简单问题引入
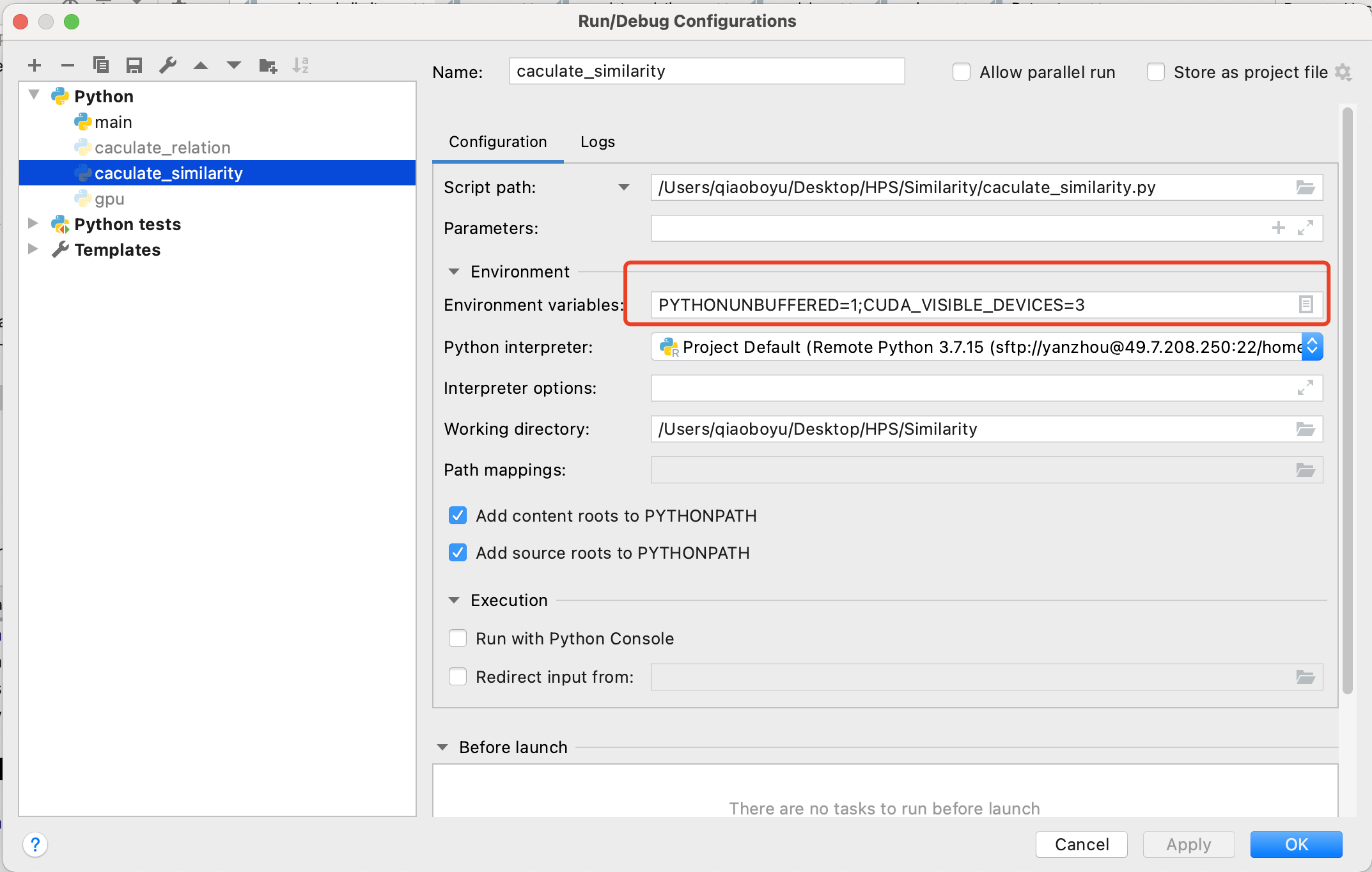
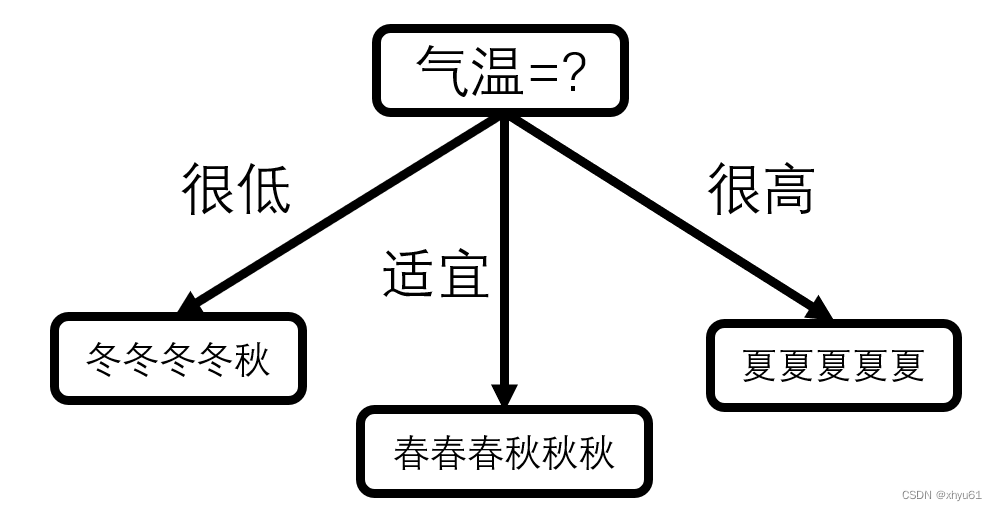
如何判断今天是什么季节?春天、夏天、秋天、冬天?
如果是我们的话,可以通过日期一下子知道今天的季节——“7月份,所以是夏天!”大概是这样的发言。
但如果不让你通过日期来判断呢?选择还是很多的,比如说根据气温来判断或许也可行?如果今天天气非常非常冷,我可以认为,这一定是冬天;今天天气太热了,一定需要一根雪糕来解暑的程度,这一定是夏天;天气适宜的时候,难办了——可能是春天,可能是夏天,这个时候我们可以看看窗外,窗外的树上的叶子越来越多了,向着枝繁叶茂发展,那一定是春天;如果叶子越来越少,不断凋零,那想必一定是秋天。
我们来对这个不允许使用时间的判断方法进行解读。
我们发现,我们一共利用了周遭环境的两个属性:一是气温,气温有很高、很低和适宜三种情况;二是树叶生长情况,有不断生长和不断凋零两种状态。
我们可以通过这个判断方法画出如下的一个判断机制。

不难发现,这是一个树形结构。继续观察的话,可以发现更多的性质:
- 所有的叶子结点都是我们的选项
- 所有的非叶子结点都是一个对属性的判断(气温和树叶长落,这是我们刚刚对周遭环境分析出来的两个属性)
- 每一条边都是一个属性的判断,一个非叶子结点向各个子节点连接的边表示了对这个非叶子结点所讨论的属性的各种可能的情况。
这一棵树生动形象地将我们的判断过程表现了出来,从根节点不断进行判断可以一路走到叶子结点,从而得到我们所求的答案。这棵树就是一棵决策树。
如果我们把这样的一棵树丢给计算机,当我们想知道今天属于什么季节的时候,把今天的气温、树叶长落的两个属性的属性值告诉这台计算机,计算机从根节点就可以一路走向叶子结点,从而告诉我们今天是春天、夏天、秋天,还是冬天。
这就是一棵决策树在做的事。
我们在训练模型的过程中对决策树有两种操作:一种是构造决策树,一种是利用决策树将所给的测试数据进行判断。
构建决策树简介
在训练模型的过程中,我们要通过所给的测试数据进行决策树的搭建。已知有 x x x个属性,利用决策树进行类别判断的时候,我们本质上是分别判断这 x x x个属性分别是什么来把类别看出来。为了提高分类的效率,我们希望可以尽可能早地排除尽可能多的错误选项。
