XTuner 微调 LLM:1.8B、多模态、Agent——笔记
- 一、Finetune 简介
- 1.1、两种 Finetune 范式
- 1.2、一条数据的一生
- 1.2.1、标准格式数据
- 1.2.2、添加对话模板
- 1.2.3、LoRA & QLoRA
- 二、XTuner
- 2.1、XTuner 简介
- 2.2、LLaMA-Factory vs XTuner
- 2.3、XTuner 数据引擎
- 2.3.1、数据处理流程
- 2.3.2、数据集映射函数
- 2.3.3、对话模板映射函数
- 2.3.4、多数据样本拼接
- 2.4、训练技巧
- 2.4.1、Flash Attention
- 2.4.2、DeepSpeedZero
- 三、多模态 LLM
- 3.1、多模态原理
- 3.2、多模态实现——LLaVA
详细视频:XTuner 微调 LLM:1.8B、多模态、Agent
一、Finetune 简介
1.1、两种 Finetune 范式
LLM的下游应用中,增量预训练 和 指令跟随 是经常会用到两种的微调模式。
- 增量预训练微调
使用场景:让基座模型学习到一些新知识,如某个垂类领域的常识。
训练数据:文章、书籍、代码等。 - 指令跟随微调
使用场景:让模型学会对话模板,根据人类指令进行对话。
训练数据:高质量的对话、问答数据。

