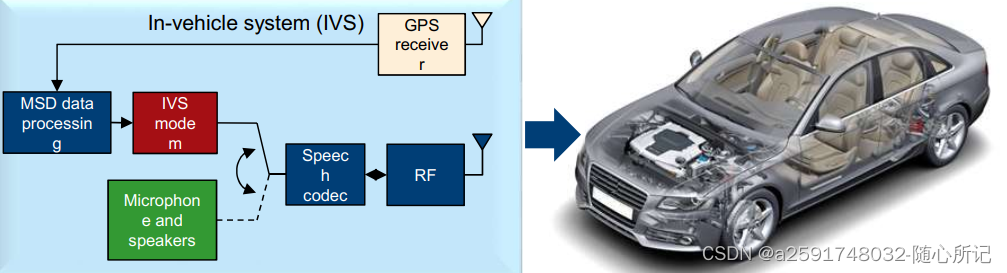
Spark 中的分桶分化
Bucketing是 Spark 和 Hive 中用于优化任务性能的一种技术。在分桶桶(集群列)中确定数据分区并防止数据混洗。根据一个或多个分桶列的值,将数据分配给预定义数量的桶。

分桶有两个主要好处:
- 改进的查询性能:在连接时,我们可以在相同的分桶列上明确指定桶的数量。由于每个存储桶包含相同大小的数据,因此映射端连接的性能优于存储桶表上的非存储桶表。在 map-side join 中,左侧表存储桶将准确知道右侧存储桶包含的数据集,以便以结构良好的格式执行表联接。
- 改进的采样:数据已经被分成更小的块,因此采样得到了改进。
- 加快连接操作的性能与尽量少的性能消耗:连接操作只需要定位各个桶,非整个数据集
何时使用桶列
- 表大小很大(> 200G)。
- 该表具有高基数列,这些列经常用作过滤和/或连接键。
- 中等大小的表,但主要用于连接一个巨大的桶化表,桶化它仍然是有益的
- 排序合并连接(没有存储桶)由于随机播放而不是由于数据倾斜而变慢
如何配置存储桶列
- 选择高基数列作为桶列。
- 尽量避免数据倾斜。
- 至少 500 个桶(因为小桶数会导致并行执行不佳)。
- 排序桶是可选的,但强烈推荐。
如何在 Spark 中创建数据桶
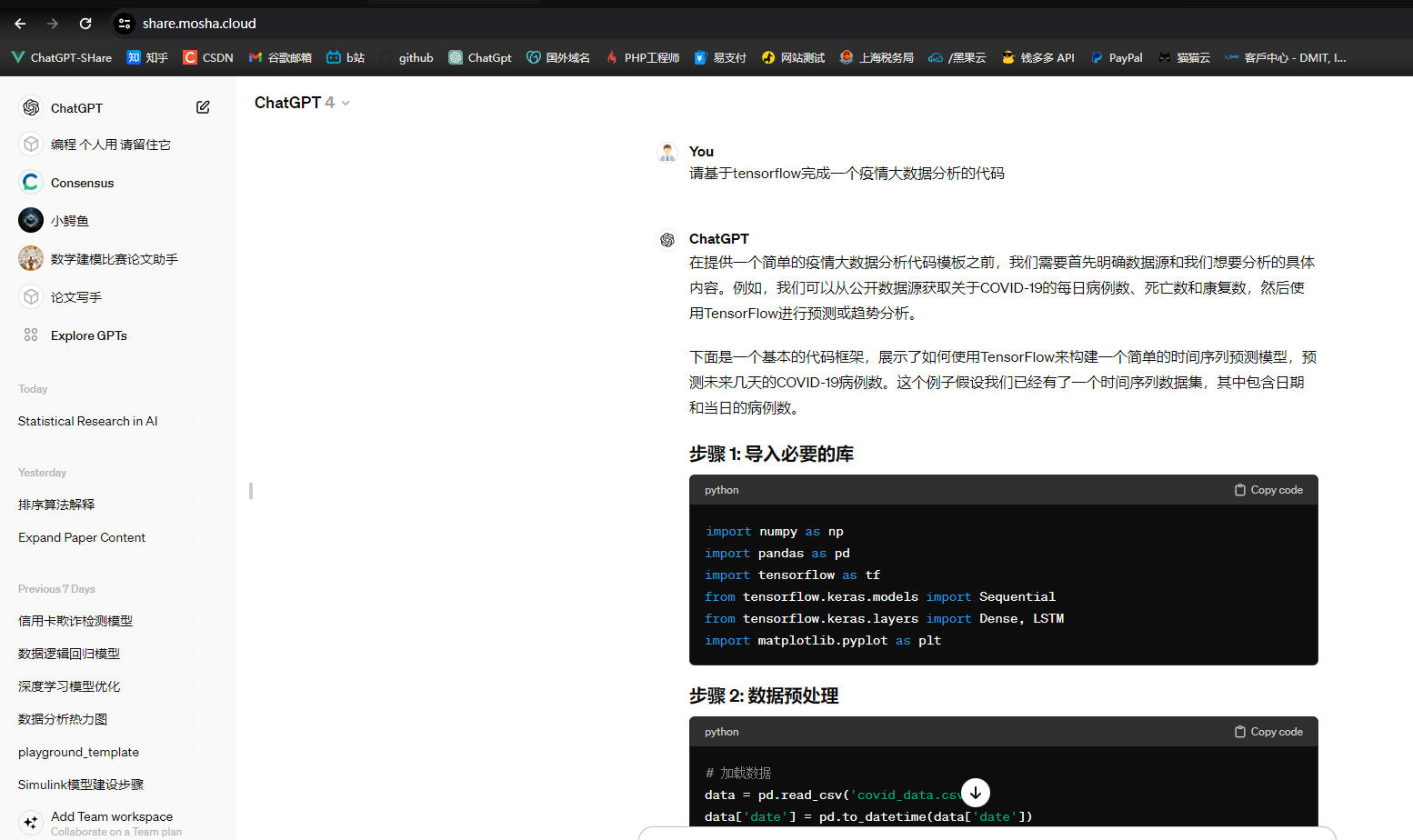
- 下面是在 SparkAPI 中创建存储桶的示例。bucketBy是在 spark 中创建存储桶的函数。我们需要将桶的信息保存在某处,所以这里需要使用saveAsTable来保存桶表的元数据信息。
n 是要创建的桶数
df.write.mode(“save_mode”)
.option(“path”, “s3 path/hdfs path”) \
