文章目录
- 前言
- 查询缓存
- 一级缓存
- 应用场景
- 生效的条件
- 测试
- 一级缓存原理
- 工作流程
- 源码分析
- 一级缓存总结
- 二级缓存
- 二级缓存配置
- 源码分析
- 为什么 MyBatis 默认不开启二级缓存?
前言
MyBatis是常见的Java数据库访问层框架。在日常工作中,开发人员多数情况下是使用MyBatis的默认缓存配置,但是MyBatis缓存机制有一些不足之处,在使用中容易引起脏数据,形成一些潜在的隐患。
查询缓存
Mybatis在进行查询数据时,提供查询缓存,用于减轻数据压力,提高数据库性能。
Mybaits提供一级缓存,和二级缓存。
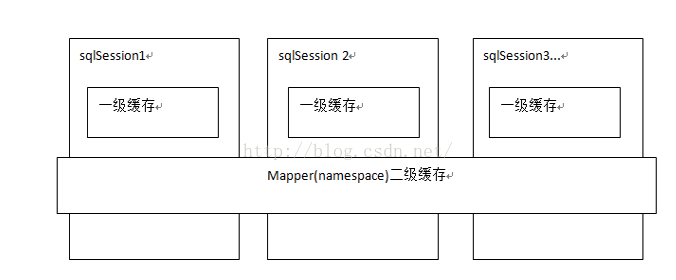
一级缓存
在应用运行过程中,我们有可能在一次数据库会话中,执行多次查询条件完全相同的SQL,MyBatis提供了一级缓存的方案优化这部分场景;
有两个选择SESSION或者STATEMENT,默认是SESSION级别,即在一个MyBatis会话中执行的所有语句,都会共享这一个缓存。一种是STATEMENT级别,可以理解为缓存只对当前执行的这一个Statement有效。
基于Mybatis中PerpetualCache的HashMap 本地缓存,其存储作用域为 SqlSession,当 Session flush 或close 之后,该 Session 中的所有 Cache 就将清空。
如果是相同的SQL语句,会优先命中一级缓存,避免直接对数据库进行查询,提高性能。具体执行过程如下图所示。
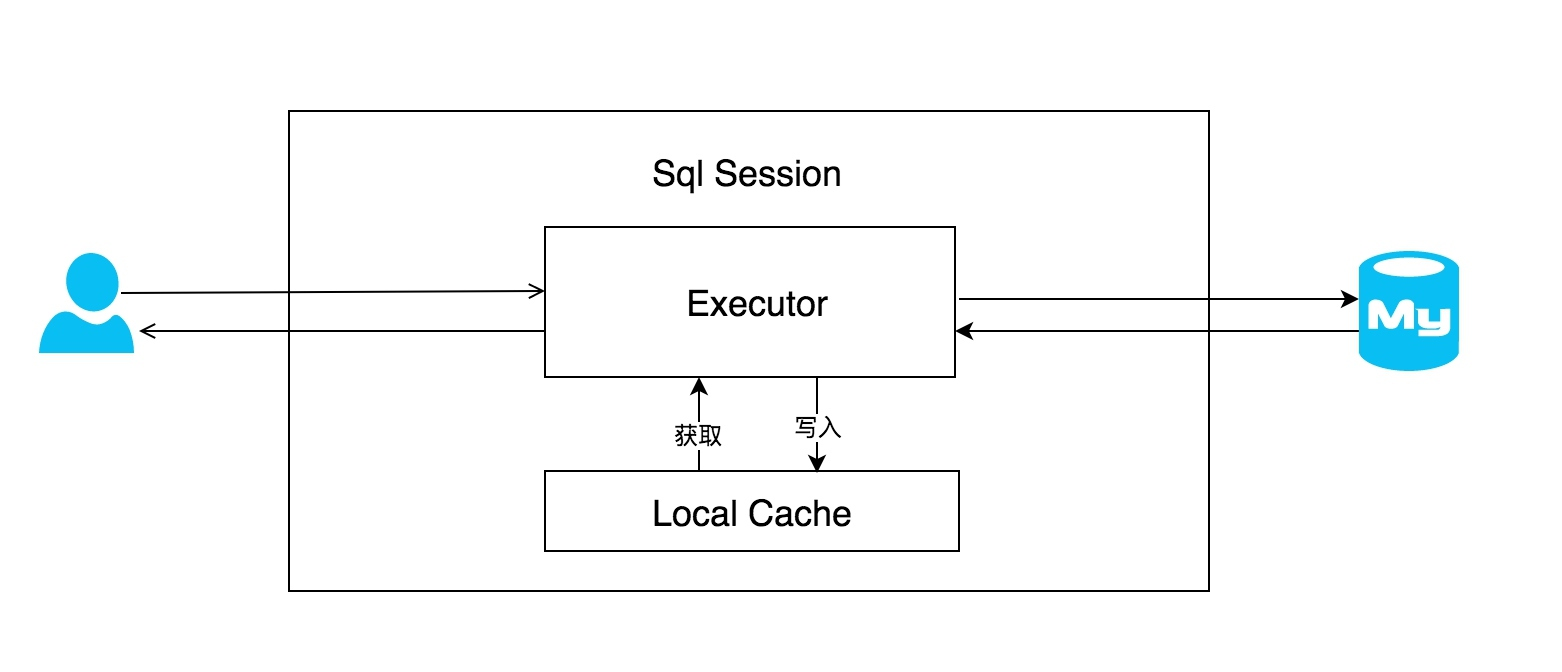
每个SqlSession中持有了Executor,每个Executor中有一个LocalCache。当用户发起查询时,MyBatis根据当前执行的语句生成MappedStatement,在Local Cache进行查询,如果缓存命中的话,直接返回结果给用户,如果缓存没有命中的话,查询数据库,结果写入Local Cache,最后返回结果给用户。具体实现类的类关系图如下图所示。
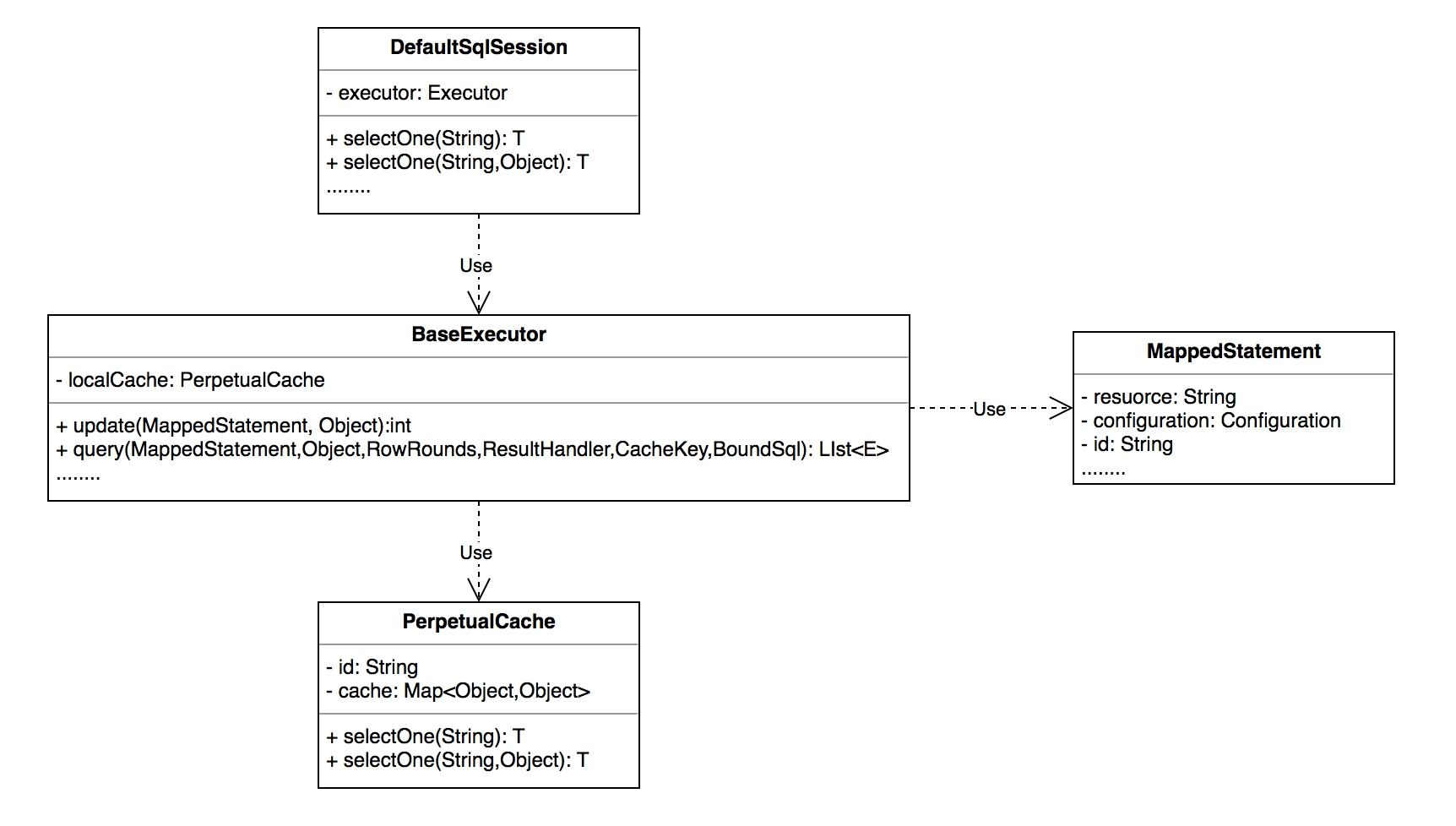
Spring Boot中默认会开启Mybatis的一级缓存。
应用场景
订单表与会员表是存在一对多的关系,为了尽可能减少 join 查询,进行了分阶段查询。即先查询出订单表,再根据 member_id 字段查询出会员表,最后进行数据整合。而如果订单表中存在重复的 member_id,就会出现很多重复查询。
针对这种情况,MyBatis 通过一级缓存来解决:在同一次查询会话(SqlSession)中如果出现相同的语句及参数,就会从缓存中取出,不再走数据库查询。
一级缓存只在数据库会话内部共享,所以也叫做会话缓存。
生效的条件
一级缓存要生效,必须满足以下条件条件:
- 必须是相同的会话
- 必须是同一个 mapper,即同一个 namespace
- 必须是相同的 statement,即同一个 mapper 中的同一个方法
- 必须是相同的 SQL 和参数
- 查询语句中间没有执行 session.clearCache() 方法
- 查询语句中间没有执行 insert/update/delete 方法(无论变动记录是否与缓存数据有无关系)
测试
@Test
void cacheTest() {
SdAiGroup aiGroup = sdAiGroupService.getById(1L);
SdAiGroup aiGroup2 = sdAiGroupService.getById(1L);
System.err.println(aiGroup == aiGroup2);
}
Creating a new SqlSession
SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@672549f3] was not registered for synchronization because synchronization is not active
JDBC Connection [HikariProxyConnection@728867118 wrapping com.mysql.cj.jdbc.ConnectionImpl@41c56930] will not be managed by Spring
==> Preparing: SELECT id,acos,budget_dynamic_status,campaign_name_sign,deleted,intention,num,num_type,profile_id,optimize_type,smart_creation_name,status,version,target_harvest_status,create_by,create_time,update_by,update_time,first_open_time,last_open_time,last_close_time FROM sd_ai_group WHERE id=? AND deleted=0
==> Parameters: 1(Long)
<== Columns: id, acos, budget_dynamic_status, campaign_name_sign, deleted, intention, num, num_type, profile_id, optimize_type, smart_creation_name, status, version, target_harvest_status, create_by, create_time, update_by, update_time, first_open_time, last_open_time, last_close_time
