进行演示了。
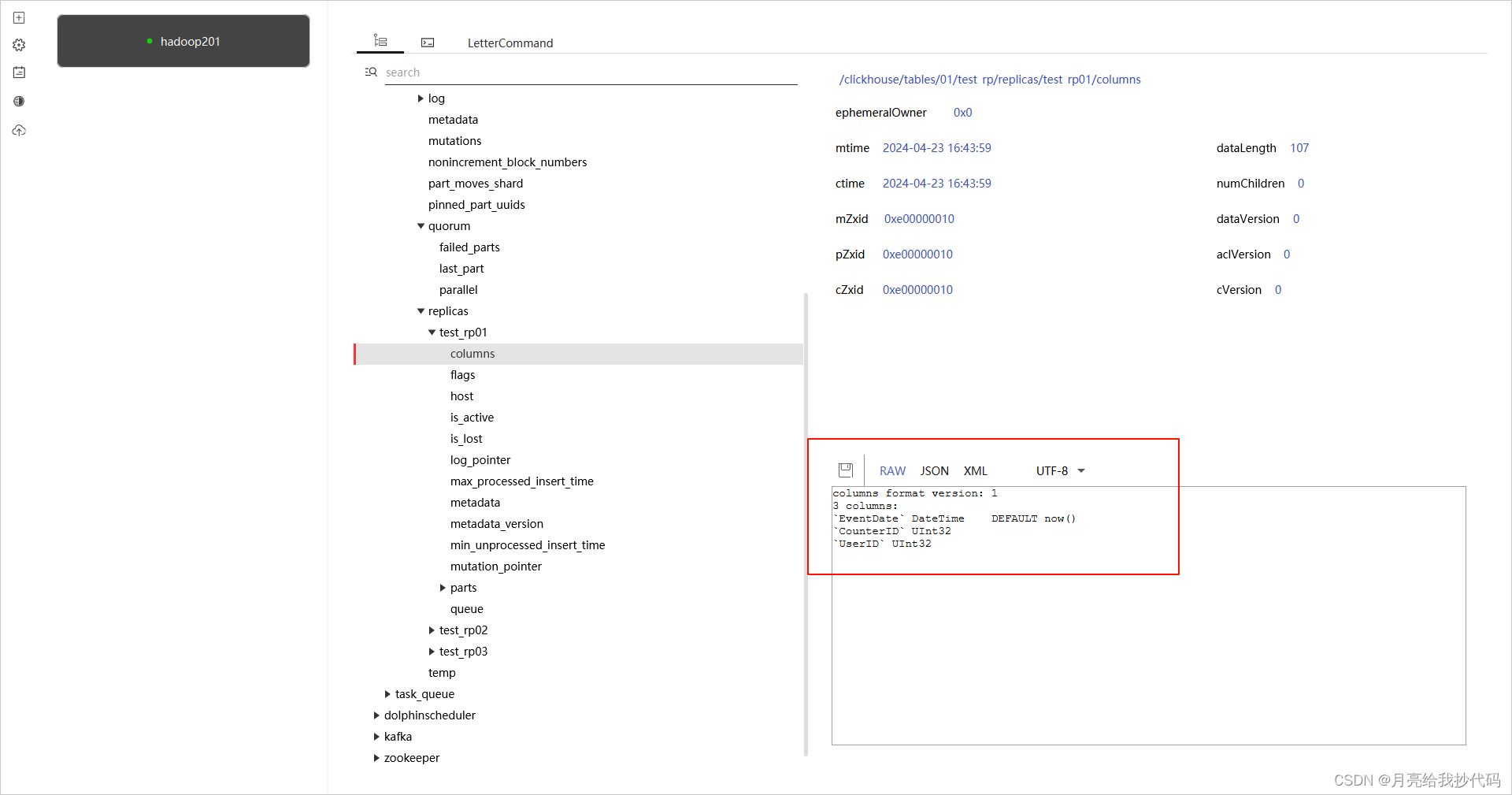
扩展 —— 在 Zookeeper 中查看副本表信息
如果你想要在 Zookeeper 中查看副本表的目录结构以及存储情况,那么你可以使用 Zookeeper 的可视化工具进行查看。当然,在命令行中查看也是可以的。