可以看到,增量预训练更多的只是将某种知识喂给模型,让模型学会这个知识,但怎么用,模型此时还是不知道的。然后,指令跟随微调就会训练模型,让模型学会对话模板,当想它问出问题的时候,模型就会运用自己的知识来解答。
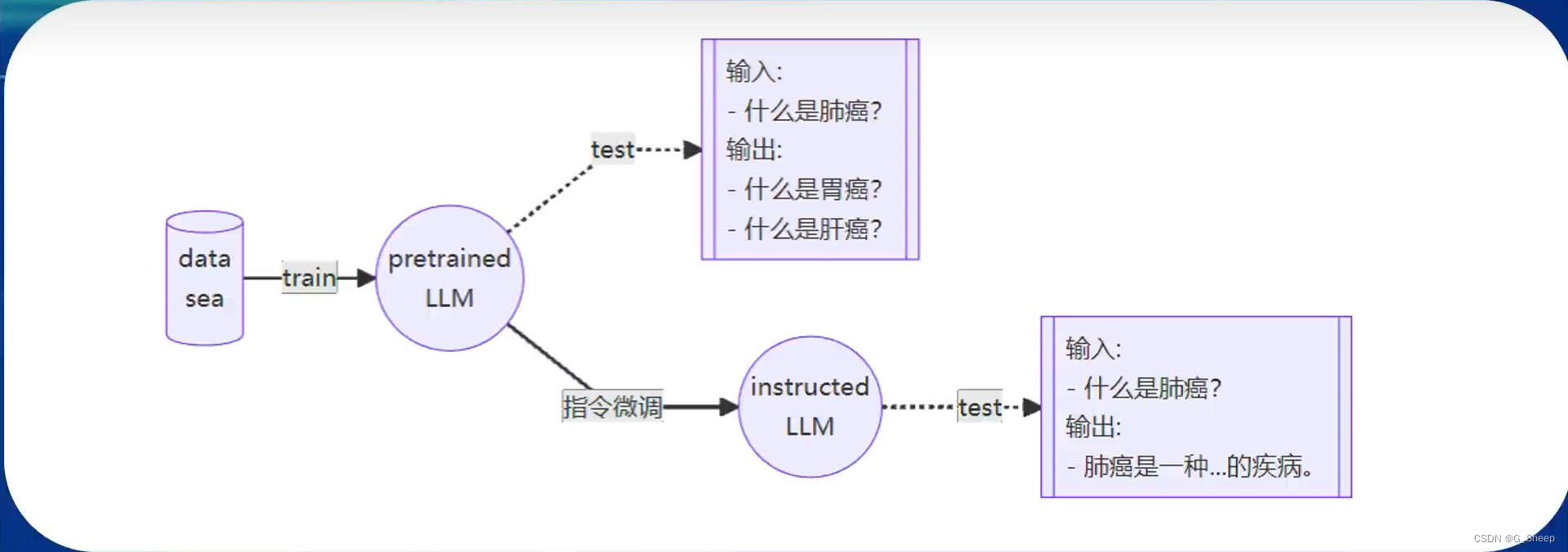
如上图,一个基座模型如果只经过增量预训练,它是不能意识到此时是在问它问题的,它只能理解可能需要输出一个和问题类似的回答,但经过指令跟随微调以后,它就能明白使用者是在问问题,此时就会输出对应的回答
1.2、一条数据的一生

1.2.1、标准格式数据
首先,可以从书籍、代码或者爬虫获取最原始的数据,比如 “世界最高峰是珠穆朗玛峰”,此时,这条原始数据是不能直接拿去训练的,需要改造成以下格式:

以上就是标准格式数据。那么什么是标准格式数据?就是我们的训练框架能够识别的数据。
首先,需要一个 System 角色,算是给模型设定的一个前置条件,这个设定也是需要提示词工程的实验的,然后这个 System 角色会赋予 Assitant 一个角色:你是一名 AI 助手。
当 User 说 “你好!” 的时候,再提供一个模型应该回答的内容。然后,再提问一个跟原始数据有关的问题,所期待模型回答部分,即答案部分,就是刚刚初试获得的原始数据。
在 XTuner 框架中,是按照以下 json 格式存储的:

按照视频的讲解,我的理解是:一条原始数据,需要我们手动改写成上面五条对话数据的格式,而后面两个问题的对话结果都是我们设置好的,算是标准答案,也就是说,我们希望模型训练好以后面对同样的问题时能回答以上输出,如果不是,即有了差异,那么就可以基于此计算损失,通过不断训练调整将损失减少到最小。
1.2.2、添加对话模板
对话模板:为了能够让 LLM 区分出 System、User 和 Assistant,不同的模型会有不同的模板。

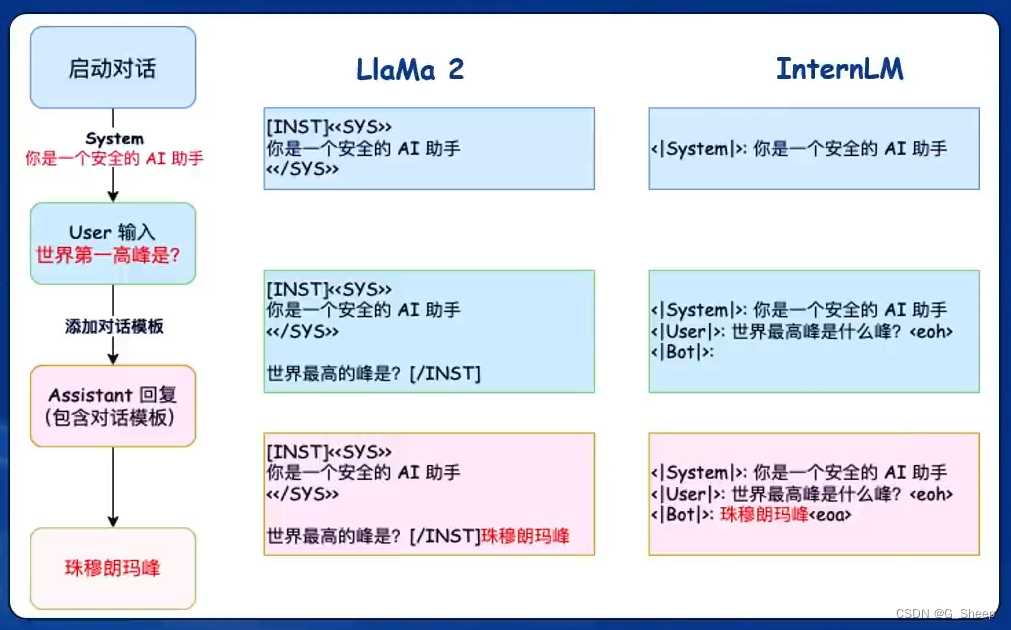
在上面一节中,只是 conversation 代码中是那么写的,但实际上,我们喂给模型的,是上图中的格式,也就是说,数据需要和模板拼接在一起才能喂给模型。
XTuner 框架已经将组装的步骤打包好了,只要一键启动即可,我们需要准备的,就是包含 conversation 的 json 文件。
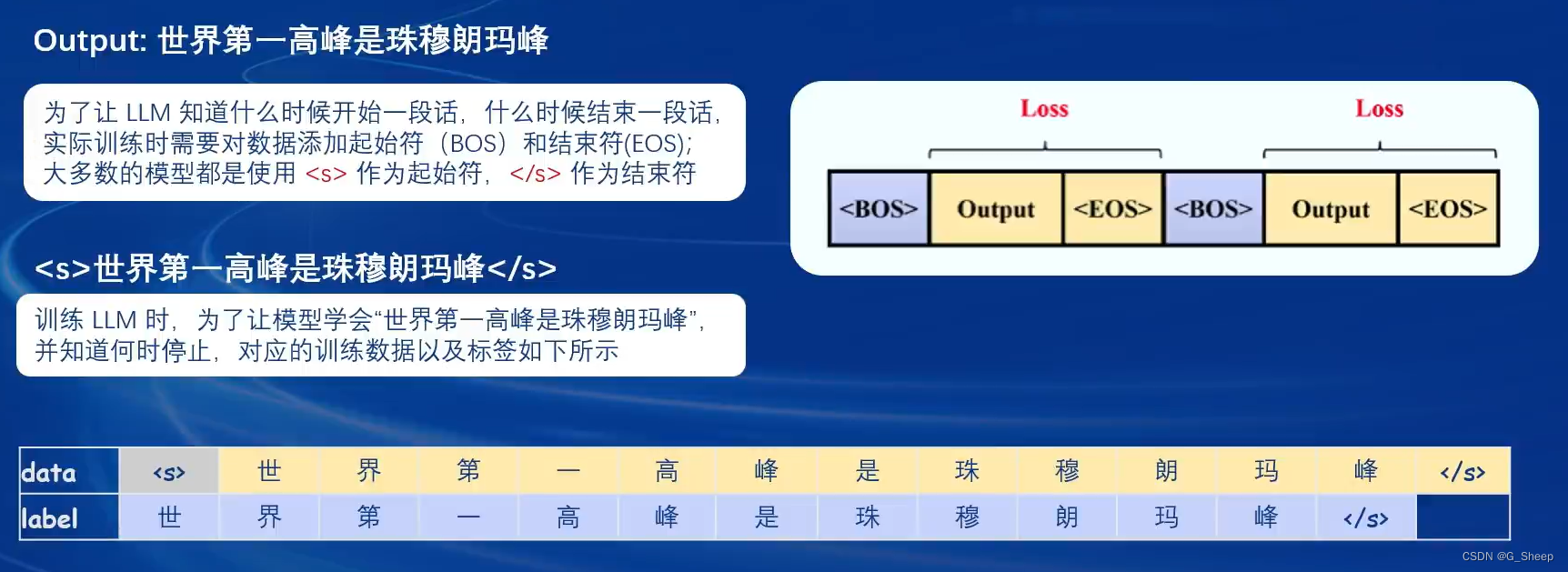
以下是对对话模板的详细解释:

1.2.3、LoRA & QLoRA
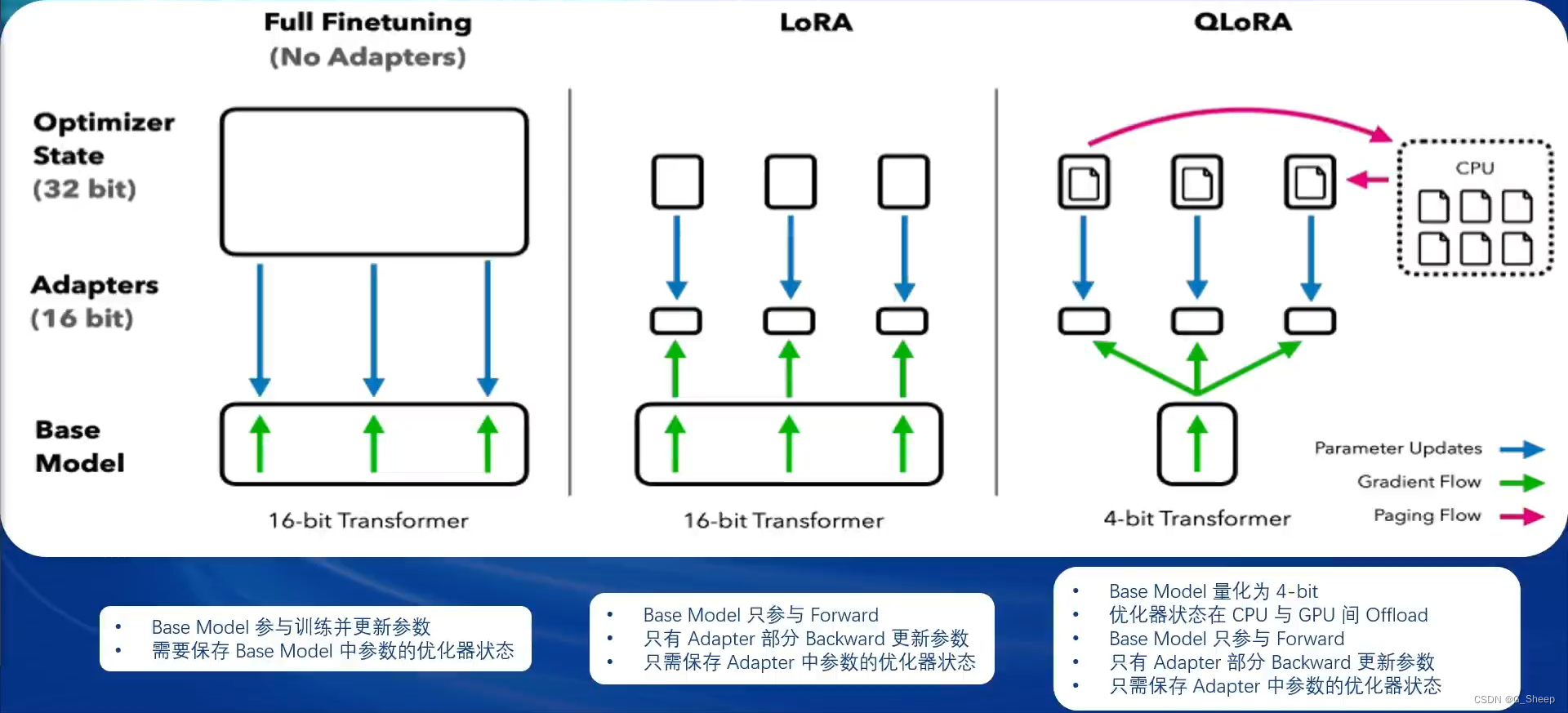
在 XTuner 中,主要使用 LoRA 和 QLoRA 两种微调方案。

