1、什么是大模型
大型语言模型(Large Language Model,LLM;Large Language Models,LLMs)。
大语言模型是一种深度学习模型,特别是属于自然语言处理(NLP)的领域,一般是指包含数干亿(或更多)参数的语言模型,这些参数是在大量文本数据上训练的,例如模型GPT-3,Chatglm,PaLM,LLaMA等,大语言模型的目的是理解和生成自然语言,通过学习大量的文本数据来预测下一个词或生成与给定文本相关的内容。从实际应用表现来看,大语言模型具备回答各种问题、编写文章、编程、翻译等能力,如果深究其原理,LLM建立在Transformers架构之上,并在很大程度上扩展了模型的大小、预训练数据和总计算量。
参数可以被理解为模型学习任务所需要记住的信息,参数的数量通常与模型的复杂性和学习能力直接相关,更多的参数意味着模型可能具有更强的学习能力。
大模型其核心思想是根据已有的文本序列生成下一个最可能出现的单词。这一切都是基于统计学习和推理,而非像人类那样进行逻辑推理或思考

2、Transformers架构
我们对LLM这样的聊天模型可能已经习以为常,一问即答似乎很正常。然而,如果深入思考其背后的工作原理,你会发现这实际上是一件令人惊奇的事情。所以,我想让大家明确一个问题:究竟什么是Transformer,以及它是如何获得这种革命性的影响力的。
Transformer由编码器(Encoder) 和解码器(Decoder)组成,其中编码器用于学习输入序列的表示,解码器用于生成输出序列。 GPT主要采用了transformer的解码器部分,用于构建语言模型。其结构是这样的:
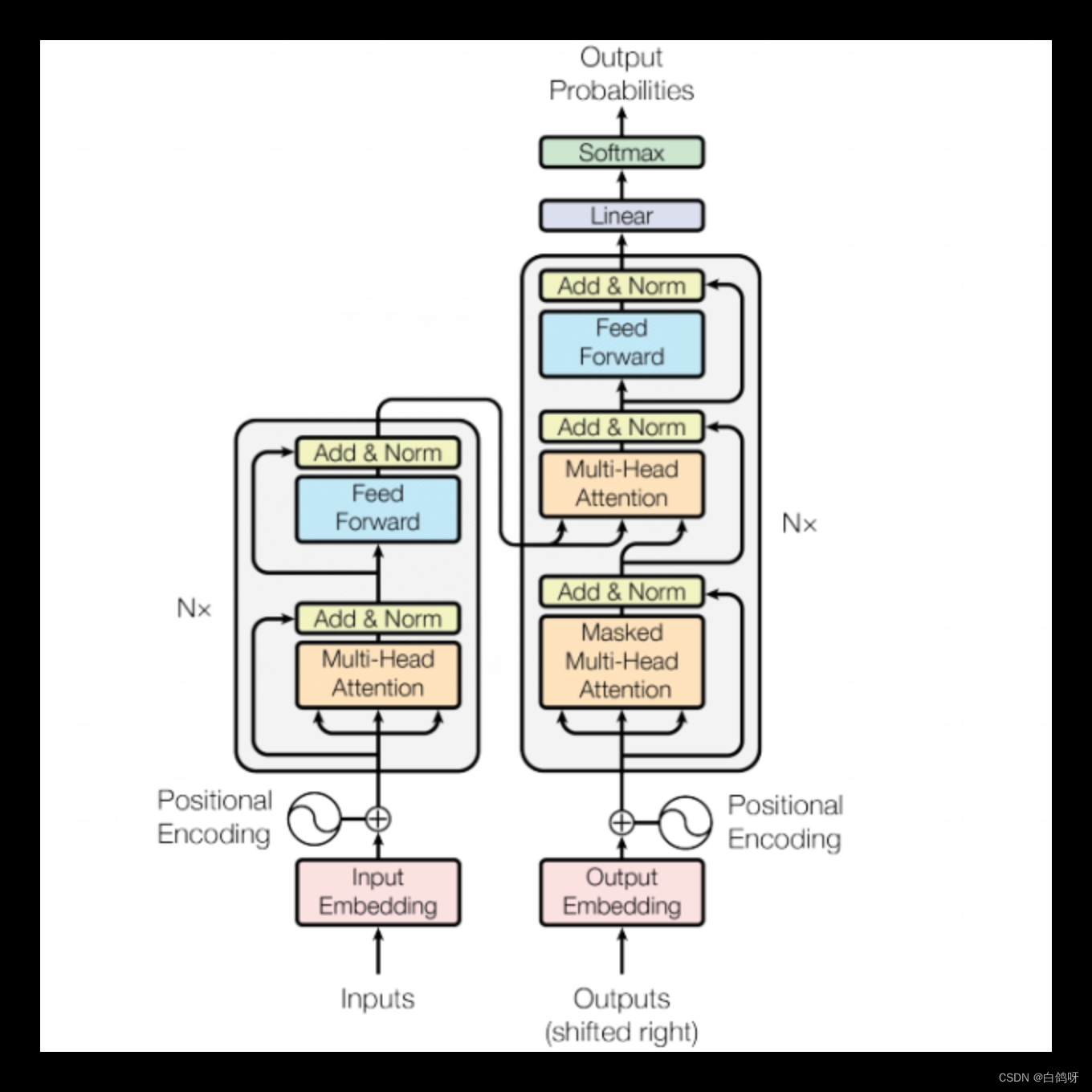 对于一条输入的数据,在这个复杂的架构中是如何流动和处理的?
对于一条输入的数据,在这个复杂的架构中是如何流动和处理的?
