原文链接
[2302.14115] Vid2Seq: Large-Scale Pretraining of a Visual Language Model for Dense Video Captioning (arxiv.org)
原文笔记
What:
《Vid2Seq: Large-Scale Pretraining of a Visual Language Model for Dense Video Captioning》
作者提出一种多模态的单阶段的密集视频描述模型Vid2Seq
Vid2Seq模型的特点:
1、是单阶段模型,能够同时输出序列中事件边界和文本描述。
2、在大规模的叙述视频(没有真值事件标注的视频上)上进行预训练。
3、使用特殊的时间标记(time tokens)增强了语言模型。
4、综合运用了多模态信息 用了两个Encoder(Vision Encoder和语言转录Encoder)
5、在 以文本段落描述整个视频和视频剪辑描述上都有这出色的表现
6、具备很强的泛化性,使用作者提供的few-shot方法更改设置就可以很好的将Vid2Seq模型应用到下游任务上
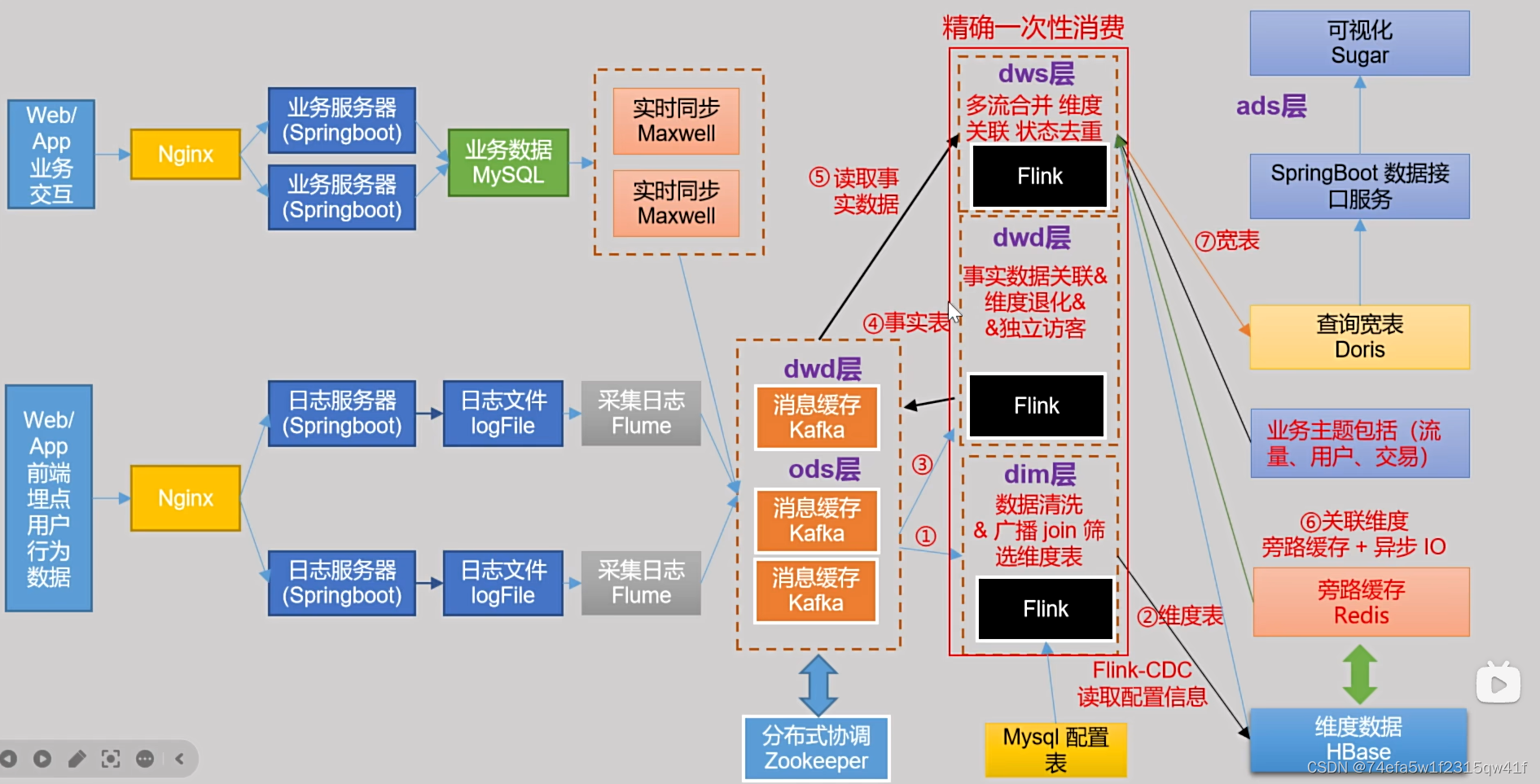
我们做出了以下贡献:(i)我们引入了Vid2Seq模型用于密集视频描述任务。给定多模态输入(转录的语音和视频),Vid2Seq预测一个离散令牌的单一序列,其中包括caption tokens与表示事件时间戳的特殊时间令牌,特殊时间令牌穿插在描述令牌之中。(ii)我们证明了未标记的视频中转录的语音和相应的时间戳可以有效地用作密集视频字幕的弱监督信息来源。(iii)最后,我们的预训练Vid2Seq模型提高了三个密集视频字幕数据集(YouCook2, ViTT, ActivityNet Captions),两个视频段落字幕基准(YouCook2, ActivityNet Captions)和两个视频剪辑字幕数据集(MSR-VTT, MSVD)的技术水平,并且经过few-shot设置在其他的下游任务上也表现得很好。
PS:还是在Transformer的基础上改变的模型架构,就是预训练思路还比较新颖,但是就多模态来说有点取巧,说的few-shot也不是多高大上的工作,模型图画的不错,一看就能看懂。
Why:
1、两阶段模型缺乏定位任务与字母任务的之间的交互,不能充分利用提取到的信息,并且下游任务严重受到上游任务效果的影响。
2、单阶段模型往往需要引入特定于任务的组件,比如事件计数器Event counter
3、无论是单阶段模型还是双阶段模型,当前都只在有限大小的人工标注数据集上进行训练,此外,为视频收集密集字幕的手动注释是昂贵的,并且在规模上令人望而却步。而不充足的训练数据不能够发挥模型的最佳性能。
