- 🍅 我是蚂蚁小兵,专注于车载诊断领域,尤其擅长于对CANoe工具的使用
- 🍅 寻找组织 ,答疑解惑,摸鱼聊天,博客源码,点击加入👉【相亲相爱一家人】
- 🍅 玩转CANoe,博客目录大全,点击跳转👉
📘前言
-
🍅 车载测试必不可少的是刷写,行业内有很多格式的刷写文件,
S19,HEX,BIN,还有一些主机厂自定义的比如Volvo/Geea的VBF,Chery的CBF等 -
🍅 本章节先了解
S19文件
目录
- 📘前言
- 📙 S19 文件的格式简介
- 🍅 标准解释
- 🍅 实例说明
- 🍅 HEX View 神器
- 📙CAPL解析S19文件源码
- 🌎总结

📙 S19 文件的格式简介
🍅 标准解释
-
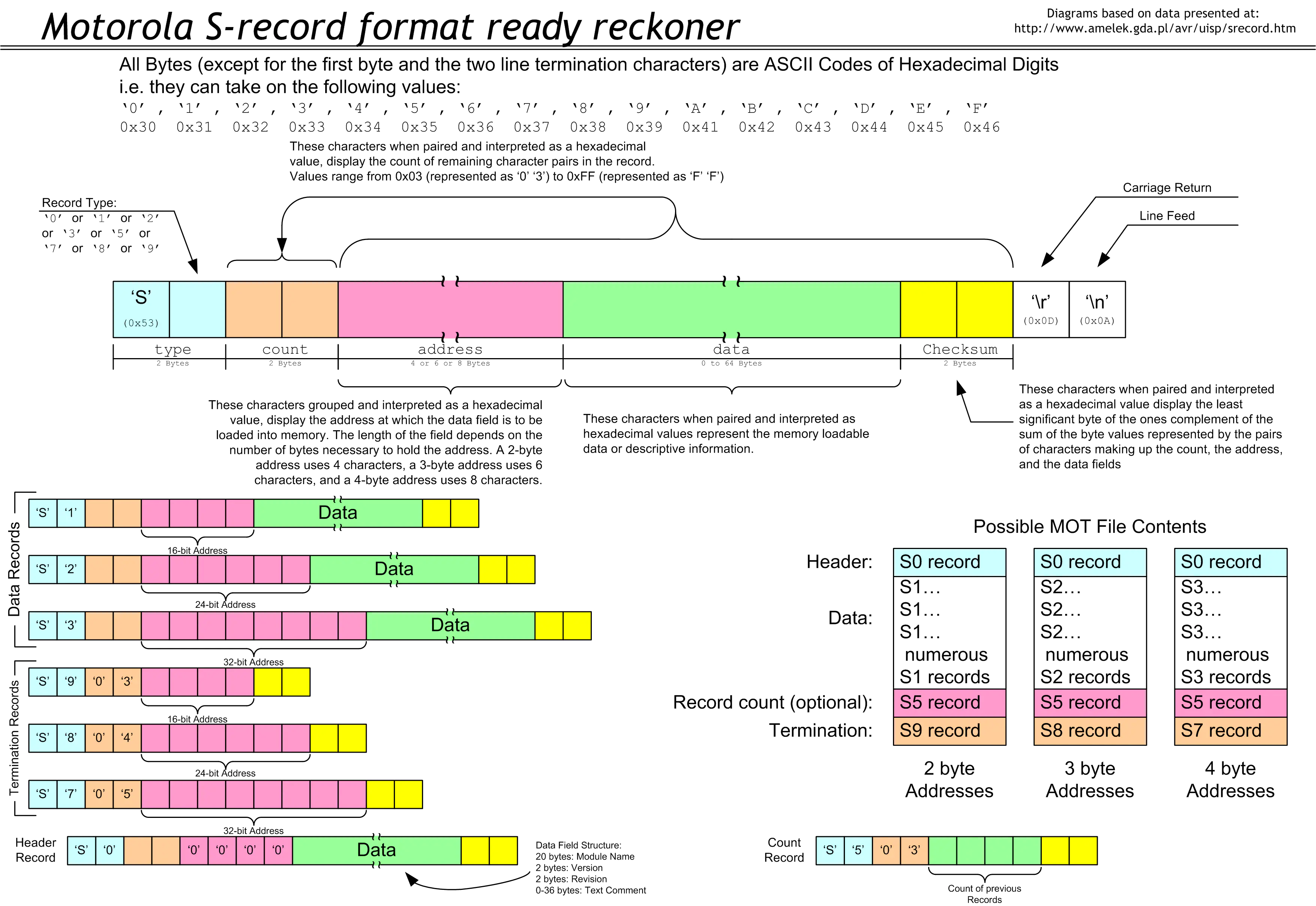
Motorola S-record是由Motorola创建的一种文件格式,它以 ASCII十六进制文本形式传送二进制信息。这种文件格式也可以称为SRECORD、SREC、S19、S28、S37。它通常用于对微控制器、EPROM 和其他类型的可编程逻辑设备进行编程。
-
S-record格式是在1970年代中期为 Motorola 6800处理器创建的。该处理器和其他嵌入式处理器的软件开发工具将生成S-record格式的可执行代码和数据。程序员将读取S-record格式并将数据“刻录”到嵌入式系统中使用的PROM或EPROM中
-
S19文件的每一行数据由下列五个部分组成:

-
type(记录类型):用来描述记录的类型 (S0,S1,S2,S3,S5,S7,S8,S9)。 -
count(字节计数):2个字符,表示记录的其余部分(address + data + checksum)的字节数,该字段的最小值为 3,最大值为 255 。通常记录有 0x20 个数据字节。 -
address(地址):4或6或8个字符。由记录类型 type(记录类型)` 决定。对于S1和S9类型(S19),地址字段为 4 个十六进制数字(2 个字节)。对于S2和S8 record(S28),地址字段为 6 个十六进制数字(3个字节),对于S3和S7 record(S37),地址字段为 8 个十六进制数字(4 个字节)。地址首先以 MSB 发送。地址字节以大端格式排列。 -
data(数据):0—64字符。用来组成和说明一个代表了内存载入数据或者描述信息的16进制的值。 -
checksum(校验和):一个字节。Checksum = 取补码( (uint8_t)(Byte count + Address + Data) )。
🍅 实例说明
- Notepad++ 打开选择语言,自动识别,根据颜色可以看出S19的记录格式
- 看到的是16进制显示的ASCII文本格式
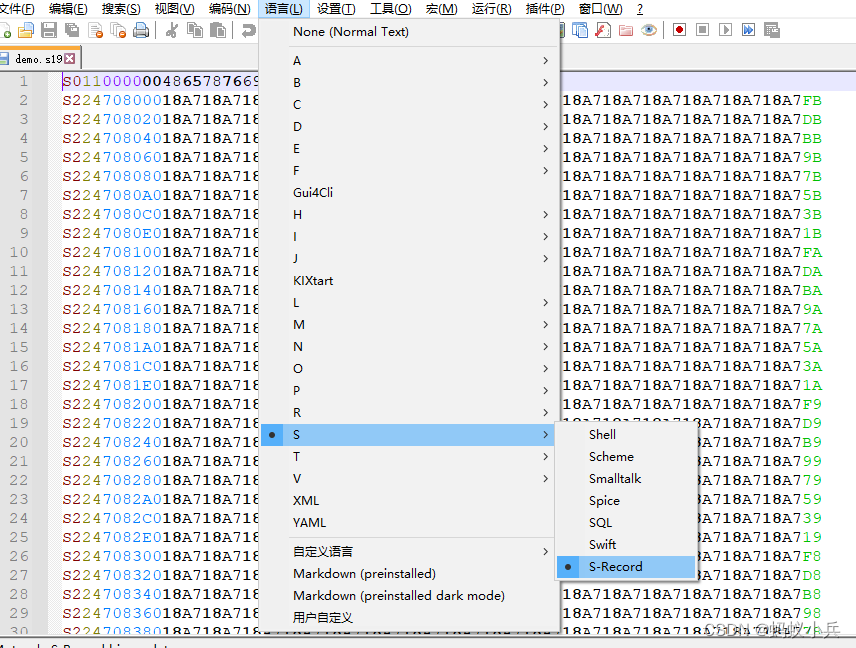
- 重点说下S19的Type类型
- S0是文件的第一行,头信息
- 如果数据是S1开头,则地址占2个字节(文本字符串用4个字节表示),则文件最后一行的尾信息的开头就是用S9表示
- 如果数据是S2开头,则地址占3个字节(文本字符串用6个字节表示),则文件最后一行的尾信息的开头就是用S8表示
- 如果数据是S3开头,则地址占4个字节(文本字符串用8个字节表示),则文件最后一行的尾信息的开头就是用S7表示
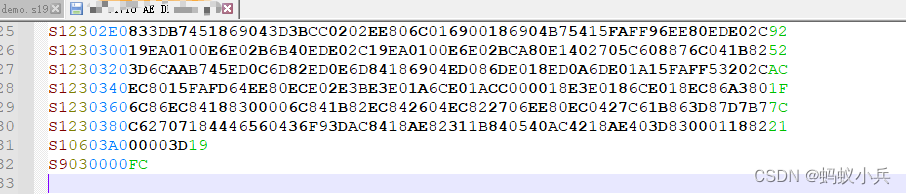
再看下面的一个type 是S2的小实例 :地址占6个字节(注意这是ASCII文本表示的,实际地址是0x708000 )
S2 24 708000 18A718A718A718A718A718A718A718A718A718A718A718A718A718A718A718A7 FB