文本编码
-
词嵌入(Word Embedding): 文本中的每个单词都被转换为一个高维向量。这个转换通常是通过预训练的词嵌入模型(如Word2Vec、GloVe等)完成的。(确定计算机能理解单词)
-
位置嵌入(Positional Embedding): 标准的Transformer模型没有内置的序列顺序感知能力,因此需要添加位置信息。这是通过位置嵌入完成的,它与词嵌入具有相同的维度,并且与词嵌入相加。(确定文本词顺序)
词嵌入和位置嵌入相加,得到一个包含了文本信息和位置信息的新的嵌入表示。
最终得到输入的Transformer表示x,这样,模型就能知道每个单词不仅是什么,还能知道它在序列中的位置
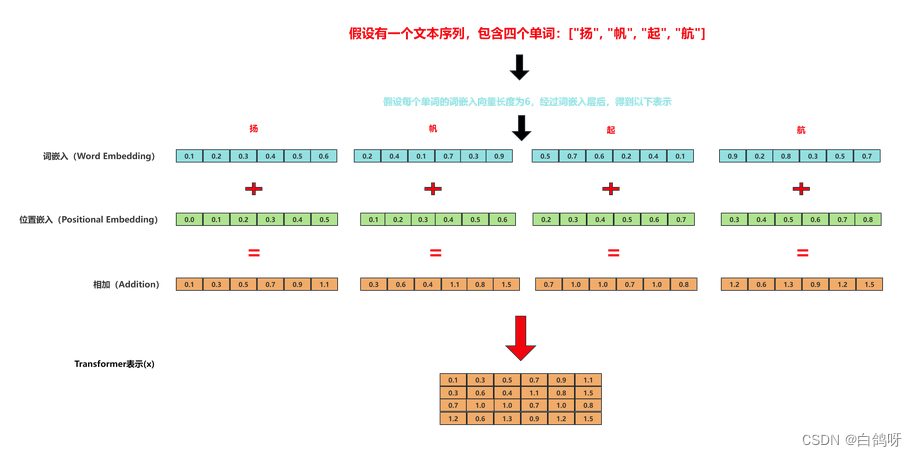 通过文本编码的一个处理过程,模型就可以认识"扬帆起航"这样的一个输入。
通过文本编码的一个处理过程,模型就可以认识"扬帆起航"这样的一个输入。
Encoder(编码器部分)
Transformer中的编码器部分,作用是学习输入序列的表示,位置如下图所示:
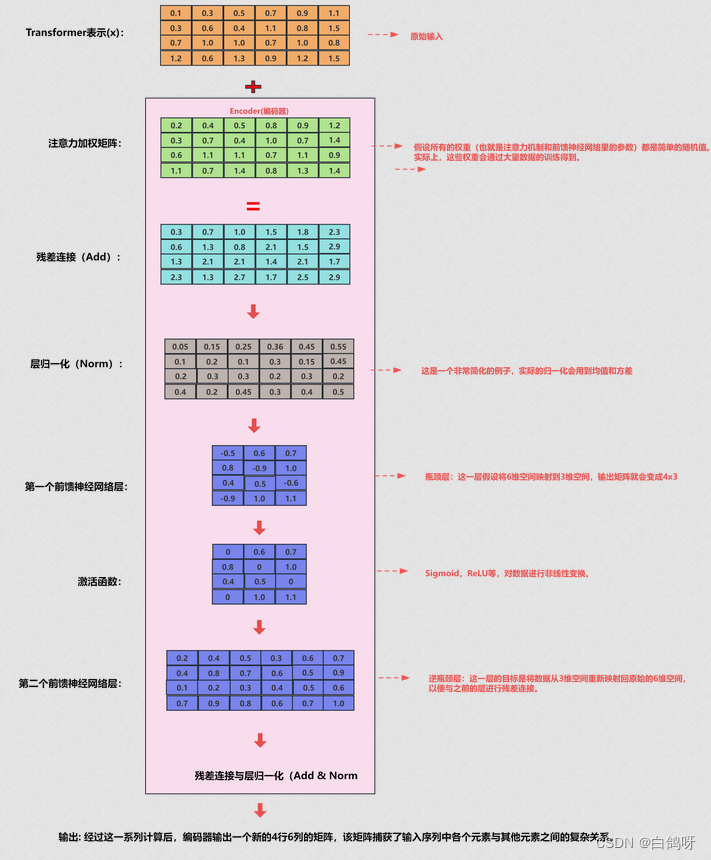
 在Transformer模型的编码器(红色虚线框)部分,数据处理流程如下:
在Transformer模型的编码器(红色虚线框)部分,数据处理流程如下:
首先,输入数据(比如一段文字)会被送入注意力(Attention)机制进行处理,这里会给数据里的每一个元素(比如每一个字或词)打个分数,以决定哪些更重要
例如:小猫想过马路,但它累倒了,理解哪个更重要,“它”指谁
在"注意力机制"(Attention)这个步骤之后,会有一些新的数据生成。
在注意力机制"中产生的新数据会和最开始输入的原始数据合在一起,这个合并其实就是简单的加法。"Add"表示残差连接,这一操作的主要目的是确保数据经过注意力处理后的效果至少不逊于直接输入的原始数据。
数据会经过一个简单的数学处理,叫做“层归一化”(Norm)(缩小或放大),主要是为了让数据更稳定,便于后续处理。
简单来说,Transformer的编码器就是通过这些步骤来理解和处理输入的数据,然后输出一种新的,更容易理解的数据形式。如图:
Decoder(解码器部分)
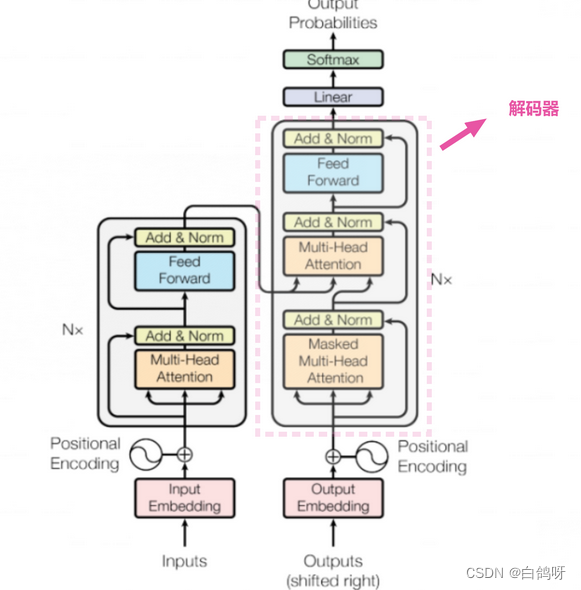 在Decoder部分,数据首先进入一个带遮罩(masked)的注意力(Attention)机制,这个遮罩的作用是确保解码器只能关注到它之前已经生成的词,而不能看到未来的词。
在Decoder部分,数据首先进入一个带遮罩(masked)的注意力(Attention)机制,这个遮罩的作用是确保解码器只能关注到它之前已经生成的词,而不能看到未来的词。
然后,这一层输出的信息会与来自Encoder部分的输出进行融合。具体来说,这两部分的信息会再次经历一个注意力机制的处理,从而综合考虑编码与解码的内容。
这个过程之后,解码器的操作与编码器部分大致相同。数据会经过层归一化、前馈神经网络,再次进行层归一化,最终输出一个词向量表示。
输出的词向量首先会通过一个线性层(Linear)。这一步的目的是将向量映射到预先定义的词典大小,从而准备进行词预测。
最后,使用softmax函数计算每个词的生成概率。最终,选取概率最高的词作为该时刻的输出
举个例子:
现在假设有一个很小的词典,只有3个词:“apple”,“banana”,“cherry”。线性层会将这个3维向量转换成另一个3维向量(对应“词典”大小)。
假设转换后的向量是 [2.5, 1.0, -0.5]。
通过softmax函数,这个向量会转换为概率分布,比如 [0.8, 0.18, 0.02]。
这就意味着模型认为下一个词是“apple”的概率是80%,是“banana”的概率是18%,是“cherry”的概率是2%。
这样,就能从解码器的高维输出中预测出一个实际的词语了。
3、大模型
3.1、大模型选型
大模型目前分为通用大模型和垂直领域大模型(行业模型)
主流的开源大模型:
- ollama3
- qwen
- chatglm3
- GLM-3-Turbo
3.2、模型显存计算和量化
如果是想本地部署大模型需要考虑模型权重显存占用,因为gpu比较贵,要选取合适参数大小的模型,那么如何计算?