<== Row: 1, null, 0, 0, 0, consideration,awareness,defense, null, null, 4404871489220462, null, idun test9999, 0, 1, 0, 3562, 1664366059000, 3562, 1664366272000, 0, 0, 0
<== Total: 1
Closing non transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@672549f3]
==> 调用Mapper方法:
==> Object com.baomidou.mybatisplus.core.mapper.BaseMapper.selectById(Serializable)
==> 执行耗时:
==> 476毫秒
Creating a new SqlSession
SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@5c438795] was not registered for synchronization because synchronization is not active
JDBC Connection [HikariProxyConnection@994782211 wrapping com.mysql.cj.jdbc.ConnectionImpl@41c56930] will not be managed by Spring
==> Preparing: SELECT id,acos,budget_dynamic_status,campaign_name_sign,deleted,intention,num,num_type,profile_id,optimize_type,smart_creation_name,status,version,target_harvest_status,create_by,create_time,update_by,update_time,first_open_time,last_open_time,last_close_time FROM sd_ai_group WHERE id=? AND deleted=0
==> Parameters: 1(Long)
<== Columns: id, acos, budget_dynamic_status, campaign_name_sign, deleted, intention, num, num_type, profile_id, optimize_type, smart_creation_name, status, version, target_harvest_status, create_by, create_time, update_by, update_time, first_open_time, last_open_time, last_close_time
<== Row: 1, null, 0, 0, 0, consideration,awareness,defense, null, null, 4404871489220462, null, idun test9999, 0, 1, 0, 3562, 1664366059000, 3562, 1664366272000, 0, 0, 0
<== Total: 1
Closing non transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@5c438795]
==> 调用Mapper方法:
==> Object com.baomidou.mybatisplus.core.mapper.BaseMapper.selectById(Serializable)
==> 执行耗时:
==> 313毫秒
false
与 SpringBoot 集成时一级缓存不生效,原因:
因为一级缓存是会话级别的,要生效的话,必须要在同一个 SqlSession 中。但是与 SpringBoot 集成的 MyBatis,默认每次执行 SQL 语句时,都会创建一个新的 SqlSession!所以一级缓存才没有生效。
当调用 mapper 的方法时,最终会执行到 SqlSessionUtils 的 getSqlSession 方法,在这个方法中会尝试在事务管理器中获取 SqlSession,如果没有开启事务,那么就会 new 一个DefaultSqlSession。
即便在同一个方法中,通过同一个 mapper 连续调用两次相同的查询方法,也不会触发一级缓存。
MyBatis 在查询时,会先从事务管理器中尝试获取 SqlSession,取不到才会去创建新的SqlSession。所以可以猜测只要将方法开启事务,那么一级缓存就会生效。
加上 @Transactional 注解,看一下效果:
Creating a new SqlSession
Registering transaction synchronization for SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@516370c1]
JDBC Connection [HikariProxyConnection@59966374 wrapping com.mysql.cj.jdbc.ConnectionImpl@2d7df55] will be managed by Spring
