ShardingSphere-JDBC读写分离快速入门
- 一、ShardingSphere-JDBC 读写分离
- 1.创建springboot程序
- 1.1 添加依赖
- 1.2 java代码
- 1.3 配置
- 2.测试
- 二、ShardingSphere-JDBC垂直分片
- 1.创建springboot程序
- 1.1 导入依赖
- 1.2 java代码
- 1.3 配置
- 2.测试
- 三、ShardingSphere-JDBC水平分片
- 1.创建springboot程序
- 1.1 导入依赖
- 1.2 java代码
- 1.3 配置
- 2.测试
前言:ShardingSphere-JDBC整合springBoot构建项目配置可以参考官方文档:
https://shardingsphere.apache.org/document/5.2.0/cn/user-manual/shardingsphere-jdbc/spring-boot-starter/
一、ShardingSphere-JDBC 读写分离
概念: ShardingSphere-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
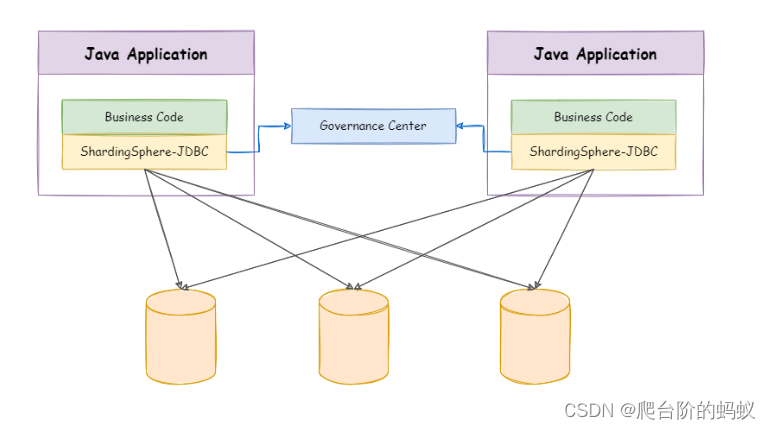
1.创建springboot程序
1.1 添加依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.1.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
1.2 java代码
@TableName("t_user")
@Data
public class User {
@TableId(type = IdType.AUTO)
private Long id;
private String uname;
}
@Mapper
public interface UserMapper extends BaseMapper<User> {
}
1.3 配置
配置前提:现有一主两从mysql集群。主从数据库同步已开启,现在有一个数据库db_user,有一张表t_user。
# 应用名称
spring.application.name=sharging-jdbc-demo
# 开发环境设置
spring.profiles.active=dev
# 内存模式
spring.shardingsphere.mode.type=Memory
# 配置真实数据源
spring.shardingsphere.datasource.names=master,slave1,slave2
# 配置第 1 个数据源
spring.shardingsphere.datasource.master.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.master.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.master.jdbc-url=jdbc:mysql://192.168.80.1:3306/db_user
spring.shardingsphere.datasource.master.username=root
spring.shardingsphere.datasource.master.password=123456
# 配置第 2 个数据源
spring.shardingsphere.datasource.slave1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.slave1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.slave1.jdbc-url=jdbc:mysql://192.168.80.2:3306/db_user
spring.shardingsphere.datasource.slave1.username=root
spring.shardingsphere.datasource.slave1.password=123456
# 配置第 3 个数据源
spring.shardingsphere.datasource.slave2.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.slave2.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.slave2.jdbc-url=jdbc:mysql://192.168.80.3:3306/db_user
spring.shardingsphere.datasource.slave2.username=root
spring.shardingsphere.datasource.slave2.password=123456
# 读写分离类型,如: Static,Dynamic
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.type=Static
# 写数据源名称
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.props.write-data-source-name=master
# 读数据源名称,多个从数据源用逗号分隔
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.props.read-data-source-names=slave1,slave2
# 负载均衡算法名称
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.load-balancer-name=alg_round
# 负载均衡算法配置
# 负载均衡算法类型
# 轮询
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_round.type=ROUND_ROBIN
# 随机
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_random.type=RANDOM
# 权重
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.type=WEIGHT
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.props.slave1=1
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.props.slave2=2
# 打印SQl
spring.shardingsphere.props.sql-show=true
2.测试
测试结果: 写数据时数据插入master库;读数据时根据配置的负载均衡算法数据从slave节点读取
@SpringBootTest
class ReadwriteTest {
@Autowired
private UserMapper userMapper;
/**
* 写入数据的测试
*/
@Test
public void testInsert(){
User user = new User();
user.setUname("张三丰");
userMapper.insert(user);
}
/**
* 读数据测试
*/
@Test
public void testSelectAll(){
List<User> users = userMapper.selectList(null);
List<User> users = userMapper.selectList(null);//执行第二次测试负载均衡
users.forEach(System.out::println);
}
}
注意: 为了保证主从库间的事务一致性,避免跨服务的分布式事务,ShardingSphere-JDBC的主从模型中,事务中的数据读写均用主库。
- 不添加@Transactional:insert对主库操作,select对从库操作
- 添加@Transactional:则insert和select均对主库操作
二、ShardingSphere-JDBC垂直分片
1.创建springboot程序