以7b模型为例:
7B,即是7 Billion个参数,70亿个参数。
目前的多数大模型中,参数是float32类型(全精度),一个参数占4个字节。
70亿个参数则占70亿 x 4 = 280亿个字节 = 280亿(Byte)。
字节的单位有TB,GB,MB,KB,它们的换算关系是1024倍,即:
1TB=1025GB
1GB=1024MB
1MB=1024KB
1KB=1024Byte
1B(10亿)参数,每个参数占4个字节,则模型占用显存:
4 x 1000000000 / 1024(KB) / 1024(MB) / 1024(GB) = 3.725G
7B则是:7 x 3.725 = 26.08G
为了方便粗略估算,可以按1B参数占用4G显存来算(虽然多算了一点,但在实际推理过程中,除了加载模型需要显存外,计算过程也是临时需要额外显存的,因此具备合理性)。
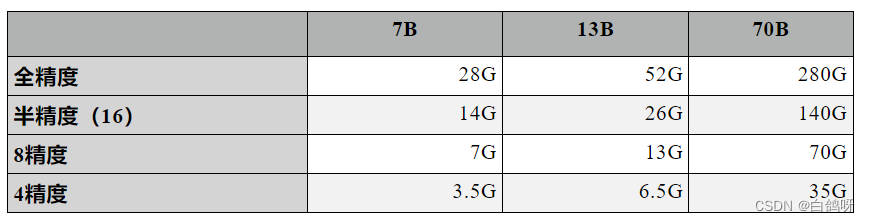
7B模型则占用:7 x 4G = 28G
半精度(16)由于只占两个字节,1B参数占用2G显存,7B模型则占用14G。
8精度则只占1个字节,4精度一个参数只占半个字节,因此分别占显存7G和3.5G。
理解了这个计算方法,以后看到某个参数规模的模型时,就能自己计算显存需求了。
能不能让模型在使用效果相差不大的情况下,减少模型的显存占用?
模型量化技术正是针对解决这一问题而提出,一句话概述就是:通过用更少位数的数据类型近似表示32位浮点数,以较低的推理精度损失,达到减少模型尺寸、内存消耗和加快推理速度的目的。
先来看看不同参数规模的Llama2在不同精度下的推理显存预估要求:
3.3、大模型部署
以chatglm3-6b为例来本地部署大模型
首先环境上必须要安装conda,python3.11
通过nvidia-smi 来确定机器上的gpu的cuda版本,然后去pytorch官网下载对应的pytorch对应的依赖。注意pytorch与cuda不对应模型跑不起来
# 获取模型基础运行代码
! git clone https://github.com/THUDM/ChatGLM3.git
# git lfs 是git大文件存储管理工具
# 如果没有# ! git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.gitgit 要先安装git, 没有git lfs需要安装git lfs
# 通过感叹号! 可以实现运行linux的命令行语句
# 获取模型, git中启用git lfs
! git lfs install
! git clone https://swanhub.co/ZhipuAI/chatglm3-6b.git
# 要在conda虚拟环境中运行,进行环境隔离,不然会有依赖冲突
conda create -n test_env python=3.11
conda activate test_env
#因无法实现cd 命令切换路径故使用python自带os库切换路径
import os
os.chdir('/mnt/workspace')
os.chdir('ChatGLM3')
# 安装代码所需的环境依赖,注意一下 requirement上的pytorch要去除掉
! pip install -r requirements.txt
os.chdir('/mnt/workspace')
# 启动模型
from modelscope import AutoTokenizer, AutoModel
model_dir = 'chatglm3-6b'
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
#cuda使用GPU计算, float使用CPU计算
model = AutoModel.from_pretrained(model_dir, trust_remote_code=True).half().cuda()
# model = AutoModel.from_pretrained(model_dir, trust_remote_code=True).half().float()
model = model.eval()
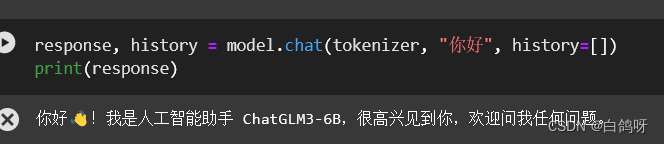
3.4、大模型微调
大模型微调就是在有限的gpu资源环境下,对模型增加少量的参数,实现模型推理生成
微调适用的场景
通常来说,适合微调的场景主要分为行业场景和通用场景
对于行业场景:
- 例如客服助手,智能写作辅导等需要专门的回答范式和预期的场景
- 例如智慧医生,智慧律师等需要更专业的行业知识和思考能力的场景
对于通用场景
- NL2SQL等输出为指定范式的
- 支持可调整参数的工具调用等原生模型不具备的能力的
模型微调以chatglm3-6b模型为例
1、首先要明确想要达成的效果,例如实现广告生成语
2、然后我们要了解到chatglm3的数据微调格式,注意,每种模型对于数据要求可能是不一样的
- 如果仅希望微调模型的对话能力,而非工具能力,应该按照以下格式整理数据
[
{
"conversations": [
{
"role": "system",
"content": "<system prompt text>"
},
{
"role": "user",
"content": "<user prompt text>"
},
{
"role": "assistant",
"content": "<assistant response text>"
},
// ... Muti Turn
{
"role": "user",
"content": "<user prompt text>"
},
{
"role": "assistant",
"content": "<assistant response text>"
}
]
}
// ...
