🏠关于专栏:Linux的浅学到熟知专栏用于记录Linux系统编程、网络编程等内容。
🎯每天努力一点点,技术变化看得见
文章目录
- 进程间通信介绍
- 如何实现进程间通信
- 进程间通信分类
- 管道通信方式
- 什么是管道
- 匿名管道pipe
- 匿名管道读写规则
- 管道的特点
- 匿名管道的应用——进程池
进程间通信介绍
如何实现进程间通信
- 什么是通信?
所谓通信,就是要实现两个或多个进程实现数据层面的交互。而在操作系统中,为了保持进程的独立性,不允许其他进程访问某个进程的地址空间。正因为进程独立性的存在,导致进程的通信成本比较高。(因为A进程无法直接将通信数据写入B进程的地址空间中,而需要通过在两进程外部创建某个空间来实现进程的通信,故成本较高)。 - 为什么进程需要通信呢?
①数据传输:一个进程需要将它的数据发送给另一个进程;
②资源共享:多个进程之间共享同样的数据,当前进程需要将共享数据发送给需要该数据的进程;
③通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发送了某种事件(如:子进程退出时需要通知父进程);
④进程控制:有些进程希望完全控制另一个进程的执行,控制进程希望能够知道另一个进程的状态改变,通过状态来确定如何控制。 - 实现进程间通信的思想是什么呢?
①进程间通信的本质,必须让不同的进程看到同一份进程外的“资源”(A进程向该资源写入信息,B进程从该资源中读取,从而实现通信);
②“资源”就是特定形式的内存空间;
③这个“资源”谁提供?一般是操作系统提供的第三方空间。
④由于该空间是操作系统提供的,则通信进程访问该空间进行通信,本质就是访问操作系统。进程处于用户,而“资源”属于操作系统,即内核级。故该“资源”从创建、使用、到释放,都需要操作系统参与,因而操作系统需要提供对应的系统调用。一般操作系统会提供一个独立的通信系统——LPC通信模块(隶属于文件系统)。
★ps:为什么不是通信的两个进程中的一个,提供通信的“资源”呢?如果由A进程提供,则该资源属于A进程。若想实现通信,则B进程也要访问这个空间,则会破坏进程独立性。
进程间通信分类
进程间通信方式可以分为3类:管道、System V IPC、POSIX IPC三种方式。其中,System V版本常用于本机进程间通信,而POSIX版本常用于网络中不同主机间的进程间通信。
以下是上述三类通信方式包含的具体通信形式↓↓↓
管道方式
● 匿名管道pipe
● 命名管道fifo
System V IPC
● System V消息队列