==> Preparing: SELECT id,type,optimize_type,acos,budget_dynamic_status,num_type,num,campaign_name_sign,cvr,status,create_time,create_by,update_time,update_by,deleted,profile_id,del_unique_key,target_harvest_status,template_name FROM ai_rule_template WHERE id=? AND deleted=0
==> Parameters: 1(Long)
<== Total: 0
Releasing transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@516370c1]
==> 调用Mapper方法:
==> Object com.baomidou.mybatisplus.core.mapper.BaseMapper.selectById(Serializable)
==> 执行耗时:
==> 270毫秒
Fetched SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@516370c1] from current transaction
Releasing transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@516370c1]
==> 调用Mapper方法:
==> Object com.baomidou.mybatisplus.core.mapper.BaseMapper.selectById(Serializable)
==> 执行耗时:
==> 0毫秒
true
Transaction synchronization deregistering SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@516370c1]
Transaction synchronization closing SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@516370c1]
没错,的确生效了。在代码中可以看到,从事务管理器中,获取到了 SqlSession:
再看看源码中是什么时候将 SqlSession 设置到事务管理器中的。
SqlSessionUtils 中,在获取到 SqlSession 后,会调用 registerSessionHolder 方法注册 SessionHolder 到事务管理器:
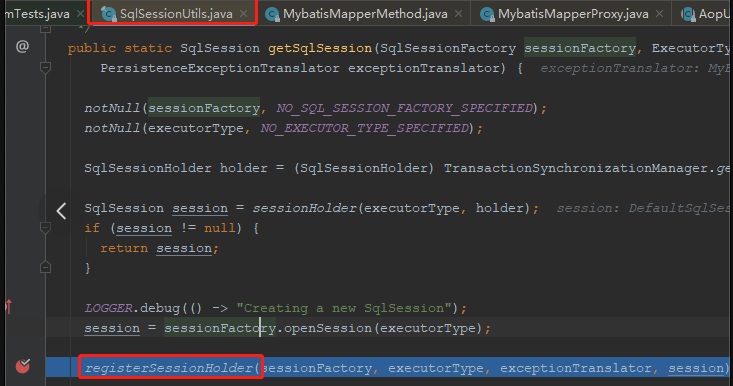
具体是在 TransactionSynchronizationManager 的 bindResource 方法中操作的,将 SessionHolder 保存到线程本地变量 (ThreadLocal) resources 中,这是每个线程独享的:

然后在下次查询时,就可以从这里取出此 SqlSession,使用同一个 SqlSession 查询,一级缓存就生效了。
所以基本原理就是:如果当前线程存在事物,并且存在相关会话,就从 ThreadLocal 中取出。如果没有事务,就重新创建一个 SqlSession 并存储到 ThreadLocal 当中,共下次查询使用。
至于缓存查询数据的地方,是在 BaseExecutor 中的 queryFromDatabase 方法中。执行 doQuery 从数据库中查询数据后,会立马缓存到 localCache(PerpetualCache类型) 中:
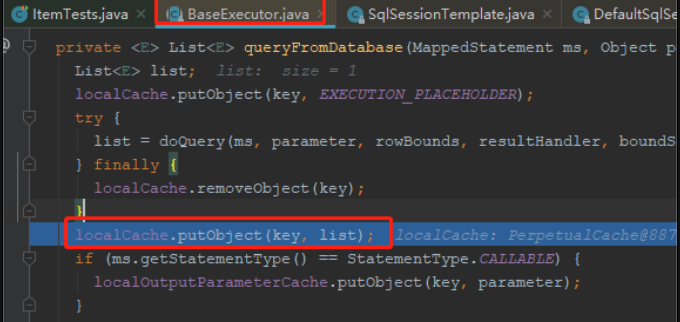
对数据库的修改操作,验证在一次数据库会话中,如果对数据库发生了修改操作,一级缓存是否会失效。
Creating a new SqlSession
Registering transaction synchronization for SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@671561b9]
JDBC Connection [HikariProxyConnection@31234171 wrapping com.mysql.cj.jdbc.ConnectionImpl@4f09d998] will be managed by Spring
==> Preparing: SELECT id,type,optimize_type,acos,budget_dynamic_status,num_type,num,campaign_name_sign,cvr,status,create_time,create_by,update_time,update_by,deleted,profile_id,del_unique_key,target_harvest_status,template_name FROM ai_rule_template WHERE id=? AND deleted=0
==> Parameters: 18616(Integer)
<== Columns: id, type, optimize_type, acos, budget_dynamic_status, num_type, num, campaign_name_sign, cvr, status, create_time, create_by, update_time, update_by, deleted, profile_id, del_unique_key, target_harvest_status, template_name