还是拿上图的决策树举例,判断季节我们用了两个属性,第一次判断,我们通过气温是很低、很高、适宜,将四个季节分为了三类;第二次判断利用了树叶的长落情况,区分了气温适宜的两个季节。
从判断的顺序来看,我们的顺序是先判断气温,后判断树叶长落。
或许我们可以反过来?是不是也可以先判断树叶长落,后判断气温呢?如果我们先判断树叶长落,那么决策树大概是这个样子:
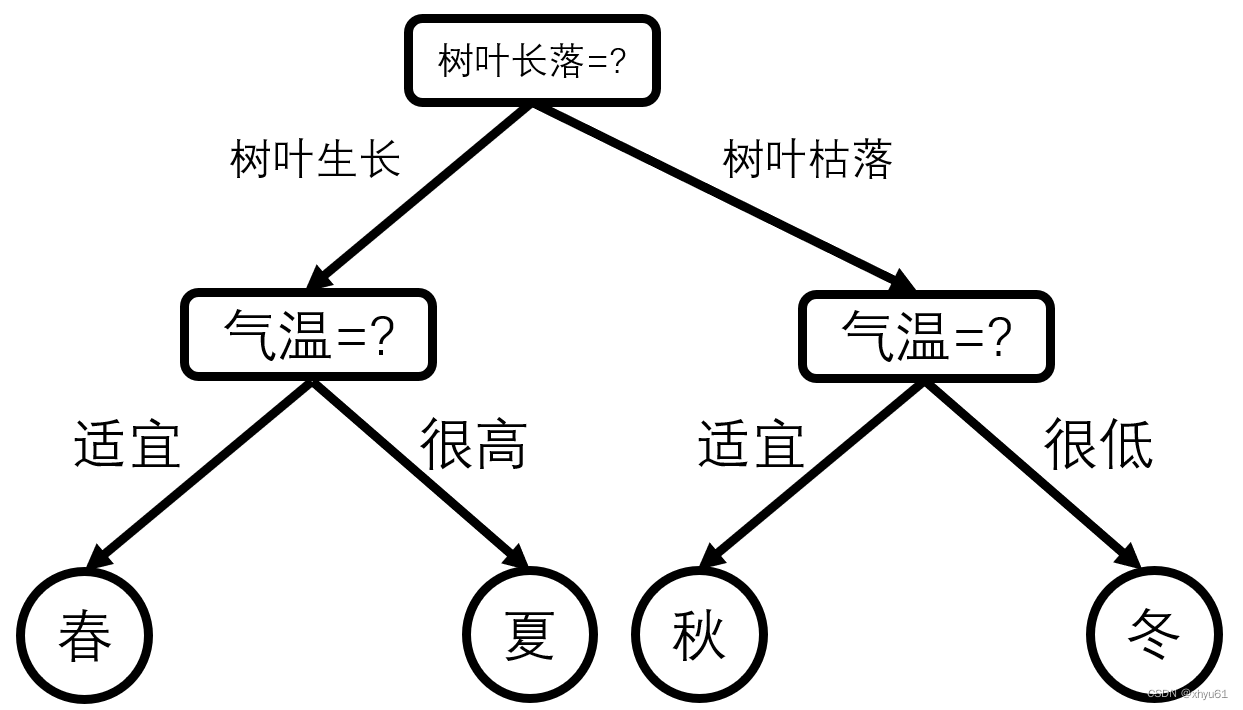
看上去也是一种可行的方案。
不妨观察和最开始的那一棵决策树相比有什么区别。
- 无论是春夏秋冬哪一个季节,第二种决策树都要进行所有属性的判断,而第一种决策树,如果气温很高或很低,我们可以只需要对气温的判断就能知道季节。
- 对于第二种决策树,在作为第二个属性进行判断的气温属性,对应不同的树叶张落情况,其值域不太相同,当树叶生长时,气温的情况为适宜、很高;当树叶枯落时,气温的情况为适宜、很低。
从我们前面提到的需求来看(尽可能早地排除尽可能多的错误选项),第一个决策树会更好一些。
从决策树的应用角度考虑会更加清晰:通常使用决策树时都会给一组关于各个属性的数据,站在根节点上的时候,我们可选的选项为所有的选项,每当我们进行判断时,我们希望当前可选的选项要变得尽可能小。
从决策树的构建角度来看:通常我们会通过给定的很多很多组关于各个属性的数据(带有最终的选项的答案)去训练出一棵决策树,我们如何选定当前应该先进行哪一个属性的判断,使得我判断完之后,分类的效果最好,即对于这个属性的每一个可选值,其筛选出来的所有组数据的最终选项最倾向于统一。
什么叫最倾向于统一呢?还是以判断四季的情景为例,比如说训练决策树的过程中,我通过气温进行当前情况下的下一次判断,分类出来所有测试集数据选项如下:
观察到,很低和很高把最后的结果分成大部分为冬和全部为夏,全部为夏是最理想的,因为这完全起到了分类的效果,很多个冬里混了一个秋也还算不错,因为我们也能大体看出他应该是什么。气温适宜这个里面,一半是春,一半是秋,就有点混乱,不知道是春还是秋了。
这样,对于先进行气温属性的判断,最后的分类是否统一,就看很低、适宜、很高分类后的选项综合到一起是否倾向于统一。也就是说,要看气温属性的判断结果是不是统一,要综合看很低、适宜、很高的分类里面选项是否倾向于都是同一个选项。我们喜欢的就是倾向于同一个选项的,因为这符合尽可能早地排除尽可能多的错误选项的思想。
