一、简单例子:构造简单NN网络生成Embedding
1、pytorch例子
2、tensorflow例子
# 1导入模块
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding
import numpy as np
# 2构建语料库
corpus=[
["The", "weather", "will", "be", "nice", "tomorrow"],
["How", "are", "you", "doing", "today"],
["Hello", "world", "!"]
]
# 3生成字典
#获取语料不同单词,并过滤掉一些字符如"!"
word_set=set([i for item in corpus for i in item if i!='!'])
word_dicts={}
#索引从1开始,0用来填充
j=1
for i in word_set:
word_dicts[i]=j
j=j+1
# 4用索引表示语料
raw_inputs=[]
for i in range(len(corpus)):
raw_inputs.append([word_dicts[j] for j in corpus[i] if j!="!"])
padded_inputs = tf.keras.preprocessing.sequence.pad_sequences(raw_inputs,padding='post')
print(padded_inputs)
# 5构建网络
model = Sequential()
model.add(Embedding(20, 4, input_length=6,mask_zero=True))
model.compile('rmsprop', 'mse')
output_array = model.predict(padded_inputs)
output_array.shape
# 6 查看结果
output_array[1]输出结果:

二、迁移学习: 使用预训练模型生成Embedding
1、什么是迁移学习?不同任务场景下,如何使用预训练模型?
迁移学习是在一个任务上学习到的模型(结构、权重)作为初始点,应用到另一个新的任务上。
那该如何使用预训练模型呢?
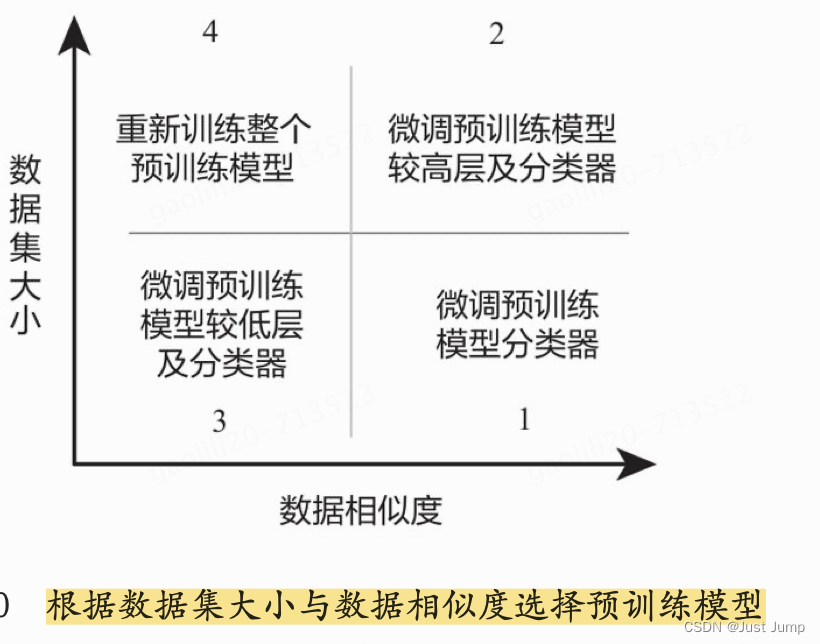
场景1: 数据集小,数据相似度高
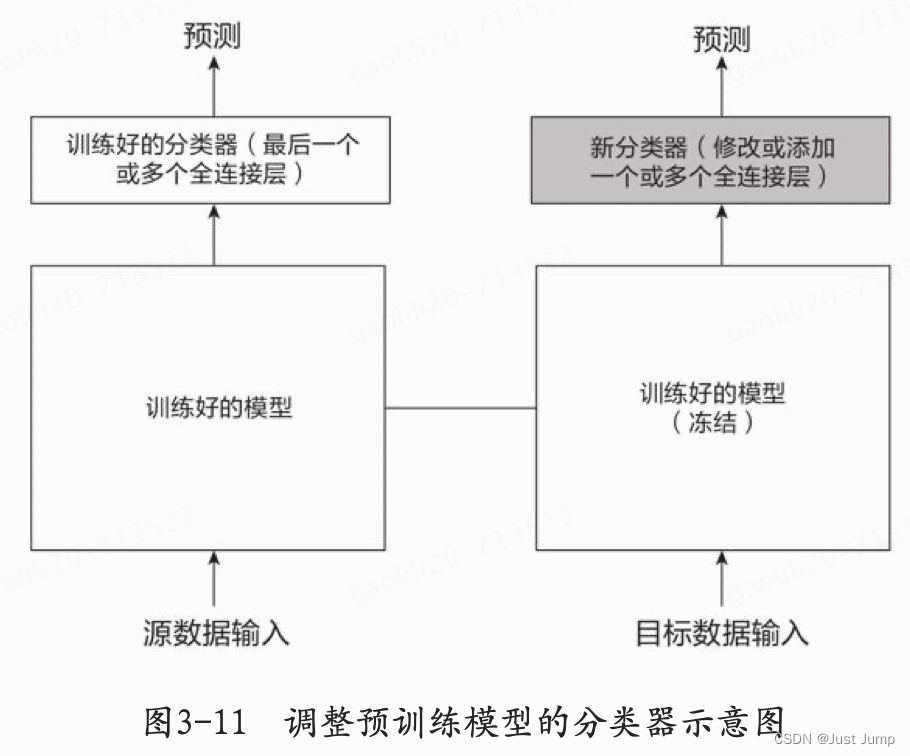