*.bucketBy(n, ‘col1’, ‘col2’…) *
*.sortBy(‘col1’, ’ col2’) *
.saveAsTable(‘table_name’, format=‘parquet’)
df = spark.table(‘table_name’)
CREATE TABLE
`temp`.`dm_log_app_activityinfo_user` (`log_id` STRING, `mid` STRING,
`app_name` STRING, `start_time` STRING, `user_name` STRING, `is_new_visitor`
INT, `user_class` STRING, `user_group` STRING, `user_id` STRING, `user_label`
STRING, `session_id` STRING, `dt` STRING)
USING orc
OPTIONS (
`serialization.format` '1'
)
PARTITIONED BY (dt)
CLUSTERED BY (log_id)
SORTED BY (log_id)
INTO 4000 BUCKETS;
- 在上面的示例中,我们使用了 bucketBy 和 sortBy,因为在某些情况下我们有多个连接键,并且希望将整数键放在 bucketBy 中,将字符串键放在 sortBy 中。当我们做数据桶时,sortBy 是可选的。
- 可以根据数据大小和我们对数据运行的查询来决定存储桶大小的数量。通常,每个存储桶可能更喜欢 100 MB 到 200 MB。
- 存储桶表将使用以下命名约定将表保存在路径中。
如何在 Spark 上启用分桶?