<== Row: 18616, sponsoredDisplay, 2, 15.00, 1, 1, 12.00, 0, 0.00, 1, 1698040341820, 3487, 1698227046378, 3487, 0, 4404871489220462, 0, 0, Test_lyw_智能优化模版01
<== Total: 1
Releasing transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@671561b9]
==> 调用Mapper方法:
==> Object com.baomidou.mybatisplus.core.mapper.BaseMapper.selectById(Serializable)
==> 执行耗时:
==> 241毫秒
Fetched SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@671561b9] from current transaction
==> Preparing: UPDATE ai_rule_template SET type=?, optimize_type=?, acos=?, budget_dynamic_status=?, num_type=?, num=?, campaign_name_sign=?, cvr=?, status=?, create_time=?, create_by=?, update_time=?, update_by=?, profile_id=?, del_unique_key=?, target_harvest_status=?, template_name=? WHERE id=? AND deleted=0
==> Parameters: sponsoredDisplay(String), 2(Integer), 15.0(Double), 1(Integer), 1(Integer), 12.0(Double), 0(Integer), 0.0(Double), 1(Integer), 1698040341820(Long), 3487(Integer), 1709792230487(Long), 3487(Integer), 4404871489220462(Long), 0(Integer), 0(Integer), Test_lyw_智能优化模版01(String), 18616(Integer)
<== Updates: 1
Releasing transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@671561b9]
==> 调用Mapper方法:
==> int com.baomidou.mybatisplus.core.mapper.BaseMapper.updateById(Object)
==> 执行耗时:
==> 348毫秒
Fetched SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@671561b9] from current transaction
==> Preparing: SELECT id,type,optimize_type,acos,budget_dynamic_status,num_type,num,campaign_name_sign,cvr,status,create_time,create_by,update_time,update_by,deleted,profile_id,del_unique_key,target_harvest_status,template_name FROM ai_rule_template WHERE id=? AND deleted=0
==> Parameters: 18616(Integer)
<== Columns: id, type, optimize_type, acos, budget_dynamic_status, num_type, num, campaign_name_sign, cvr, status, create_time, create_by, update_time, update_by, deleted, profile_id, del_unique_key, target_harvest_status, template_name
<== Row: 18616, sponsoredDisplay, 2, 15.00, 1, 1, 12.00, 0, 0.00, 1, 1698040341820, 3487, 1709792230487, 3487, 0, 4404871489220462, 0, 0, Test_lyw_智能优化模版01
<== Total: 1
Releasing transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@671561b9]
==> 调用Mapper方法:
==> Object com.baomidou.mybatisplus.core.mapper.BaseMapper.selectById(Serializable)
==> 执行耗时:
==> 199毫秒
false
Transaction synchronization deregistering SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@671561b9]