这里使用国内个人开发者设计的 PrettyZoo —— 颜值与功能双在线的 Zookeeper 可视化工具。
软件下载地址 —— PrettyZoo
解压后即可使用,单机左上角 + 号连接 Zookeeper:
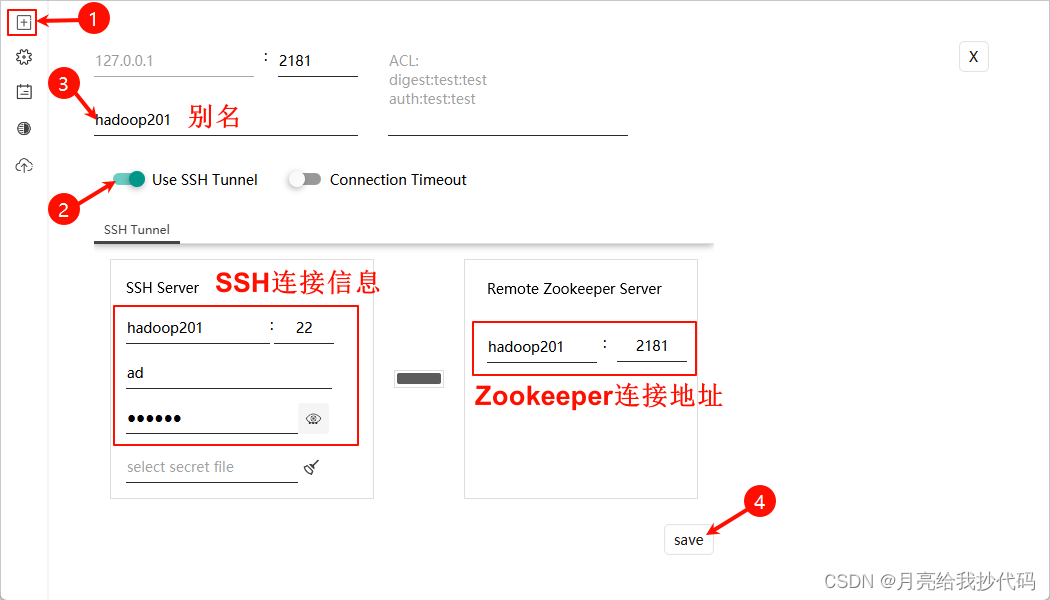
创建完成后,直接点击 connect 进行连接:
