Linux篇
Linux中常见命令:Linux常见命令
1.free命令-查看内存状态
free命令用于显示内存状态,它可以提供关于系统内存使用情况的详细信息。这个命令会显示出内存的使用情况,包括实体内存、虚拟的交换文件内存、共享内存区段,以及系统核心使用的缓冲区等。

其中,参数包括但不限于:
-b:以Byte为单位显示内存使用情况。-k:以KB为单位显示内存使用情况(这是默认的单位)。-m:以MB为单位显示内存使用情况。-g:以GB为单位显示内存使用情况。-o:不显示缓冲区调节列。-s <间隔秒数>:持续观察内存使用状况。-t:显示内存总和列。-V:显示版本信息。
- 内存使用情况:这部分显示了总的内存量、已使用的内存量、空闲的内存量、共享的内存量、缓冲区内存量和缓存内存量。
- 交换空间使用情况:这部分显示了交换空间的总量、已使用的交换空间量、空闲的交换空间量。
补:交换空间的概念:当物理内存(RAM)不够用的时候,将硬盘中的一些空间作为交换空间,系统可以将部分数据从物理内存转移到交换空间中,以便释放RAM资源给其他应用程序使用。这个过程称为交换(swapping)。交换空间可以提高系统的性能,因为它允许系统在物理内存紧张时继续运行。
在内存使用情况的输出中,total表示总的内存量,used表示已使用的内存量,free表示空闲的内存量,shared表示共享的内存量,buffers表示缓冲区内存量,cached表示缓存内存量。
补:cpu (cache) 内存 (buffer) 硬盘
1.cache是介于cpu和内存之间的,用于cpu和内存之间缓存数据的。
cache:L1、L2。最常见的是L1cache和L2cache。L1cache一般是存在cpu的芯片里面,速度是最快的。L2cache是存在主板里面,是作为cpu和内存之间数据缓存的空间。当cpu和内存有数据交换时,先把数据存到cache中,cpu直接区cache里面取。
2.buffer是介于内存和硬盘之间的缓存
Linux中有两种设备:字符设备(如键盘)和块设备(硬盘),操作系统可以从这两种设备中获取数据。内存和硬盘交换数据的时候通过一个缓冲区buffer。
在交换空间使用情况的输出中,total表示交换空间的总量,used表示已使用的交换空间量,free表示空闲的交换空间量。
2.top命令-查看资源占用情况
在Linux系统中,top命令是一个非常实用的性能分析工具,它能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。top命令提供了一个动态显示的过程,即可以通过用户按键来不断刷新当前状态。如果在前台执行该命令,它将独占前台,直到用户终止该程序为止。
其中,参数包括但不限于:
-b:批处理模式,直接将结果输出到文件。-c:显示完整的命令行而不截断。-I:忽略失效进程。-s:保密模式,不显示敏感信息。-S:累积模式,显示进程的CPU使用时间。-i:不显示闲置(idle)或无用的进程。-n:设置更新次数后自动退出。-d:设置每两次屏幕信息刷新之间的时间间隔。