1.1 导入依赖
依赖同上面的配置一样
1.2 java代码
@TableName("t_order")
@Data
public class Order {
@TableId(type = IdType.AUTO)
private Long id;
private String orderNo;
private Long userId;
private BigDecimal amount;
}
@Mapper
public interface OrderMapper extends BaseMapper<Order> {
}
@TableName("t_user")
@Data
public class User {
@TableId(type = IdType.AUTO)
private Long id;
private String uname;
}
@Mapper
public interface UserMapper extends BaseMapper<User> {
}
1.3 配置
配置前提: 假设现在微服务进行了拆分,有user-service、order-service服务,微服务架构下,不同的服务有自己的数据库。所以现在有两个数据库db_user、db_order。db_user数据库有一张表t_user,db_order数据库有一张表t_order。
# 应用名称
spring.application.name=sharding-jdbc-demo
# 环境设置
spring.profiles.active=dev
# 配置真实数据源
spring.shardingsphere.datasource.names=user-service,order-service
# 配置第 1 个数据源
spring.shardingsphere.datasource.user-service.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.user-service.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.user-service.jdbc-url=jdbc:mysql://192.168.80.4:3306/db_user
spring.shardingsphere.datasource.user-service.username=root
spring.shardingsphere.datasource.user-service.password=123456
# 配置第 2 个数据源
spring.shardingsphere.datasource.server-order.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.order-service.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.order-service.jdbc-url=jdbc:mysql://192.168.80.5:3306/db_order
spring.shardingsphere.datasource.order-service.username=root
spring.shardingsphere.datasource.order-service.password=123456
# 标准分片表配置(数据节点)
# spring.shardingsphere.rules.sharding.tables.<table-name>.actual-data-nodes=值
# 值由数据源名 + 表名组成,以小数点分隔。
# <table-name>:逻辑表名
spring.shardingsphere.rules.sharding.tables.t_user.actual-data-nodes=user-service.t_user
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=order-service.t_order
# 打印SQL
spring.shardingsphere.props.sql-show=true
2.测试
测试结论: :查询t_user数据从user-service数据库查询,查询t_order数据从order-service数据库查询
@SpringBootTest
public class ShardingTest {
@Autowired
private UserMapper userMapper;
@Autowired
private OrderMapper orderMapper;
/**
* 垂直分片:插入数据测试
*/
@Test
public void testInsertOrderAndUser(){
User user = new User();
user.setUname("强哥");
userMapper.insert(user);
Order order = new Order();
order.setOrderNo("ATGUIGU001");
order.setUserId(user.getId());
order.setAmount(new BigDecimal(100));
orderMapper.insert(order);
}
/**
* 垂直分片:查询数据测试
*/
@Test
public void testSelectFromOrderAndUser(){
User user = userMapper.selectById(1L);
Order order = orderMapper.selectById(1L);
}
}
三、ShardingSphere-JDBC水平分片
1.创建springboot程序
1.1 导入依赖
依赖同上面的配置一样
1.2 java代码
@TableName("t_order")
@Data
public class Order {
@TableId(type = IdType.AUTO)
private Long id;
private String orderNo;
private Long userId;
private BigDecimal amount;
}
@Mapper
public interface OrderMapper extends BaseMapper<Order> {
}
@TableName("t_user")
@Data
public class User {
@TableId(type = IdType.AUTO)
private Long id;
private String uname;
}
@Mapper
public interface UserMapper extends BaseMapper<User> {
}
1.3 配置
配置前提: 假设现在订单量过大,我们将订单库再增加一个。即一个db_user数据库,两个db_order数据库
#========================基本配置
# 应用名称
spring.application.name=sharging-jdbc-demo
# 开发环境设置
spring.profiles.active=dev
# 内存模式
spring.shardingsphere.mode.type=Memory
# 打印SQl
spring.shardingsphere.props.sql-show=true
#========================数据源配置
# 配置真实数据源
spring.shardingsphere.datasource.names=user-service,order-service0,order-service1
# 配置第 1 个数据源
spring.shardingsphere.datasource.user-service.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.user-service.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.user-service.jdbc-url=jdbc:mysql://192.168.80.6:3306/db_user
spring.shardingsphere.datasource.user-service.username=root