LLM 的参数量主要集中在模型中的 Linear,训练这些参数会耗费大量的显存,LoRA 通过在原本的 Linear 旁,新增一个支路,包含两个连续的小 Linear,新增的这个支路通常叫做 Adapter。Adapter 参数量远小于原本的 Linear,能大幅降低训练的显存消耗。
我的理解是:想象一下,现在有一幅铅笔画,但这副画的阴影、背景、细节等部分还不够好,你可以选择通过使用铅笔慢慢构思,一点点这些细节补充完善,但显然,这并不是一件轻松的事,并且因为不断地增加线条,导致整个画看起来有点杂乱,现在,有一种笔,专门应用于处理这些阴影、细节部分,他有一个特殊的笔尖,可以更细致地描绘细节。虽然这个小笔只能在需要增加阴影和细节的地方使用,但由于它很小巧,所以不会占用太多的空间。总结来说,怎么使用尽可能少的步骤、过程,就能达到和原来差不多的结果,这就是我理解的 LoRA 原理。
横向比较 全参数微调、LoRA 微调 和 QLoRA 微调。
二、XTuner
XTuner,书生 · 浦语开发的微调框架,是一个已经打包好的大模型微调工具箱,具有以下两个特点:
- 傻瓜化。以配置文件的形式封装了大部分微调场景,0基础的非专业人员也能一键开始微调。
- 轻量级。对于 7B 参数量的 LLM,微调所需的最小显存仅为 8GB。
2.1、XTuner 简介

2.2、LLaMA-Factory vs XTuner