显示信息
top命令的输出包括以下几个部分:
- 系统状态:显示当前时间、系统运行时间、登录用户数量、平均负载等信息。
- CPU使用情况:显示用户空间、内核空间、改变过优先级的进程、空闲CPU、IO等待、硬中断和软中断占用的CPU百分比。
- 内存使用情况:显示物理内存总量、已使用内存、空闲内存、缓存内存等。
- 交换空间使用情况:显示交换空间的总量、已使用的交换空间、空闲的交换空间等。
- 进程信息:显示进程ID、进程所有者、进程优先级、nice值、虚拟内存使用量、常驻内存使用量、共享内存使用量、CPU使用率、内存使用率、进程启动后的CPU时间总计等。
3.vmstat命令
vmstat命令是Linux系统中用于监控系统资源使用情况的工具,它可以展示系统的CPU使用率、内存使用情况、虚拟内存交换情况以及I/O读写情况。vmstat命令提供了对系统整体性能的快照,帮助系统管理员了解系统的实时状态。

注:这里 vmstat 1 100 代表每秒打印一条数据,共打印100条
vmstat命令的输出结果包括多个部分,每个部分代表了不同的系统资源使用情况:
- 进程信息(procs):显示当前运行队列中线程的数目(r)和等待IO的进程数量(b)。
- 内存信息(memory):显示虚拟内存已使用的大小(swpd)、空闲的物理内存大小(free)、用作缓冲的内存大小(buff)、用作缓存的内存大小(cache)、每秒从交换区写到内存的大小(si)、每秒写入交换区的内存大小(so)。
- I/O信息(io):显示每秒从磁盘读入虚拟内存的大小(bi)、每秒虚拟内存写入磁盘的大小(bo)、每秒CPU的中断次数(in)、每秒上下文切换次数(cs)。
- CPU使用情况(cpu):显示用户进程执行时间(us)、系统进程执行时间(sy)、空闲时间(id)和等待IO的时间(wa)。
3.Linux中查看文件内容的命令
1. more指令 —— 分页显示文件内容
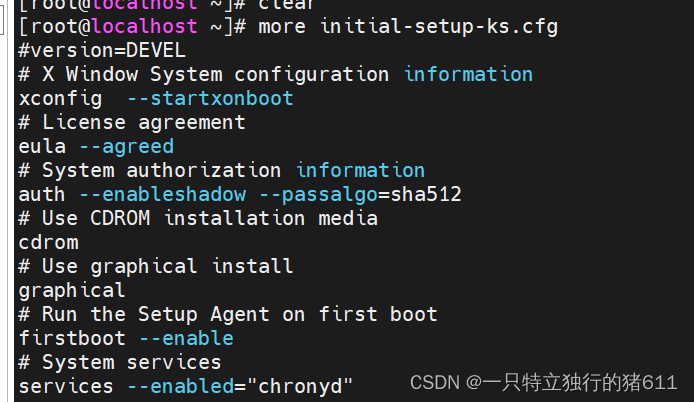
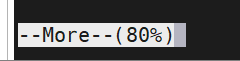
注:左下角会显示当前已经阅读了所有内容的百分之几。
more指令会以一页一页的形式显示文件内容,按空白键(space)显示下一页内容,按Enter键会显示下一行内容,按 b 键就会往回(back)一页显示,其基本用法如下:
more file1 查看文件file1的文件内容;
more -num file2 查看文件file2的内容,一次显示num行;
more +num file3 查看文件file3的内容,从第num行开始显示;
2. less指令 —— 可以向前或向后查看文件内容
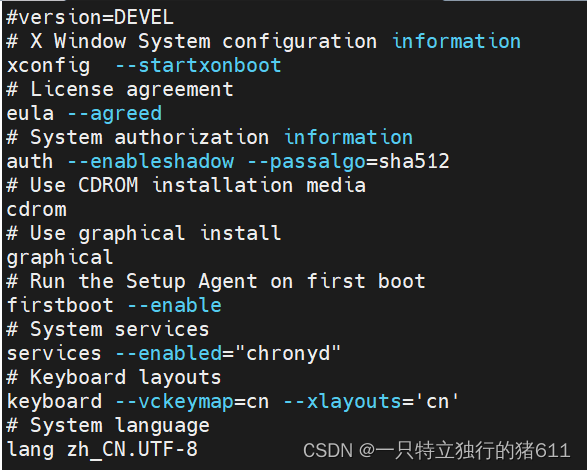
注:less查出来的文件内容,可以通过鼠标滚轮往前看或者往后看!