]
- 如果希望微调模型的对话和工具能力,应该按照以下格式整理数据。
[
{
"tools": [
// available tools, format is not restricted
],
"conversations": [
{
"role": "system",
"content": "<system prompt text>"
},
{
"role": "user",
"content": "<user prompt text>"
},
{
"role": "assistant",
"content": "<assistant thought to text>"
},
{
"role": "tool",
"name": "<name of the tool to be called",
"parameters": {
"<parameter_name>": "<parameter_value>"
},
"observation": "<observation>"
},
{
"role": "assistant",
"content": "<assistant response to observation>"
},
// ... Muti Turn
{
"role": "user",
"content": "<user prompt text>"
},
{
"role": "assistant",
"content": "<assistant response text>"
}
]
}
// ...
]
3、然后我们按照对应上述格式将数据进行处理
原始数据
 转换成大模型数据交互模型
转换成大模型数据交互模型
 4、安装微调一些必要的依赖
4、安装微调一些必要的依赖
jieba>=0.42.1
ruamel_yaml>=0.18.5
rouge_chinese>=1.0.3
jupyter>=1.0.0
datasets>=2.16.1
peft==0.7.1
transformers>=4.37.2
deepspeed>=0.13.1
5、通过lora将对应的数据输入大模型进行微调
# CUDA_VISIBLE_DEVICES 设置使用的显卡. 0指明使用0号位置的显卡,可以设置使用多个显卡,通过 nvidia-smi 查看显卡序号
!CUDA_VISIBLE_DEVICES=0 /home/pai/bin/python finetune_hf.py data/AdvertiseGen_fix
/mnt/workspace/chatglm3-6b configs/lora.yaml no
finetune_hf.py :chatglm提供的微调文件
data/AdvertiseGen_fix:转换后的数据目录
/mnt/workspace/chatglm3-6b :模型权重
configs/lora.yaml :lora配置文件
6、使用微调的数据集进行推理
在完成微调任务之后,我们可以查看到 output 文件夹下多了很多个checkpoint-*的文件夹,这些文件夹代表了训练的轮数。我们选择最后一轮的微调权重,并使用inference进行导入。
!ls output/
# 经过验证,根据输入的提示词,模型可以自动进行推理生成,不是一对一映射给出结果
# 但回答结果不尽如人意,应该是数据质量不行
!CUDA_VISIBLE_DEVICES=0 python inference_hf.py output/checkpoint-3000/ --prompt "衣服和裙子"
output/checkpoint-3000/ :微调后的模型权重目录
prompt:用户输入
 可以看到训练的结果,不是原本模型那种模板化的回答
可以看到训练的结果,不是原本模型那种模板化的回答
3.5、RAG(检索增强生成)
RAG(Retrieval-Augmented Generation)是什么?
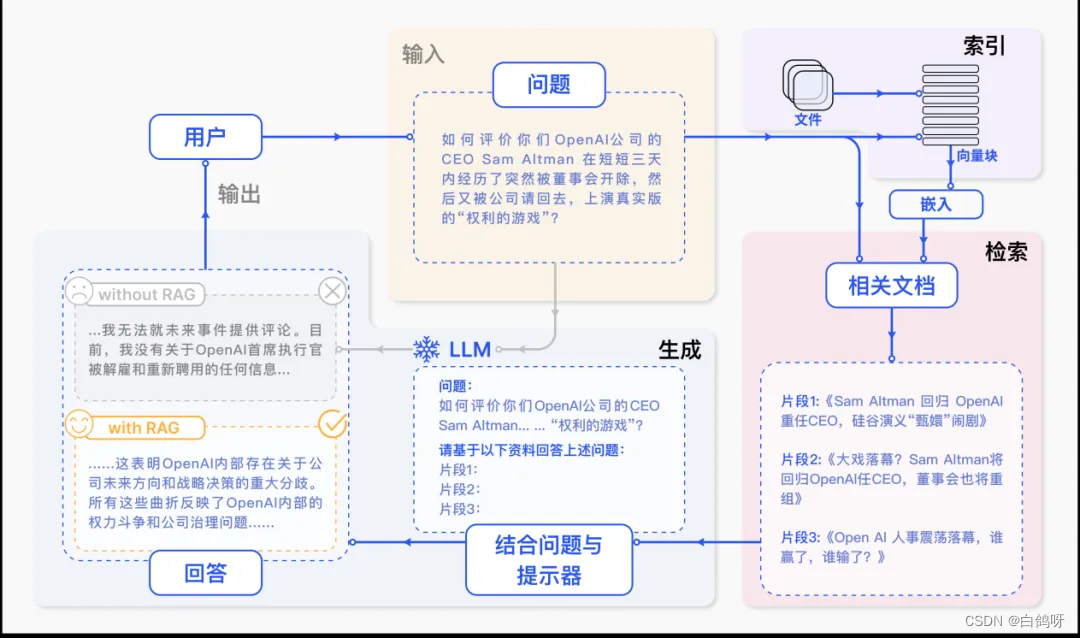
一个典型的 RAG 案例如图所示。如果我们向 ChatGPT 询问 OpenAI CEO Sam Atlman 在短短几天内突然解雇随后又被复职的事情。由于受到预训练数据的限制,缺乏对最近事件的知识,ChatGPT 则表示无法回答。RAG 则通过从外部知识库检索最新的文档摘录来解决这一差距。在这个例子中,它获取了一系列与询问相关的新闻文章。这些文章,连同最初的问题,随后被合并成一个丰富的提示,使 ChatGPT 能够综合出一个有根据的回应。
RAG实现原理
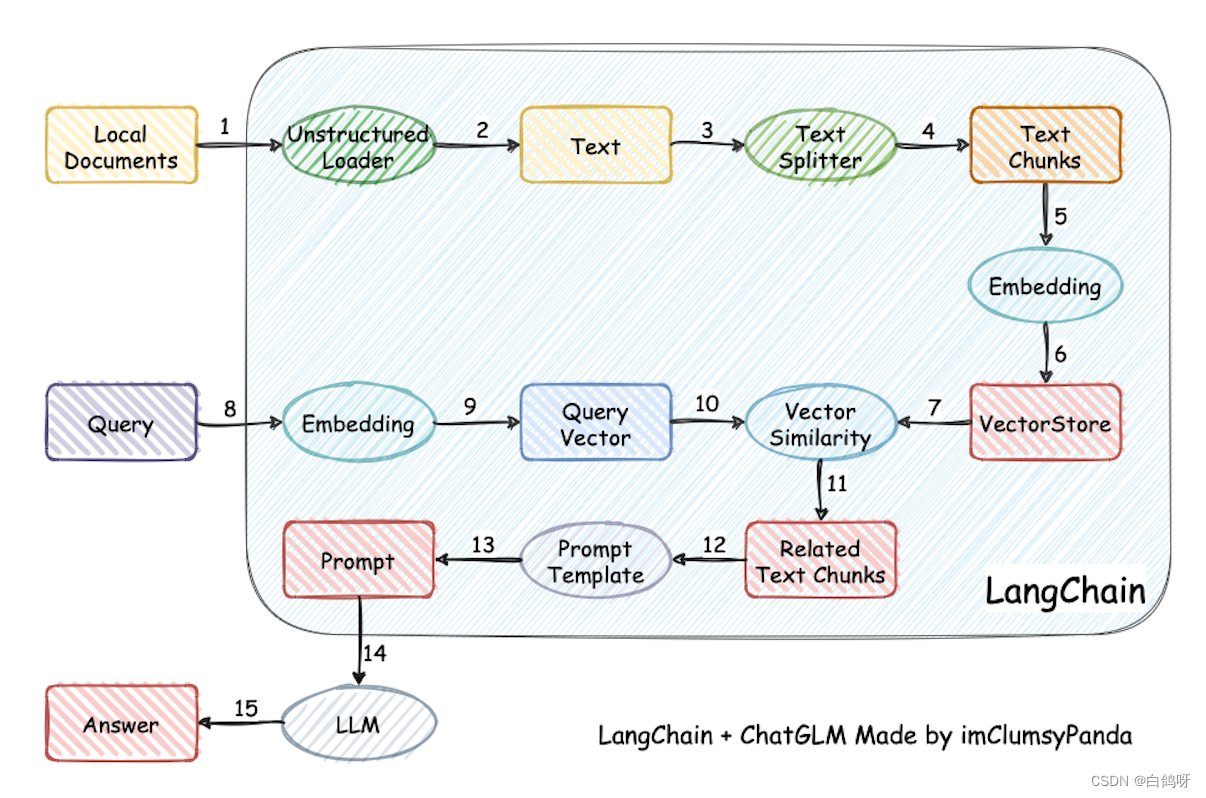
1、首先读取各种文件pdf,text,word,ppt等等,通过程序loader将它们转换为文档
2、通过文本分割器textSplit(这种分割器有很多)将文本分割成一块块的,存储在数据库中,可以是pgsql
3、将一块块文本块分别转换为向量,通过向量模型,然后存储在向量库中,可以pgsql+pgvector
4、当用户输入问题的时候,会将问题文本通过向量模型向量化,然后再去向量库进行模糊匹配一定范围内的向量块数据,最终取出topn 数据
5、将问题 和 取出来的多个文本块数据 一起作为输入,让模型推理生成,符合实际的答案
6、将问题和答案进行缓存,提高并发率
3.6、Function Calling(功能调用)
什么是工具调用?
大模型虽然强大,但是由于训练的时间和语料限制。大模型通常会存在以下问题:
- 只能获取训练数据集中有的事件和内容,这意味着大模型不具备访问最新资料的能力。(RAG只是知识库的能力)
- 模型以通用语料训练为主,因此,缺少专业领域的知识。
- 体量较小,虽然拥有较强的数学,英语等能力,但仍然无法与GPT4等大模型进行抗衡,因此,会出现数学计算不准确等问题。(专业功能不强大)