● System V共享内存
● System V信号量
POSIX IPC
● 消息队列
● 共享内存
● 信号量
● 互斥量
● 条件变量
● 读写锁
上述列出的各个通信形式,将于本文及后序文章中陆续介绍,本文先介绍匿名管道。
管道通信方式
什么是管道
管道是Unix操作系统中最古老的进程间通信方式,我们将一个进程链接到另一个进程的数据流缓冲区称为一个“管道”。
【示例】当我们执行ps axj | grep test.c的时候,ps axj的标准输出结果写入到内核的管道中,grep test.c从该内核管道获取输入,将将结果输出给用户显示器。
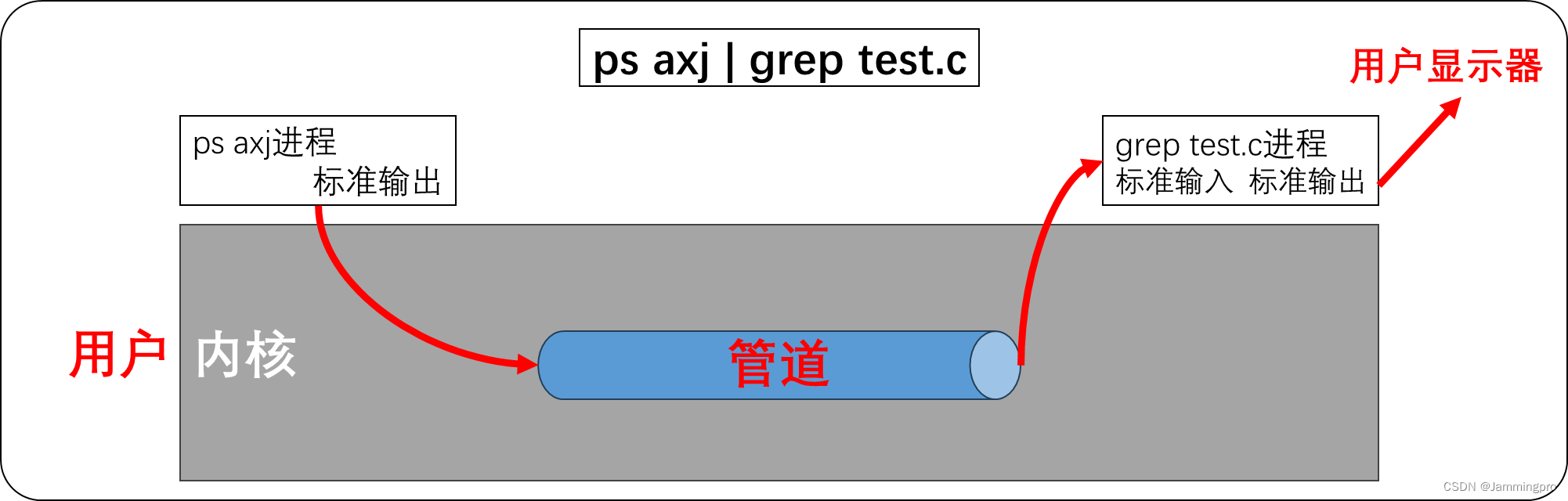
★ps:建立通信为什么那么费劲?因为进程具有独立性。
匿名管道pipe

创建匿名管道的系统调用原型为int pipe(int pipefd[2]);。参数pipefd是文件描述符数组,其中pipefd[0]表示读端,pipefd[1]表示写端。

从上图可以看出,当需要进行通信时,需要通过pipefd[1]文件描述符,将数据拷贝到管道文件中;再通过pipefd[0]文件描述符,将管道文件中的数据拷贝到用户空间中。因而,管道通信时,需要产生两次拷贝。
下面是一个进程向管道内写入数据,并从管道内读取数据的代码↓↓↓
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
int main()
{
int fds[2];
pipe(fds); //创建匿名管道
//向匿名管道文件中写入数据
char* msg = "Jammingpro";
write(fds[1], msg, strlen(msg));
//从匿名管道文件中读取输入
char buffer[1024];
ssize_t n = read(fds[0], buffer, sizeof(buffer));
buffer[n] = '\0';
printf("The info read from pipe is %s\n", buffer);
return 0;
}

但我们创建匿名的目的是为了实现进程间的通信,在同一个进程内读写匿名管道文件并没有多大意义。由于匿名管道只能实现具有血缘关系的进程进行通信(如父子进程、兄弟进程、爷孙进程等具有血缘关系的进程),下面我们来探索父子进程如何进行匿名管道通信。↓↓↓
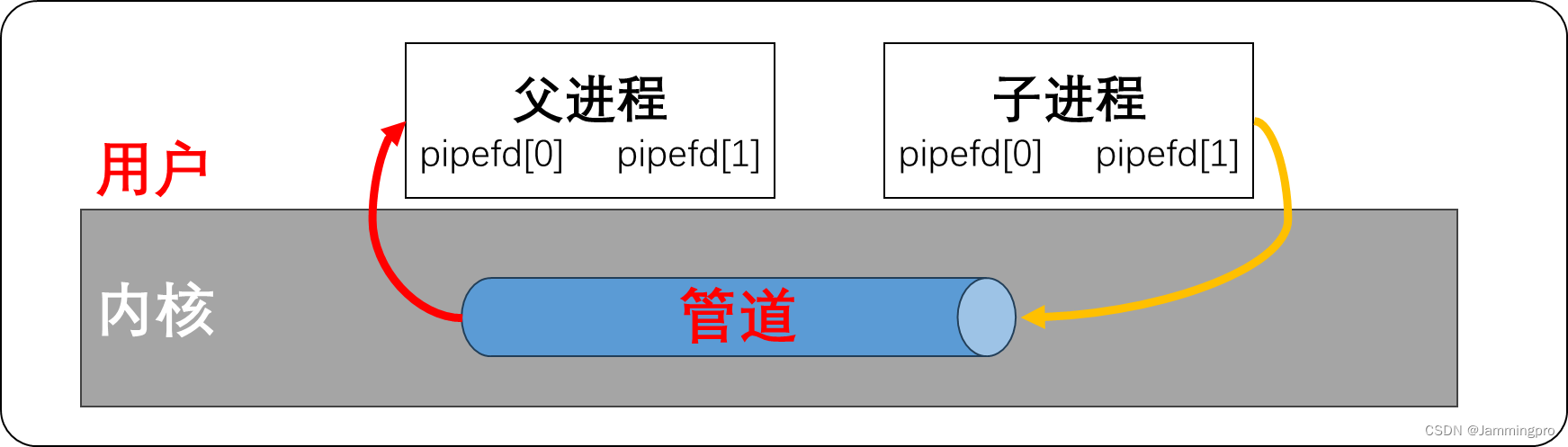