less指令查看文件内容时可以向前或向后随意查看内容;
less指令的基本用法为:
less file1 查看文件file1的内容;
less -m file2 查看文件file2的内容,并在屏幕底部显示已显示内容的百分比;
less -N file2 查看文件file3的内容,并显示每行的行号;
按空格键显示下一屏的内容,按回车键显示下一行的内容;
按 U 向前滚动半页,按 Y 向前滚动一行;
按[PageDown]向下翻动一页,按[PageUp]向上翻动一页;
按 Q 退出less命令;
3. head指令 —— 查看文件开头的内容
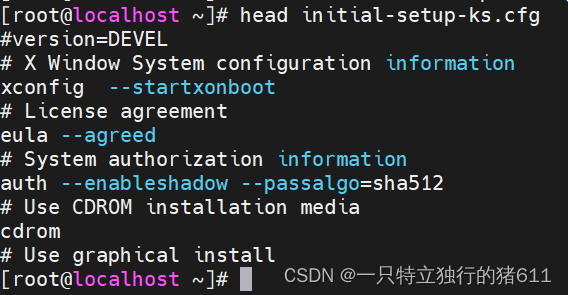
head指令用于显示文件开头的内容,默认情况下,只显示文件的头10行内容;
head指令的基本用法:
head -n <行数> filename 显示文件内容的前n行;
例如:head -n 5 file1 显示文件file1的前5行内容
head -c <字节> filename 显示文件内容的前n个字节;
例如:head -c 20 file2 显示文件file2的前20个字节内容
4. tail指令 —— 显示文件尾部的内容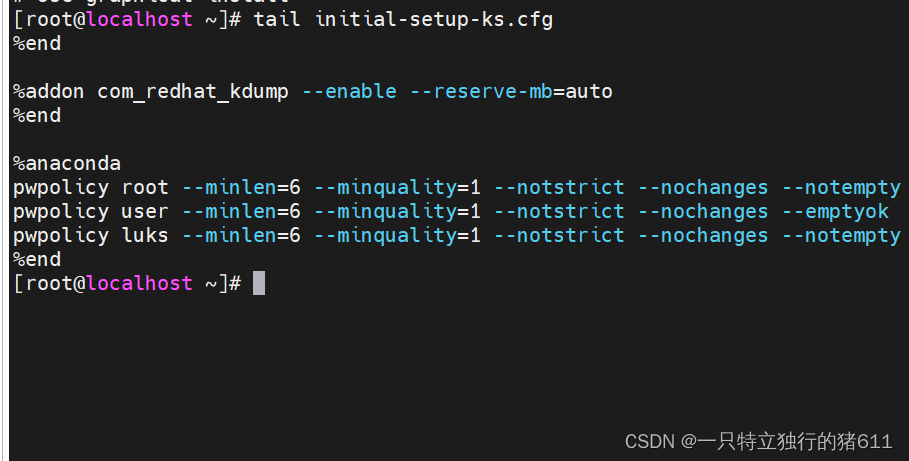
tail指令用于显示文件尾部的内容,默认情况下只显示指定文件的末尾10行;
tail指令的基本用法:
tail file1 显示文件file1的尾部10行内容;
tail file1 -f 动态显示文件file1的尾部10行内容;文件如果一直在写入数据,最新写入的数据也会被同步查出来。
tail -n <行数> filename 显示文件尾部的n行内容;
例如:tail -n 5 file1 显示文件file1的末尾5行内容
tail -c <字节数> filename 显示文件尾部的n个字节内容;
例如:tail -c 20 file2 显示文件file2的末尾20个字节
5. cat指令 —— 显示文件内容
使用cat命令时,如果文件较小还勉强能用,如果文件内容过多,则只会显示最后一屏的内容;

cat指令的基本用法:
cat file1 用于查看文件名为file1的文件内容;
cat -n file2 查看文件名为file2的文件内容,并从1开始对所有输出的行数(包括空行)进行编号;
cat -b file3 查看文件名为file3的文件内容,并从1开始对所有的非空行进行编号;
4.crontab命令-设置定时任务
在Linux中设置定时任务通常是通过crond服务(表现就是一个一直执行的守护进程,这个守护进程会一直监视定时任务列表有没有指定定时任务)来实现的。crond服务允许用户在指定的日期和时间运行脚本和命令。如果有定时任务,就会到指定时间执行,如果没有,守护进程也会一直运行。要设置定时任务,你需要编辑当前用户的crontab文件,或者在/etc/crontab文件中添加系统级别的任务。
使用场景:日志分析、定时数据备份等周期性工作。
简单使用步骤:
1.创建一个任务 (可以是脚本或者命令)
2.通过 crontab - e 命令把定时任务加入crontab服务队列中
3.通过 crontab - l 命令查看队列中是否有加入的定时任务(确认成功加入任务)