Transaction synchronization closing SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@671561b9]
我们可以看到,在修改操作后执行的相同查询,查询了数据库,一级缓存失效。
一级缓存原理
工作流程
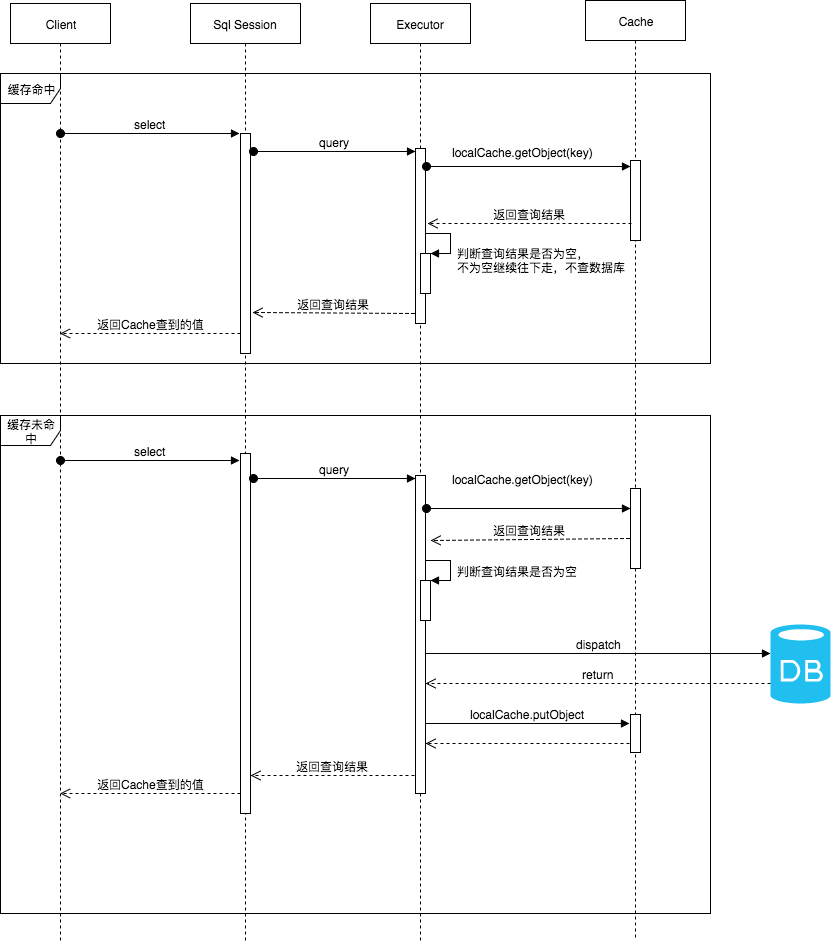
源码分析
SqlSession: 对外提供了用户和数据库之间交互需要的所有方法,隐藏了底层的细节。默认实现类是DefaultSqlSession。
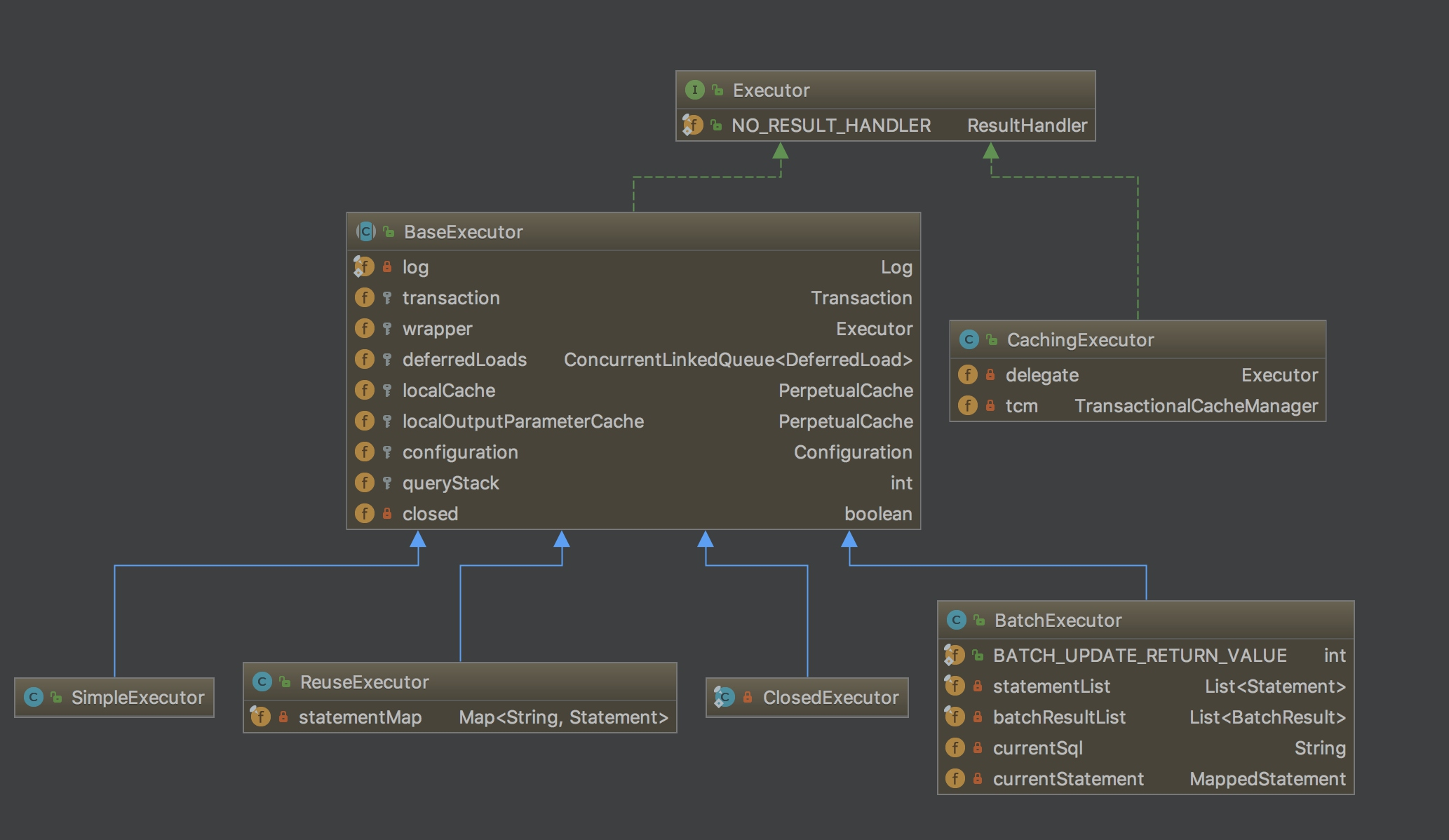
Executor: SqlSession向用户提供操作数据库的方法,但和数据库操作有关的职责都会委托给Executor,有若干个实现类,为Executor赋予了不同的能力,大家可以根据类名,自行学习每个类的基本作用。
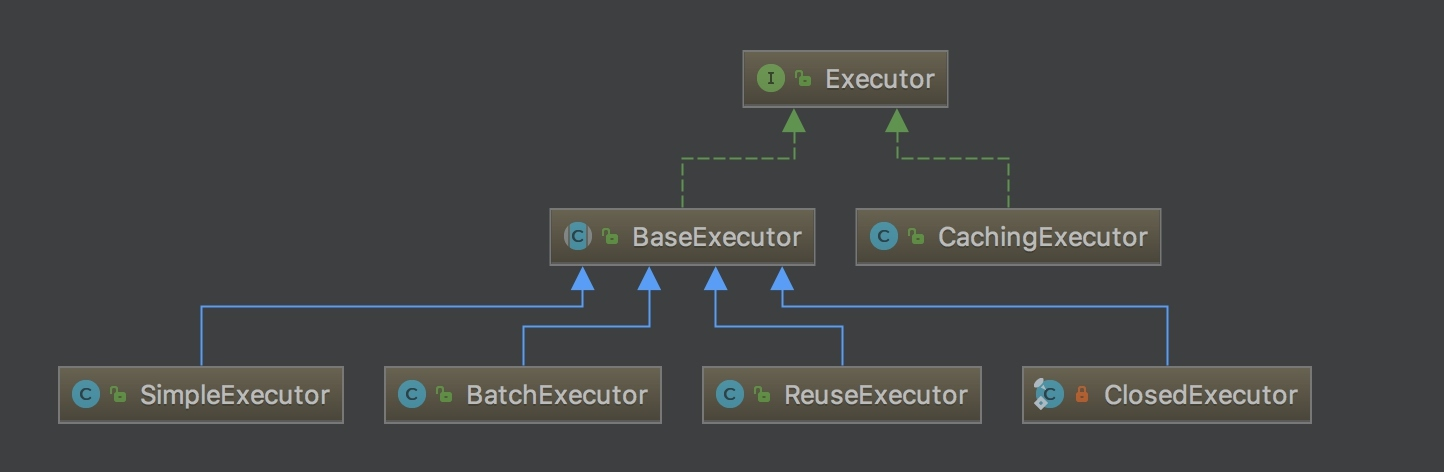
在一级缓存的源码分析中,主要学习BaseExecutor的内部实现。
BaseExecutor: BaseExecutor是一个实现了Executor接口的抽象类,定义若干抽象方法,在执行的时候,把具体的操作委托给子类进行执行。
protected abstract int doUpdate(MappedStatement ms, Object parameter) throws SQLException;
protected abstract List<BatchResult> doFlushStatements(boolean isRollback) throws SQLException;
protected abstract <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException;
protected abstract <E> Cursor<E> doQueryCursor(MappedStatement ms, Object parameter, RowBounds rowBounds, BoundSql boundSql) throws SQLException;
在一级缓存的介绍中提到对Local Cache的查询和写入是在Executor内部完成的。在阅读BaseExecutor的代码后发现Local Cache是BaseExecutor内部的一个成员变量,如下代码所示。
public abstract class BaseExecutorimplementsExecutor {
protected ConcurrentLinkedQueue<DeferredLoad> deferredLoads;
protected PerpetualCache localCache;
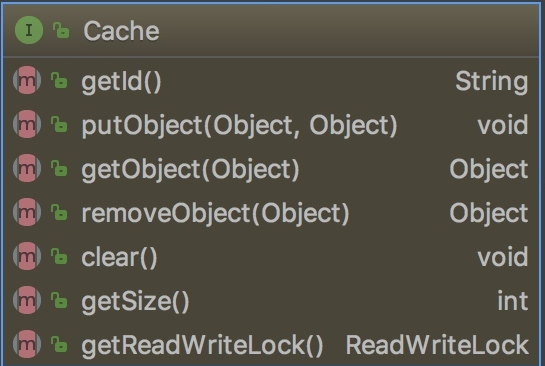
Cache: MyBatis中的Cache接口,提供了和缓存相关的最基本的操作,如下图所示:
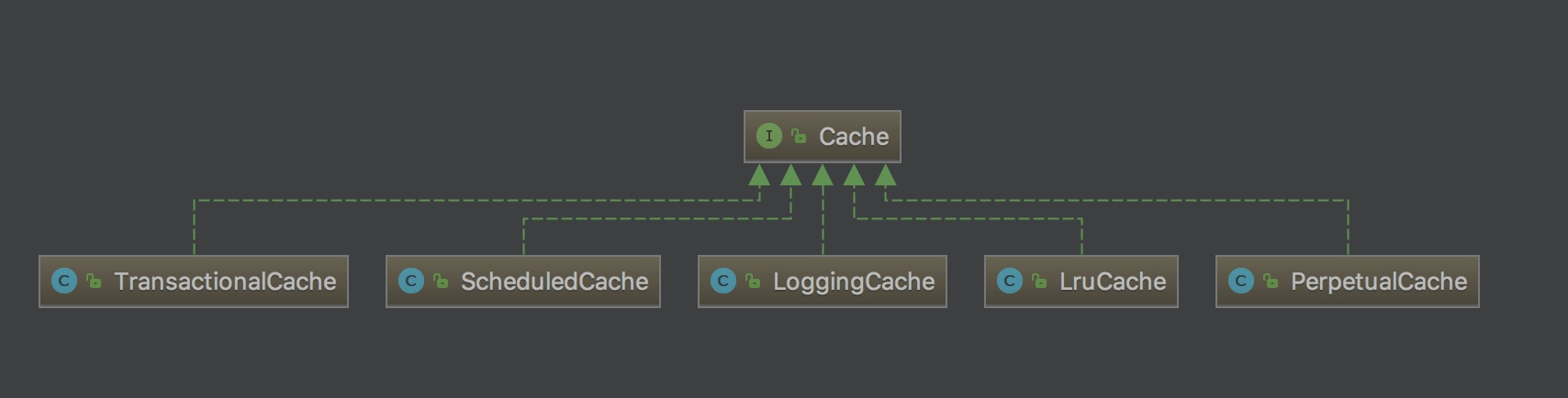
有若干个实现类,使用装饰器模式互相组装,提供丰富的操控缓存的能力,部分实现类如下图所示:
BaseExecutor成员变量之一的PerpetualCache,是对Cache接口最基本的实现,其实现非常简单,内部持有HashMap,对一级缓存的操作实则是对HashMap的操作。如下代码所示:
public class PerpetualCacheimplementsCache {
private String id;
private Map<Object, Object> cache =new HashMap<Object, Object>();
}
执行和数据库的交互,首先需要初始化SqlSession,通过DefaultSqlSessionFactory开启SqlSession:
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
............
final Executor executor = configuration.newExecutor(tx, execType);
return new DefaultSqlSession(configuration, executor, autoCommit);
}
在初始化SqlSesion时,会使用Configuration类创建一个全新的Executor,作为DefaultSqlSession构造函数的参数,创建Executor代码如下所示:
public ExecutornewExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType ==null ? defaultExecutorType : executorType;
executorType = executorType ==null ? ExecutorType.SIMPLE : executorType;
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor =new BatchExecutor(this, transaction);
}elseif (ExecutorType.REUSE == executorType) {
executor =new ReuseExecutor(this, transaction);
}else {
executor =new SimpleExecutor(this, transaction);
}