对于每一个非叶子结点,我们把所有当前还没有判断的属性的这样的是否统一的度量比较一下,选择一个最统一的属性作为当前情况的下一个判断的属性。
于是自然而然地引出了训练决策树的方法:我们通过训练集,从根节点开始构造。根节点处选择一个分类后最倾向于统一的属性,然后按照可选值域进行向下扩展,对于每一个子树的根节点,继续用同样的方法找出还没有判断过的属性中最倾向于统一的属性,把那个属性作为这个节点的判断属性。以此类推直到每一个分支都分出唯一的选项。
我们这里采用的是一个“统一”的定性的分析,但是在实现过程中,我们需要一个定量操作来判断他的“统一”性,于是引入了熵的概念。
熵
大学物理中在热力学章节里学过熵这个概念,大体上是描述一个状态是否稳定。我们经常听到一个词叫做“熵增”,就是描述一个过程变得更加不稳定,或者更加混乱。
在决策树中也有熵这一概念。我们用熵来表示当前分类的混乱程度(这和熵原本的含义是相近的)。
熵是表示随机变量不确定性的度量。换句话说,就是当前物体内部的混乱程度。
设 H ( x ) H(x) H(x)表示 x x x状态的熵,那么有公式
H ( x ) = − ∑ i = 1 n p i × log 2 p i H(x)=-\displaystyle\sum\limits_{i=1}^n p_i\times \log_2 p_i H(x)=−i=1∑npi×log2pi
p i p_i pi表示 x x x状态中某一个选项出现的概率(或许频率这个词更好?)。
我们通常都用以 2 2 2为底的 log \log log来算,但有少数情况也可以采用其他的底数,比如说差值太小太小,精度要求太高之类的情况。
熵是一个表示混乱程度的变量,也就是说我们希望熵本身越小越好。
引入熵的概念之后,我们可以通过熵来定量地观察接下来判断哪一个属性会使熵最小,每一个属性都计算出一个熵,选择一个熵最小的属性,用于下一个判断。
借用该视频中的一个例子,来看如何通过熵来构建一棵决策树。
例:给定14天的天气、温度、湿度、风的强度以及当天是否打球的数据,目标是构造一棵决策树。
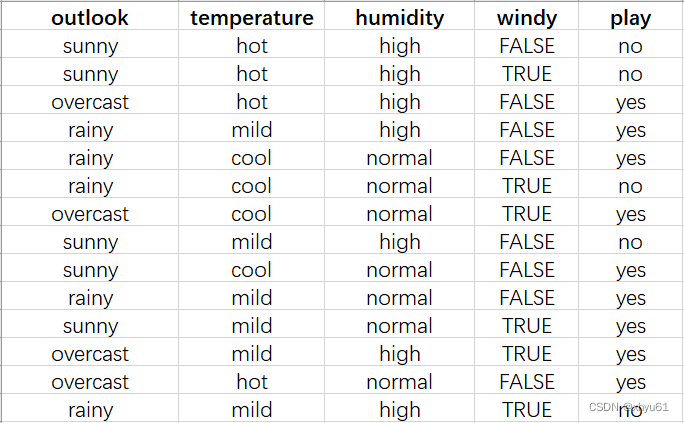
