文章目录
- 前言
- 一、OpenAI大模型
- 二、LangChain开发框架
- 三、RAGA评估框架
- 四、GLM大模型
- 五、搜索服务
- 1. Tavily Search API
- 六、文本LLM大模型
- 七、多模态LLM模型
- 八、模型排行榜
- 1.大模型评测体系(司南OpenCompass)
- 2.大模型排行榜(DataLearner AI)
- 3.CLiB中文大模型能力评测榜单
- 4.Embeddings模型排行榜
前言
本文的核心目的在于梳理和汇编大型模型开发领域内的相关资料与资源。通过集中整理这些信息,为后续大模型语言应用开发实践提供一个便捷的知识库和参考入口。
一、OpenAI大模型
官网地址:https://platform.openai.com/docs/introduction
中文文档地址:https://www.openaidoc.com.cn/docs/introduction (没有官网更新那么及时)
github源码地址:https://github.com/openai/openai-cookbook

二、LangChain开发框架
LangChain是一个为开发者设计的框架,用于构建由大型语言模型(LLM)驱动的端到端应用程序。
Langchain官网:https://python.langchain.com/docs/get_started/introduction
Langchain中文网:http://docs.autoinfra.cn/
LangSmith地址:https://smith.langchain.com/
github源码地址:https://github.com/langchain-ai/langchain
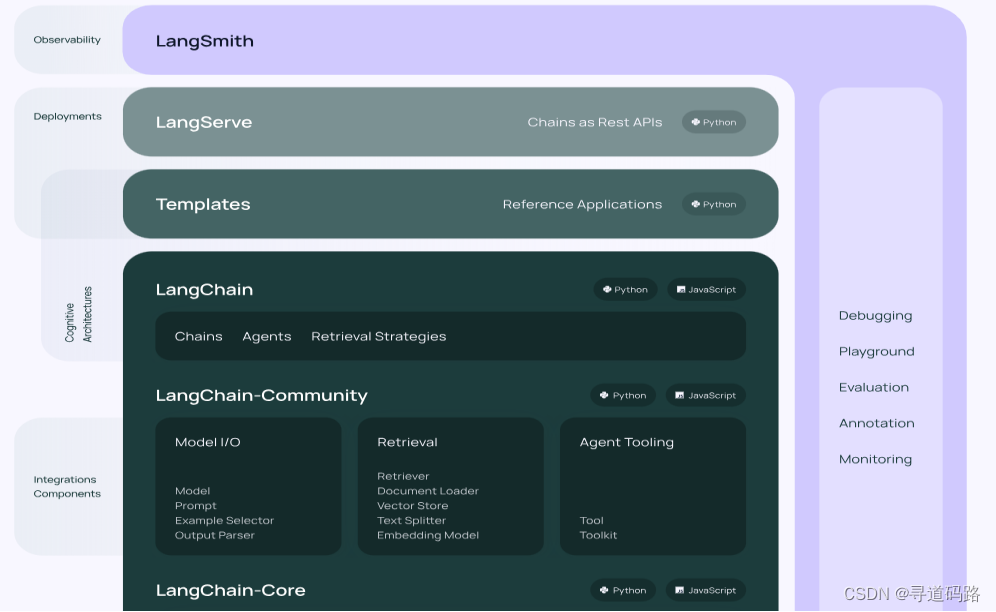
三、RAGA评估框架
官网地址:https://docs.ragas.io/en/latest/getstarted/index.html
RAGA评估框架是一种自动化评估工具,它旨在评估检索增强生成模型(Retrieval Augmented Generation Models)的质量。这种类型的模型通常包括两个主要组件:一个检索系统和一个语言模型。检索系统负责从大量文本中找出与给定问题最相关的信息,而语言模型则利用这些信息来生成答案。RAGA评估框架关注的是这两个组件的协同工作能力,以及它们共同产生的结果的质量。
四、GLM大模型
由清华智谱研发的一个开源的、高性能中英双语对话语言模型。
1) github仓库地址:https://github.com/THUDM/ChatGLM3
2) huggingface上的预训练模型下载地址:https://huggingface.co/THUDM/chatglm3-6b
3)嵌入模型:https://huggingface.co/BAAI/bge-large-zh-v1.5
其他常用的中文嵌入模型text2vec-base-chinese
https://huggingface.co/shibing624/text2vec-base-chinese
备注:也可在gitee上下载huggingface的模型: https://gitee.com/hf-models
五、搜索服务
1. Tavily Search API
官网地址:https://tavily.com/
Tavily Search API被设计成一个专门为AI代理服务的搜索引擎。它旨在提供一个可扩展、易于集成、并且能够满足AI代理特定需求的搜索API,使得AI代理能够更加高效地获取精确、相关的在线信息。这样的API可以帮助AI代理更好地理解和响应用户的查询,提供更加准确和个性化的结果。
六、文本LLM大模型
1)ChatGLM:
地址::https://github.com/THUDM/ChatGLM3
ChatGLM是中文领域效果最好的开源底座模型之一,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持
2)ChatGLM3-6B
地址https://github.com/THUDM/ChatGLM-6B
ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略;更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景;更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM3-6B-Base、长文本对话模型 ChatGLM3-6B-32K。以上所有权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