// 尤其可以注意这里,如果二级缓存开关开启的话,是使用CahingExecutor装饰BaseExecutor的子类if (cacheEnabled) {
executor =new CachingExecutor(executor);
}
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
SqlSession创建完毕后,根据Statment的不同类型,会进入SqlSession的不同方法中,如果是Select语句的话,最后会执行到SqlSession的selectList。
SqlSession把具体的查询职责委托给了Executor。如果只开启了一级缓存的话,首先会进入BaseExecutor的query方法。代码如下所示:
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler)throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameter);
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
在上述代码中,会先根据传入的参数生成CacheKey,进入该方法查看CacheKey是如何生成的,代码如下所示:
CacheKey cacheKey =new CacheKey();
cacheKey.update(ms.getId());
cacheKey.update(rowBounds.getOffset());
cacheKey.update(rowBounds.getLimit());
cacheKey.update(boundSql.getSql());
//后面是update了sql中带的参数
cacheKey.update(value);
在上述的代码中,将MappedStatement的Id、SQL的offset、SQL的limit、SQL本身以及SQL中的参数传入了CacheKey这个类,最终构成CacheKey。
除去hashcode、checksum和count的比较外,只要updatelist中的元素一一对应相等,那么就可以认为是CacheKey相等。只要两条SQL的下列五个值相同,即可以认为是相同的SQL。
Statement Id + Offset + Limit + Sql + Params
在源码分析的最后,我们确认一下,如果是insert/delete/update方法,缓存就会刷新的原因。
SqlSession的insert方法和delete方法,都会统一走update的流程,代码如下所示:
@Override
public int insert(String statement, Object parameter) {
return update(statement, parameter);
}
@Override
public int delete(String statement) {
return update(statement,null);
}
update方法也是委托给了Executor执行。BaseExecutor的执行方法如下所示:
@Override
public int update(MappedStatement ms, Object parameter)throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
clearLocalCache();
return doUpdate(ms, parameter);
}
每次执行update前都会清空localCache。
一级缓存总结
- MyBatis一级缓存的生命周期和SqlSession一致。
- MyBatis一级缓存内部设计简单,只是一个没有容量限定的HashMap,在缓存的功能性上有所欠缺。
- MyBatis的一级缓存最大范围是SqlSession内部,有多个SqlSession或者分布式的环境下,数据库写操作会引起脏数据,建议设定缓存级别为Statement。
二级缓存
在上文中提到的一级缓存中,其最大的共享范围就是一个SqlSession内部,如果多个SqlSession之间需要共享缓存,则需要使用到二级缓存。开启二级缓存后,会使用CachingExecutor装饰Executor,进入一级缓存的查询流程前,先在CachingExecutor进行二级缓存的查询,具体的工作流程如下所示。
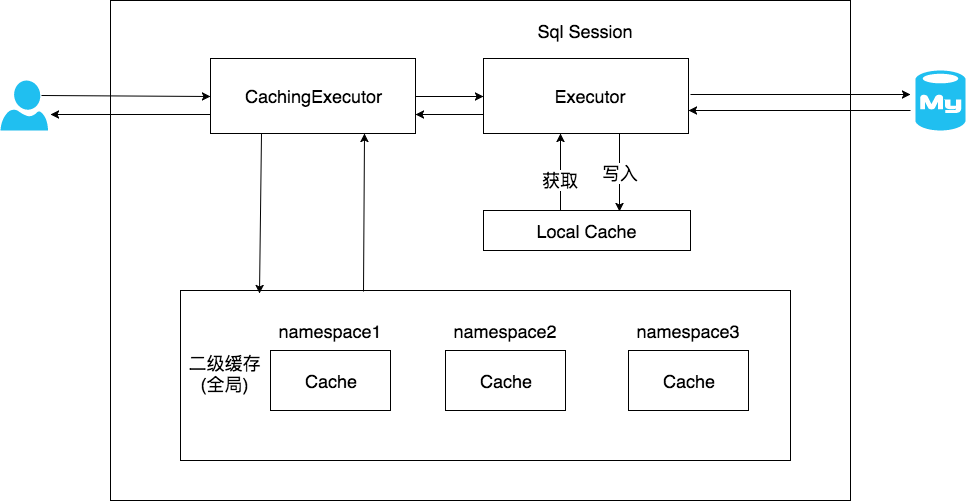
二级缓存开启后,同一个NameSpace下的所有操作语句,都影响着同一个Cache,即二级缓存被多个SqlSession共享,是一个全局的变量。
当开启缓存后,数据的查询执行的流程就是 二级缓存 -> 一级缓存 -> 数据库。
二级缓存配置
-
集成在Spring Boot中,配置如下:
# 总开关 开启mybatis的二级缓存 mybatis.configuration.cache-enabled=true -
在MyBatis的配置文件(SqlMapConfig.xml)中开启二级缓存。
<!-- 全局配置参数,需要时再设置 --> <settings> <!-- 开启二级缓存 默认值为true --> <setting name="cacheEnabled" value="true"></setting> </settings>
除了以上的总开关外,还要在具体的mapper.xml中开启二级缓存。
<mapper namespace="cn.hpu.mybatis.mapper.UserMapper">
<!-- 开启本mapper namespace下的二级缓存 -->