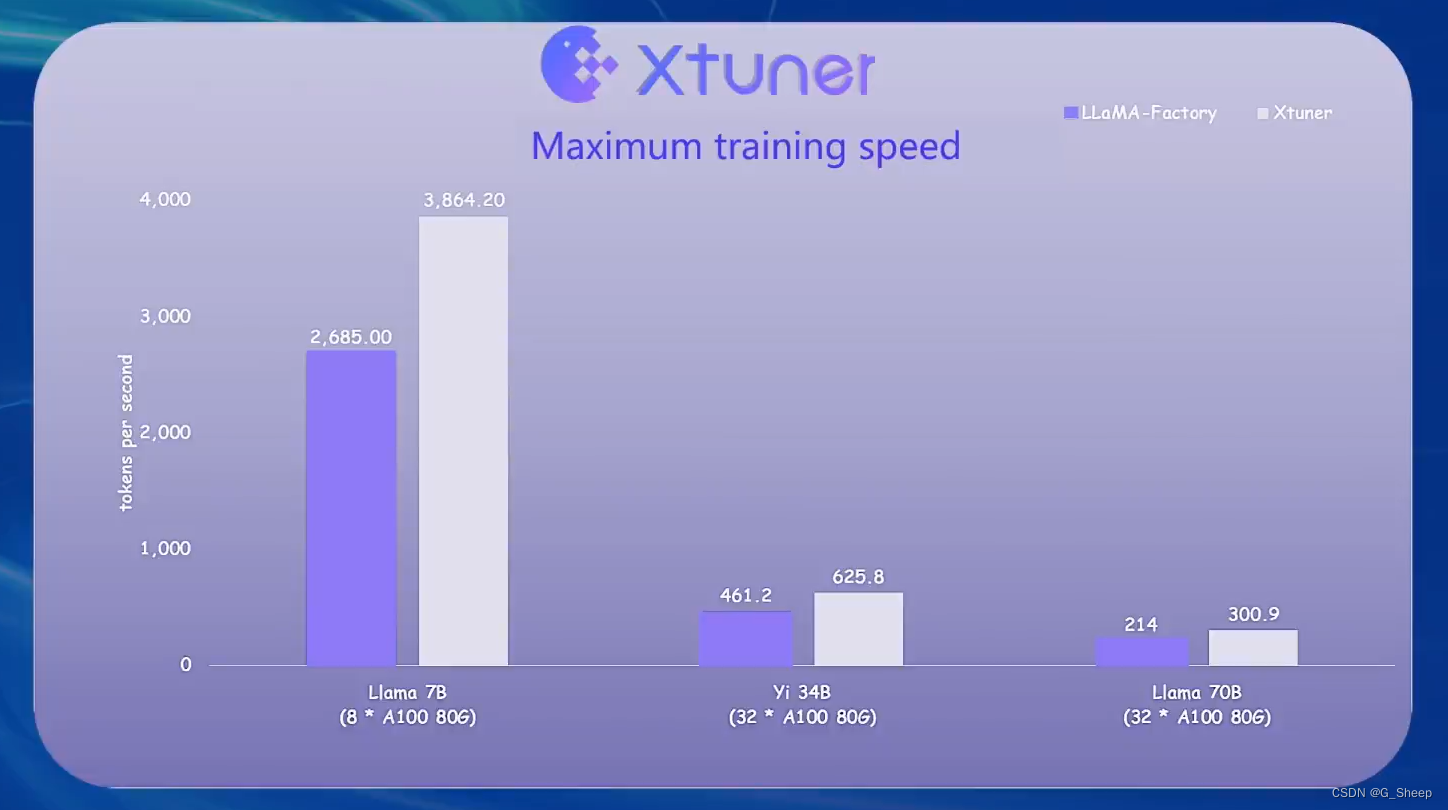
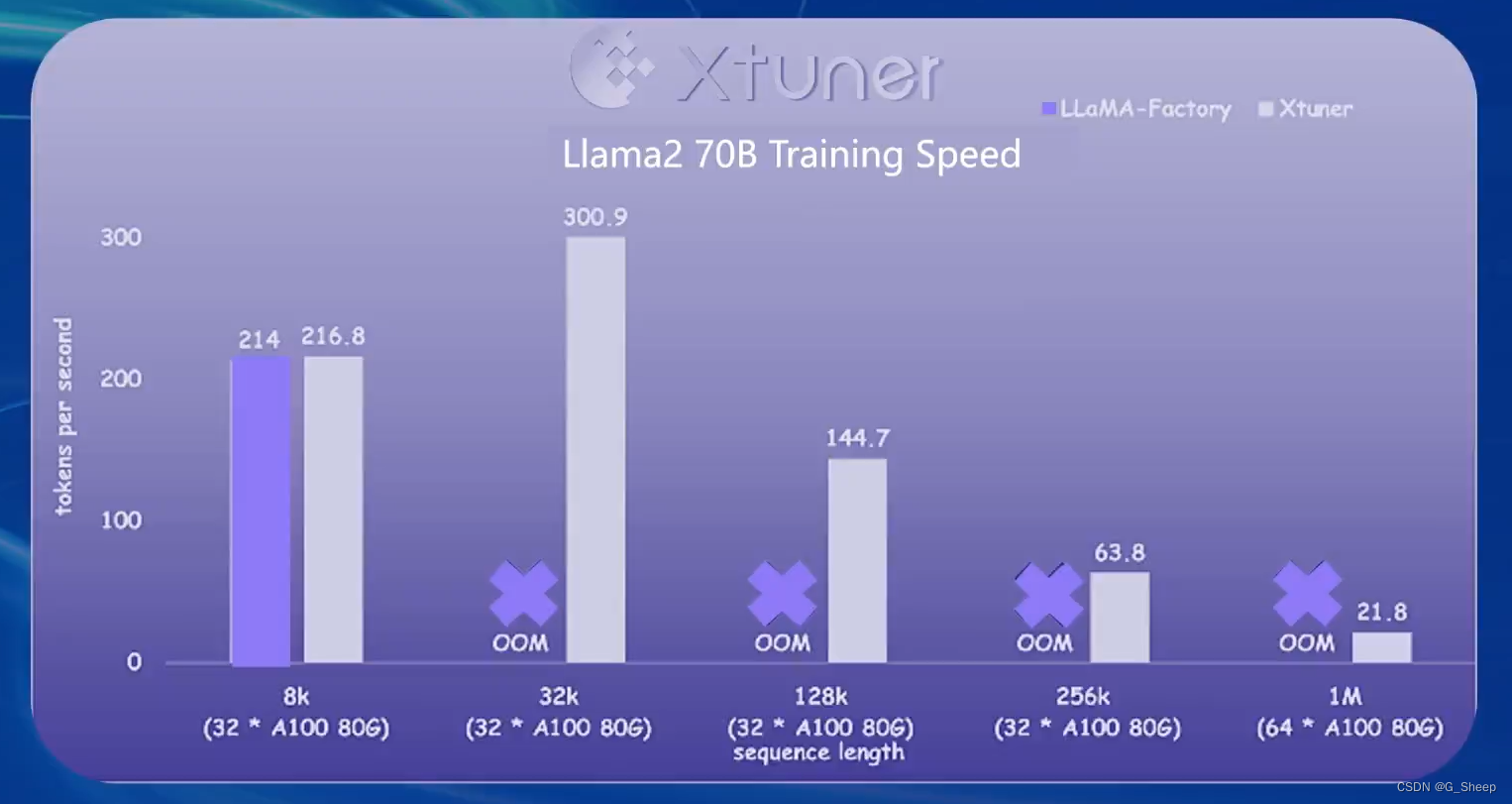
可以看到,在相同模型训练的情况下,当数据长度超过 32k 时,LLaMA-Factory 就出现了 OOM ( Out Of Memory ) 的情况,可见 XTuner 对性能优化、显存优化这一块做的是很不错的。
2.3、XTuner 数据引擎
2.3.1、数据处理流程
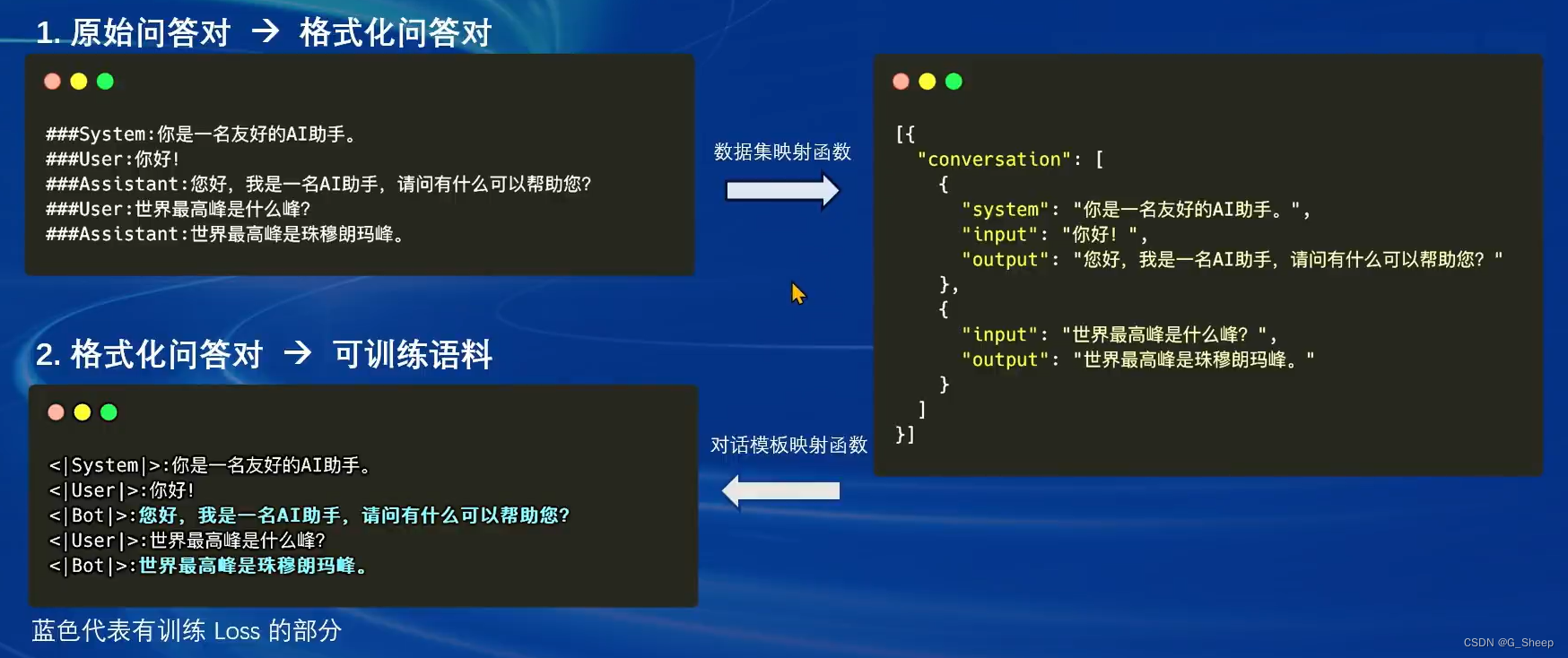
2.3.2、数据集映射函数
XTuner 内置了多种热门数据集的映射函数。

2.3.3、对话模板映射函数
XTuner 内置了多种对话模板映射函数。

所以对于使用者而言,就不需要再花费过多时间在数据预处理上面,还要思考对数据格式怎么修改,我们只要准备好原始的数据就好了。
2.3.4、多数据样本拼接
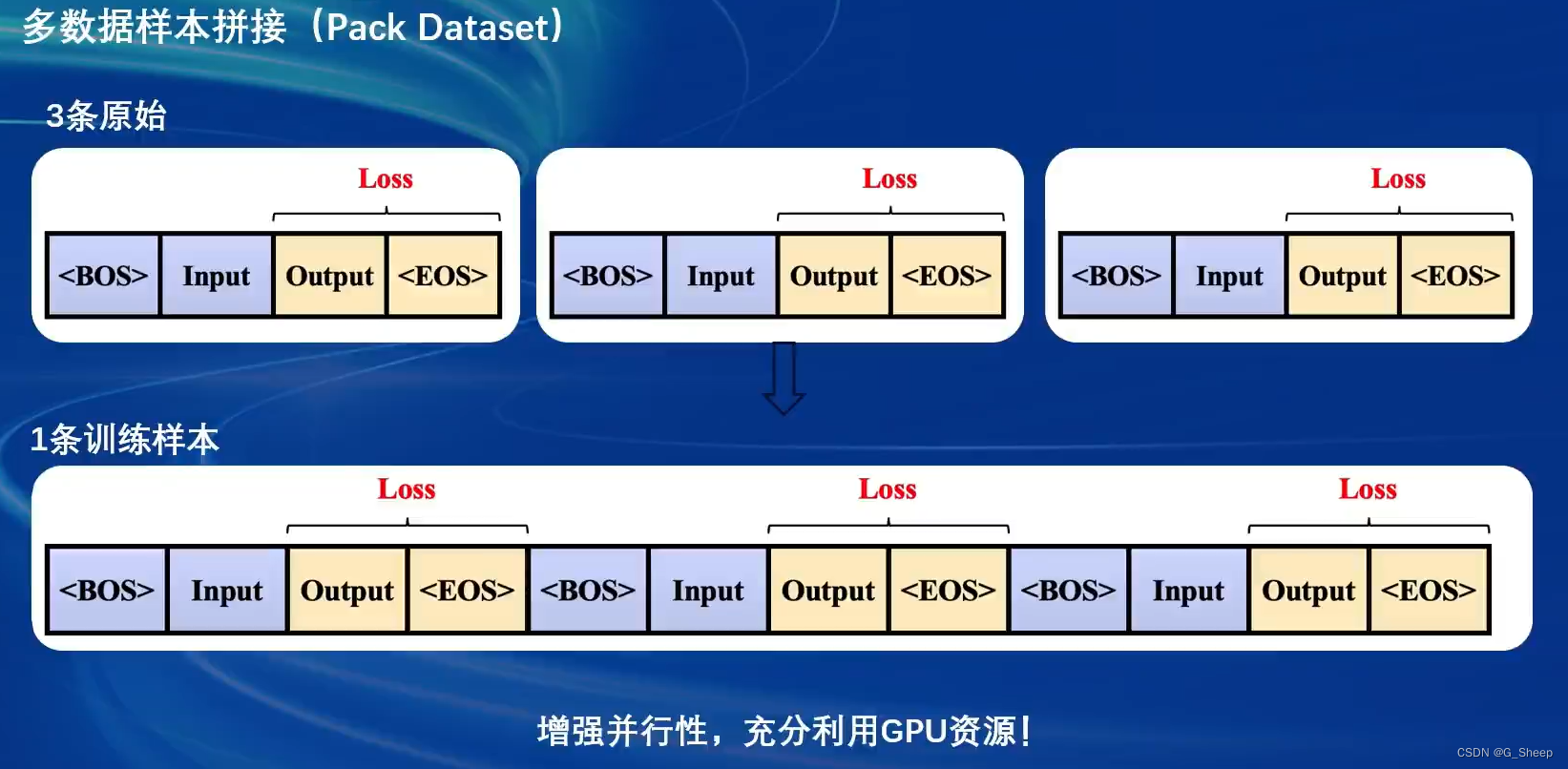
当程序运行,发现显存利用率并不是很高时,可以将参数 pack_to_max_length 设置为 True,即同意将多条短数据拼接到 max_length,单挑数据最大 token 数,超过则截断,能有效地利用显存资源,不会浪费。
2.4、训练技巧