想想一下大模型就是大脑用来思考,这时候,通过给大模型加上“四肢“,让大模型学会使用工具,这些问题将迎刃而解。
例如,我们通过编写计算器插件,使用Python的eval()验证功能,或者numexpr.evaluate() 等功能,将能有效的辅助模型进行计算。模型仅需要告诉插件计算的内容,由工具完成计算,并返回大模型,大模型将答案进行整合输出,便可以得到正确的答案。
那么这些外接的功能函数,就是function calling
那么,如何实现呢?我们依旧以chatglm3为例
1、定义工具信息
tools = [
{
"name": "track",
"description": "追踪指定股票的实时价格",
"parameters": {
"type": "object",
"properties": {
"symbol": {
"description": "需要追踪的股票代码"
}
},
"required": ['symbol']
}
},
{
"name": "text-to-speech",
"description": "将文本转换为语音",
"parameters": {
"type": "object",
"properties": {
"text": {
"description": "需要转换成语音的文本"
},
"voice": {
"description": "要使用的语音类型(男声、女声等)"
},
"speed": {
"description": "语音的速度(快、中等、慢等)"
}
},
"required": ['text']
}
}
]
system_info = {
"role": "system",
"content": "Answer the following questions as best as you can. You have access to the following tools:",
"tools": tools
}
这个实际上是告诉大模型我有这些函数工具,以及对应的参数
2、理解工具运行流程
<|user|>
提出问题
<|assistant|>
思考应该做什么
<|assistant|>调用工具的名称
python(这里的python是固定格式,并不一定是python语句)
tool_call(调用工具的参数)
<|observation|>
工具回复的结果,为一个字符串
<|assistant|>
(如果知道最后答案)我知道最后答案了,回答用户的问题
3、工具注册到工具库,以便模型调用
在chatglm3的代码中,设计了一个工具注册的函数,用户可以在tool_register.py中寻找到这个函数。该函数如下
def register_tool(func: callable):
tool_name = func.__name__
tool_description = inspect.getdoc(func).strip()
python_params = inspect.signature(func).parameters
tool_params = []
for name, param in python_params.items():
annotation = param.annotation
if annotation is inspect.Parameter.empty:
raise TypeError(f"Parameter `{name}` missing type annotation")
if get_origin(annotation) != Annotated:
raise TypeError(f"Annotation type for `{name}` must be typing.Annotated")
typ, (description, required) = annotation.__origin__, annotation.__metadata__
typ: str = str(typ) if isinstance(typ, GenericAlias) else typ.__name__
if not isinstance(description, str):
raise TypeError(f"Description for `{name}` must be a string")
if not isinstance(required, bool):
raise TypeError(f"Required for `{name}` must be a bool")
tool_params.append({
"name": name,
"description": description,
"type": typ,
"required": required
})
tool_def = {
"name": tool_name,
"description": tool_description,
"params": tool_params
}
print("[registered tool] " + pformat(tool_def))
_TOOL_HOOKS[tool_name] = func
_TOOL_DESCRIPTIONS[tool_name] = tool_def
return func
实现自己的工具代码,以下例子为天气查询工具的示例
@register_tool
def get_weather(
city_name: Annotated[str, 'The name of the city to be queried', True],
) -> str:
"""
Get the current weather for `city_name`