例:1.![]() 假设我们已经写了一个脚本“time.sh”
假设我们已经写了一个脚本“time.sh”
2.执行 crontab -e 命令,就会进入:
任务执行的格式: 时间 + 任务路径
时间 + 任务路径
注:最后一个代表每天每小时每分钟执行1次。
写入以后,通过" :wq! " 保存并退出编辑。
3.查看定时任务队列,通过命令 crontab -l

注意:如果定时任务没有执行,可能是crond服务没有在运行。可以通过 ps -ef | grep crond 命令查看该进程运行情况。
补:service crond restart 重启crond服务 service crond stop 停止crond服务
5.Linux中的挂载
1.概念
挂载:指的就是将设备文件中的顶级目录连接到Linux根目录下的某一目录,访问此目录就等同于访问设备文件。
Linux系统中"一切皆文件",所有文件都放置在以根目录为树根的树形目录结构中。
在Linux看来,任何硬件设备也都是文件,它们各有自己的一套文件系统。
当在Linux系统中使用这些硬件设备时,只有将硬件设备的文件目录 嫁接到Linux本身的文件目录,硬件设备才能为我们所用。这里的嫁接过程我们称之为"挂载"。
2.举例
举个例子,我们想通过命令行访问某个 U 盘中的数据,图 1 所示为 U 盘文件目录结构和 Linux 系统中的文件目录结构。
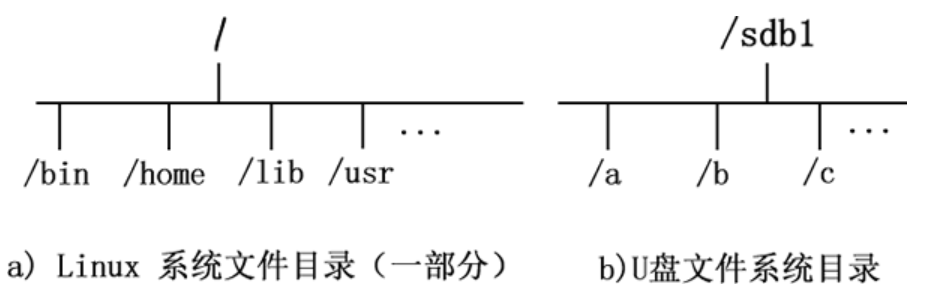
图 1 U 盘和 Linux 系统文件目录结构
图 1 中可以看到,目前 U 盘和 Linux 系统文件分属两个文件系统,还无法使用命令行找到 U 盘文件,需要将两个文件系统进行挂载。
接下来,我们在根目录下新建一个目录 /sdb-u,通过挂载命令将 U 盘文件系统挂载到此目录,
mount /dev/sdb1 /sdb-u挂载效果如图 2 所示。
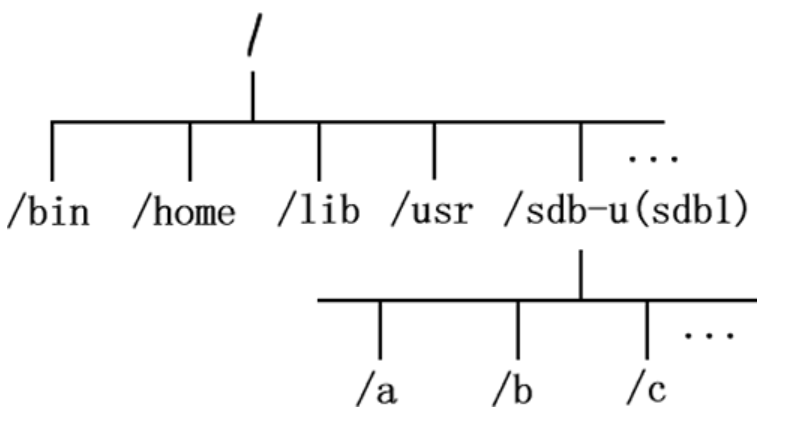
图 2 文件系统挂载
可以看到,U 盘文件系统已经成为 Linux 文件系统目录的一部分,此时访问 /sdb-u/ 就等同于访问 U 盘。
前面讲过,根目录下的 /dev/ 目录文件负责所有的硬件设备文件,事实上,当 U 盘插入 Linux 后,系统也确实会给 U 盘分配一个目录文件(比如 sdb1),就位于 /dev/ 目录下(/dev/sdb1),但无法通过 /dev/sdb1/ 直接访问 U 盘数据,访问此目录只会提供给你此设备的一些基本信息(比如容量)。
总之,Linux 系统使用任何硬件设备,都必须将设备文件与已有目录文件进行挂载。
3.补充
前面讲过,根目录下的/dev/目录文件负责所有的硬件设备文件。
事实上,当U盘插入Linux后,系统也确实会给U盘分配一个目录文件(比如:sdb4)。
位于/dev/sdb4,但是无法通过/dev/sdb4/直接访问U盘数据。
我们只要执行mount操作后就可以访问U盘数据了。
总之,Linux系统使用任何硬件设备,都必须将设备文件与已有目录文件进行挂载。
4、LINUX文件结构和WINDOWS的不同