XTuner 有两个很重要的训练技巧——Flash ATTention 和 DeepSpeedZero。
2.4.1、Flash Attention
Flash Attention 将 Attention 计算并行化,避免了计算过程中 Attention Score N * N 的显存占用( 训练过程中的 N 都比较大 )。
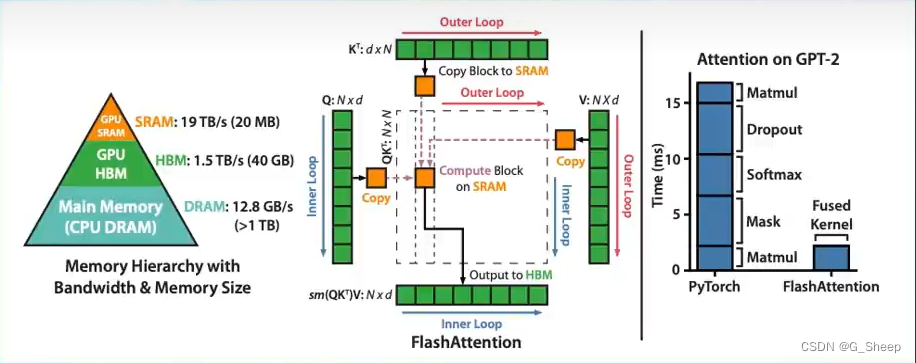
2.4.2、DeepSpeedZero
DeepSpeed 是一个深度学习优化库,由微软开发,旨在提高大规模模型训练的效率和速度。它通过几种关键技术来优化训练过程,包括模型分割、梯度累积、以及内存和带宽优化等。DeepSpeed 特别适用于需要巨大计算资源的大型模型和数据集。
在 DeepSpeed 中,zero 代表 “ZeRO”(Zero Redundancy Optimizer),是一种旨在降低训练大型模型所需内存占用的优化器。ZeRO 通过优化数据并行训练过程中的内存使用,允许更大的模型和更快的训练速度。ZeRO 分为几个不同的级别,主要包括:
- deepspeed_zero1:这是ZeRO的基本版本,它优化了模型参数的存储,使得每个GPU只存储一部分参数,从而减少内存的使用。