"""
if not isinstance(city_name, str):
raise TypeError("City name must be a string")
key_selection = {
"current_condition": ["temp_C", "FeelsLikeC", "humidity", "weatherDesc", "observation_time"],
}
import requests
try:
resp = requests.get(f"https://wttr.in/{city_name}?format=j1")
resp.raise_for_status()
resp = resp.json()
ret = {k: {_v: resp[k][0][_v] for _v in v} for k, v in key_selection.items()}
except:
import traceback
ret = "Error encountered while fetching weather data!\n" + traceback.format_exc()
return str(ret)
if __name__ == "__main__":
print(dispatch_tool("get_weather", {"city_name": "beijing"}))
print(get_tools())
当用户输入“帮我查询下北京目前的天气”
大模型会根据语境理解,去函数库匹配 对应的方法,返回方法和对应的参数信息,然后python 根据方法名及参数去进行调用。
再举一个例子
本地定义如下两个外部函数供模型选择调用:
- 查询两地之间某日航班号函数:get_flight_number(departure: str, destination: str, date: str)
- 查询某航班某日票价函数:get_ticket_price(flight_number: str, date: str)
def get_flight_number(date:str , departure:str , destination:str):
flight_number = {
"北京":{
"上海" : "1234",
"广州" : "8321",
},
"上海":{
"北京" : "1233",
"广州" : "8123",
}
}
return { "flight_number":flight_number[departure][destination] }
def get_ticket_price(date:str , flight_number:str):
return {"ticket_price": "1000"}
然后编写函数库工具的描述
tools = [
{
"type": "function",
"function": {
"name": "get_flight_number",
"description": "根据始发地、目的地和日期,查询对应日期的航班号",
"parameters": {
"type": "object",
"properties": {
"departure": {
"description": "出发地",
"type": "string"
},
"destination": {
"description": "目的地",
"type": "string"
},
"date": {
"description": "日期",
"type": "string",
}
},
"required": [ "departure", "destination", "date" ]
},
}
},
{
"type": "function",
"function": {
"name": "get_ticket_price",
"description": "查询某航班在某日的票价",
"parameters": {
"type": "object",
"properties": {
"flight_number": {
"description": "航班号",
"type": "string"
},
"date": {
"description": "日期",
"type": "string",
}
},
"required": [ "flight_number", "date"]
},
}
},
]
我们想查询2024年1月20日从北京前往上海的航班。我们向模型提供这个信息:
messages = []
messages.append({"role": "user", "content": "帮我查询从2024年1月20日,从北京出发前往上海的航班"})
response = client.chat.completions.create(
model="glm-4", # 填写需要调用的模型名称
messages=messages,
tools=tools,
tool_choice='auto'
)
print(response.choices[0].message)
messages.append(response.choices[0].message.model_dump())
模型返回输出
content=None role='assistant'
tool_calls[CompletionMessageToolCall(id='call_8495942909317716104',
function=Function(arguments='{"date":"2024-01-20","departure":"北京","destination":"上海"}',