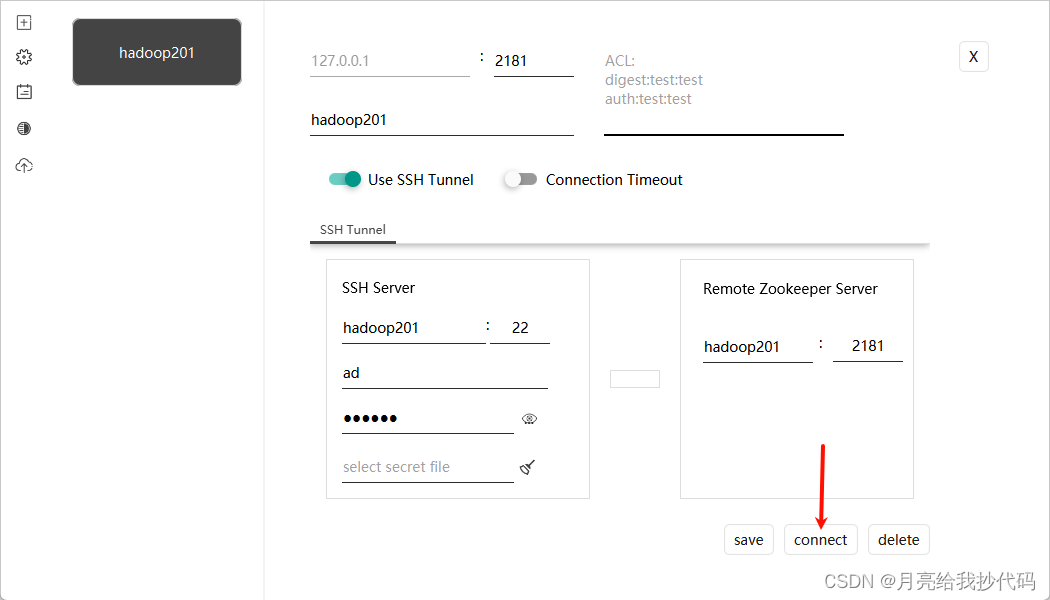
连接成功后,会自动进入 Zookeeper 目录结构界面:
查看我们创建的副本表的元数据信息:
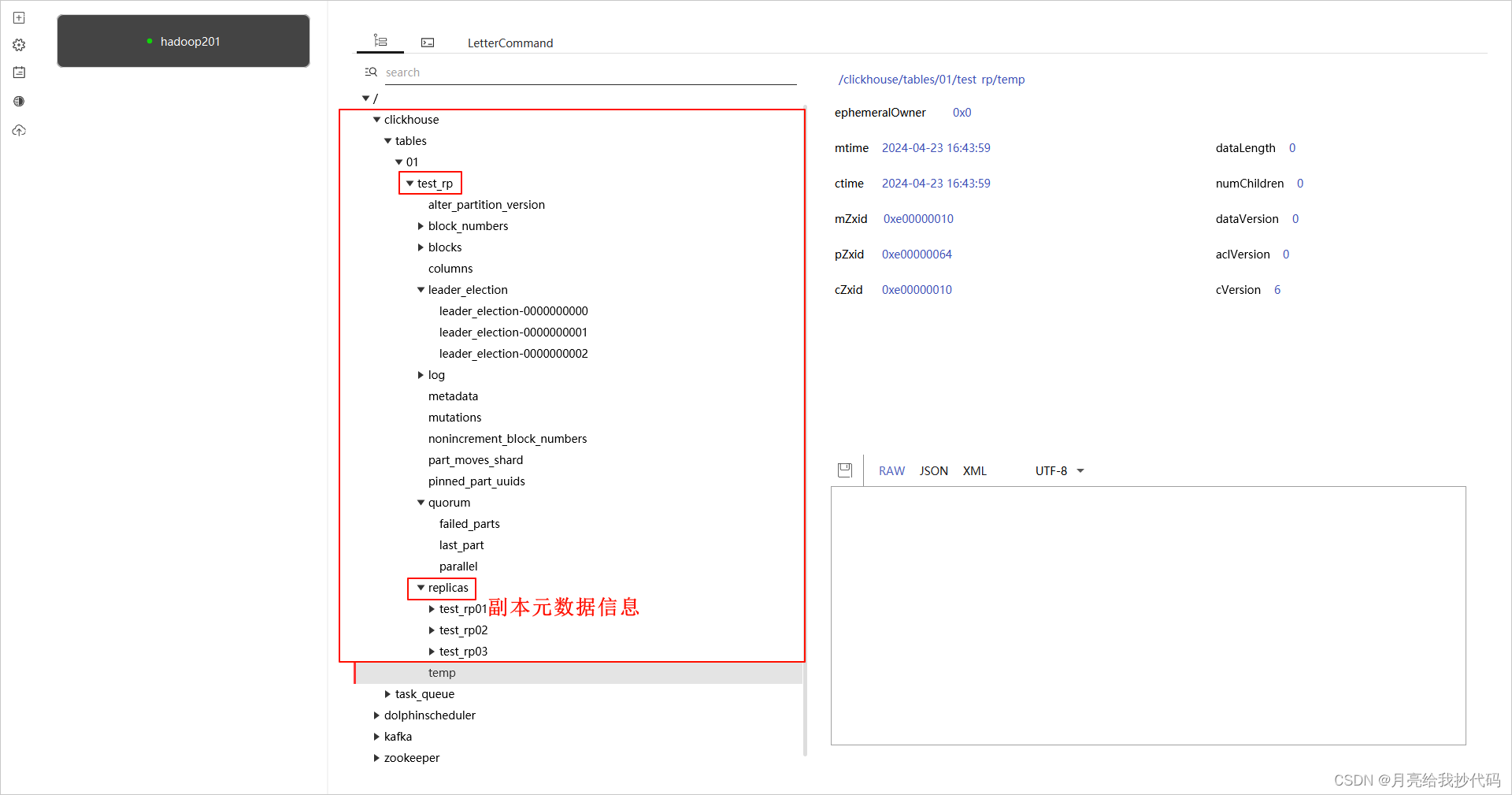
其中存储了副本表的各种元数据信息,大家感兴趣的话就自己下载玩玩吧,这里不过多介绍了。