spring.shardingsphere.datasource.user-service.password=123456
# 配置第 2 个数据源
spring.shardingsphere.datasource.order-service0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.order-service0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.order-service0.jdbc-url=jdbc:mysql://192.168.80.7:3306/db_order
spring.shardingsphere.datasource.order-service0.username=root
spring.shardingsphere.datasource.order-service0.password=123456
# 配置第 3 个数据源
spring.shardingsphere.datasource.order-service1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.order-service1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.order-service1.jdbc-url=jdbc:mysql://192.168.80.8:3306/db_order
spring.shardingsphere.datasource.order-service1.username=root
spring.shardingsphere.datasource.order-service1.password=123456
#------------------------标准分片表配置(数据节点配置)
# 由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持 inline 表达式。
# 缺省表示使用已知数据源与逻辑表名称生成数据节点,用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况
spring.shardingsphere.rules.sharding.tables.t_user.actual-data-nodes=user-service.t_user
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=order-service$->{0..1}.t_order$->{0..1}
#------------------------基于user_id进行分库基于order_no进行分表
#------------------------分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一
# 用于单分片键的标准分片场景
# 分片列名称
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-column=user_id
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=alg_mod
#------------------------分表策略
# 用于单分片键的标准分片场景
# 分片列名称
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-column=order_no
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name=alg_hash_mod
#------------------------分片算法配置
# 行表达式分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_inline_userid.type=INLINE
# 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_inline_userid.props.algorithm-expression=order-service$->{user_id % 2}
# 取模分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_mod.type=MOD
# 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_mod.props.sharding-count=2
# 哈希取模分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_hash_mod.type=HASH_MOD
# 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_hash_mod.props.sharding-count=2
#------------------------分布式序列策略配置
# 分布式序列列名称
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.column=id
# 分布式序列算法名称
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.key-generator-name=alg_snowflake
#------------------------分布式序列算法配置
# 分布式序列算法类型
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=SNOWFLAKE
2.测试
测试结论:
1.数据插入:基于user_id进行分库user_id为奇数插入order-service1,user_id为偶数插入order-service0, 基于order_no进行分表也是同样逻辑。
2.数据查询:我们只需要操作t_order表,ShardingSphere-JDBC会自动从两个库的表中查询结果合并在一起
/**
* 水平分片:分表插入数据测试
*/
@Test
public void testInsertOrderTableStrategy(){
for (long i = 1; i < 5; i++) {
Order order = new Order();
order.setOrderNo("order" + i);
order.setUserId(1L);
order.setAmount(new BigDecimal(100));
orderMapper.insert(order);
}
for (long i = 5; i < 9; i++) {
Order order = new Order();
order.setOrderNo("order" + i);
order.setUserId(2L);
order.setAmount(new BigDecimal(100));
orderMapper.insert(order);
}
}
/**
* 水平分片:查询所有记录
* 查询了两个数据源,每个数据源中使用UNION ALL连接两个表
*/
@Test
public void testShardingSelectAll(){
List<Order> orders = orderMapper.selectList(null);
orders.forEach(System.out::println);
}
/**
* 水平分片:根据user_id查询记录
* 查询了一个数据源,每个数据源中使用UNION ALL连接两个表
*/
@Test
public void testShardingSelectByUserId(){
QueryWrapper<Order> orderQueryWrapper = new QueryWrapper<>();
orderQueryWrapper.eq("user_id", 1L);
List<Order> orders = orderMapper.selectList(orderQueryWrapper);
orders.forEach(System.out::println);
}