Challenge:
密集视频字幕的目标是在未修剪的输入视频中使用自然语言对所有事件进行时间定位和描述。因此,
1、一个关键的挑战是有效地对视频中不同事件之间的关系进行建模,
为了增强事件定位和描述生成任务之间的交互,作者选择继续开发单阶段模型,因此
如何避免引入特定于任务的组件(以前任务的缺陷,比如许多模型都会引入event counter)以简单的模型实现高效的表现就是新的挑战
2、另一个关键挑战是手动收集此任务的注释特别昂贵。需要找到解决数据集不足,补充数据集的方法
2中(我们提出通过利用大规模很容易获得的未标记叙述视频来预训练Vid2Seq。为此,我们将转录语音的句子边界重新表述为伪事件边界,并使用转录后的语音句子作为伪事件标题。)同样面临着转录的语音可能无法真实的地描述视频内容,并且通常与视觉流在时间上错位 这样的挑战。
Idea:
1、为了更好的构建单阶段模型,
3、为了解决可用训练数据不足,我们提出通过利用大规模很容易获得的未标记叙述视频来预训练Vid2Seq。为此,我们将转录语音的句子边界重新表述为伪事件边界,并使用转录后的语音句子作为伪事件标题。
Model:

模型图还是比较好理解的,前文中所总结的细节请看下面的原文翻译。
原文翻译
Abstract
在这项工作中,我们引入了Vid2Seq,这是一种多模态单阶段密集事件字幕模型,它在大规模可用的叙述视频上进行了预训练,Vid2Seq 架构使用特殊的时间标记(time tokens)增强了语言模型,使其能够同时预测同一输出序列中的事件边界和文本描述。这种统一的模型需要大规模的训练数据,这在当前的注释数据集中是不可用的。我们表明,通过将转录语音的句子边界重新表述为伪事件边界,并使用转录的语音句子作为伪事件字幕,可以利用未标记的叙述视频进行密集视频字幕。在 YT-Temporal-1B 数据集上预训练的生成的 Vid2Seq 模型在各种密集视频字幕基准上(包括 YouCook2、ViTT 和 ActivityNet Captions。)展现出了最先进的水平,Vid2Seq 还可以在很少的设置改动下很好地推广到视频片段字幕和视频帧描述的任务,我们的代码可在 [1] 公开获得。
1.Introduction
密集视频字幕需要未裁剪视频中所有事件的时间定位和字幕生成[46,102,131]。这与目标是为给定的短视频剪辑生成单个标题的标准的视频字幕生成任务 [63,70,80] 不同。密集字幕要困难得多,因为它增加了在几分钟长视频中定位事件的额外复杂性。然而,它也受益于远程视频信息。该任务在大规模视频搜索和索引等应用中可能非常有用,这些应用中视频内容没有被分割成片段。