再看下面的一个type 是S1的小实例 ,地址占4个字节(注意这是ASCII文本表示的,实际地址是0x0020)
S1 23 0020 1A6416AE01DA6426AE024A6E01B6AE01EEDE029A6416AE01FA6406AE025A6436 21
🍅 HEX View 神器
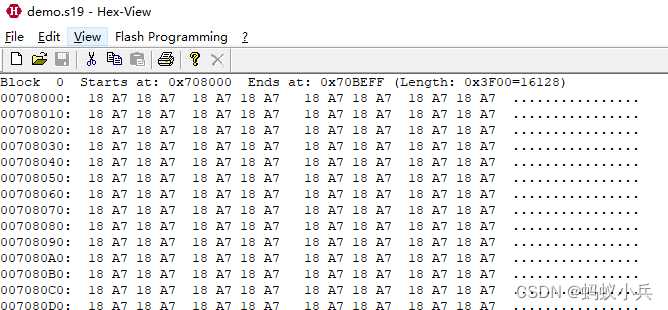
- HEX View 是一款专业的解析S19文件,HEX文件的工具,可以很方便的看出打开文件的Block块,起始地址和地址块的长度等信息
📙CAPL解析S19文件源码
- 核心变量解释下:
F_SegmentInfor[10]:用来存放解析S19文件的Block的信息,一般情况下,刷写文件的地址是不连续的,那么就会分成几个Block块,每个Block块我们要记录下该Block的起止地址,数据大小,因为这是我们UDS 34服务下载的必须数据,这里定义数组大小为10,足够大了,具体有多少个Block块,由变量SegCounter记录FlsData_BufferArr[0x1FFFFFF]: 这个数组是记录是s19文件的所有字节,数组大小可由刷写文件具体大小设置,因为这个数组存放的是所有Block块的数据,那么当我下载的时候我怎么区分,去取数据呢,那就是 上面说的结构体中的dword data_offset;这个变量来控制的,AllDataBytes:该文件所有的数据字节数。- 我为什么没有这样定义 结构体呢?这样分段信息不是更加明确,刷写时取数据也更加方便直观吗?想一想为什么? struct FlsData_Segment
{
byte seg_index;
dword start_address;
dword data_size;
byte FlsData_BufferArr[0x1FFFFFF];
} F_SegmentInfor[10];//暂时定数组为10
/*@!Encoding:936*/
variables
{
dword fileHandle;
const dword text_module = 0;
const dword binary_module = 1;
enum File_Type { file_header, file_data,file_tail };
struct FlsData_Segment
{
byte seg_index;
dword start_address;
dword data_size;
dword data_offset;
} F_SegmentInfor[10];//暂时定数组为10
long SegCounter; //记录文件被分成多少个段
long AllDataBytes; // 文件所有的数据字节数
byte FlsData_BufferArr[0x1FFFFFF]; //文件中的所有字节被解析后放在该数组
}
on key 'a'
{
Flash_Parse_S19("E:\\demo.s19");
}
long Flash_Parse_S19(char f_path[])
{
long i;
char tmpBuffer[5000];
char temStr[255];
byte AddressSize; // s19文件的地址占多少个字节,S1是2个;S2是3个;S3是4个
dword DataSize_PerLine_0; // 两个地址之间的插值,是个固定值,比如0x20
dword DataSize_PerLine_1; // 每行数据的第2-3,两个字节,是改行的数据长度(包含地址,数据,和校验)
dword DataSize_PerLine_2; // 每行纯数据段的长度