默认情况下启用分桶。
或者,您可以在 Spark Shell 或属性文件中设置以下属性。
设置 spark.sql.sources.bucketing.enabled=true
Spark 中对表进行分桶的优点
- 优化表。
- 使用预洗牌分桶表时优化联接。
- 当您在分桶列上定义谓词时,启用更有效的查询。
- 优化了对表数据的访问。_在桶列上使用 WHERE 条件时,您将最小化给定查询的表扫描。
- 将数据均匀分布在不同的存储桶中,从而实现对表数据的最佳访问。
转换列表
以下转换将受益于分桶:
- 加入
- 清楚的
- 通过…分组
- 减少
Spark Bucket 的限制
Spark Bucketing 有其自身的局限性,我们在创建分桶表以及将它们连接在一起时需要非常小心。
为了优化连接并在 Spark 中使用分桶,我们需要确保以下几点:
- 两个表都使用相同数量的存储桶进行存储 如果加入表中的桶号不同,则不会应用预洗牌。
- 两个表都存储在同一列上以进行连接 由于数据是根据给定的分桶列进行分区的,如果我们不使用同一列进行连接,那么您就没有使用分桶,它会影响性能。
Spark 分桶与 Hive 分桶有何不同?
在 Hive 中,我们需要根据需要创建文件数量的 reducer。
而在 Spark 分桶中,我们没有减速器。因此,它最终会根据任务的数量创建 n 个文件。


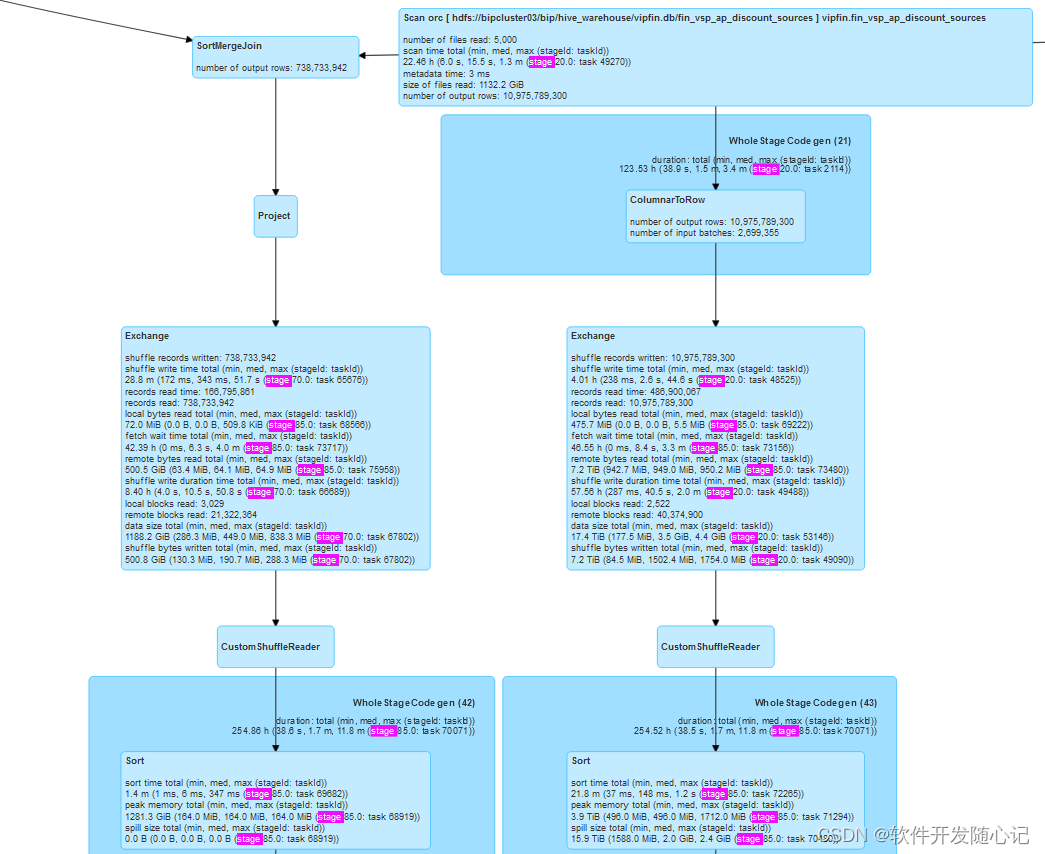
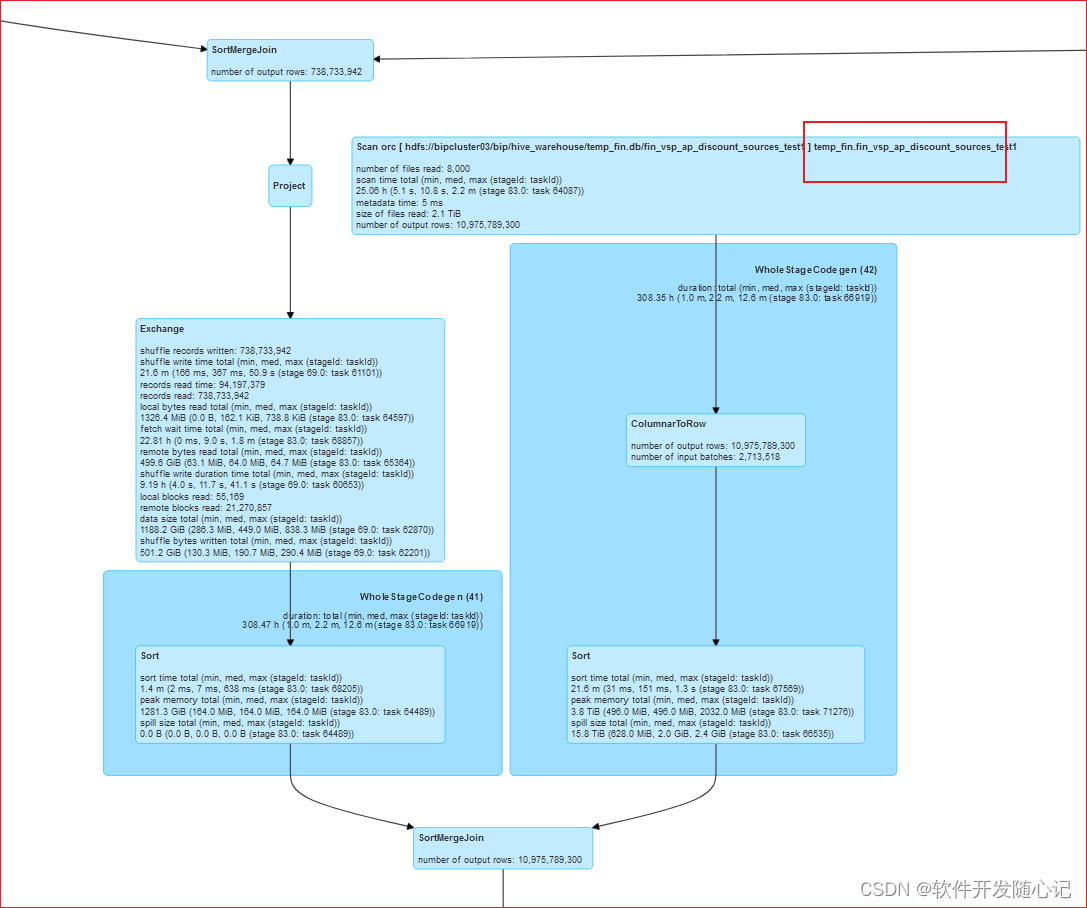
分桶表实践
将增量大表与存量历史大表(rows≈百亿)的full join去重过程优化,通过历史表分桶方式避免 TB级别表的shuffle过程,相同过程中 图2修改成了历史数据分桶表 避免自身exchange过程,
相同task数测试性能将200分钟压缩至50分钟左右

![【UnityShader]使用Shader将图片进行水平/竖直镜像翻转](https://img-blog.csdnimg.cn/direct/50d09d82688143e1986a10e56ba6bf36.gif)