去掉输出层,然后将剩下的整个网络当作一个固定的特征提取机,应用到新的数据集中。
过程如图3-11所示,调整分类器中的几个参数,其他模块保持“冻结”即可。
这种微调方法,有时又称为特征抽取,因为预训练模型可以作为目标数据的特征提取器。
场景2: 数据集大, 数据相似度高
因为目标数据与预训练模型的训练数据之间高度相似,故采用预训练模型会非常有效。
另外,训练系统有一个较大的数据集,采用冻结预处理模型中少量较低层,修改分类器,然后在新数据集的基础上重新开始训练是一种较好的方式,具体处理过程如图3-12所示。
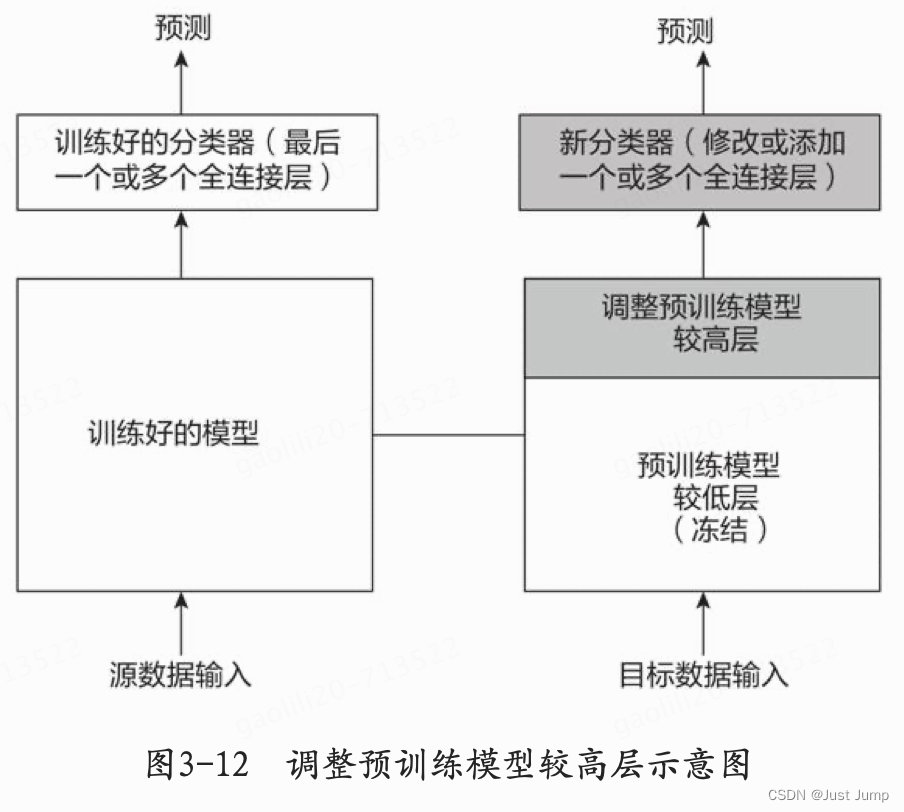
场景3: 数据集小,数据相似度不高
在这种情况下,可以冻结预训练模型中较少的网络高层,然后重新训练后面的网络,修改分类器。因为数据的相似度不高,重新训练的过程就变得非常关键。而新数据集大小的不足,则是通过冻结预训练模型中一些较低的网络层进行弥补,具体处理过程如图3-13所示。
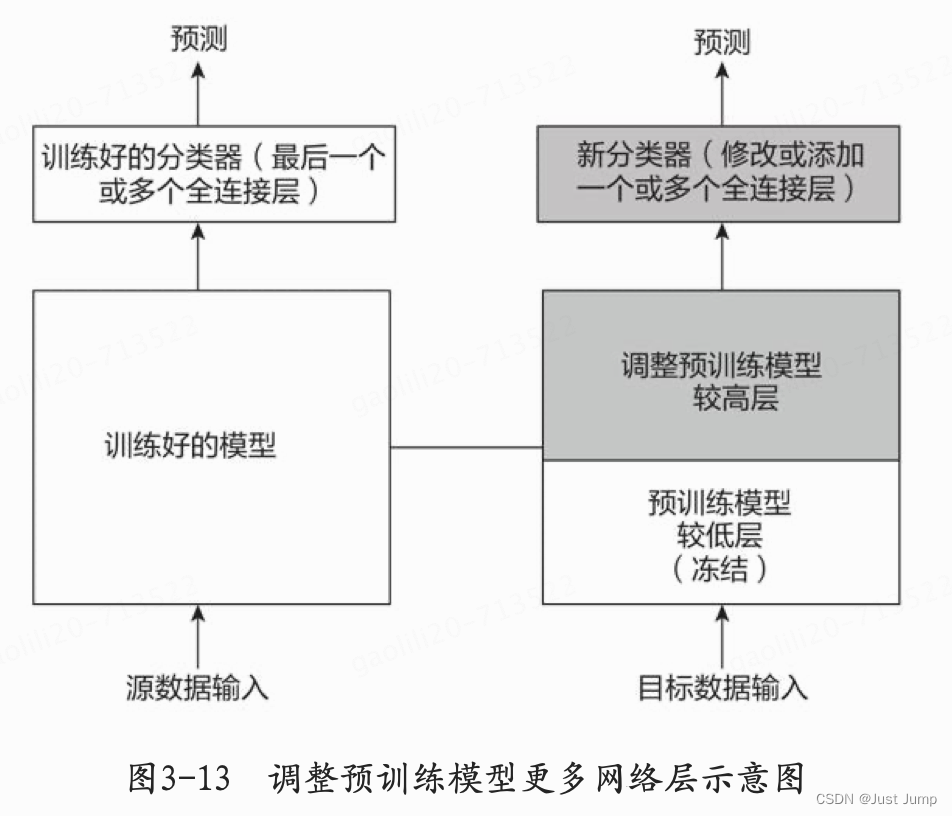
场景4: 数据集大, 数据相似度不高
在这种情况下,因为有一个很大的数据集,所以神经网络的训练过程将会比较有效率。然而,因为目标数据与预训练模型的训练数据之间存在很大差异,采用预训练模型不是一种高效的方式。因此最好的方法还是将预处理模型中的权重全都初始化后再到新数据集的基础上重新开始训练,具体处理过程如图3-14所示。
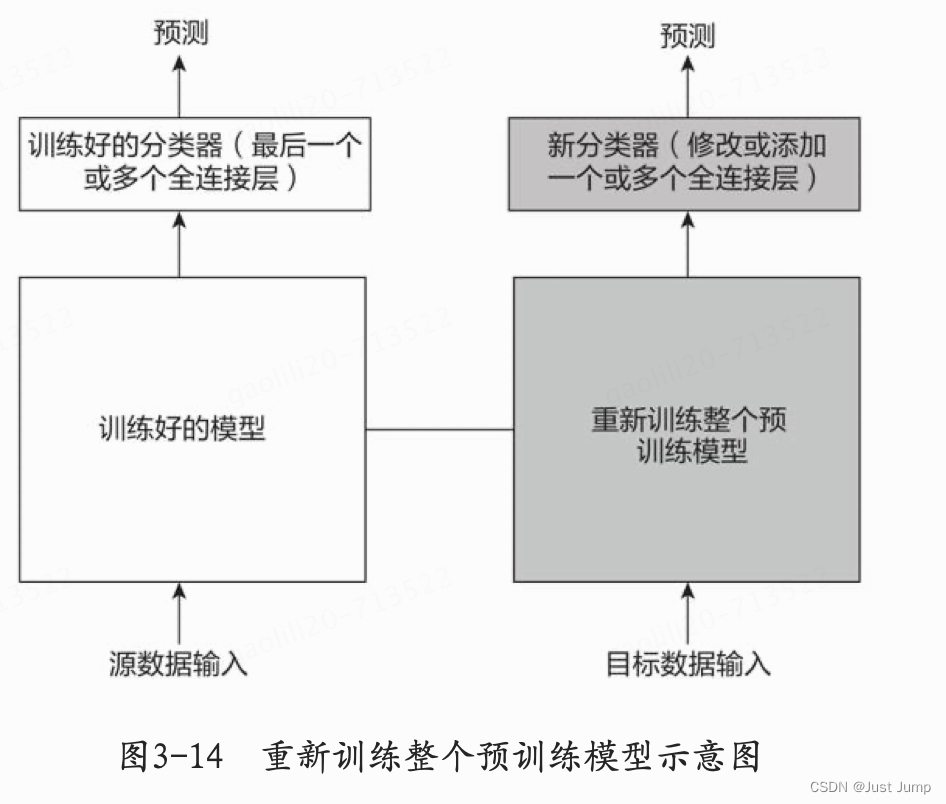
2、使用Glove预训练数据集迁移学习例子
import os
imdb_dir = './aclImdb' # 电影评论数据集
train_dir = os.path.join(imdb_dir, 'train')
labels = []
texts = []
for label_type in ['neg', 'pos']:
dir_name = os.path.join(train_dir, label_type)
for fname in os.listdir(dir_name):
if fname[-4:] == '.txt':
f = open(os.path.join(dir_name, fname))
texts.append(f.read())
f.close()
if label_type == 'neg':
labels.append(0)
else:
labels.append(1)