现有的方法大多采用两阶段方法[37,46,100],首先对事件进行定位,然后进行描述生成。为了进一步增强事件定位和字幕之间的任务间交互,一些方法引入了联合解决这两个任务的模型[20,102,131]。然而,通常这些方法仍然需要特定于任务的组件,如事件计数器[102]。此外,它们只在有限大小的人工标注数据集上进行训练[35,46,130],这使得很难有效地解决任务。为了解决这些问题,我们从最近在Web数据上预训练的序列到序列模型中获得启发,这些模型在广泛的视觉和语言任务中取得了成功[4,11,13,105,117]。
首先,我们提出了一个视频语言模型,称为Vid2Seq。我们从一个经过Web文本训练的语言模型开始[78],并在视频中添加了表示时间戳的特殊时间标记。给定视频帧和转录的语音输入,生成的模型通过生成单个离散令牌序列,共同预测所有事件标题及其相应的时间边界,如图1(右)所示。因此,这样的模型有可能通过注意力学习视频中不同事件之间的多模态依赖关系[94]。然而,这需要大规模的训练数据,这在当前密集的视频字幕数据集中是不可用的[35,46,130]。此外,为视频收集密集字幕的手动注释是昂贵的,并且在规模上令人望而却步。
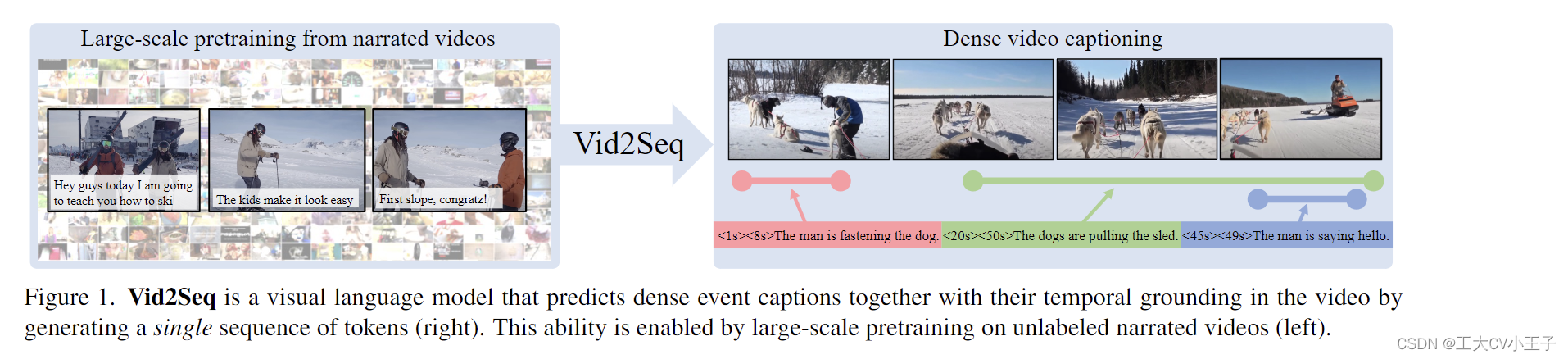
因此,我们提出通过利用大规模很容易获得的未标记叙述视频来预训练Vid2Seq。为此,我们将转录语音的句子边界重新表述为伪事件边界,并使用转录后的语音句子作为伪事件标题。然后,我们使用生成目标预训练 Vid2Seq,这需要在给定视觉输入和去噪目标(覆盖了转录语音的跨度)的情况下预测转录的语音,请注意,转录的语音可能无法真实的地描述视频内容,并且通常与视觉流在时间上错位[32,43,71]。例如,从图 1(左)中的示例可以看出,穿着灰色服装的滑雪者已经从最后一个语音句子后下了一个斜坡,但是这句话是在他实际下降斜率之后说的。直观地说,Vid2Seq 特别适合从此类嘈杂的监督中学习,因为它联合建模视频中的所有叙述和相应的时间戳。
我们通过大量的实验证明了我们的预训练模型的有效性。我们展示了对未修剪的解说视频进行预训练的重要性,Vid2Seq同时使用视觉和语音模式的能力,预训练目标的重要性,联合标题生成和定位的好处,以及语言模型大小和预训练数据集规模的重要性。预训练的Vid2Seq模型在各种密集视频字幕基准上达到了最先进的性能[35,46,130]。我们的模型在生成描述视频的文本段落方面也表现出色:在推理时不使用真实事件建议,我们的模型优于所有先前的方法,包括那些依赖于这些建议的方法[50,76,128]。此外,Vid2Seq可以很好地泛化到视频剪辑字幕的标准任务中[9,109]。最后,我们引入了一个新的few-shot密集视频字幕设置,在这个设置中,我们在一小部分的下游训练数据集上微调我们的预训练模型,并在这个设置中显示Vid2Seq的好处。
