摘要
自然语言处理首先要应对的是如何表示文本以供机器处理,随着网络技术的发展和信息的公开,因特网上可供访问的数字文档成爆炸式的增长,文本摘要生成逐渐成为了自然语言处理领域的重要研究课题。本文主要介绍了分布式技术在文本摘要生成中的几种应用。
关键词:分布式技术;自然语言处理;文本摘要生成
Abstract
The first thing natural language processing needs to deal with is how to represent text for machine processing. With the development of network technology and the disclosure of information, the number of accessible digital documents on the Internet has exploded, and text summarization generation has gradually become an important research topic in the field of natural language processing. This article mainly introduces several applications of distributed technology in text summarization generation
KEY WORDS: distributed computation; natural language processing;Text Summarization;
0 引言
自然语言处理任务如文本分类、问答、关系抽取、文本摘要生成等,在各个领域都有着广泛的应用,但随着互联网上文本数据量的激增,以及海量数据中表现出的文本数据的复杂性和多样性,传统的自然语言处理技术面对海量的数据很难进行高效的任务处理,大数据和分布式技术的产生及运用,使得高效处理海量数据变为了可能,它们将许多原本需要人工来完成的文本任务交由机器完成,能够实现文本信息的高效处理。文档自动摘要算法是现在自然语言处理中发展迅速的算法,它可以从文本信息中自动的给出文章的概括,将文本的主要内容呈现在用户面前。文档自动摘要算法使人们不需要花太多时间阅读全文就能知道文本大意,从而更方便的让人们找到感兴趣的文章。自动摘要算法在自然语言处理中应用广泛,如在检索领域有很多自动摘要的应用,如将检索结果以摘要的形式呈现并且按照相关度排序,这样减少了用户点击非目标网站的几率。自动摘要还广泛应用到网页推荐系统,汇总用户平时常关注的网络信息,总结网页的信息内容,不断地查找相关的网页推荐给用户。
分布式系统是一种可以在多平台上同时执行任务的系统,具有横向扩展性、容错性和高并行处理能力。利用分布式系统的优势,可以大大提高文本摘要任务的处理效率。自动摘要分为两种,一种是直接抽取原文句子的抽取式摘要,另一种是基于机器写作的生成式摘要。前者由一组从原文档集中抽取的句子组成, 而后者由自然语言处理后所生成的语句组成。本文旨在研究基于分布式系统的文本摘要生成方法,探讨如何将分布式方法应用于文本摘要,并介绍了一种分布式技术在文本摘要生成中的应用。
1 文本摘要生成相关概念
1.1 词的独热表示
词的独热(One-Hot)表示是指用一个词表(假设词表大小为V)大小的向量表示一个词。假设有1000个陌生单词,one-hot编码的维度就是1000维,每个单词只有一个位置上为1,其余位置全部为0。one-hot编码对于非连续型数值特征也可以很好地进行处理。在该向量中,此表的第i个词在第i维上被设置为1其余维均为0。词的独热具体表示如以下公式所示:

但独热向量存在两个问题,第一个问题是此种编码方式无法反应原内容的顺序关系,词语之间的相似性也无法从向量中体现,不同的词使用完全不同的两个向量表示,这会导致假设两个词在语义上很接近,但是通过余弦相似度来度量他们之间的关系是相似度却为0。另外独热表示也会导致模型数据稀疏的问题。