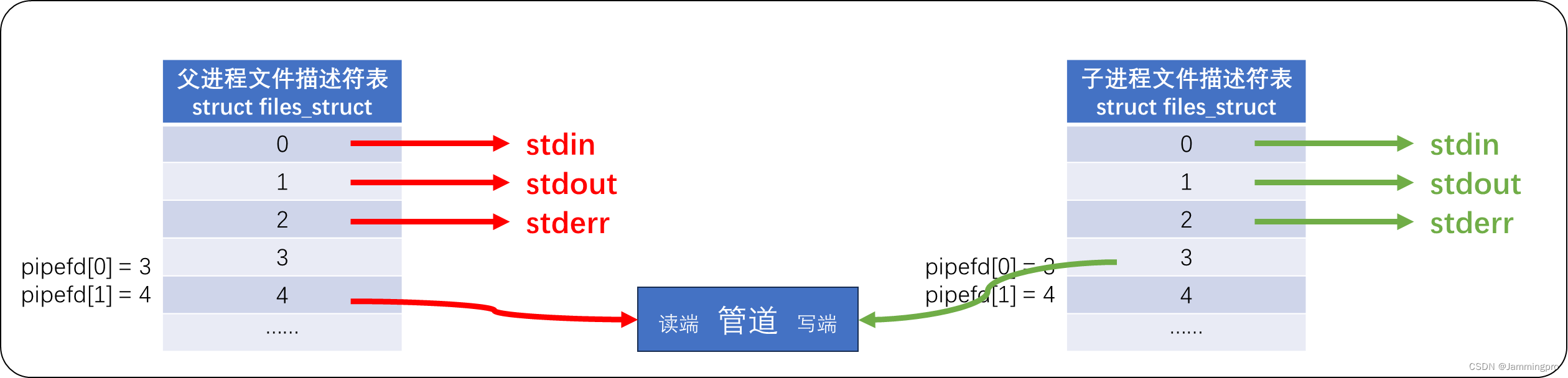
当父进程创建匿名管道时,则会在父进程的文件描述符表中,为匿名管道的读端和写端各分配一个文件描述符。

当父进程fork创建子进程时,子进程会继承父进程的文件描述符表,即子进程的3号和4号文件符和父进程一样,指向刚刚创建的匿名管道的读写端。
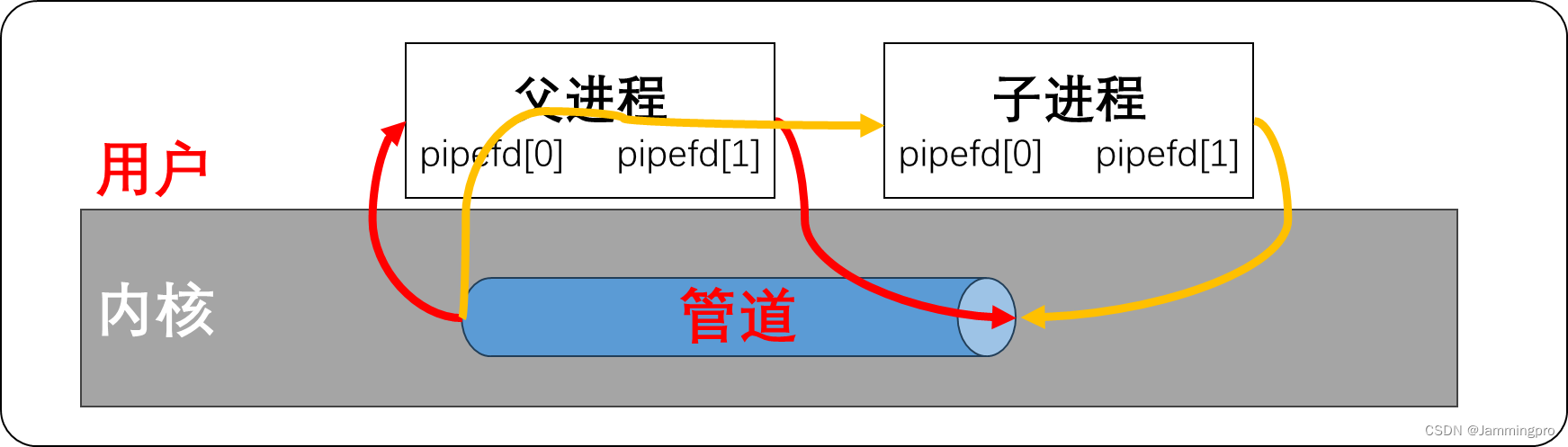
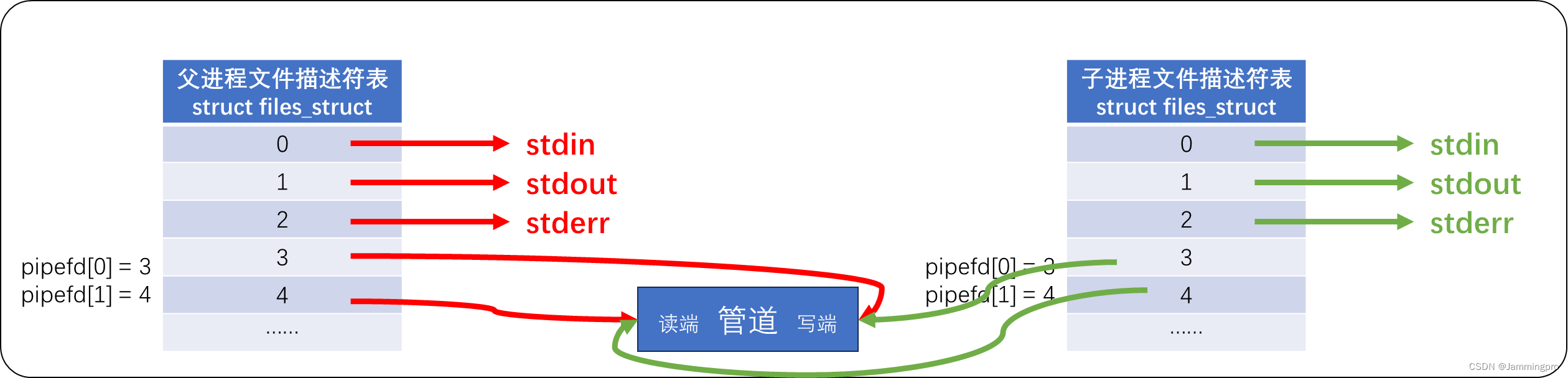
若我们希望子进程向父进程发送数据,则对于父进程来说,管道的写文件描述符的存在是没有意义的;对于子进程来说,管道的读文件描述符是没有意义的。我们可以将父进程的写文件描述符pipefd[1]和子进程读文件描述符pipefd[0]关闭。
下面我们实现一个子进程向父进程发送数据的代码↓↓↓
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdbool.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/wait.h>
int main()
{
int fds[2];
pipe(fds);
pid_t id = fork();
if(id == 0)//子进程
{
close(fds[0]);
int cnt = 10;
while(cnt--)
{
char buffer[1024];
snprintf(buffer, sizeof(buffer), "%d->child process sending a message", cnt);
write(fds[1], buffer, strlen(buffer));
sleep(1);
}
close(fds[1]);
exit(0);
}
//父进程
close(fds[1]);
char info[1024];
while(true)
{
ssize_t n = read(fds[0], info, sizeof(info) - 1);
if(n != 0)
{
info[n] = '\0';
printf("get a info from child process! --> %s\n", info);
}
else
{
close(fds[0]);
break;
}
}
int status = 0;
pid_t ret = waitpid(id, &status, 0);
if(WIFEXITED(status))
{