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import numpy as np
maxlen = 100 # 只保留前100单词的评论
training_samples = 200 # 在200个样本上训练
validation_samples = 10000 # W对10000个样品进行验证
max_words = 10000 # 只考虑数据集中最常见的10000 个单词
tokenizer = Tokenizer(num_words=max_words)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
word_index = tokenizer.word_index
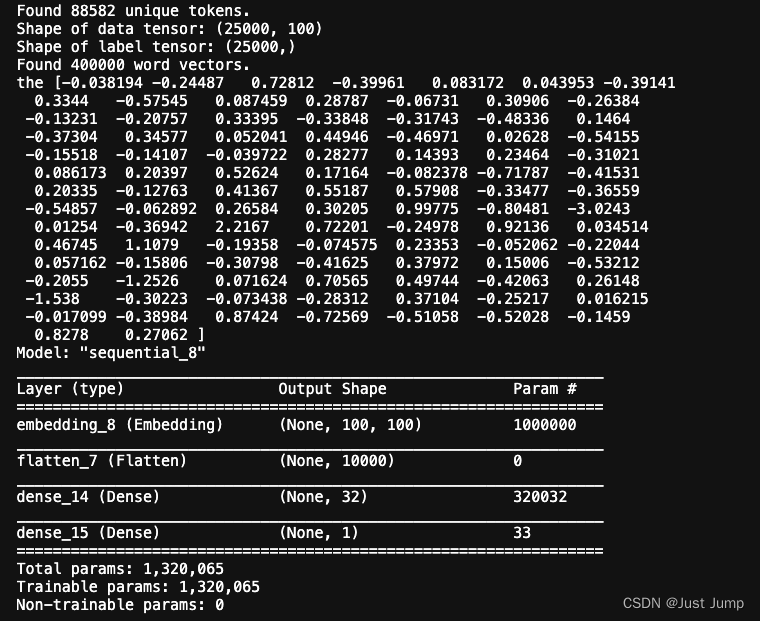
print('Found %s unique tokens.' % len(word_index))
data = pad_sequences(sequences, maxlen=maxlen)
labels = np.asarray(labels)
print('Shape of data tensor:', data.shape)
print('Shape of label tensor:', labels.shape)
# 将数据划分为训练集和验证集
# 首先打乱数据, 因一开始数据集是排序好的
# 负面评论在前, 正面评论在后
indices = np.arange(data.shape[0])
np.random.shuffle(indices)
data = data[indices]
labels = labels[indices]
x_train = data[:training_samples]
y_train = labels[:training_samples]
x_val = data[training_samples: training_samples + validation_samples]
y_val = labels[training_samples: training_samples + validation_samples]
glove_dir = './glove.6B/'
embeddings_index = {}
f = open(os.path.join(glove_dir, 'glove.6B.100d.txt'))
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