<cache eviction="LRU" flushInterval="100000" readOnly="true" size="1024"></cache>
</mapper>
eviction: 回收策略
- LRU 最近最少使用的,移除最长时间不被使用的对象,这是默认值
- FIFO 先进先出,按对象进入缓存的顺序来移除它们
- SOFT 软引用,移除基于垃圾回收器状态和软引用规则的对象
- WEAK 弱引用,更积极的移除基于垃圾收集器状态和弱引用规则的对象
flushInterval: 刷新间隔,以毫秒为单位,100000表示每100秒刷新一次缓存。不设置的话,则每次调用语句时刷新。
readOnly: 只读
属性可以被设置为true后者false。只读的缓存会给所有调用者返回缓存对象的相同实例,因此这些对象不能被修改,这提供了很重要的性能优势。可读写的缓存会通过序列化返回缓存对象的拷贝,这种方式会慢一些,但很安全,因此默认为false。
size: 可以被设置为任意的正整数,要记住缓存的对象数目和运行环境的可用内存资源数目,默认1024。
源码分析
MyBatis二级缓存的工作流程和前文提到的一级缓存类似,只是在一级缓存处理前,用CachingExecutor装饰了BaseExecutor的子类,在委托具体职责给delegate之前,实现了二级缓存的查询和写入功能。
CachingExecutor的query方法,首先会从MappedStatement中获得在配置初始化时赋予的Cache。
本质上是装饰器模式的使用:SynchronizedCache -> LoggingCache -> SerializedCache -> LruCache -> PerpetualCache。
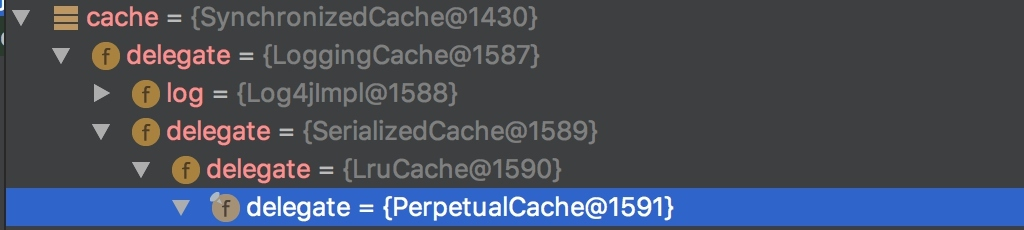
以下是具体这些Cache实现类的介绍,他们的组合为Cache赋予了不同的能力。
SynchronizedCache:同步Cache,实现比较简单,直接使用synchronized修饰方法。LoggingCache:日志功能,装饰类,用于记录缓存的命中率,如果开启了DEBUG模式,则会输出命中率日志。SerializedCache:序列化功能,将值序列化后存到缓存中。该功能用于缓存返回一份实例的Copy,用于保存线程安全。LruCache:采用了Lru算法的Cache实现,移除最近最少使用的Key/Value。PerpetualCache: 作为为最基础的缓存类,底层实现比较简单,直接使用了HashMap。
在默认的设置中SELECT语句不会刷新缓存,insert/update/delte会刷新缓存。进入该方法。代码如下所示:
private void flushCacheIfRequired(MappedStatement ms) {
Cache cache = ms.getCache();
if (cache !=null && ms.isFlushCacheRequired()) {
tcm.clear(cache);
}
}
MyBatis的CachingExecutor持有了TransactionalCacheManager,即上述代码中的tcm。
TransactionalCacheManager中持有了一个Map,代码如下所示:
private Map<Cache, TransactionalCache> transactionalCaches =new HashMap<Cache, TransactionalCache>();
这个Map保存了Cache和用TransactionalCache包装后的Cache的映射关系。
TransactionalCache实现了Cache接口,CachingExecutor会默认使用他包装初始生成的Cache,作用是如果事务提交,对缓存的操作才会生效,如果事务回滚或者不提交事务,则不对缓存产生影响。
在TransactionalCache的clear,有以下两句。清空了需要在提交时加入缓存的列表,同时设定提交时清空缓存,代码如下所示:
@Override
public void clear() {
clearOnCommit = true;
entriesToAddOnCommit.clear();
}
CachingExecutor继续往下走,ensureNoOutParams主要是用来处理存储过程的,暂时不用考虑。
if (ms.isUseCache() && resultHandler ==null) {
ensureNoOutParams(ms, parameterObject, boundSql);
之后会尝试从tcm中获取缓存的列表。
List<E> list = (List<E>) tcm.getObject(cache, key);
在getObject方法中,会把获取值的职责一路传递,最终到PerpetualCache。如果没有查到,会把key加入Miss集合,这个主要是为了统计命中率。
Object object = delegate.getObject(key);
if (object ==null) {
entriesMissedInCache.add(key);
}
CachingExecutor继续往下走,如果查询到数据,则调用tcm.putObject方法,往缓存中放入值。
if (list ==null) {
list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list);// issue #578 and #116
}
tcm的put方法也不是直接操作缓存,只是在把这次的数据和key放入待提交的Map中。
@Override