Linux是多用户操作系统,所以制定一个固定的目录规划有助于对系统文件和不同的用户文件进行统一管理——Linux采用标准的树状目录结构
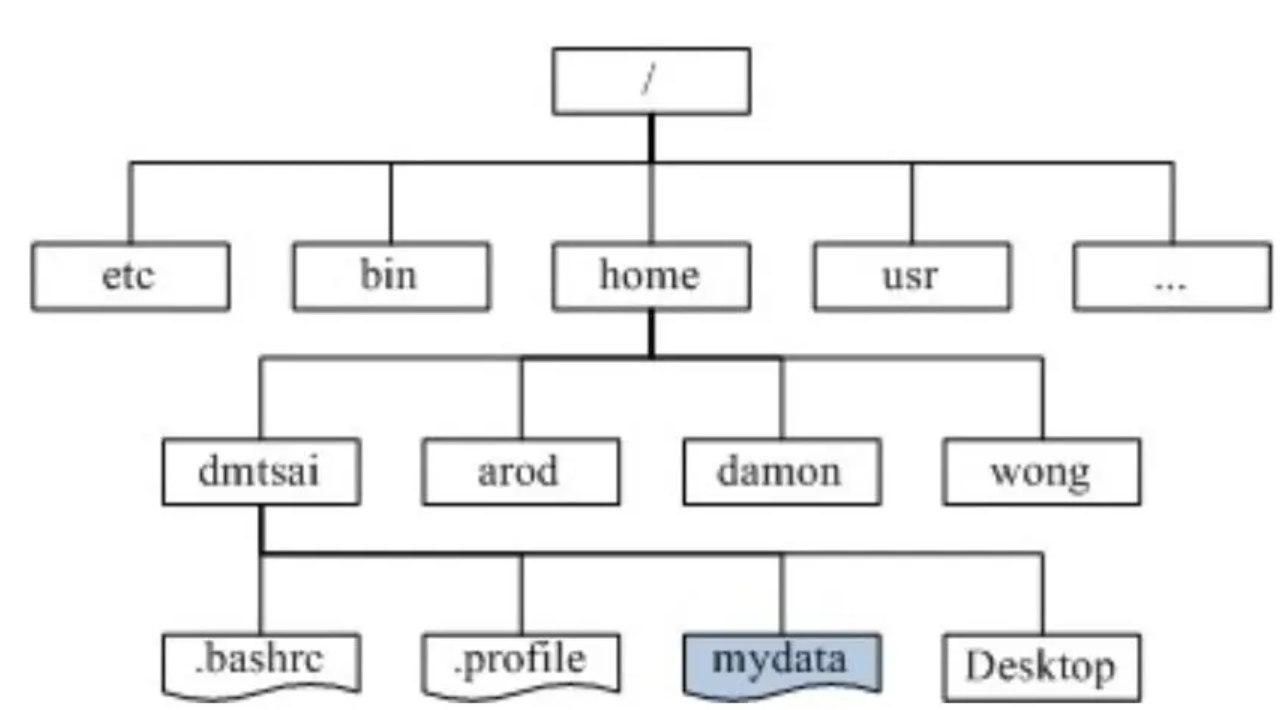
Windows不同的是,在最顶层的文件目录不是唯一的(多个盘符)

5、挂载文件系统
linux系统中每个分区都是一个文件系统,都有自己的目录层次结构。linux会将这些分属不同分区的、单独的文件系统按一定的方式形成一个系统的总的目录层次结构;这里所说“按一定方式”就是指的挂载
通俗的说,将一个文件系统的顶层目录挂到另一个文件系统的子目录上,使它们成为一个整体,称为挂载;我们把这个子目录叫“挂载点”

注意几点:
1. 挂载点必须是一个目录
2. 一个分区挂载在一个已存在的目录上,这个目录可以不为空,但挂载后这个目录下以前的内容将不可用;对于其他操作系统建立的文件系统的挂载也是这样
挂载前要了解linux是否支持所要挂载的文件系统格式
6.挂载常用命令
在Linux中,挂载是一个关键的概念,它允许我们将文件系统附加到目录树中的某个位置。这可以通过使用`mount`命令来实现。以下是一些常用的`mount`命令及其用途:
1. `mount`:显示当前已挂载的文件系统信息。
2. `mount -a`:尝试自动挂载`/etc/fstab`文件中定义的所有文件系统。这个命令常用于启动时自动挂载文件系统。
3. `mount -t <文件系统类型>`:指定要挂载的文件系统类型,如`ext4`、`ntfs`、`vfat`等。
4. `mount -L <卷标名>`:通过卷标名称来挂载分区,而不必知道设备文件名。
5. `mount -U <UUID>`:通过UUID来挂载特定的设备。
6. `mount -o <特殊选项>`:设置挂载时的特殊选项,例如`ro`(只读)、`rw`(读写)、`noatime`(不过记录访问时间)等。
7. `umount`:卸载之前挂载的文件系统,对应的设备才可以安全移除。
例:
将 /dev/hda1 挂在 /mnt 之下。
#mount /dev/hda1 /mnt将 /dev/hda1 用唯读模式挂在 /mnt 之下。
#mount -o ro /dev/hda1 /mnt
在使用`mount`命令时,需要注意以下几点:
- 必须拥有足够的权限(通常是root权限)来执行挂载操作。
- 在挂载之前,确认你要挂载的设备或文件系统是有效的,并且不会与其他已挂载的文件系统冲突。
- 卸载设备前,确保没有进程正在使用该设备,否则可能导致数据丢失或系统不稳定
6.find命令
`find`命令是Linux系统中一个强大的工具,主要用于在指定目录下查找文件和目录。它可以配合多种选项来过滤和限制查找的结果。
`find`命令的基本用法
`find`命令的一般格式如下:
find [路径] [匹配条件] [动作]
其中:
**路径**:要查找目录路径,可以是一个目录或文件名,也可以是多个路径,多个路径之间用空格分隔,如果未指定路径,则默认为当前目录。
**匹配条件**:可选参数,用于指定查找的条件,可以是文件名、文件类型、文件大小等等。
**动作**:可选的,用于对匹配到的文件执行操作,比如删除、复制等。
find命令的一些常见选项:
1.name pattern:按文件名查找,支持使用通配符 `*` 和 `?`。
