序言
胡哥首马在淮安325完赛,他的本硕都在淮安度过,七年的跑步生涯画上句号,真的是很圆满。七年,从180斤瘦到120斤,历经种种,胡哥理解的跑步,不是快,而是稳,他在比赛中从来不追求顶到极限,一旦感觉吃力,就会减速以重回舒适的区间。
现在,看到一些刚开始跑起来的人呐,就像看到从前的自己,有些高兴,却难起波澜。
不管出于什么初心,这总不是件坏事。
放弃不简单,坚持也没有多酷。
但是,我会等,直到那天到来。
(^_^)
文章目录
- 序言
- 20240422
20240422
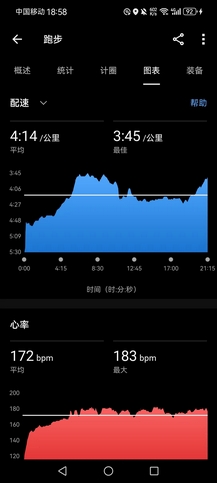
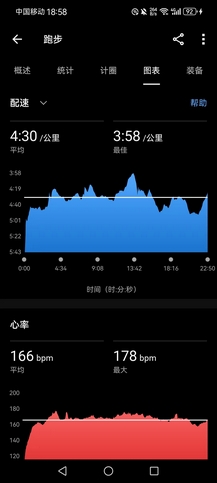
- 右脚的伤痛缓解,下午试着跑得快些。第一个5000米@4’14",全程能用前掌跑下来。但是,之后就连全掌跑都无法坚持很久,疼得只能用后跟跑,很艰难地顶完了第二个5000米@4’30",心率很高,水平倒退到2021年底。
- 中途超越一个白衣小伙,他很快就提速反超,我却再也提不起速度,年轻人真是活力四射。名义上,目前手握学校现役最佳半马PB,至少还能保持半年,如今连4分以外的配速都跑得这么吃力,怎么会没有落差呢?补25个弹力带引体,菜就多练。
- 近期NRC的训练只能鸽了,手头事情也很紧。作为最终考核指标之一,5月24日,NRC会进行场地5000米测试,届时必然是要去,我也两年多没有正式测一回场地5000米了,希望一个月里,能再回巅峰。
torchvision.transforms.ToTensor
-
把一个取值范围是 [ 0 , 255 ] [0,255] [0,255]的
PIL.Image或者shape为 ( H , W , C ) (H,W,C) (H,W,C)的numpy.ndarray,转换成shape为 ( C , H , W ) (C,H,W) (C,H,W),取值范围是 [ 0 , 1.0 ] [0,1.0] [0,1.0]的torch.FloadTensor;- 注意会把
channel(大部分图片的channel都是在第三个维度,channel维度值一般为 3 3 3或 4 4 4, 即 R G B \rm RGB RGB或 R G B A \rm RGBA RGBA对应的维度提到了shape的最前面; - 注意该变换并不是直接转为张量, 对于 R G B \rm RGB RGB值的图片型的张量, 观察源码可发现会作除以 255 255 255的归一标准化;
- 不符合上述图片型张量的形式的张量(如输入二维矩阵), 将直接不作任何数值处理直接转为 t o r c h \rm torch torch中的张量;
- 注意会把
-
可以使用
torchvision.transforms.ToPILImage作逆变换, 这两个函数互为反函数;- 这是一个只针对
PIL.Image输入的反函数, 即必然乘以 255 255 255再返回成图片数据类型;
- 这是一个只针对
-
代码示例:
import cv2 import torchvision as tv # torchvision.transforms.ToTensor f = tv.transforms.ToTensor() numpy2tensor = f(np.array([[0, 1, 2, 3], [4, 5, 6, 7], [8, 9, 10, 11]])) image = cv2.imread(r'D:\media\image\wallpaper\1.jpg') image2tensor = f(image) print(numpy2tensor) print(image.shape) print(type(image2tensor)) print(image2tensor.shape) # torchvision.transforms.ToPILImage f1 = tv.transforms.ToTensor() f2 = tv.transforms.ToPILImage() image = cv2.imread(r'D:\media\image\wallpaper\1.jpg') image2tensor = f1(image) tensor2image = f2(image2tensor) print(type(tensor2image)) print(np.asarray(tensor2image))
torchvision.transforms.Normalize
-
这也是个很诡异的函数, 目前没有看出到底是怎么进行标准化的, 两个参数分别为
mean与std;- 我现在看明白了,其实是
x
:
=
(
x
−
mean
)
/
std
x:=(x-\text{mean})/\text{std}
x:=(x−mean)/std,这里的
mean和std是可以对应 c h a n n e l \rm channel channel数来写的
- 我现在看明白了,其实是
x
:
=
(
x
−
mean
)
/
std
x:=(x-\text{mean})/\text{std}
x:=(x−mean)/std,这里的
-
也只能对图片型张量进行处理
-
代码示例:
import torchvision as tv f1 = tv.transforms.ToTensor() f2 = tv.transforms.Normalize([.5], [.5]) image = cv2.imread(r'D:\media\image\wallpaper\1.jpg') image2tensor = f1(image) normal_tensor = f2(image2tensor) print(image.shape) print(image2tensor.shape) print(normal_tensor.shape)