(zero-shot是不做更改直接将预训练模型应用到下游任务,对应的few-shot就是将预训练模型做一点更改再应用到下游任务上)
综上所述,我们做出了以下贡献:(i)我们引入了Vid2Seq模型用于密集视频描述任务。给定多模态输入(转录的语音和视频),Vid2Seq预测一个离散令牌的单一序列,其中包括caption tokens与表示事件时间戳的特殊时间令牌,特殊时间令牌穿插在描述令牌之中。(ii)我们证明了未标记的视频中转录的语音和相应的时间戳可以有效地用作密集视频字幕的弱监督信息来源。(iii)最后,我们的预训练Vid2Seq模型提高了三个密集视频字幕数据集(YouCook2, ViTT, ActivityNet Captions),两个视频段落字幕基准(YouCook2, ActivityNet Captions)和两个视频剪辑字幕数据集(MSR-VTT, MSVD)的技术水平,并且经过few-shot设置在其他的下游任务上也表现得很好。
我们用Jax实现的基于Scenic库的代码[19]公开发布在[1]。
2.Related Work
Dense video captioning.
密集视频字幕位于事件定位[25、29、33、62、65、66、84、127]和事件字幕[30、63、75、97、104]的交叉点。现有的大多数密集视频字幕方法[37,38,46,100,103]都是由时间定位阶段和事件字幕阶段组成的。(双阶段)为了丰富任务间的交互,最近的研究[8,10,20,61,73,79,82,83,100,102,131]联合训练了字幕和定位模块。特别是Wang等人[102]提出将密集视频字幕视为一组预测任务,并对每个事件并行地联合执行事件定位和字幕。(单阶段)相反,我们的模型生成的事件边界和标题取决于先前生成的事件。Deng等人[20]建议首先生成一个段落,然后在视频中匹配段落中的每个句子。我们还将所有标题生成为单个输出序列,但是我们的输出已经包含了事件时间戳。Zhang等人[125]提出按顺序生成事件边界,但分别执行事件定位和单个事件字幕,并且只使用视觉输入。与我们的工作最相关的是,Zhu等人[133]也通过生成单个输出序列来执行密集的视频字幕。然而,他们的方法直接从转录语音的时间戳推断出事件的位置,因此,只能检测紧跟语音的事件。相比之下,我们的模型生成事件时间戳作为特殊令牌,并且可以为语音有限的视频生成密集的字幕,正如我们在ActivityNet字幕数据集上演示的那样。
Video and language pretraining.