3)Qwen
地址:https://github.com/QwenLM/Qwen
通义千问 是阿里云研发的通义千问大模型系列模型,包括参数规模为18亿(1.8B)、70亿(7B)、140亿(14B)和720亿(72B)。各个规模的模型包括基础模型Qwen,即Qwen-1.8B、Qwen-7B、Qwen-14B、Qwen-72B,以及对话模型Qwen-Chat,即Qwen-1.8B-Chat、Qwen-7B-Chat、Qwen-14B-Chat和Qwen-72B-Chat。数据集包括文本和代码等多种数据类型,覆盖通用领域和专业领域,能支持8K的上下文长度,针对插件调用相关的对齐数据做了特定优化,当前模型能有效调用插件以及升级为Agent。
4)OpenChineseLLaMA:
地址:https://github.com/OpenLMLab/OpenChineseLLaMA
OpenChineseLLaMA基于 LLaMA-7B 经过中文数据集增量预训练产生的中文大语言模型基座,对比原版 LLaMA,该模型在中文理解能力和生成能力方面均获得较大提升,在众多下游任务中均取得了突出的成绩。
七、多模态LLM模型
1)CogVLM
地址:https://github.com/THUDM/CogVLM
CogVLM是一个强大的开源视觉语言模型(VLM)。CogVLM-17B 拥有 100 亿视觉参数和 70 亿语言参数。 CogVLM-17B 在 10 个经典跨模态基准测试上取得了 SOTA 性能。CogVLM 能够准确地描述图像,几乎不会出现幻觉。
2)Qwen-VL
地址:https://github.com/QwenLM/Qwen-VL
Qwen-VL是阿里云研发的大规模视觉语言模型,可以以图像、文本、检测框作为输入,并以文本和检测框作为输出。特点包括:强大的性能:在四大类多模态任务的标准英文测评中上均取得同等通用模型大小下最好效果;多语言对话模型:天然支持英文、中文等多语言对话,端到端支持图片里中英双语的长文本识别;多图交错对话:支持多图输入和比较,指定图片问答,多图文学创作等;
八、模型排行榜
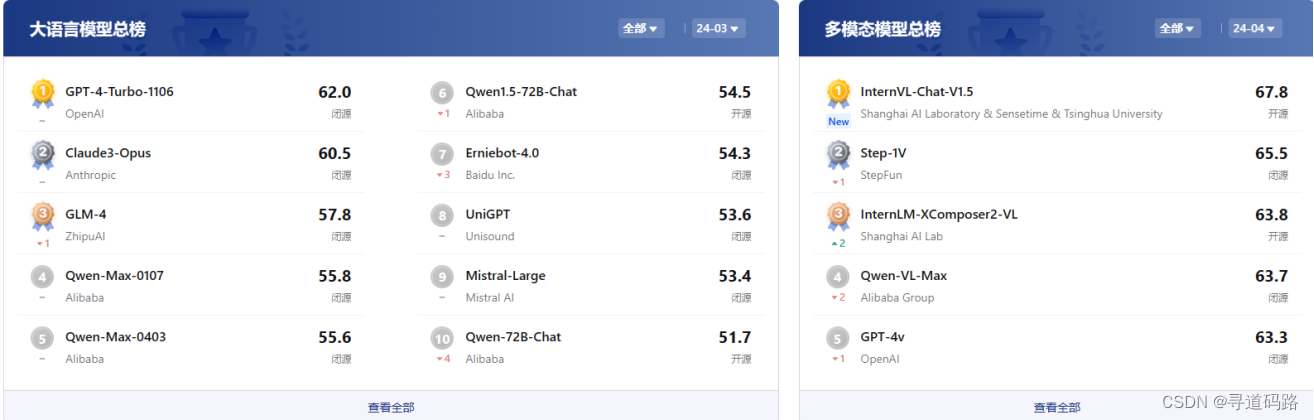
