摘要
现代视觉识别系统受限于其能力为:扩大大规模数量的目标类别。
- scale to large numbers of object categories
- text data :文本数据
- 这篇文章我们提出一个a new deep visual-semantic embedding model
- 从unannotated text 中收集的语义信息和有标签的图像数据。
- on the 1000-class ImageNet object recognition
介绍
目前顶级的图像分类的方法是:
- 训练一个a deep convolutional neural networkwith a softmax output layer: multinomial logistic regression
- 其实越来越困难的从罕见概念中得到足够多数量的训练数据。
- W S A B I E WSABIE WSABIE
- a joint embedding model of both images and labels.
- 方式:employing an online learning-to-rank algorithm
- explored linear mappings from image features to the embedding space
- the image representation space: 图像表示空间
- the embedding space嵌入空间。
- a mean-squared error criterion: 均方误差标准
- the 8-way classification 八种类别的Classification.
Proposed Approach
- semantic knowledge learned in the text domain:文本域中学习到的语义知识。
- vector representation of the image label text: 图像标签文本的词向量表示。
Language Model Pre-training
- The skip-gram text modeling architecture: 由其提出 M i k o l o v e t a l Mikolov et al Mikolovetal
- represent each term as a fixed length embedding vector 代表每一项作为一个固定长度的嵌入向量。
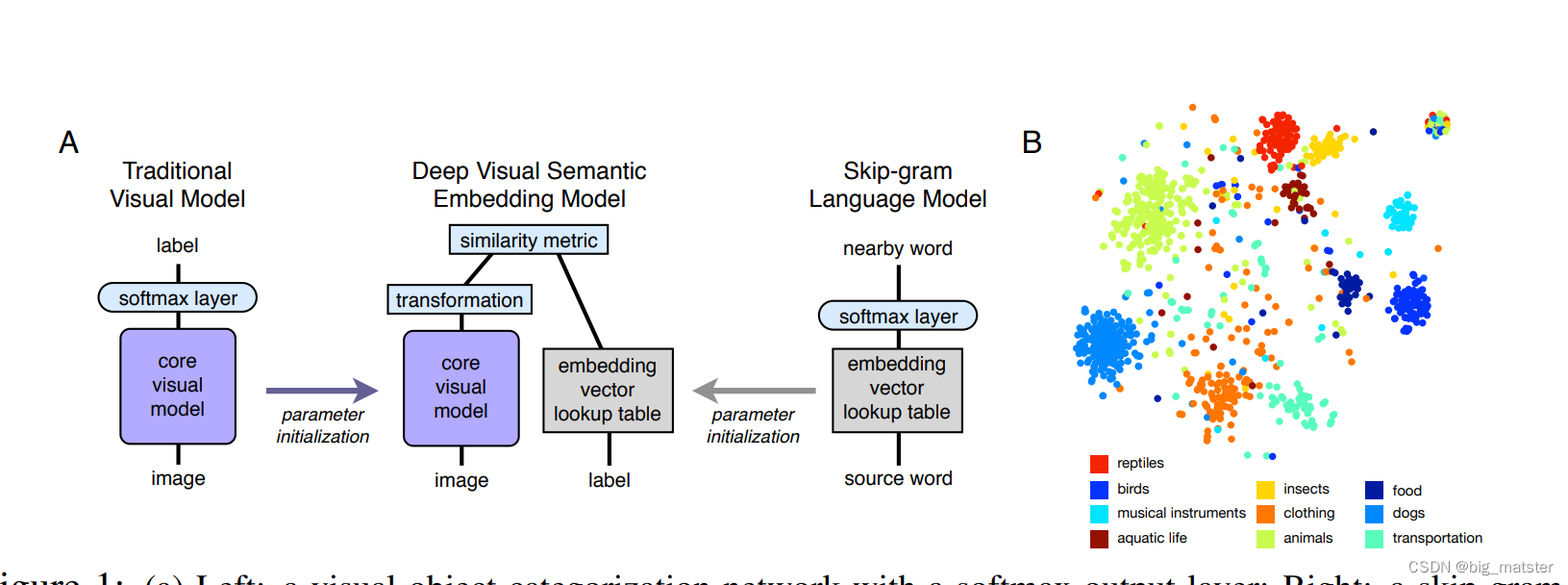
- 训练一个a skip-gram text model
-
Visual Model Pre-training