不难发现,这个列表中,outlook、temperature、humidity、windy是自变量,play是因变量。换句话说,前四个是属性,最后一个是选项,选项有两种,分别是no和yes。
构造决策树,相当于考察各个属性之间的判断顺序。我们需要通过这些数据集来判断先进行哪一个属性的分类会使整体的熵最小。想看谁的熵最小,就需要对于每一个属性都假设其为第一个进行分类的属性,然后计算分类后的熵,再看看哪一个可以使当前熵下降的最多(和看哪一个的熵最小没有什么区别)。
4种属性的熵值计算方法相同,仅以outlook属性为例。以outlook属性为根节点处的分类属性后,大概分成了这个样子:
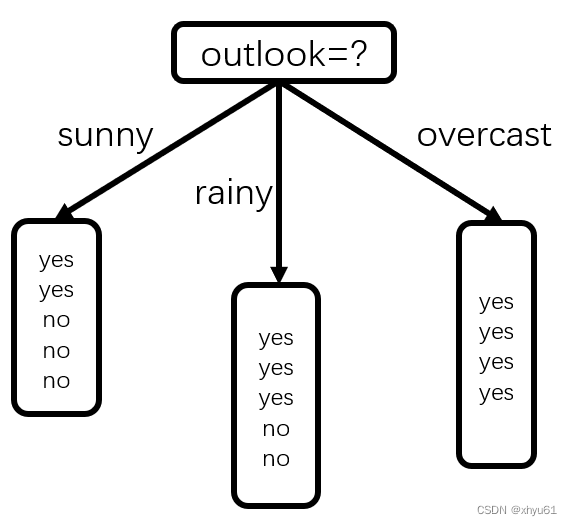
首先,我们计算一下选定第一个分类的属性之前的熵值。根据数据,数据集中有9天在打球,5天没有打球。此时的熵套入公式,为:
− 9 14 log 2 9 14 − 5 14 log 2 5 14 = 0.940 -\frac{9}{14}\log_2 \frac{9}{14}-\frac{5}{14}\log_2 \frac{5}{14}=0.940 −149log2149−145log2145=0.940
其中, 9 14 \frac{9}{14} 149为打球的概率, 5 14 \frac{5}{14} 145为不打球的概率。这两个数都是公式中 p i p_i pi中的取值。
接下来看sunny中有5天的数据记录,其中有2天打球,3天不打球,求得sunny情况下的熵为
−
2
5
log
2
2
5
−
3
5
log
2
3
5
=
0.971
-\frac{2}{5}\log_2 \frac{2}{5}-\frac{3}{5}\log_2 \frac{3}{5}=0.971
−52log252−53log253=0.971
rainy中有5天的数据记录,其中有3天打球,2天不打球,求得rainy情况下的熵为(不难看出其实和sunny一样)
−
3
5
log
2
3
5
−
2
5
log
2
2
5
=
0.971
-\frac{3}{5}\log_2 \frac{3}{5}-\frac{2}{5}\log_2 \frac{2}{5}=0.971
−53log253−52log252=0.971