public void putObject(Object key, Object object) {
entriesToAddOnCommit.put(key, object);
}
从以上的代码分析中,我们可以明白,如果不调用commit方法的话,由于TranscationalCache的作用,并不会对二级缓存造成直接的影响。因此我们看看Sqlsession的commit方法中做了什么。代码如下所示:
@Override
public void commit(boolean force) {
try {
executor.commit(isCommitOrRollbackRequired(force));
因为我们使用了CachingExecutor,首先会进入CachingExecutor实现的commit方法。
@Override
public void commit(boolean required)throws SQLException {
delegate.commit(required);
tcm.commit();
}
会把具体commit的职责委托给包装的Executor。主要是看下tcm.commit(),tcm最终又会调用到TrancationalCache。
public void commit() {
if (clearOnCommit) {
delegate.clear();
}
flushPendingEntries();
reset();
}
看到这里的clearOnCommit就想起刚才TrancationalCache的clear方法设置的标志位,真正的清理Cache是放到这里来进行的。具体清理的职责委托给了包装的Cache类。之后进入flushPendingEntries方法。代码如下所示:
private void flushPendingEntries() {
for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) {
delegate.putObject(entry.getKey(), entry.getValue());
}
}
在flushPendingEntries中,将待提交的Map进行循环处理,委托给包装的Cache类,进行putObject的操作。
后续的查询操作会重复执行这套流程。如果是insert|update|delete的话,会统一进入CachingExecutor的update方法,其中调用了这个函数,代码如下所示:
private void flushCacheIfRequired(MappedStatement ms)
在二级缓存执行流程后就会进入一级缓存的执行流程。
- MyBatis的二级缓存相对于一级缓存来说,实现了
SqlSession之间缓存数据的共享,同时粒度更加的细,能够到namespace级别,通过Cache接口实现类不同的组合,对Cache的可控性也更强。 - MyBatis在多表查询时,极大可能会出现脏数据,有设计上的缺陷,安全使用二级缓存的条件比较苛刻。
- 在分布式环境下,由于默认的MyBatis Cache实现都是基于本地的,分布式环境下必然会出现读取到脏数据,需要使用集中式缓存将MyBatis的Cache接口实现,有一定的开发成本,直接使用Redis、Memcached等分布式缓存可能成本更低,安全性也更高。
为什么 MyBatis 默认不开启二级缓存?
答案就是,不推荐使用二级缓存!
二级缓存虽然能带来一定的好处,但是有很大的隐藏危害!
-
它的缓存是以
namespace(mapper)为单位的,不同namespace下的操作互不影响。且insert/update/delete操作会清空所在namespace下的全部缓存。那么问题就出来了,假设现在有
ItemMapper以及XxxMapper,在XxxMapper中做了表关联查询,且做了二级缓存。此时在ItemMapper中将 item 信息给删了,由于不同namespace下的操作互不影响,XxxMapper的二级缓存不会变,那之后再次通过XxxMapper查询的数据就不对了,非常危险。 -
二级缓存与一级缓存其机制相同,默认也是采用
PerpetualCache,HashMap存储,不同在于其存储作用域为Mapper(Namespace),并且可自定义存储源,如Ehcache。作用域为namespance是指对该namespance对应的配置文件中所有的 select 操作结果都缓存,这样不同线程之间就可以共用二级缓存。启动二级缓存:在 mapper 配置文件中:<cache ></cache>。二级缓存可以设置返回的缓存对象策略:<cache readOnly="true">。当 readOnly="true"时,表示二级缓存返回给所有调用者同一个缓存对象实例,调用者可以 update 获取的缓存实例,但是这样可能会造成其他调用者出现数据不一致的情况(因为所有调用者调用的是同一个实例)。当 readOnly="false"时,返回给调用者的是二级缓存总缓存对象的拷贝,即不同调用者获取的是缓存对象不同的实例,这样调用者对各自的缓存对象的修改不会影响到其他的调用者,即是安全的,所以默认是 readOnly=“false”; -
对于缓存数据更新机制,当某一个作用域(一级缓存 Session/二级缓存 Namespaces)的进行了 C/U/D 操作后,默认该作用域下所有 select 中的缓存将被 clear。
本文作者:Java技术债务
原文链接:https://cuizb.top/myblog/article/detail/1712832377
版权声明: 本博客所有文章除特别声明外,均采用 CC BY 3.0 CN协议进行许可。转载请署名作者且注明文章出处。