Deep Visual-Semantic Embedding Model
- is initialized from these two pre-trained neural network model。
- 语言模型学习的嵌入向量,

-
- a combination of dot-product similarity and hinge rank loss
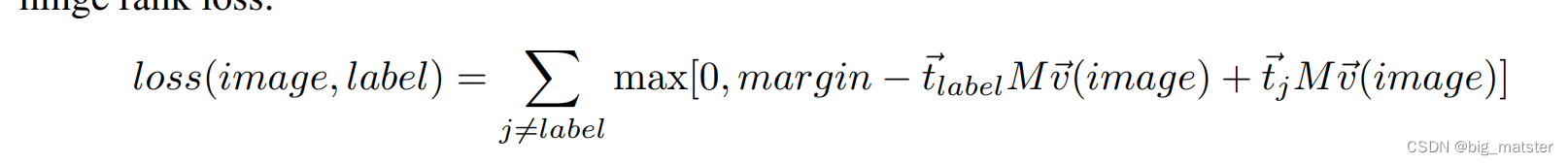
-
Results
-
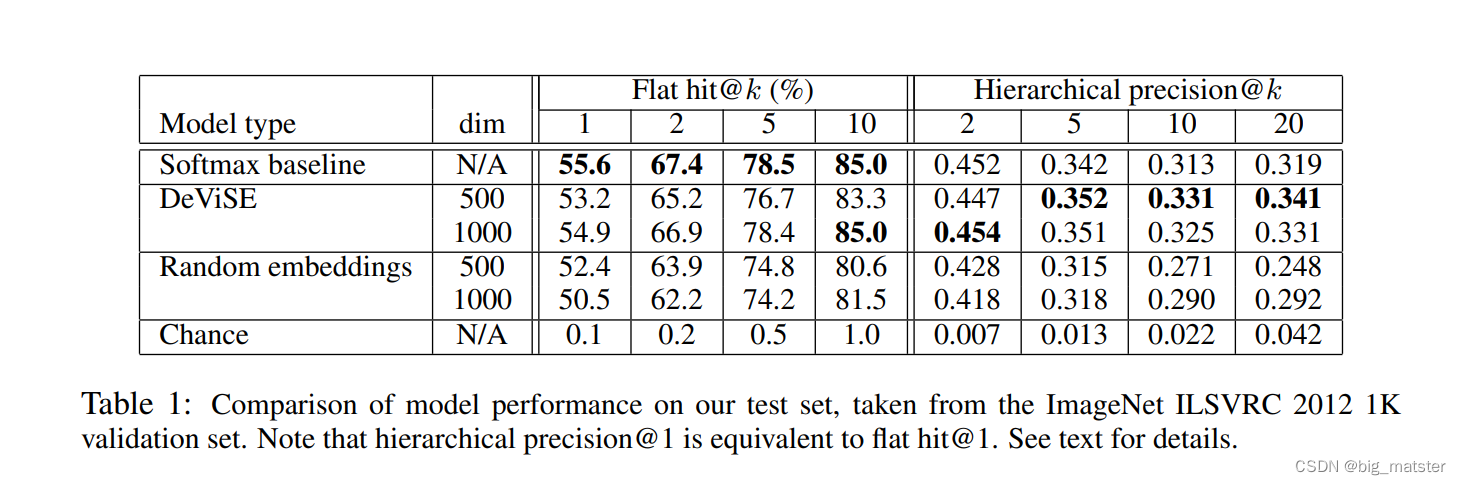
- a softmax baseline model
- a 1000-way softmax classifier
- a ranodm embedding model
-
ImageNet (ILSVRC) 2012 1K Results