byte RawData_Line[255]; // 解析后每行数据内容
dword FlsData_CurrentAddress;
dword FlsData_PreviousAddress;
long file_line_num; // 文件有多少行
long SegmentDataSize; //记录当前段的字节数,临时变量
/*初始化变量*/
file_line_num = 0;
SegCounter = 0;
AllDataBytes = 0;
SegmentDataSize = 0;
FlsData_CurrentAddress = 0x00000000;
fileHandle = OpenFileRead(f_path,text_module);
if (fileHandle == 0 )
{
write("Failed to open File %s !",f_path);
return 0 ;
}
write("File:%s Opened",f_path);
while ( fileGetString(tmpBuffer,elcount(tmpBuffer),fileHandle) != 0)
{
file_line_num++; //数据行计数器
if(S19_Record_Type(tmpBuffer[1],AddressSize) == file_header)
{
write("文件头数据:%s",tmpBuffer);
}
else if(S19_Record_Type(tmpBuffer[1],AddressSize) == file_data)
{
FlsData_PreviousAddress = FlsData_CurrentAddress;
substr_cpy_off(temStr, 0, tmpBuffer, 2, 2, elcount(tmpBuffer)); // 截取字符串,取出数据长度
snprintf(temStr, elcount(temStr), "0x%s",temStr);
strtoul(temStr,DataSize_PerLine_1); //将数据长度 字符串转为数值
substr_cpy_off(temStr, 0, tmpBuffer, 4, AddressSize, elcount(tmpBuffer)); // 截取字符串,取出当前行的地址
snprintf(temStr, elcount(temStr), "0x%s",temStr);
strtoul(temStr,FlsData_CurrentAddress); //将当前行的地址 字符串转为数值
if (file_line_num == 2) //只执行一次,获取S19文件 第一段的刷写地址,和数据长度
{
DataSize_PerLine_0 = DataSize_PerLine_1; //DataSize_PerLine_0 是标准数据长度,DataSize_PerLine_1最后一行数据可能不等于标准数据长度
F_SegmentInfor[SegCounter].start_address = FlsData_CurrentAddress;
F_SegmentInfor[SegCounter].data_offset = 0;
}
//分段处理
if(((FlsData_CurrentAddress - FlsData_PreviousAddress) > DataSize_PerLine_0) && (FlsData_PreviousAddress != 0x00000000))
{
write("Previous Address:0x%2X,Current Addresses:0x%2X ",FlsData_PreviousAddress,FlsData_CurrentAddress);