name='get_flight_number'), type='function')]
然后编写一个解析函数,实现函数调用
def parse_function_call(model_response,messages):
# 处理函数调用结果,根据模型返回参数,调用对应的函数。
# 调用函数返回结果后构造tool message,再次调用模型,将函数结果输入模型
# 模型会将函数调用结果以自然语言格式返回给用户。
if model_response.choices[0].message.tool_calls:
tool_call = model_response.choices[0].message.tool_calls[0]
args = tool_call.function.arguments
function_result = {}
if tool_call.function.name == "get_flight_number":
function_result = get_flight_number(**json.loads(args))
if tool_call.function.name == "get_ticket_price":
function_result = get_ticket_price(**json.loads(args))
messages.append({
"role": "tool",
"content": f"{json.dumps(function_result)}",
"tool_call_id":tool_call.id
})
response = client.chat.completions.create(
model="glm-4", # 填写需要调用的模型名称
messages=messages,
tools=tools,
)
print(response.choices[0].message)
messages.append(response.choices[0].message.model_dump())
可以看到此时模型成功触发对 get_flight_number 函数的调用 参数为:date=“2024-01-20”,departure=“北京”,destination=“上海”
3.7、本地模型对外提供API访问(FastAPI)
FastAPI是一个现代、快速(高性能)的python web框架,基于标准的python类型提示,使用python3.6+构建的web框架。
FastAPI的架构为RESTful风格,RESTful是一种网络应用程序的设计风格和开发方式,其特点为每一个URI代表一种资源,客户端通过GET、POST、PUT、DELETE等动作,对服务器端资源进行操作。
环境准备
安装FastAPI:pip install fastapi
安装ASGI服务:pip install uvicorn
新建一个main.py文件,编写如下:
from fastapi import FastAPI
app = FastAPI()
@app.get('/')
def root():
return {'message': 'Hello World'}
启动服务
命令:uvicorn main:app --reload
main:文件main.py(python模块)
app:在模块中app=FastAPI()行中创建的对象
–reload:代码更改后自动重启服务(上线时该参数值不能为true,降低性能)
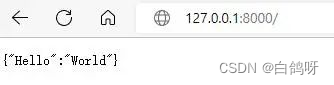
访问服务
启动服务后,使用浏览器访问127.0.0.1:8000,
结合模型
以chatgml3为例
新增api.py文件
from fastapi import FastAPI, Request
from transformers import AutoTokenizer, AutoModel
import uvicorn, json, datetime
import torch
DEVICE = "cuda"
DEVICE_ID = "0"
CUDA_DEVICE = f"{DEVICE}:{DEVICE_ID}" if DEVICE_ID else DEVICE
def torch_gc():
if torch.cuda.is_available():
with torch.cuda.device(CUDA_DEVICE):
torch.cuda.empty_cache()
torch.cuda.ipc_collect()
app = FastAPI()
@app.post("/")
async def create_item(request: Request):
global model, tokenizer
json_post_raw = await request.json()
json_post = json.dumps(json_post_raw)
json_post_list = json.loads(json_post)
prompt = json_post_list.get('prompt')
history = json_post_list.get('history')
max_length = json_post_list.get('max_length')
top_p = json_post_list.get('top_p')
temperature = json_post_list.get('temperature')
response, history = model.chat(tokenizer,
prompt,
history=history,