printf("exitcode = %d, sig = %d\n", WEXITSTATUS(status), (status & 0x7F));
}
return 0;
}
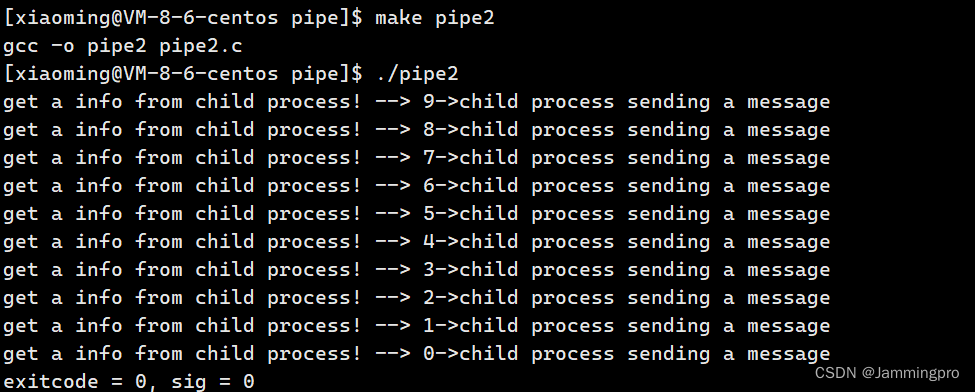
上面代码中,子进程每间隔1秒向管道中写入一条数据,我们并没有对父进程做任何限制。但父进程却可以实现每隔一秒从管道中读取数据。并且,子进程在写入时,父进程并没有立即读取,而是等子进程写完才读取(如果子进程在写的时候,父进程就开始读,就会出现读取的数据不完整的情况)。
由上面代码执行结果可知,管道具有同步机制,即只有写端写入数据后,读端才能读取,读写存在先后顺序。当读写端均正常时,写端没有写入时,读端会阻塞等待。当写端文件描述符关闭时,读端read返回结果为0,表示读到文件末尾。
那如果我们让读端每隔1秒读一次,写端不限制,则会出现什么情况呢↓↓↓
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdbool.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/wait.h>
int main()
{
int fds[2];
pipe(fds);
pid_t id = fork();
if(id == 0)//子进程
{
close(fds[0]);
int cnt = 100;
while(cnt--)
{
char buffer[1024];
snprintf(buffer, sizeof(buffer), "%d->child process sending a message", cnt);
write(fds[1], buffer, strlen(buffer));
}
close(fds[1]);
exit(0);
}
//父进程
close(fds[1]);
char info[1024];
while(true)
{
ssize_t n = read(fds[0], info, sizeof(info) - 1);
if(n != 0)
{
info[n] = '\0';
printf("get a info from child process! --> %s\n", info);
}
else
{
close(fds[0]);
break;
}
sleep(10);
}
int status = 0;
pid_t ret = waitpid(id, &status, 0);
if(WIFEXITED(status))