随着图像-文本预训练的成功[14,21,23,24,28,34,36,39-41,53-55,58,60,68,69,85,88,92,93,99,11-120,124,129],最近的工作探索了视频-文本预训练[3-5,26,31,32,43,49,52,56,71,72,74,80,81,89,89,96,98,96,98,108,111,111,11122]。这些方法在各种任务中都显示出强大的改进,例如文本视频检索 [5,71]、视频问答 [112,122] 和视频剪辑字幕 [4, 80]。虽然这些工作大多学习全局视频表示来解决视频级预测任务,但我们在这里专注于学习详细的表示来解决密集预测任务,该任务需要对未修剪视频中的多个事件进行推理。一些工作已经探索了用于时间定位任务的长格式视频-文本预训练[90]和视频-文本预训练[7,48,64,106,110,116]。然而,这些工作侧重于视频理解任务,而我们的预训练方法是针对生成任务量身定制的,该任务不仅需要模型推理视频中的多个事件,还需要用自然语言描述它们。
一些工作探索了密集视频字幕的预训练。Zhang等人[125]用ActivityNet Captions数据集进行预训练,以提高使用同一数据集的下游任务的性能表现。相比之下,我们提出了一种不依赖任何手动注释的预训练方法,并展示其在多个下游数据上的优势,Huang等人[35]探索了叙述教学视频的预训练,但只考虑使用ground truth proposals进行事件描述,因为它们的模型不能处理事件定位(即他们的模型不包括预测event proposals)。最后,[35, 133] 探索特定领域纯文本数据集 [45] 的预训练。相比之下,我们提出对通用视频语料库 [121] 进行预训练,并展示在各个领域的优势。
Unifying tasks as language modeling.将任务统一为语言建模。
最近的工作[11-13、15、17、44、59、101、117、132]表明,可以将各种计算机视觉问题转换为语言建模任务,解决目标检测[11]、定位图像字幕[117]或视觉定位[132]。在这项工作中,我们还将视觉定位视为语言建模任务。然而,与之前专注于图像级空间定位的工作不同,我们在未修剪的视频中解决了事件时间定位的不同问题。
3 Method
密集视频字幕的目标是在未修剪的输入视频中使用自然语言对所有事件进行时间定位和描述。因此,一个关键的挑战是有效地对视频中不同事件之间的关系进行建模,例如,如果我们知道那人刚刚拴住了一只狗,那么更容易预测狗正在拉雪橇(见图 1(右))。此外,由于任务的密集性质,在一个长视频中可能有很多事件,要求是为每个事件输出一个自然语言描述。因此,另一个关键挑战是手动收集此任务的注释特别昂贵。为了应对这些挑战,我们首先开发了一个统一的多模态模型,该模型将事件边界和标题联合预测为单个标记序列,如第 3.1 节和图2所述。其次,我们设计了一种预训练策略,通过将句子边界重新表述为伪事件边界,有效地利用来自未标记叙述视频的转录语音形式的跨模态监督,如第 3.2 节和图3所述。
3.1.Model