- deepspeed_zero2:在deepspeed_zero1的基础上,deepspeed_zero2进一步优化了梯度和优化器状态的存储。它将这些信息也分散到不同的GPU上,进一步降低了单个GPU的内存需求。
- deepspeed_zero3:这是目前最高级的优化等级,它不仅包括了deepspeed_zero1和deepspeed_zero2的优化,还进一步减少了激活函数的内存占用。这通过在需要时重新计算激活(而不是存储它们)来实现,从而实现了对大型模型极其内存效率的训练。
选择哪种deepspeed类型主要取决于你的具体需求,包括模型的大小、可用的硬件资源(特别是GPU内存)以及训练的效率需求。一般来说:
- 如果你的模型较小,或者内存资源充足,可能不需要使用最高级别的优化。
- 如果你正在尝试训练非常大的模型,或者你的硬件资源有限,使用deepspeed_zero2或deepspeed_zero3可能更合适,因为它们可以显著降低内存占用,允许更大模型的训练。
- 选择时也要考虑到实现的复杂性和运行时的开销,更高级的优化可能需要更复杂的设置,并可能增加一些计算开销。
三、多模态 LLM
3.1、多模态原理
在文本单模态中,基本就是以下流程。

某些时候,中间可能还要加上一个文本重排序模型。
而在文本 + 图像多模态的情况下,就是这样:
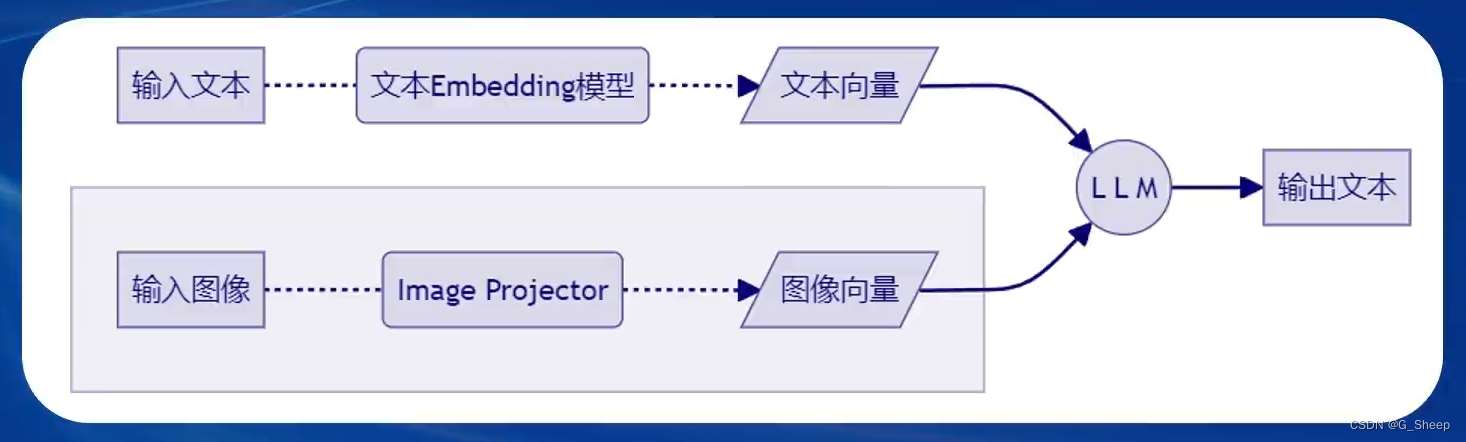
可以看到,此时 LLM 有两部分输入,第一部分就是文本单模态的路线,并没有什么变化,而第二部分则是对输入图像的处理。
如果依此类推的话,那么其实可以在上面多模态的基础上,再加一条“路径”,可以是对视频或者音频的处理,转换成 视频 / 音频向量。
3.2、多模态实现——LLaVA
Haotian Liu 等使用 GPT-4V 对图像数据生成描述,以此构建出大量 <question text><image> -- <answer text>的数据对,再利用这些数据对,配合文本单模态LLM,训练出一个 Image Project。
所使用的文本单模型LLM和训练出来的 Image Projector,统称为LLaVA模型。(这便是为了方便理解所以这么说,但实际上 LLaVA 不是这边说的这么简单)


![[RTOS 学习记录] 复杂工程项目的管理](https://img-blog.csdnimg.cn/img_convert/299e42a82bcfd1b79b68a9e95fba5a32.png#pic_center)
![[第一届 帕鲁杯 CTF挑战赛 2024] Crypto/PWN/Reverse](https://img-blog.csdnimg.cn/direct/cca0ad5a294b40378def6c701ceb43d8.png)