{
printf("exitcode = %d, sig = %d\n", WEXITSTATUS(status), (status & 0x7F));
}
return 0;
}

由上面程序执行结果可以看出,当读端没有读取匿名管道文件中的数据时,写端将匿名管道文件写满后,只能阻塞等待,待读端将数据读走后,才能继续写入。
由上面的程序执行结果我们可以得出,当读写端正常时,读端读的慢,则写端写满管道文件后会阻塞等待。
同时,从上面程序的执行结果来看。多次写入管道文件中的内容,被一次性读取出来,说明管道是基于字节流的。
那如果父进程的读端关闭,则写端会出现什么情况呢?↓↓↓
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdbool.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/wait.h>
int main()
{
int fds[2];
pipe(fds);
pid_t id = fork();
if(id == 0)//子进程
{
close(fds[0]);
int cnt = 100;
while(cnt--)
{
char buffer[1024];
snprintf(buffer, sizeof(buffer), "%d->child process sending a message", cnt);
write(fds[1], buffer, strlen(buffer));
sleep(1);
}
close(fds[1]);
exit(0);
}
//父进程
close(fds[1]);
char info[1024];
int count = 0;
while(true)
{
ssize_t n = read(fds[0], info, sizeof(info) - 1);
if(n != 0)
{
info[n] = '\0';
printf("get a info from child process! --> %s\n", info);
}
else
{
close(fds[0]);
break;
}
if(count == 2)
{
close(fds[0]);
break;
}
count++;
}
int status = 0;
pid_t ret = waitpid(id, &status, 0);
if(ret > 0)
{