1.2 词的分布式表示
为解决独热表示的问题,John Rupert Firth于1957年提出了分布式语义假设,该思想可以根据每个词的上下文分布对词进行表示。下面用一个具体的例子演示如何构建词的分布式表示,假设语料库中有以下三句话:
- 我喜欢自然语言处理
(2)我喜欢机器学习
(3)我爱深度学习
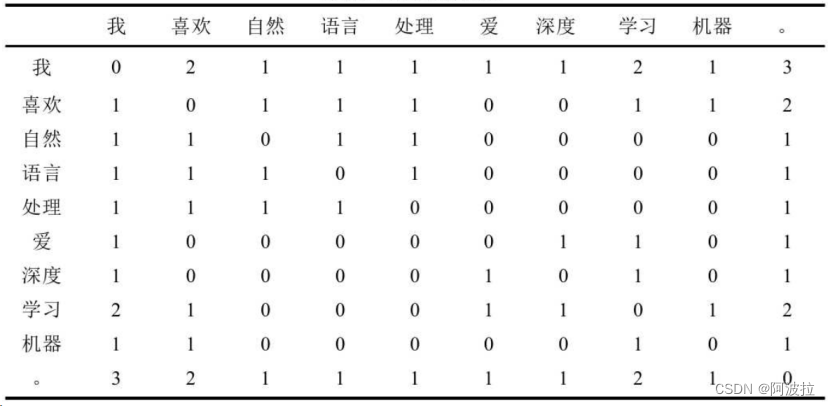
假设以词所在句子中的其他词语作为上下文,那么可以创建如表1-1所示的词语共现频次表。表中的每一行代表一个词的向量。通过计算两个向量之间的余弦函数,就可以计算两个词的相似度。如“喜欢”和“爱”,由于有共同的上下文“我”和“学习”,使得它们之间具有了一定的相似性,而不是如独热表示一样,没有任何关系,但分布式表示依旧存在稀疏性的问题。
表1-1词语共现频次表
1.3 词嵌入表示
与传统的词的分布式表示类似,词嵌入表示(Word Embedding)也使用向量的方式来表示词,简称词向量。词嵌入表示与分布式表示的不同之处在于其赋值方式。传统的词的分布式表示是经过点互信息、奇异值分解等变换而来。词嵌入中的词向量则是通过神经网络训练出来而来,通过这种方式可以更好的将输入信息映射为低维稠密的语义向量。
1.4 抽取式文本摘要
抽取式文本摘要是一种非监督的文本摘要方法,其主要目的是从原始文本中抽取具有代表性的候选信息,然后根据候选信息的评分高低选择最优的摘要作为最终输出,而不需要生成新的文本。在这个过程中,抽取式摘要通过对文本进行处理,提取与原文话题较为接近的句子作为参考摘要,并对其进行评分排序,最后选择评分最高的句子或段落作为文本的最终摘要,具体方法如图1-1所示。相比于生成式文本摘要,抽取式摘要更注重保留原始文本的信息完整性和准确性,适用于需要快速获取文本主要信息的场景,如自动化新闻摘要、文档总结等。
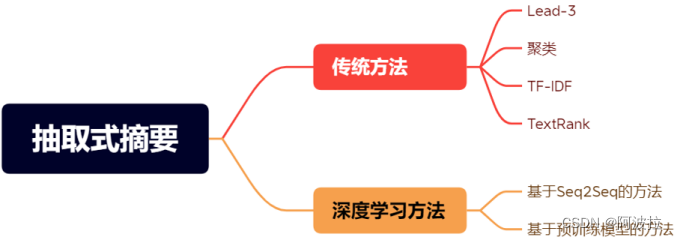
图1-1 抽取式摘要方法
1.5 生成式文本摘要
抽取式摘要的概括性和文本连贯性较差,而生成式摘要从原始文本中抽取信息,并利用这些信息重新排序组合后生成新的语句来构建摘要,以便更好地概括原始文本的内容,具有更好的灵活性。该种方法在生成最终摘要前,会对文本的语义进行分析,抽取出关键信息后再重新进行整合成摘要,这种方法与人们撰写摘要的方法十分相似,得到的摘要也能够更全面的展示文本的主要思想。
2 分布式相关概念
2.1 分布式系统的定义与特点
分布式系统是一个硬件或软件组件分布在不同的网络计算机上,彼此之间仅仅通过消息传递进行通信和协调的系统。在一个分布式系统中,一组独立的计算机展现给用户的是一个统一的整体,就好像是一个系统似的。系统拥有多种通用的物理和逻辑资源,可以动态的分配任务,分散的物理和逻辑资源通过计算机网络实现信息交换。系统中存在一个以全局的方式管理计算机资源的分布式操作系统。
分布式系统的特点:
(1)并行性:分布式系统中的计算机可以并行处理任务,从而提高系统的处理速度和吞吐量。这使得分布式系统能够应对大规模、复杂的问题和高负载场景。
(2)异构性:分布式系统可以包括不同类型、不同配置的计算机和软件组件。这使得分布式系统能够充分利用现有的硬件资源,并便于系统的扩展和升级。
(3)透明性:分布式系统为用户和应用程序提供一个统一的、透明的接口,使得它们无需关注底层的硬件和网络结构。这包括访问透明性、位置透明性、迁移透明性、复制透明性、并发透明性和容错透明性等。
(4)扩展性:分布式系统应具备良好的扩展性,能够根据需求动态地增加或减少节点数量,以适应不断变化的工作负载和数据规模。
(5)容错性与可靠性:分布式系统可以通过数据冗余和备份、故障检测与恢复等机制来提高系统的容错性和可靠性。当某个计算机或组件发生故障时,分布式系统可以自动调整资源分配和任务处理,以保证系统的正常运行。