overcast中有4天的数据记录,其中有4天打球,0天不打球,是最理想的统一状态,期望熵为0,但还是套一下公式看一看:
−
1
log
2
1
=
0
-1\log_2 1=0
−1log21=0
现在,outlook中的每一个取值中的熵算好了,现在要统合这三种情况的熵,将他们合为一个整体。具体的做法是,把三个熵按照其中数据集的大小加权起来求一个平均数。
换句话说,sunny在14组数据中出现了5次,权值就是\frac{5}{14};rainy在14组数据中出现了5次,权值就是\frac{5}{14};overcast在14组数据中出现了4次,权值就是\frac{4}{14}=\frac{2}{7}。
求得熵为加权平均数:
0.971
×
5
14
+
0.971
×
5
14
+
0
×
2
7
=
0.693
0.971\times \frac{5}{14}+0.971\times \frac{5}{14}+0\times \frac{2}{7}=0.693
0.971×145+0.971×145+0×72=0.693
那么这样分类之后,整体系统的熵值从原来的0.940下降至了0.693,变化量是0.247。
这里引入一个新的概念信息增益。不难看出,我们期待熵值下降,而且分类后熵值确实是下降,其下降的量是期待的数值,对我们来说属于一种增益,所以这个0.247就是这里的信息增益。
用同样的方式计算temperature、humidity、windy三个属性在作为第一次分类属性后系统的熵值,然后分别求得信息增益。
计算后求得,temperature分类后信息增益为0.029,humidity为0.152,windy为0.048。
不难看出,按照outlook属性作为第一次分类的属性,把outlook的分类放在根节点上,对系统而言是最优的。所以我们就把根节点设置为按照outlook分类。
那么接下来将问题分散到从根节点出发到sunny、rainy、overcast三棵子树上的子问题了。对于这些子问题,再分别计算temperature、humidity、windy三个属性给他们各自带来的信息增益,然后取那个信息增益最大的属性,作为这个子树里下一个要分类的属性。对于每一个子树,我们只尝试其祖先还没有进行分类的属性。这样以此类推,就可以建好整棵决策树。