2.type type:按文件类型查找,可以是 `f`(普通文件)、`d`(目录)、`l`(符号链接)等。
3.size [+-]size[cwbkMG]:按文件大小查找,支持使用 `+` 或 `-` 表示大于或小于指定大小,单位可以是 `c`(字节)、`w`(字数)、`b`(块数)、`k`(KB)、`M`(MB)或 `G`(GB)。
4. time days:按修改时间查找,支持使用 `+` 或 `-` 表示在指定天数前或后,天数是一个整数表示天数。
5.user username:按文件所有者查找。
6.group groupname:按文件所属组查找。
find命令的实际应用
例如,如果你想找到当前目录及其子目录下所有名为 `example.txt` 的文件,你可以使用以下命令:
find . -name "example.txt"
如果你想找到当前目录及其子目录下所有大于1MB的文件,你可以使用以下命令:
find . -type f -size +1M
如果你想找到当前目录及其子目录下所有属于用户 `username` 的文件,你可以使用以下命令:
find . -type f -user username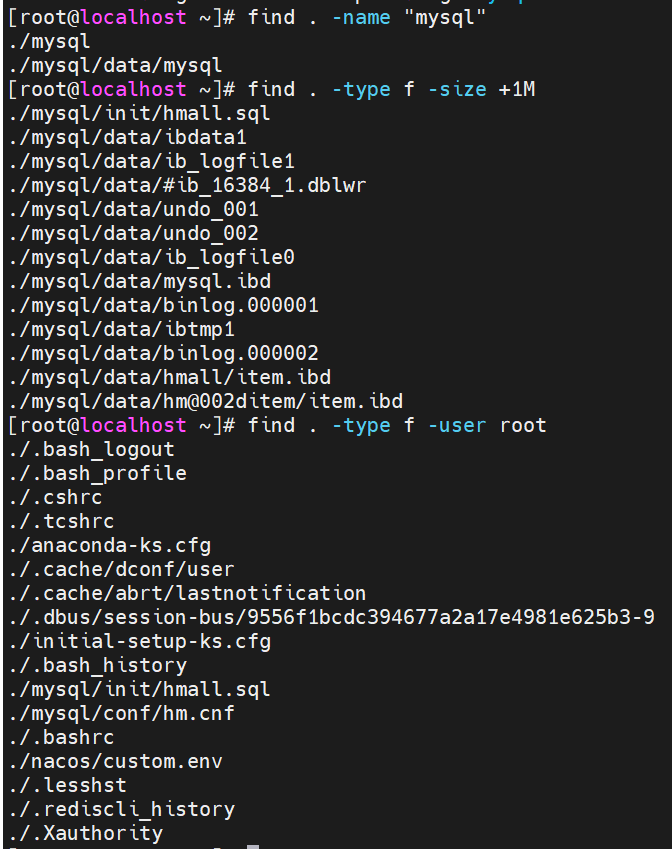
以上只是 `find` 命令的一部分功能,实际上 `find` 命令的功能非常强大,可以根据你的需求进行各种复杂的查询。
7.Linux文件处理相关命令(grep、awk、sed)
对文件内容进行处理,grep擅长查找功能,sed擅长取行和替换文件内容,awk擅长取列。这三个命令的功能十分丰富,在此只说一下常用功能。
1.grep命令
-i:忽略大小写进行匹配。-v:反向查找,只打印不匹配的行。-n:显示匹配行的行号。-r:递归查找子目录中的文件。-l:只打印匹配的文件名。-c:只打印匹配的行数。
- 在文件中搜索指定字符串:
grep "pattern" file.txt - 使用正则表达式进行搜索:
grep "^[0-9]*$" file.txt - 忽略大小写进行搜索:
grep -i "pattern" file.txt - 递归搜索目录下的文件:
grep -r "pattern" directory/ - 统计匹配到的行数:
grep -c "pattern" file.txt2.sed命令
提取文件中符合条件的行,输出到屏幕
假设文件 fin.txt 中的内容如下:
hello Jobs
hello Pony
hello Jack, hi Jack1. 把每一行中的 Jack 替换成 Mark
sed 's/Jack/Mark/' fin.txt
>>
hello Jobs
hello Pony
hello Mark, hi Jacksed 命令一般是写在单引号内,引号内开头的 s 表示替换(substitute),
需要注意的是,在默认情况下,sed 只会替换每行中匹配到的第一个字符串,所以上面例子中最后一行的第二个 Jack 没有被替换,如果希望替换每一行中所有匹配到的字符串,需加在命令末尾上选项 g,比如:
sed 's/Jack/Mark/g' fin.txt
>>
hello Jobs