F_SegmentInfor[SegCounter].data_size = SegmentDataSize; //上一段结束,保存上一段的字节数
SegCounter++;
F_SegmentInfor[SegCounter].start_address = FlsData_CurrentAddress; //保存下一段的首地址
F_SegmentInfor[SegCounter].data_offset += SegmentDataSize; //相对数组FlsData_BufferArr的开始索引地址
SegmentDataSize = 0; // 重置计数变量,为这一段字节计数准备
}
// DataSize_PerLine_0 - AddressSize -1 : Byte count: 一个字节,表示后面其余部分(地址+数据+校验和)的字节数
DataSize_PerLine_2 = DataSize_PerLine_1*2 - AddressSize - 2 ;
substr_cpy_off(temStr, 0, tmpBuffer, 4+AddressSize,DataSize_PerLine_2 , elcount(tmpBuffer)); // 截取字符串,取出当前行的数据
HexStrToByteArr(temStr,RawData_Line);
for(i=0;i<DataSize_PerLine_2/2;i++)
{
FlsData_BufferArr[AllDataBytes] = RawData_Line[i];
AllDataBytes ++ ;
SegmentDataSize ++ ;
}
}
else if(S19_Record_Type(tmpBuffer[1],AddressSize) == file_tail)
{
write("文件尾数据:%s\n",tmpBuffer);
//最后一段的数据长度
F_SegmentInfor[SegCounter].data_size = SegmentDataSize;
F_SegmentInfor[SegCounter].data_offset = AllDataBytes - SegmentDataSize; //相对数组FlsData_BufferArr的开始索引地址
fileClose(fileHandle);
SegCounter++;
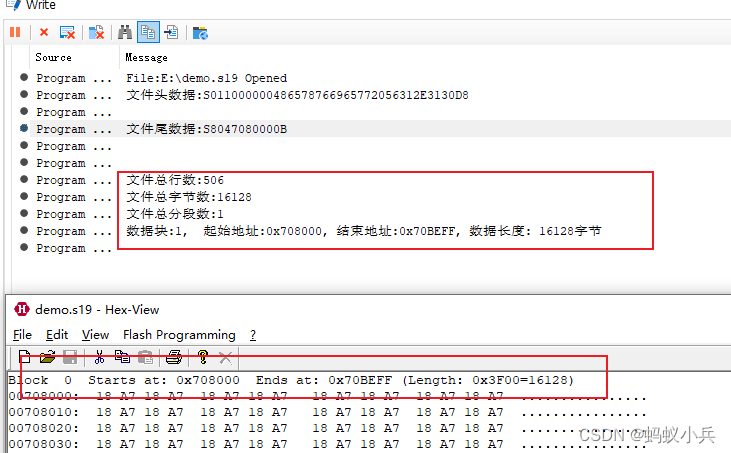
write("文件总行数:%d",file_line_num);
write("文件总字节数:%d",AllDataBytes);
write("文件总分段数:%d",SegCounter);
for(i = 0; i < SegCounter; i++)
{
write("数据块:%d, 起始地址:0x%X, 结束地址:0x%X, 数据长度:%6d字节\r\n", i+1, F_SegmentInfor[i].start_address, F_SegmentInfor[i].start_address + F_SegmentInfor[i].data_size - 1, F_SegmentInfor[i].data_size);
}
}
else
{
write("S19为定义格式!");
fileClose(fileHandle);
return 0 ;
}
}
return 1 ;
}
long S19_Record_Type(byte type ,byte &address_size)
{
if(type == '0') //s19文件的头部
{
return file_header;