我们希望设计一个密集视频字幕模型,该模型可以使用视觉和(转录)语音线索捕获事件之间的关系,以便在未修剪的几分钟长视频中有效地定位和描述这些事件。为了应对这一挑战,我们将密集视频字幕转换为序列到序列的问题,其中输入和输出序列同时包含自然语言描述形式的有关事件的语义信息和时间戳形式的事件的时间定位。此外,为了最好地利用视觉和语言信号,我们开发了一个适当的多模态编码器-解码器架构。,正如图2所示的那样,我们的架构取输入视频帧x = {xi} i=1->F和转录的语音序列= {yj} j=1->S。我们模型的输出是一个事件序列= {zk}k=1->L,其中每个事件都包含其文本描述和与视频中时间事件位置相对应的时间戳。下面我们将解释为我们的模型构建的转录语音和事件序列的结构以及我们的模型体系结构的细节。
序列构建。为了对密集事件字幕注释中的事件间关系进行建模(或现成的转录叙述,参见第 3.2 节),我们将密集视频字幕转换为预测标记 z 的单个输出序列。该输出事件序列通过利用 用特殊时间标记增强的 文本标记器来构建。此外,我们通过以与事件序列 z 类似的方式构建输入转录序列 y 来联合推理输入叙述转录本中提供的语义和时间信息。接下来给出详细信息。
时间标记化。我们从词汇量为 V 的文本标记器开始,并用 N 个额外的时间标记对其进行扩充,从而产生具有 V + N 个标记的标记器。时间标记表示视频中的相对时间戳,因为我们将持续时间 T 的视频量化为 N 个等间距的时间戳。具体来说,我们使用词汇量为 V = 32、128 和 N = 100 的 SentencePiece 分词器 [47]。
事件序列。我们引入的标记器使我们能够构建包含视频时间戳和文本视频描述的序列。接下来,我们解释了我们如何构造输出事件序列 z。请注意,在标准密集视频字幕数据集中,视频具有可变数量的事件 [35, 46, 130]。每个事件 k 都由一个文本段、开始时间和结束时间来表征。我们首先通过连接每个事件 k 的起始时间标记 tstartk 、其结束时间标记 tendk及其文本标记 [zk1, ..., zklk]为每个事件k构成一个序列。然后我们按照它们开始时间的增序顺序对所有这些序列进行排序并将它们连接起来。事实上,每个文本段都以指示不同事件之间分离的点符号结束。最后,通过在序列之前添加BOS令牌和在末尾附加一个EOS 令牌来分别表示序列的开始和结束,即 z = [BOS, tstart1, tend1, z11 , ..., z1l1 , tstart2 ,..., EOS]。
转录的语音序列。为了使模型同时使用转录的语音及其相应的时间戳,我们将语音转录转换为语音序列 y,类似于输入训练密集事件字幕 z。这是通过将原始语音转录用Google Cloud API1分割成句子来完成的,并使用每个转录的语音句子及其对应的时间戳,类似于先前解释过的事件的处理过程。
架构。我们希望设计一个架构,可以有效地建模未修剪的长视频中不同事件之间的关系。为了应对这一挑战,我们提出了一种多模态编码器-解码器架构,如图 2 所示,该架构逐步细化和输出上述事件序列。具体来说,给定一个未修剪的分钟长视频,视觉编码器 f 嵌入(embedding)其帧,而文本编码器 g 嵌入转录的语音和相应的时间戳。然后文本解码器 h 使用视觉和转录的语音嵌入预测事件边界和文本字幕。接下来描述各个模块。


文本初始化。我们使用 T5-Base [78] 初始化文本编码器和文本解码器,该解码器已在具有去噪损失的 Web 文本语料库上进行了预训练。因此,它们的实现和参数也紧跟 T5-Base,例如他们使用相对位置嵌入并共享它们的令牌嵌入层 gs = hs ∈ R(V +N )×d。
3.2.Training