hello Pony
hello Mark, hi Mark注意这条命令并不会修改文件 fin.txt 的内容,只是将文件中的每一行读入缓存,执行替换,然后输出到屏幕,文件内容并没有发生改变。
如果希望直接修改文件内容,可加上选项 “ -i ”
sed -i 's/Jack/Mark/g' fin.txt2. 将 2~3 行中的 hello 替换成 hey
sed '2,3s/hello/hey/g' fin.txt
>>
hello Jobs
hey Pony
hey Jack, hi Jack这条命令开头的 2,3 表示仅在第 2 至第 3 行执行替换
3. 找出包含字符 Pony 的那些行,将这些行中的 hello 替换成 hey
sed '/Pony/s/hello/hey/g' fin.txt
>>
hello Jobs
hey Pony
hello Jack, hi Jack这里的 Pony 是正则表达式,所以需要用 // 括起来
4. 删除 2~3 行
sed '2,3d' fin.txt
>>
hello Jobs命令中的 d 表示删除(delete),执行之后第 2~3 行就被删除了,仅剩下第一行
5. 删除包含字符串 Pony 的行
sed '/Pony/d' fin.txt
>>
hello Jobs
hello Jack, hi Jack这里的 Pony 也是正则表达式,所以用 // 括起来了
6. 删除空白行
sed '/^$/d' fin.txt这里的 ^ 匹配一行的开头, $ 匹配一行的结尾,所以 /^$/ 就表示一行的开头和结尾之间没有任何内容,也就是空白行;
注意有时候有些空白行是包含空格的,这种情况就需要写成:
sed '/^\s*$/d' fin.txt其中 \s 表示空格, 星号 * 表示前面的字符重复 0 次或多次,所以这种写法可以匹配那些包含任意个空格的空白行
7. 删除不包含字符 Pony 的行
sed '/Pony/\!d' fin.txt这里的感叹号 ! 表示反选,也就是选择那些不符合正则表达式 /Pony/ 的行, 右斜杠表示转义, 因为在有些系统下 ! 会被识别成其他的意思
8. 在指定某一行的前面或者后面添加一行
sed -i '1i\welcome' fin.txt
>>
welcome
hello Jobs
hello Pony
hello Jack, hi Jack这里的 1 表示第一行, i 表示在这一行前面添加一行,如果要在第一行后面添加一行,则用字母 a
sed -i '1a\welcome' fin.txt字母 a 是 append ,在后面添加一行
字母 i 是 insert, 在前面添加一行
9. 在匹配行的前面或者后面添加一行
sed -i '/Pony/a\welcome' fin.txt
>>
hello Jobs
hello Pony
welcome
hello Jack, hi Jack同样,在后面添加一行用字母 a,在前面添加一行用字母 i
sed -i '/Pony/i\welcome' fin.txt3.awk命令
awk 的工作原理是将文件内容逐行读入,然后以每一行中的空格为分隔符将每行数据切分成几列,再对每列的元素进行各种分析处理。