(6)资源共享:分布式系统中的计算机和软件组件可以共享硬件资源(如处理器、内存、存储设备等)和软件资源(如数据库、文件、服务等),以提高资源利用率和降低成本。
(7)通信和协同:分布式系统中的计算机和软件组件需要通过网络进行通信和协同,以完成特定的任务或应用。通信协议和机制的设计对分布式系统的性能和可靠性至关重要。
2.2 分布式系统的优缺点
2.2.1 优点
(1)资源共享。若干不同的节点通过通信网络彼此互联,一个节点上的用户可以使用其他节点上的资源,如分布式系统允许设备共享,使众多用户共享昂贵的外部设备;允许数据共享,使众多用户访问共用的数据库;可以共享远程文件。
(2)加快计算速度。如果一个特定的计算任务可以划分为若干个并行运行的子任务,则可把这些子任务分散到不同的节点上,使它们同时在这些节点上运行,从而加快计算速度。另外,分布式系统具有计算迁移功能,如果某个节点上的负载太重,则可把其中一些作业移到其他节点去执行,从而减轻该节点的负载。这种作业迁移称为负载平衡。=
(3)可靠性高。分布式系统具有高可靠性。如果其中某个节点失效了,则其余的节点可以继续操作,整个系统不会因为一个或少数几个节点的故障而全体崩溃。因此,分布式系统有很好的容错性能。
(4)通信方便、快捷。分布式系统中各个节点通过一个通信网络互联在一起。通信网络由通信线路、调制解调器和通信处理器等组成,不同节点的用户可以方便地交换信息。
2.2.1 缺点
尽管分布式系统具备众多优势,但它也有自身的缺点,主要是可用软件不足,系统软件、编程语言、应用程序以及开发工具都相对很少。并且,分布式系统涉及多个计算机之间的协作,设计和实现较为复杂,需要更多的资源和专业知识来维护和管理,当系统规模较大时,监控、收集日志、负载均衡等管理任务变得更加困难。此外,还存在通信网络饱和或信息丢失和网络安全问题,方便的数据共享同时意味着机密数据容易被窃取。虽然分布式系统存在这些潜在的问题,但其优点远大于缺点,而且这些缺点也正得到克服。因此,分布式系统仍是人们研究、开发和应用的方向。
3 分布式技术在文本摘要生成中的应用
3.1 分布式存储数据
(1)分布式数据存储和管理:文本摘要生成需要处理大量的文本数据,包括原始文本和生成的摘要。分布式存储系统能够有效地存储这些数据,并提供高可靠性和可扩展性。通过分布式存储,可以将数据分散存储在多个节点上,避免单点故障,并且能够根据需求扩展存储容量。
(2)提高数据访问性能:文本摘要生成算法通常需要频繁地访问大规模的文本数据集。分布式存储系统可以提供高性能的数据访问能力,通过数据分片和并行访问技术,可以实现快速的数据检索和读取操作,从而加速摘要生成的过程。
(3)增强数据一致性和可靠性:文本摘要生成的过程中,对数据的一致性和可靠性要求较高。分布式存储系统通常具有副本机制和容错能力,能够保证数据的一致性和可靠性。即使在节点故障或网络分区的情况下,系统仍然能够保证数据的完整性和可用性。
(4)分布式文件系统:分布式文件系统是一种常见的分布式存储技术,在文本摘要生成中广泛应用。分布式文件系统能够将数据分布存储在多个节点上,并提供统一的文件访问接口。通过分布式文件系统,可以方便地管理文本数据集,并支持并行处理和高性能的数据访问。
(5)实现扩展性和弹性:随着数据规模的不断增长,文本摘要生成系统需要具备良好的扩展性和弹性。分布式存储系统能够根据需求动态扩展存储容量,并自动调整数据分布,以适应不断变化的工作负载。这样可以确保系统能够持续地处理大规模的文本数据,并满足用户对摘要生成的需求。
3.2 分布式任务调度
(1)任务分发和负载均衡:在文本摘要生成过程中,需要处理大量的文本数据,并对其进行分析和处理。分布式任务调度器负责将这些任务分发到不同的计算节点上,并通过负载均衡算法来保证各个节点的负载尽可能均衡,避免出现单点瓶颈。