在本节中,我们将描述如何利用大量未标记的叙述视频来训练前面描述的密集事件字幕模型。我们首先提出了预训练方法,用于在3.2.1节和图3中现成的叙述视频中使用跨模态监督有效地训练Vid2Seq。然后,我们解释了我们如何为各种下游任务微调我们的架构,包括第3.2.2节中的密集事件字幕。
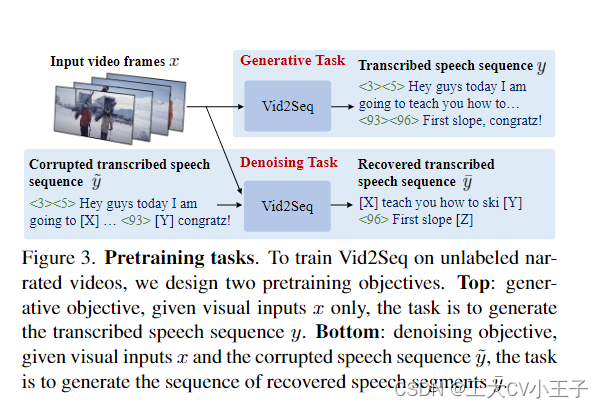
3.2.1 Pretraining on untrimmed narrated videos
我们希望利用解说视频进行预训练,因为它们在规模上很容易获得[72,121]。然而,这些视频不包含密集的事件字幕注释。因此,我们使用转录的语音句子及其相应的时间戳作为监督信号。由于语音记录并不总是基于视觉,并且经常暂时错位[32,43,71],我们注意到它们只能提供弱监督。此外,语音抄本与密集的事件字幕注释有很大的不同。例如,在YT-Temporal-1B数据集[121]中,一个视频平均包含120个语音句子,这比标准密集视频字幕数据集中的事件数量多出一个数量级[35,46,130]。我们的Vid2Seq模型特别适合使用这种弱监督,因为它将语音序列构建得类似于人工注释的事件序列,并在可能长达几分钟的视频级别(参见3.1节)上联合上下文化语音边界和语义信息,而不是在更短的剪辑级别上,使我们的模型能够学习不同语音段之间的长期关系。在实验中,我们表明,对整个几分钟长的视频进行预训练是非常有益的。
接下来,我们描述了两个提议的训练目标,它们都基于最大似然目标。形式上,给定视觉输入 x、编码器文本序列 y 和解码器目标文本序列 z,两个目标都基于最小化以下损失:

生成目标。这个目标使用转录的语音作为(伪)监督信号来教解码器在给定视觉输入的情况下预测一系列事件。给定输入到编码器的视频帧 x,解码器必须预测转录的语音序列 y(见图 3),作为代理密集事件字幕注释。请注意,此任务的编码器没有给出文本输入,因为同时使用转录语音作为输入,目标会导致模型学习纯文本快捷方式。
去噪目标。由于生成代理任务的编码器没有给出文本输入,因此生成目标只训练视觉编码器和文本解码器,而不是文本编码器。然而,当我们的模型用于密集视频字幕时,文本编码器在对语音转录本进行编码时具有显着的重要性。因此,我们引入了一个去噪目标,旨在联合对齐视觉编码器、文本编码器和文本解码器。受文本域中的 T5 [78] 的启发,我们以概率 P 和平均跨度长度 M 随机屏蔽转录语音序列中(文本和时间)标记的跨度。编码器输入由视频帧 x 和损坏的语音序列 ̃y 组成,其中包含唯一识别掩码跨度的哨兵标记。然后,解码器必须根据视觉输入 x 和语音上下文 ̃y 为每个哨兵标记生成相应的掩码跨度构建的序列 ̄y(见图 3)。
3.2.2 Downstream task adaptation
我们的架构和任务公式使我们能够使用通用语言建模训练目标和推理过程来解决密集视频字幕。请注意,作为我们通用架构副产品,我们的模型还可以用于通过简单地从输出序列中删除时间标记来生成关于整个视频的段落,并且还可以在相同微调和推理方法的处理下轻松适应视频剪辑字幕。
微调。为了对我们的模型进行微调以进行密集视频字幕,我们使用基于事件序列的最大似然目标(参见公式 1)。给定视频帧 x 和语音转录本 y,解码器要预测事件序列 z。
推理。文本解码器通过从模型似然中采样自回归生成事件序列。在实践中,我们使用波束搜索,因为我们发现与 argmax 采样或核采样相比,它提高了字幕质量。最后,通过简单地反转序列构建过程,将事件序列转换为一组事件预测。
4.Experiments
略