max_length=max_length if max_length else 2048,
top_p=top_p if top_p else 0.7,
temperature=temperature if temperature else 0.95)
now = datetime.datetime.now()
time = now.strftime("%Y-%m-%d %H:%M:%S")
answer = {
"response": response,
"history": history,
"status": 200,
"time": time
}
log = "[" + time + "] " + '", prompt:"' + prompt + '", response:"' + repr(response) + '"'
print(log)
torch_gc()
return answer
if __name__ == '__main__':
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True).cuda()
# 多显卡支持,使用下面三行代替上面两行,将num_gpus改为你实际的显卡数量
# model_path = "THUDM/chatglm2-6b"
# tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# model = load_model_on_gpus(model_path, num_gpus=2)
model.eval()
uvicorn.run(app, host='0.0.0.0', port=8000, workers=1)
4、大模型与软件智能化实践
4.1、什么是LangChain
LangChain是一个强大的框架,旨在帮助开发人员使用语言模型构建端到端的应用程序。它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互,将多个组件链接在一起,并集成额外的资源,例如 API 和数据库。
官方文档:https://python.langchain.com/en/latest/
中文文档:https://www.langchain.com.cn/
LangChain有几个核心概念
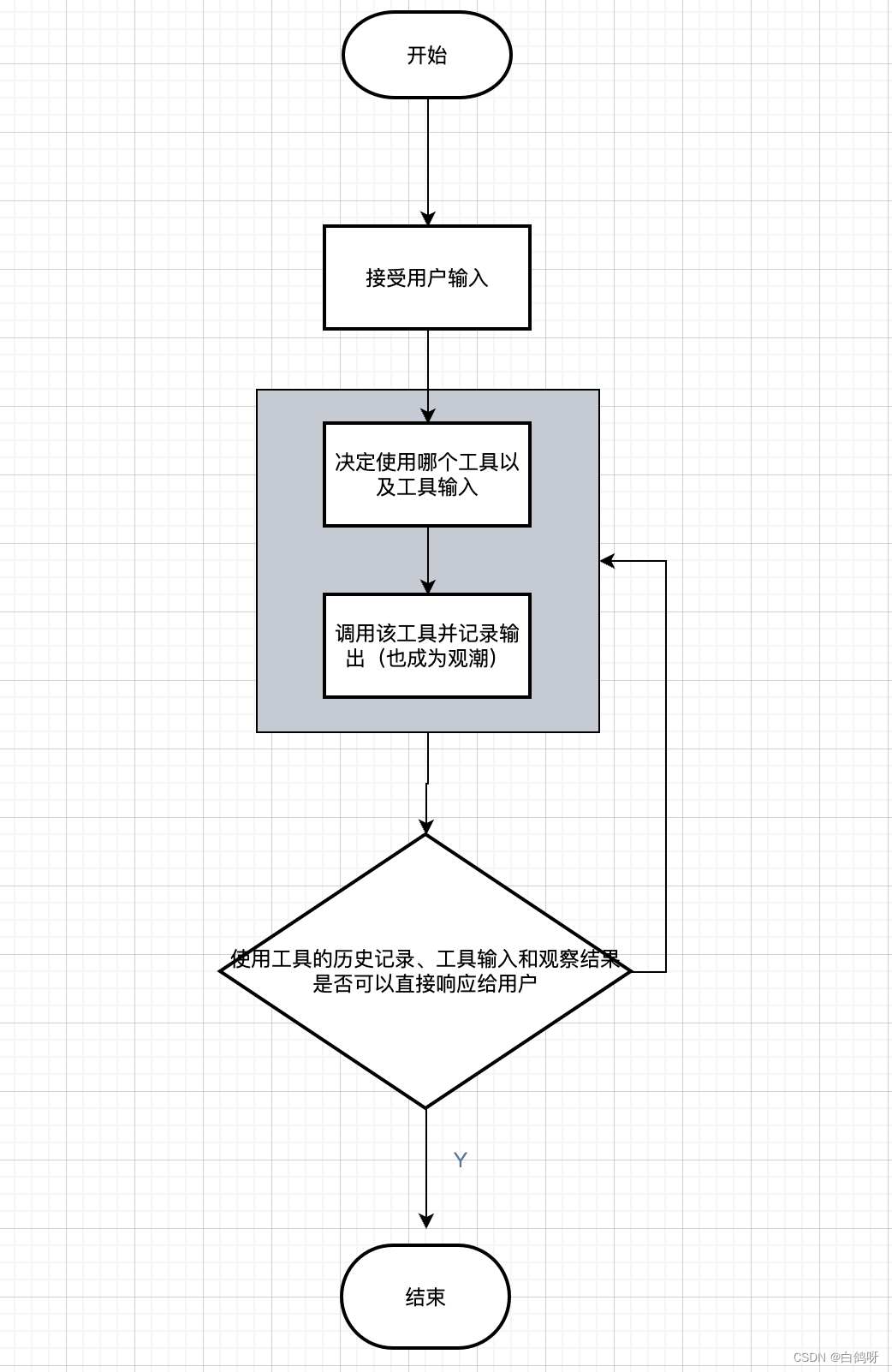
1、agent(代理/智能体)通常用户的一个问题可能需要应用程序的多个逻辑处理才能完成相关任务,而且往往可能是动态的,会随着用户的输入不同而需要不同的 Action,或者 LLM 输出的不同而执行不同的 Action。因此应用程序不仅需要预先确定 LLM 以及其他工具调用链,而且可能还需要根据用户输入的不同而产生不同的链条。使用代理可以让 LLM 访问工具变的更加直接和高效,工具提供了无限的可能性,LLM 可以搜索网络、进行数学计算、运行代码等等相关功能。
LangChain 中代理使用 LLM 来确定采取哪些行动及顺序,查看观察结果,并重复直到完成任务。LangChain 库提供了大量预置的工具,也允许修改现有工具 或创建新工具。当代理被正确使用时,它们可以非常强大。在 LangChain 中,通过“代理人”的概念在这些类型链条中访问一系列的工具完成任务。根据用户的输入,代理人可以决定是否调用其中任何一个工具。
总结:首先我们需要告诉大模型有哪些工具库,agent概念呢,可以独立创建不同的agent分配给这些agent对应的工具库,例如:数据家agent(复杂计算,论文润色等),作家agent(论文润色,写作)。然后通过用户指定不同agent进行多轮交互,最终完成任务
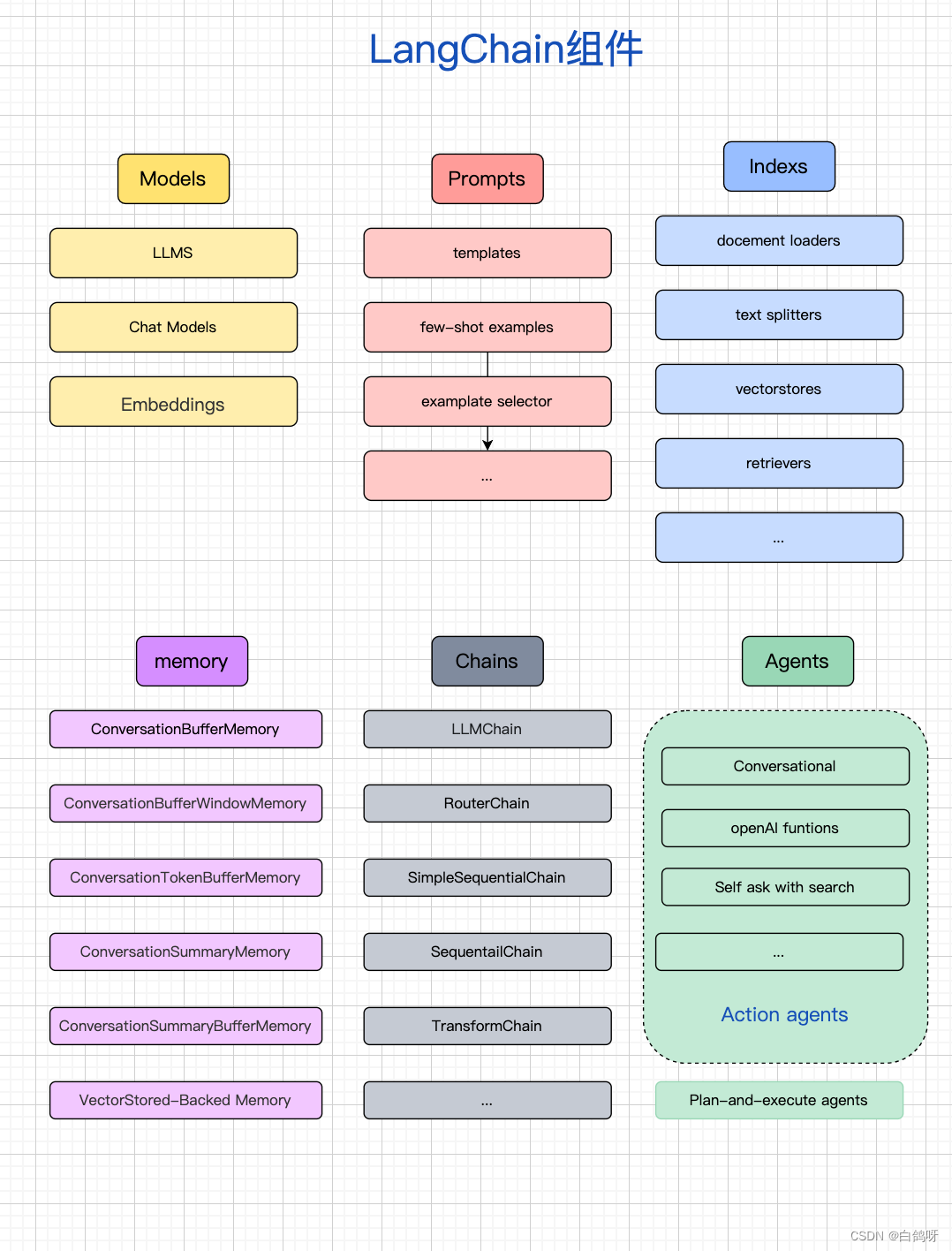
2、chain(链)链允许我们将多个组件组合在一起以创建一个单一的、连贯的任务。例如,我们可以创建一个链,它接受用户输入,使用 PromptTemplate 对其进行格式化,然后将格式化的响应传递给 LLM。另外我们也可以通过将多个链组合在一起,或者将链与其他组件组合来构建更复杂的链。
3、index(索引)索引是指对文档进行结构化的方法,以便 LLM 能够更好的与之交互。该组件主要包括:Document Loaders(文档加载器)、Text Splitters(文本拆分器)、VectorStores(向量存储器)以及 Retrievers(检索器)。
4、memory(记忆存储)
5、models(模型)
6、prompts(提示词工程)基于模板做提示词
4.2、Langchain4j实践(java版langchain)
从概念上来说大体一致与langchain,但还是有一定的区别的
1、chatLanguageModel 指代大语言模型
2、chatMemory 问题和答案存储 内存缓存
3、AI service 基于他可以实现function call 和 RAG
4、embedding store
5、embedding model
6、document loader
问题:
1、如何通过java访问远程大模型,进行交互
2、langchain4j 如何做RAG
3、langchain4j 如何做function calling
4、function calling 思路
5、embedding model如何选择?,langchain4j如何接入
6、文档如何切割?才能让语义更加完整,进行向量匹配才能更加准确
7、如何编写长文档?
展示代码,运行测试




![【UnityShader]使用Shader将图片进行水平/竖直镜像翻转](https://img-blog.csdnimg.cn/direct/50d09d82688143e1986a10e56ba6bf36.gif)