下面结合实例简单介绍 awk 命令常用的几种格式:
假设文件 form.txt 中有如下内容:
Num Name Company Product
1 Jobs Apple iPhone
2 Jack Alibaba taobao
3 Pony Tencent wechat1. 打印第二列和第三列:
awk '{print $2 $3}' form.txt
>>
NameCompany
JobsApple
JackAlibaba
PonyTencent awk 的命令都写在单引号内,再用花括号括起来,这里的 $2 $3 分别表示第二列和第三列, $0 则表示整行;
可以看到第二列和第三列就打印出来了,但是两列数据紧贴在一起,如果我们希望以制表符来分隔开:
awk '{print $2"\t"$3}' form.txt
>>
Name Company
Jobs Apple
Jack Alibaba
Pony Tencent注意制表符 \t 需要用双引号括起来
2. 打印出第 2,3,4 行的第二列和第三列,以制表符分隔开:
awk '/^[0-9]/{print $2"\t"$3}' form.txt
>>
Jobs Apple
Jack Alibaba
Pony Tencent这里用到了 awk 的一种常用语法: awk ‘ 样式{命令}’ file
表示从文件 file 中取出那些符合 “样式” 的行,然后对这些行执行{命令}
这里的 “样式” 一般是正则表达式,用定界符 / / 括起来,命令依然是用花括号括起来
所以上面这个例子就表示:取出那些以数字开头的行,打印这些行的第二列和第三列,并以制表符分隔开
3. 打印出前三行的第二列和第三列:
awk '{ if (NR<=3) {print $2"\t"$3} }' form.txt
>>
Name Company
Jobs Apple
Jack Alibaba这里用到了 awk 编程,在花括号内写了一小段程序,awk 编程基本都是借鉴 C 语言,所以 C 语言中常见的 if for while 等控制结构都可以直接借用。
这个例子中还用到了awk 内嵌特殊变量 NR,NR 记录的是当前行号,awk还有很多其他的内嵌变量,比如 NF 表示当前行有多少列。
在数字后端设计中,经常需要从一些 report 中抓出某几行的某一列数据,比如 timing report 中的 cell name 或者 pin name,此时就很适合用这种简短的 awk 编程来处理。
4.使用 “非空格字符” 切分列
默认情况下,awk 命令读入一行数据后,会用这行中的空格将整行数据切分成若干列,但是有些数据不是以空格作为间隔的,比如下面这组:
Num,Name,Company,Product
1,Jobs,Apple,iPhone
2,Jack,Alibaba,taobao
3,Pony,Tencent,wechat此时,如果想要打印出第二列和第三列,就需要使用选项 “ -F ” 来指定分隔符:
awk -F"," '{print $2"\t"$3 }' form.txt
>>
Name Company
Jobs Apple
Jack Alibaba
Pony Tencent这里的选项 -F "," 就表示以每行数据中的逗号为分隔符,来切分数据。