1.大模型评测体系(司南OpenCompass)
地址:https://rank.opencompass.org.cn/home
上海人工智能实验室正式发布大模型开源开放评测体系司南(OpenCompass2.0),旨在为大语言模型、多模态模型等各类模型提供一站式评测服务。
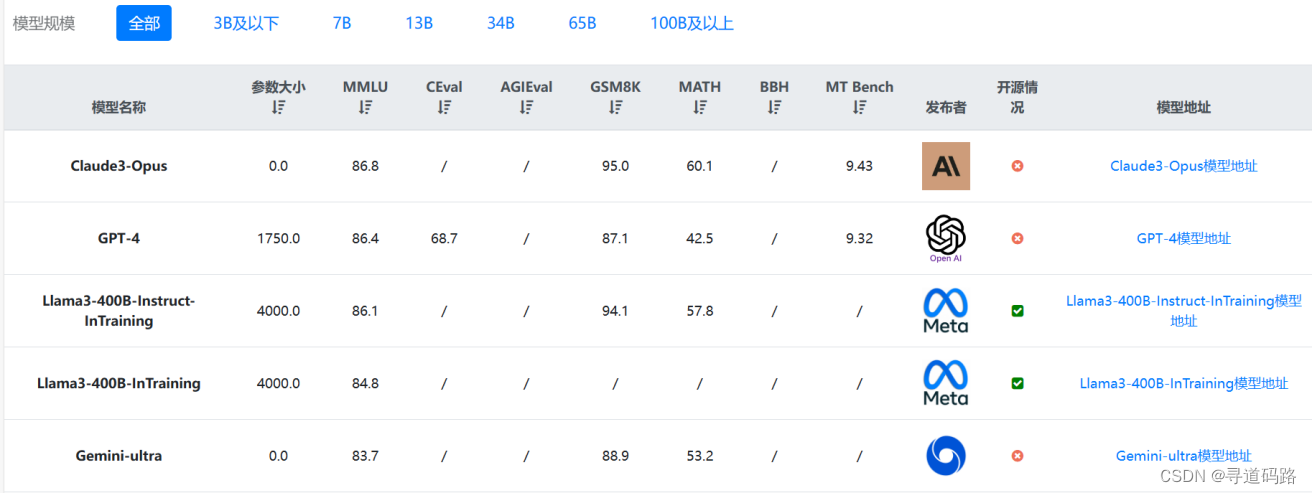
2.大模型排行榜(DataLearner AI)
地址:https://www.datalearner.com/ai-models/leaderboard/datalearner-llm-leaderboard
DataLearner AI 提供了最新的大模型排行榜、深入的大模型评测、丰富的大模型数据集,以及每日更新的人工智能与大模型相关的资讯
3.CLiB中文大模型能力评测榜单
地址:https://github.com/jeinlee1991/chinese-llm-benchmark?tab=readme-ov-file
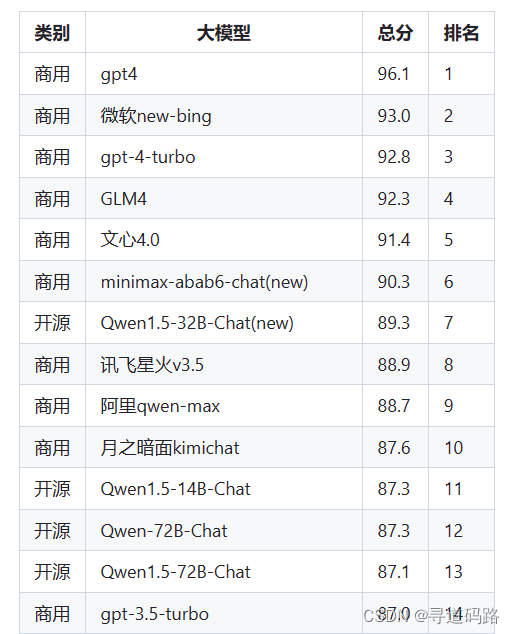
CLiB中文大模型能力评测榜单
目前已囊括77个大模型,覆盖chatgpt、gpt4、谷歌bard、百度文心一言、阿里通义千问、讯飞星火、360智脑、商汤senseChat、微软new-bing、minimax等商用模型, 以及百川、qwen、belle、chatglm6b、tigerbot、ziya、openbuddy、Phoenix、linly、MOSS、AquilaChat、vicuna、wizardLM、书生internLM、llama2-chat等开源大模型。综合能力排行榜:综合能力得分为分类能力、信息抽取能力、阅读理解能力、数据分析能力四者得分的平均值
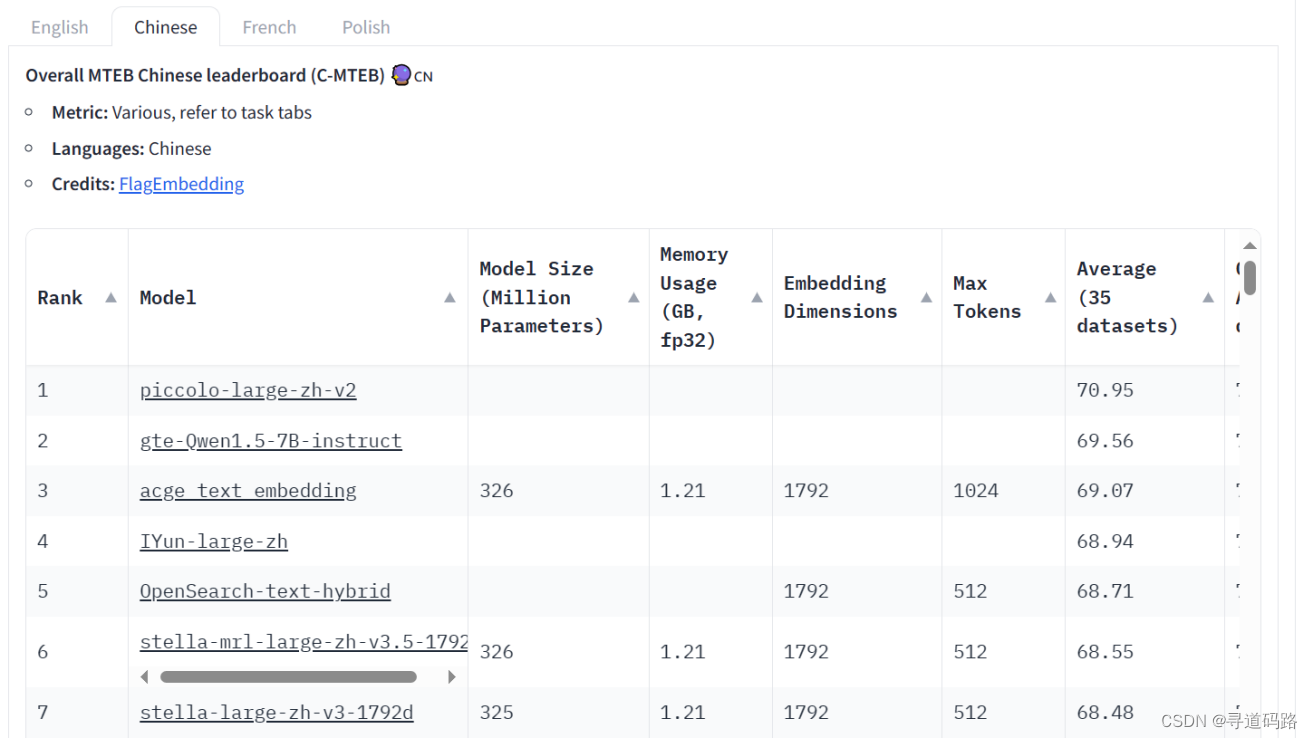
4.Embeddings模型排行榜
地址:https://huggingface.co/spaces/mteb/leaderboard
Huggingface上的mteb是一个海量Embeddings排行榜,定期会更新Huggingface开源的Embedding模型各项指标,进行一个综合的排名。
探索未知,分享所知;点击关注,码路同行,寻道人生!