(2)并行计算:文本摘要生成算法通常可以分解成多个子任务,并且这些子任务之间可能是相互独立的,可以并行计算。分布式任务调度器可以根据任务之间的依赖关系和计算资源的可用情况,合理地安排并行计算,以提高整个系统的计算速度。
(3)动态资源调整:文本摘要生成过程中,可能会根据任务的优先级和系统资源的变化动态调整任务的执行顺序和资源分配。分布式任务调度器需要能够灵活地根据实际情况进行资源调度和管理,以最大程度地利用计算资源,提高系统的整体性能。
(4)任务监控和管理:分布式任务调度器通常提供了丰富的监控和管理功能,可以实时地监控任务的执行情况和系统资源的利用率,及时发现和解决潜在的问题,保证任务的顺利执行。
(5)故障容错:在分布式系统中,计算节点可能会出现故障或者网络中断等问题。分布式任务调度器需要具备故障检测和恢复的能力,及时发现并处理计算节点的故障,保证任务的顺利执行和系统的稳定性。
3.3 分布式算法训练
(1)分布式文本处理:分布式算法可以将文本数据分割成多个部分,并在多个计算节点上并行处理。这种分布式文本处理方式可以大大加快文本数据的预处理过程,例如分词、词性标注、去除停用词等,为后续摘要生成做好准备。
(2)分布式特征提取:在文本摘要生成中,提取重要特征是至关重要的一步。分布式算法可以在多个计算节点上并行提取文本的关键特征,例如词频、TF-IDF值、句子位置等,以供后续的摘要生成算法使用。
(3)分布式摘要生成算法:一些摘要生成算法可以通过分布式方式实现。例如,基于图的摘要生成算法(如TextRank、LexRank等)可以将文本表示成图结构,在分布式环境下,可以并行计算节点之间的节点权重、边权重等信息,从而高效地生成文本摘要。
(4)分布式模型训练:一些深度学习模型(如循环神经网络、Transformer等)可以通过分布式方式进行训练,以生成更加准确和流畅的文本摘要。在分布式环境下,可以利用多个计算节点的计算资源进行模型训练,并通过分布式优化算法来优化模型参数,以提高摘要生成的效果。
(5)分布式评估和调优:在文本摘要生成过程中,评估摘要的质量和调优算法也是非常重要的。分布式算法可以在多个计算节点上并行评估摘要的质量,例如与原始文本的相似度、信息覆盖度等指标,并通过分布式优化算法来调整摘要生成算法的参数,以提高摘要的质量和流畅度。
3.4 分布式计算框架
分布式计算框架在文本摘要生成中的应用可以带来多方面的优势,包括处理大规模数据、加速计算速度、提高系统的可扩展性和容错性等。以下是一些常见的分布式计算框架在文本摘要生成中的应用:
(1)Hadoop
Hadoop是一个开源的分布式计算框架,主要用于存储和处理大规模数据。在文本摘要生成中,可以使用Hadoop的分布式文件系统(HDFS)存储原始文本数据,并使用MapReduce编程模型实现摘要生成算法。
MapReduce可以将摘要生成任务分解成多个Map和Reduce阶段,在多台计算节点上并行执行。这样可以大大加速摘要生成的速度,特别是对于处理大规模文本数据时效果显著。
(2)Apache Spark
Apache Spark是另一个流行的分布式计算框架,它提供了比Hadoop更快速、更灵活的数据处理能力。Spark可以通过其RDD(Resilient Distributed Datasets)抽象来实现文本摘要生成算法。
Spark的内存计算能力和基于内存的数据处理方式使得它在迭代计算任务(如迭代式摘要生成算法)中表现更加出色。同时,Spark也支持广播变量和累加器等功能,方便在分布式计算过程中共享数据和收集统计信息。
4 应用举例——基于谱聚类的分布式文本摘要自动提取方法
该自动摘要方法是基于抽取式的中文摘要,抽取式多文档自动摘要有三个必要的步骤:消除冗余、摘要句抽取、摘要句排序。其常用的基本框架如图4-1所示。
消除冗余与摘要句抽取的先后顺序可以互换。消除冗余可以避免抽到的句子对文档的某一方面过度描述。文摘消冗效果较好的方法是对文章进行子主题的划分,消冗后计算句子权重,抽取权重较大的的句子作为摘要句,考虑句子的前后顺序将摘要句排列实现自动摘要。抽取式摘要的框架都是类似的,但是具体到每一环节又有具体的不同方法。