print('Found %s word vectors.' % len(embeddings_index))
for key,value in embeddings_index.items():
print(key,value)
break
embedding_dim = 100
embedding_matrix = np.zeros((max_words, embedding_dim))
for word, i in word_index.items():
embedding_vector = embeddings_index.get(word)
if i < max_words:
if embedding_vector is not None:
# 在嵌入索引(embedding index)找不到的词,其嵌入向量都设为0
embedding_matrix[i] = embedding_vector
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Flatten, Dense
model = Sequential()
model.add(Embedding(max_words, embedding_dim, input_length=maxlen))
model.add(Flatten())
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()
model.layers[0].set_weights([embedding_matrix])
model.layers[0].trainable = False
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(x_train, y_train,
epochs=10,
batch_size=32,
validation_data=(x_val, y_val))
model.save_weights('pre_trained_glove_model.h5')
import matplotlib.pyplot as plt
%matplotlib inline
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
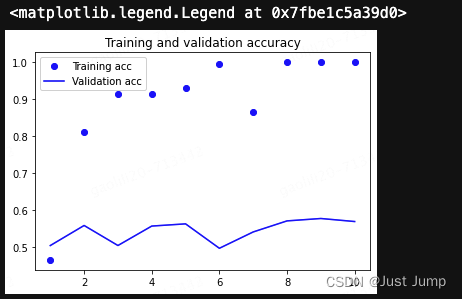
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()输出结果: