之前在《TDengine高可用探讨》提到过,TDengine通过多副本和多节点能够保证数据库集群的高可用。单对于应用端来说,如果使用原生连接方式(taosc)还好,当一个节点下线,应用不会受到影响;但如果使用了Restful/Websocket连接方式,而前端又没有部署负载均衡,那么必须调整应用程序,才能继续访问数据库。
对此我们可以采用TDengine+Keepalived 架构,使用VIP保证在没有负载均衡的情况下数据库集群可用性。
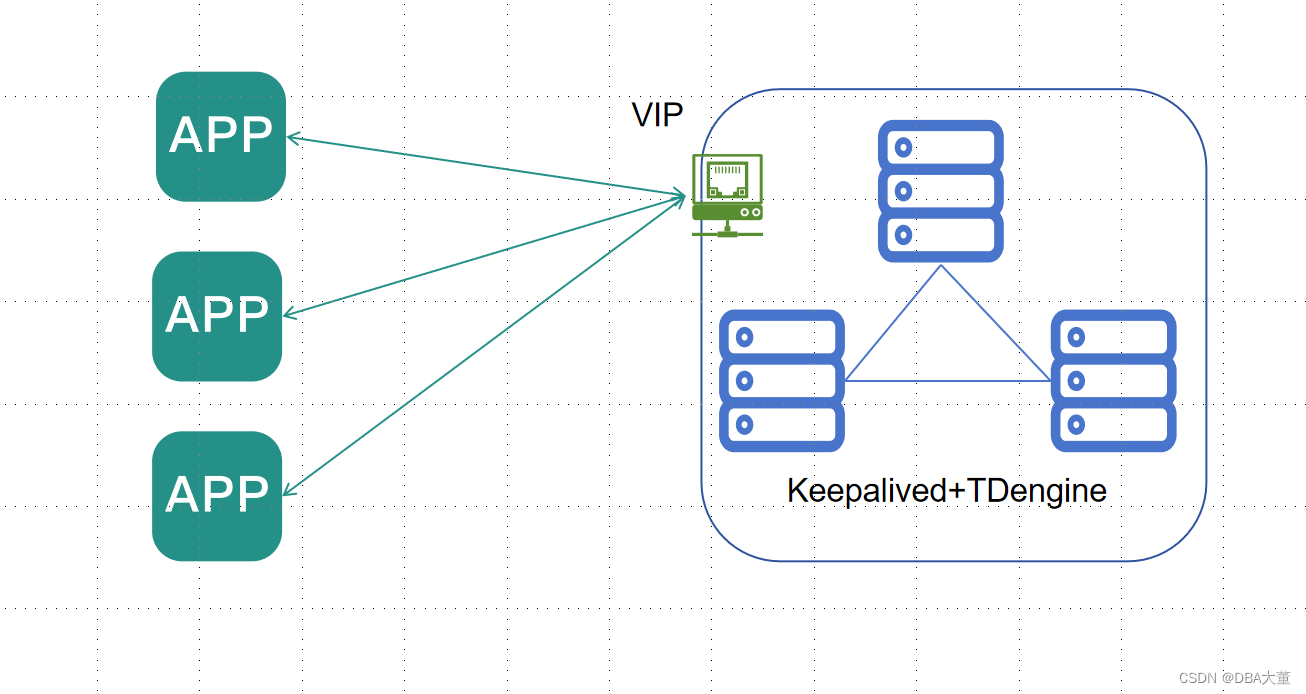
相较于部署负载均衡,该方案不需要再单独部署负载均衡服务器,架构更简单,避免了负载均衡的单点故障。但因不具备负载均衡的能力,访问压力会集中在一个节点上。
因此以上方案适用于负载不好的业务场景。
keepalived 安装配置
安装
yum install -y keepalived
配置 keepalived
/etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id c3-60 ##节点标识,使用主机名即可
}
vrrp_script chk_adapter {
script "/etc/taos/adapter_check.sh" ##检查脚本
interval 2
weight -50
}
vrrp_instance VI_1 {
state BACKUP ##由于采用了nopreempt,所有节点配置为BACKUP
interface ens192 ## 网卡
virtual_router_id 51
priority 100 ## 优先级
nopreempt ##非抢占模式,防止故障节点恢复后VIP迁移
advert_int 1 ##通告时间
authentication {
auth_type PASS
auth_pass 1111
}
track_script {
chk_adapter
}
virtual_ipaddress {
192.168.3.59
}
}
检测脚本
/etc/taos/adapter_check.sh
#!/bin/sh
acheck()
{
curl http://127.0.0.1:6041/-/ping
if [ $? -ne 0 ]
then
systemctl stop keepalived
return 1
else
return 0
fi
}
acheck
以上脚本会检查taosadapter组件的可用性,当taosadapter不可用时,会停止keepalived服务,从而引发VIP的漂移。
测试
- 使用客户端连续查询
- 停止主节点taosadapter服务
- 检查客户端连接状态
- 检查主节点keepalived 服务状态

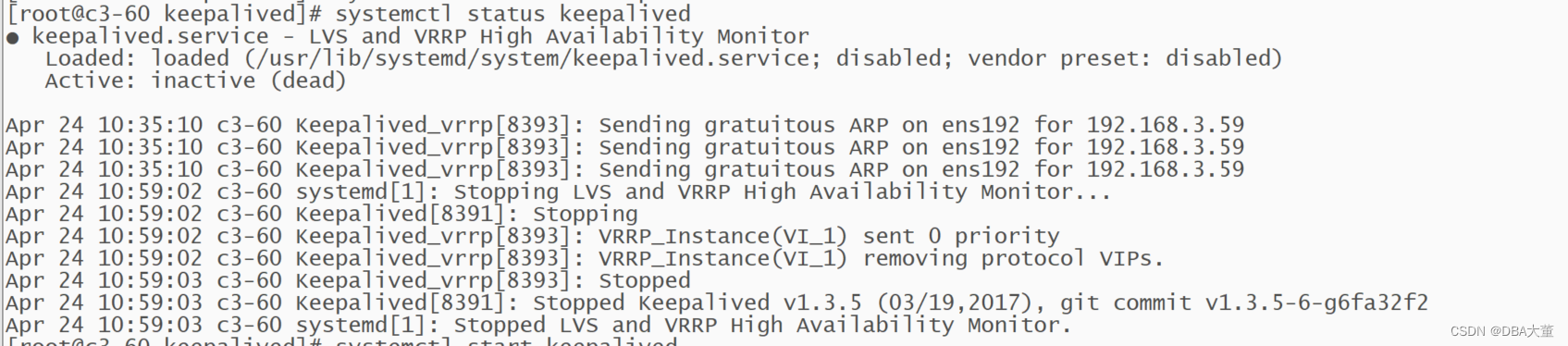
keepalived服务被停止。因为我的服务器没有启用ntp,因此时间存在差异。
优化
以上方案存在一个问题,即一个节点taosadapter出现故障后,keepalived服务会被中止。等故障恢复后,需要手动启动keepalived服务进行恢复。
为了keepalived能做到自动恢复,需要做如下优化:
-
修改检查脚本
将systemctl stop keepalived修改为pkill keepalived,即用杀掉进程替换中止服务。 -
修改keepalived服务脚本
添加如下内容,让服务异常中止后,每隔30s自动重试启动。
Restart=always
StartLimitInterval=0
RestartSec=30