图4-1 抽取式多文档自动摘要基本框架
基于谱聚类的分布式文本摘要自动提取方法在句子相关性度量上利用文本分布式表示模型——Doc2Vec模型,将句子训练为句向量,通过向量间的相似度来度量句子间的相似度。Word2Vec模型将词语映射为词向量实现了词的分布式表示,对于句子也有相应的方法可以将句子映射为句向量,例如可以将句子所包含词语的词向量求平均来作为句向量,但是这种方法忽略了句子中词语的顺序关系。应当类似于Word2Vec模型,基于神经概率语言模型利用神经网络训练以得到句子向量。Doc2Vec模型是与Word2Vec模型相对应的方法,其在Word2Vec模型的基础上加入了paragraph向量可以训练段落或句子向量。
该方法在消冗上采用谱聚类对句向量进行聚类以划分出各个子主题文档,减少摘要句的冗余。抽取式多文档自动摘要是希望用少量的句子来尽可能去描述文本集内容的各个方面。仅仅按照句子的权重大小来抽取摘要句无法保证两个权重较大的句子描述的是不同的方面。消除摘要句冗余是必不可少的环节。为了防止对同一子主题的过度描述,将文本划分子主题是一个很有效的方法。
为了计算句子的重要度,基于谱聚类的分布式文本摘要自动提取方法对每个子主题文档建立句子关系图模型,利用TextRank算法迭代计算句子的权重。每个子主题文档抽取权重最高的句子作为摘要句,按照摘要句在原文章中的位置排序组合成摘要。TextRank算法是由PageRank算法改进而来。PageRank是Google用于网页排序而设计的数学模型,该算法将互联网上的所有网页视作一个整体,在计算网页权重时不仅仅考虑网页本身还考虑网页之间的链接关系。
句子排序按照摘要句所在原文章的位置来排序。
5 总结和展望
由于计算资源的限制,传统的文本摘要生成通常在小规模数据集上进行,虽然过去的研究在这些数据集上取得了不错的成果,但更大规模的数据集可以为自然语言处理任务提供更多有用的信息。面对更大规模的数据,有效地利用有限的计算资源成为研究的焦点。分布式技术在各个领域的成熟应用为解决这一问题提供了基础。本文探讨了分布式技术在文本摘要生成任务中的应用,并简要介绍了其对任务提升与优化的影响。
尽管应用分布式技术可以有效提高文本摘要生成的计算效率,但由于自然语言文本的多样性和复杂性,如何有效统一地对大规模文本数据进行预处理仍是一个需要重点研究解决的问题。
参考文献
- 胡侠,林晔,王灿,等.自动文本摘要技术综述[J].情报杂志,2010,29(08):144-147.
- Radev D, Jing H, Stys M, et al.Centroid-based Summarization of Multiple Documents[jy,Information Processing&Management, 2004,40(6):919-938.
- 梁晔平. 中文文本自动分类相关算法的研究与实现[D]. 广东广州:华南理工大学, 2010.
- 邹立民.基于Hadoop的分布式数据存储系统应用的研究.2018.沈阳工业大学,MA thesis.
- 张新英."HADOOP分布式文件系统(HDFS)的应用." 电脑迷 .03(2018):188.
- 王铮.基于Hadoop的分布式系统研究与应用.2014.吉林大学,MA thesis.
- 马军红.文本相似度计算理论与应用研究.2011.西北大学,MA thesis.
- 韦福如. 基于图模型多文档自动文摘研究[D]. 湖北武汉:武汉大学, 2009.
- 黄文彬, 倪少康. 多文档自动摘要方法的进展研究[J]. 情报科学, 2017(4):160-165.
- 周丹. 基于子主题的多文档摘要关键技术研究[D]. 北京:北京邮电大学, 2008.
- 朱翔. 基于分布式表示的文本分类与自动摘要方法研究[D].山东工商学院,2019.