原生的ES打分基于BM25算法,相比于TF-IDF已经有了较大的改进,但是在实际场景中往往最终的排序效果还是需要进行调整。由于直接修改索引的权重往往代价较大,比较经济的方式还是在查询时即时修改得分以实现排序控制。
注:案例测试数据详见:ElasticSearch中使用bge-large-zh-v1.5进行向量检索(一)-CSDN博客 中的第三部分。
场景一:negative_boost
适用场景:想降低某些关键词的检索权重,但这些文档往往又包含我们想命中的关键词,直接去掉也不合适,只能把排名降低。
例如,针对以下case,我们想搜包含“新疆”的文档:
GET article/_search
{
"query": {
"match": {
"title": "新疆"
}
}
}直出的结果为:

编号002的在003前面。
假设我们的需求是想让出现“中欧”关键词的文档相关度降低,则可以使用negative_boost:
GET article/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"title": "新疆"
}
},
"negative": {
"match": {
"title": "中欧"
}
},
"negative_boost": 0.5
}
}
}效果:

调整后编号003的在002的前面,因为标题包含“中欧”的文档的分值乘以了negative_boost(0.5)后被降低了。
场景二:script_score
适用场景:利用索引数据中既有的一些数值字段细粒度控制打分函数。有些索引中本来就有可以用来排名的字段(比如点赞数,阅读数,评论数等等)。
还是上文的案例,默认情况下搜“新疆”,文档002在003之前,但很明显,文档003的阅读量(readNumber)更高,我们想让其排在前面。可以使用如下的查询:
GET article/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "新疆"
}
},
"script_score": {
"script": {
"source": "_score * (doc['readNumber'].value)"
}
}
}
}
}注意script_score要写在function_score里,其中_score * (doc['readNumber'].value)的意思是:将原始的打分乘以readNumber(阅读量)字段的值作为最终的打分。
最终效果如下:

场景三:field_value_factor
适用场景:和script_score类似,更注重打分平滑性。
还是上文的案例,默认情况下搜“新疆”,文档002在003之前,但很明显,文档003的阅读量(readNumber)更高,我们想让其排在前面。可以使用如下的查询:
GET article/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "新疆"
}
},
"field_value_factor": {
"field": "readNumber",
"modifier": "log1p",
"factor": 2,
"missing": 1
},
"boost_mode": "multiply"
}
}
}field_value_factor的含义:
field:待计算的字段
modifier:打分函数
factor:field计算时乘以的因子
missing:缺失值
boost_mode:和原始打分_score的结合方式。分 sum / avg / multiply / max / min / replace
上述语句的含义等于:
新分数=原分数 * log(1 + 2 * readNumber)
效果如下:
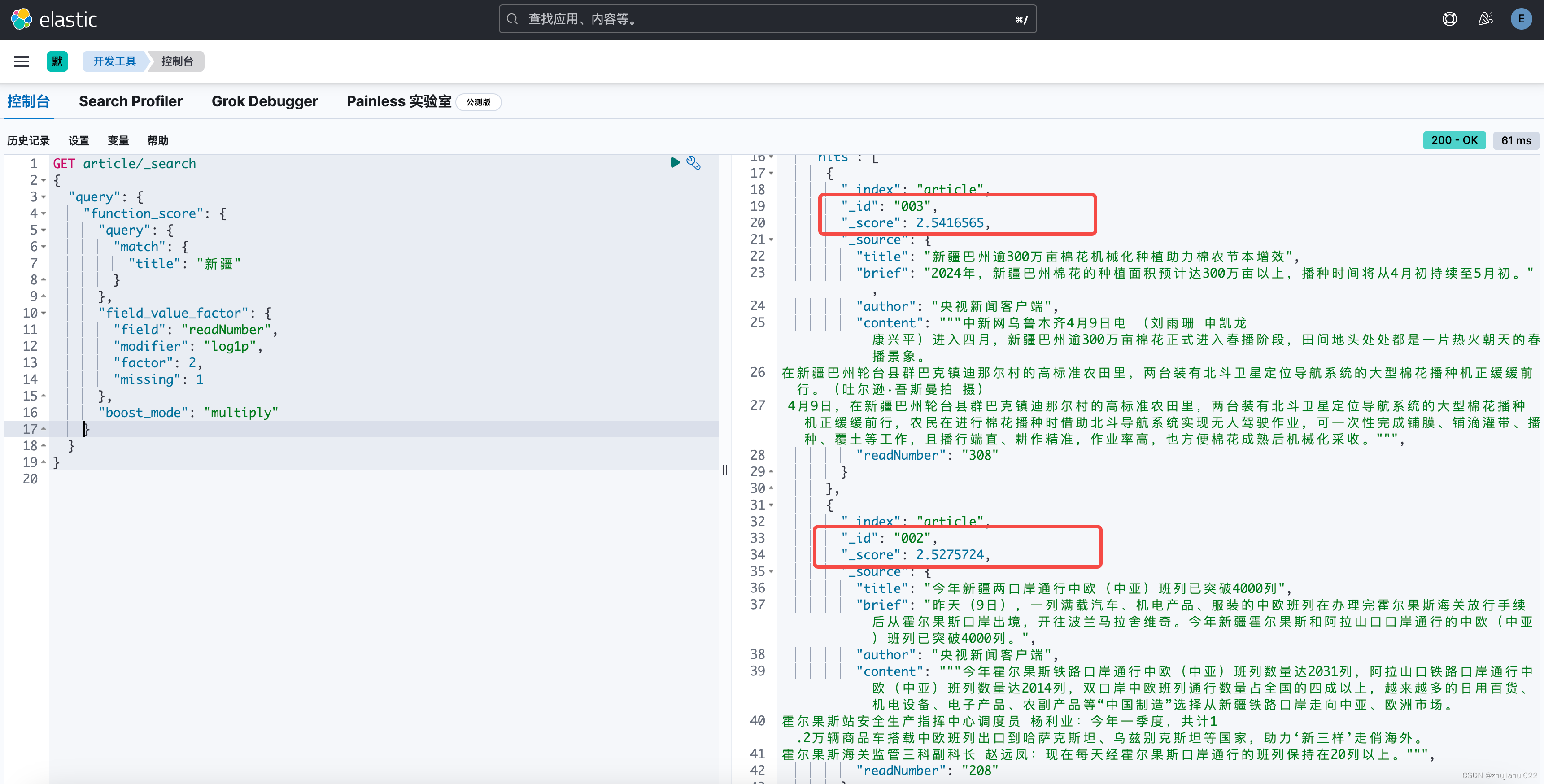
优势是得分相对比较光滑,比较接近。