-
Generalization and Zero-Shot Learning

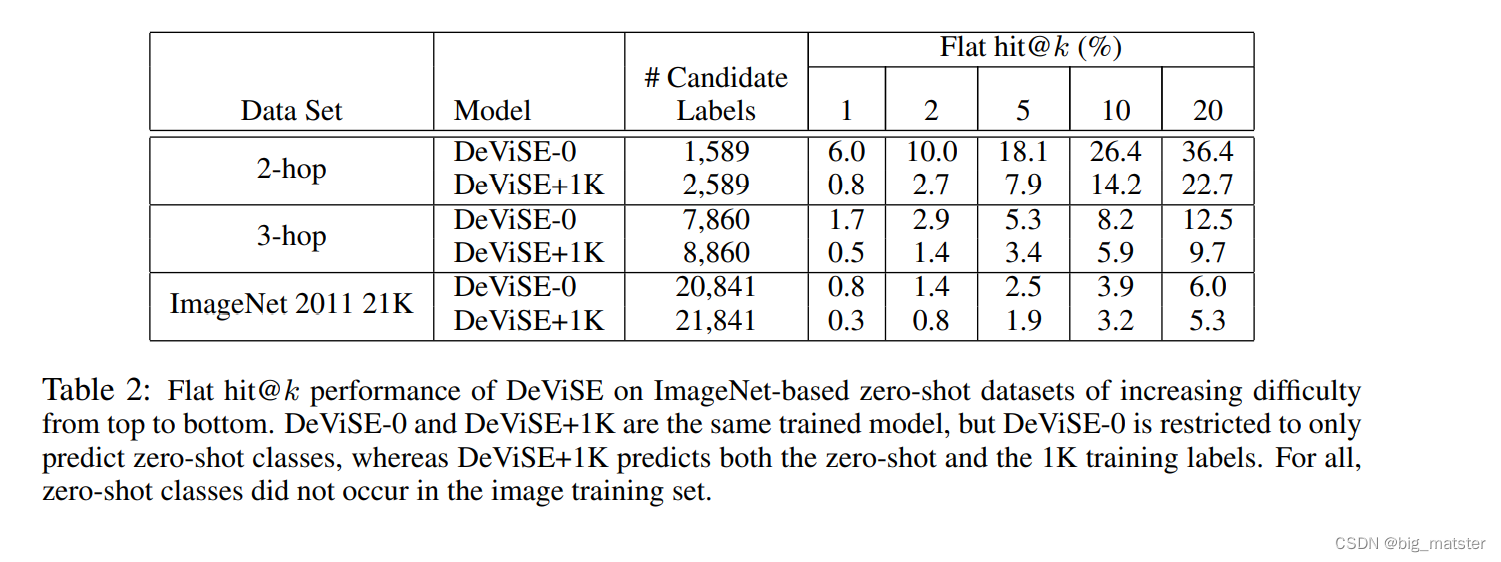
- To test this hypothesis:为了验证这个假设,

!在这里插入图片描述
Colusion
- joint visual-semantic enbeddug model
- a hierarchical label metric

经验
重点是总结以下,常见的不熟悉的词汇,慢慢的将其全部都研究彻底,
- 训练模型的时候,在将各个层总结以下,会知道如何构建网络架构,设计自己的架构环境。会自己总结网络架构,设计自己的架构思想都行啦的理由与打算。
- 慢慢的将各种网络架构,全部都将其搞彻底,全部都将其理解错误都行啦的理由与打算。
- 自己设计自己的网络架构,慢慢的将各种网络架构全部都设计完整,会自己设计自己的架构与架构层次。

![[go]深入学习Go总结](https://img-blog.csdnimg.cn/img_convert/b2b65101a65acecf7d7e7aee1f1be1d4.png)