}
else if((type == '7') || (type == '8') || (type == '9') ) //s19文件的结束
{
return file_tail;
}
else if((type == '1') || (type == '2') || (type == '3') ) //s19文件的数据
{
if(type== '1')
{
address_size = 4 ; //地址占 4个字节
}
else if(type == '2')
{
address_size = 6 ; //地址占6个字节
}
else if(type == '3')
{
address_size = 8 ; //地址占 8个字节
}
return file_data;
}
else
{
write("Not Defined!");
}
return -1;
}
byte HexStrToByteArr(char hexRawData[], byte outByteArr[])
{
word i;
word offset;
word hexLength;
word byteIndex;
byte tmpVal;
byte retVal;
for (i = 0; i < elcount(outByteArr); i++)
{
outByteArr[i] = 0;
}
// get the hex length
hexLength = elcount(hexRawData);
if( hexRawData[0] == '0' && hexRawData[1] == 'x' )
offset = 2;
else
offset = 0;
if ( elcount(outByteArr) < (hexLength - offset)/2 )
{
write("Out Arrary too Small.");
return 0;
}
else
{
//All checks went fine, convert data
for (i = offset; i < hexLength; i++)
{
// The byte index to use for accessing output array
byteIndex = (i - offset) / 2 ;
// convert the Hex data and validity check it
tmpVal = (byte)hexRawData[i];
if (tmpVal >= 0x30 && tmpVal <= 0x39)
tmpVal = tmpVal - 0x30;
else if(tmpVal >= 'A' && tmpVal <= 'F')
tmpVal = tmpVal - 0x37;
else if (tmpVal >= 'a' && tmpVal <= 'f')
tmpVal = tmpVal - 0x57;
else
{
return 0;
}
if (0 == (i % 2))
{
outByteArr[byteIndex] = tmpVal << 4;
}
else
{
outByteArr[byteIndex] = outByteArr[byteIndex] | tmpVal;
}
}
}
return 1;
}
- CAPL脚本跑出来的结果和HexView对比,结果一致,说明我们解析没问题

🌎总结

- 🍅 有需要演示中所用demo工程的,可以关注下方公众号网盘自取啦,感谢阅读。
- 🚩要有最朴素的生活,最遥远的梦想,即使明天天寒地冻,路遥马亡!
- 🚩如果这篇博客对你有帮助,请 “点赞” “评论”“收藏”一键三连 哦!码字不易,大家的支持就是我坚持下去的动力。