3月29日长安链可验证数据库技术架构和代码解读中,北京大学博士后研究员高健博带开发者一起了解了长安链可验证数据库的应用背景、设计实现方式和功能代码结构。
数据存证以及通过智能合约进行数据共享是目前联盟链最直接、最广泛的应用场景。在很多存证场景中,需要上链的数据量特别大,但是数据价值密度并不高,相比于完全的链上存储,通过一定的链下存储并在链上进行验证,能够降低存储成本且保障数据权限,但是链下存储需要保证数据可信及其完整性。链下存储背景介绍中,高健博分析了链下存储的具体环节以及环节中存在的问题(视频约0-9分钟)。
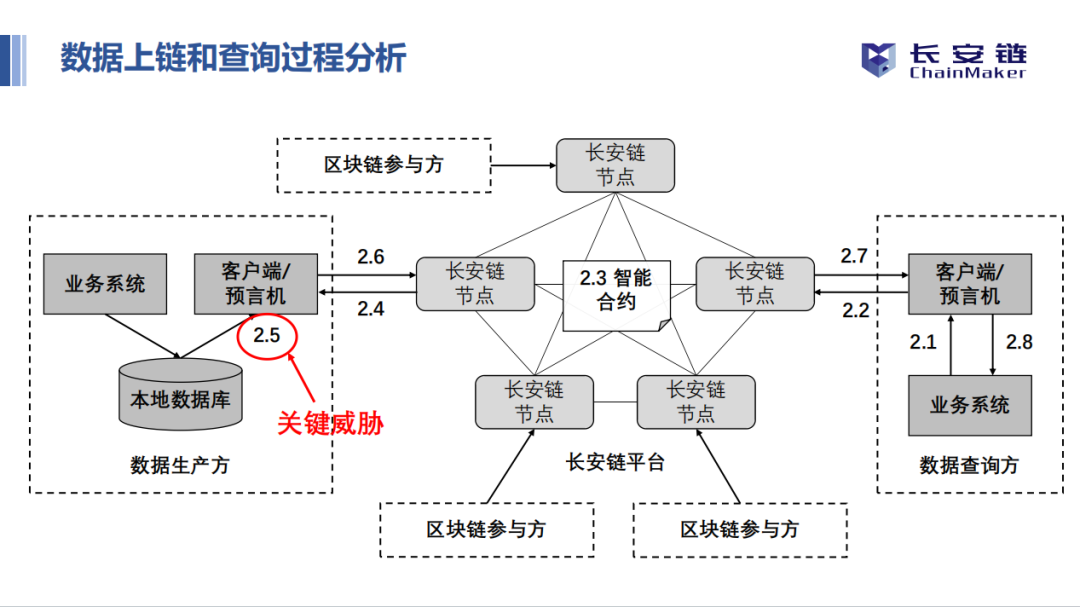
可验证数据库介绍环节,高健博博士分享了区块链、数据库的数据结构与链下数据存储完整性的定义,着重介绍了保证数据完整性的5种方案,其中Merkle B+树索引结构的可验证数据库兼顾了数据完整性的三个方面:正确性、真实性、全面性(视频约9-29分钟)。
设计实现方式介绍环节高健博博士分享了可验证数据库的链上链下交互过程。可验证数据库是作为MySQL插件开发的存储引擎,已经提供了完善的技术文档和相对完备的组件,目前主要适配了长安链2.3.1版本。高健博博士分享了可验证数据的具体使用方式,并通过视频进行了直观展示(视频约29-45分钟)。
最后代码解读环节介绍了可验证数据的代码目录结构和文件功能划分以及具体的代码内容(视频约45-50分钟)。
直播精彩问答
1.请问proof包括什么内容?请讲一下具体的验证过程,谢谢!
答:可验证数据库的证明主要包括Merkle证明和范围证明,其中范围证明是超出查询条件且与查询结果连续的两端数据,只需要通过比较查询条件即可;Merkle证明是查询结果及范围证明到Merkle根的路径,验证时需要重新计算hash,然后与Merkle根进行比较。
2. 只能验证查询条件是ID的记录吗?审计业务过程中查询条件很少是ID,可能是地区,年龄等。业务数据产生时可能不知道查询条件是什么?
答:直播中讲解查询条件为ID是为了便于理解,实际上只要是索引键都可以作为查询条件,但是推荐使用数字、字符串等分布较大且有序的键,例如年龄、编号等,不建议使用只有少数枚举值的字段,例如性别。
3. 把查询结果上链有必要吗,只发给在乎的参与对象可以么?
答:从验证查询结果的角度来说,不是必须上链的,也可以通过链下发送查询结果和证明。但是上链能够带来两个好处:一是发起链下查询的重要目的就是保证结果可信,上链之后能够让查询结果和证明具备抗抵赖等特性;二是通过智能合约封装了查询结果及证明的验证功能,降低开发难度和成本,所以还是推荐通过上链方式实现可验证数据库查询。
4. 树的大小有限制吗,如果数据比较多,数据的增删会不会引起比较大的开销?
答:树的大小限制和开销都是与传统关系型数据库的B+树一致的,额外的开销仅在Merkle树的更新时产生。Merkle树不会再数据增删改时实时更新,只在数据库管理员触发生成可验证版本(类似传统关系型数据库备份或快照)时才会进行批处理,这一过程可以在凌晨等业务低谷时进行。