printf("exitcode = %d, sig = %d\n", WEXITSTATUS(status), (status & 0x7F));
}
return 0;
}

上面程序中,当父进程读取3次管道文件内容后,将父进程的读端文件描述符关闭。由程序执行结果可以看到,子进程收到了13号信号,即SIGPIPE信号。
匿名管道读写规则
由上面的多个代码执行结果,我们可以得到如下结论↓↓↓
- 读写端正常,若管道如果为空,读端就要阻塞;
- 读写端正常,若管道如果被写满,写端被阻塞;
- 读端正常读,写端关闭,读端就会读到0,表明读到pipe文件末尾。这种情况,读端并不会阻塞。
- 写端正常写,读端关闭,操作系统会用13号信号SIGPIPE杀死系统中正在写入的进程。
多执行流共享,难免出现访问冲突。例如,A进程本想向管道中写入"Hello World",但当A进程写完"Hello"时,B进程就来读取,导致数据不完整。管道能提供协同机制(包含同步和互斥),对于同步来说,只有写端写入数据后,读端才能读取数据;对于互斥来说:先进来读写的进程要完成其读写任务后,下一个进程才能进行读写,不允许两个进程同时访问管道。
但对于管道的互斥机制来说,之后当管道内数据小于PIPE_BUF大小时,才能保证。当读写入的数据不大于PIPE_BUF时,Linux将可以保证写入的原子性,即保证写进程写入时没有进程读取,进程读取时没有其他进程写入。当读写数据大于PIPE_BUF大小时,Linux不再保证读写的原子性。
★ps:原子性操作表示只有两种结果的操作,这里的原子性读写操作表示读写成功或不进行读写。
管道的特点
- 具有血缘关系的进程才可以进行通信(常用于父子通信);
- 管道是半双工的,数据只能单向流动;
- 父子进程是会进程协同的,匿名管道会提供同步与互斥机制——保护管道文件的数据安全;
- 管道提供面向流式的通信服务——面向字节流;
- 管道是基于文件的,而文件的生命周期是随进程的。当进程执行结束,则对应的匿名管道文件会被释放。
★ps:匿名管道只能让父子进程之间实现单向通信,如果我们需要实现双向通信,则需要使用两个管道。
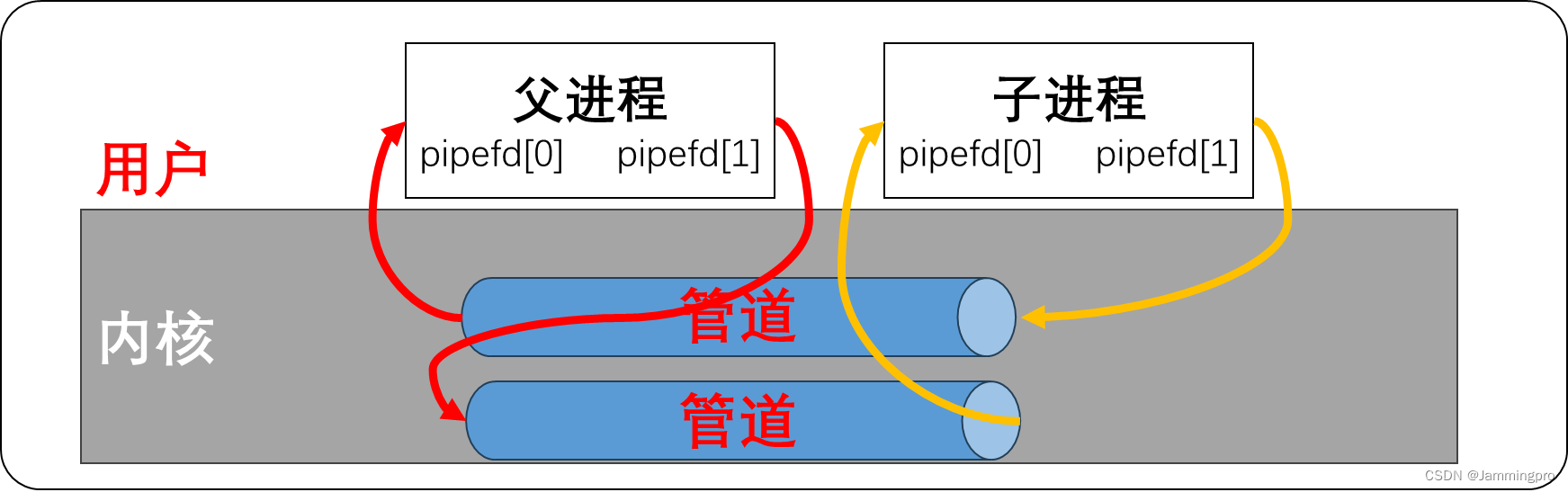
★ps:如果两个进程不存在任何关系(不是父子进程、兄弟进程、爷孙进程等有血缘的关系),则这两个进程能不能通信呢?不能。进程之间必须有血缘关系,常用于父子进程。这种方式打开的管道文件,称为匿名管道。
管道是有固定大小的,不同内核里,大小可能有差异。我们可以使用ulimit -a查看当前系统中的匿名管道文件pipe的大小。↓↓↓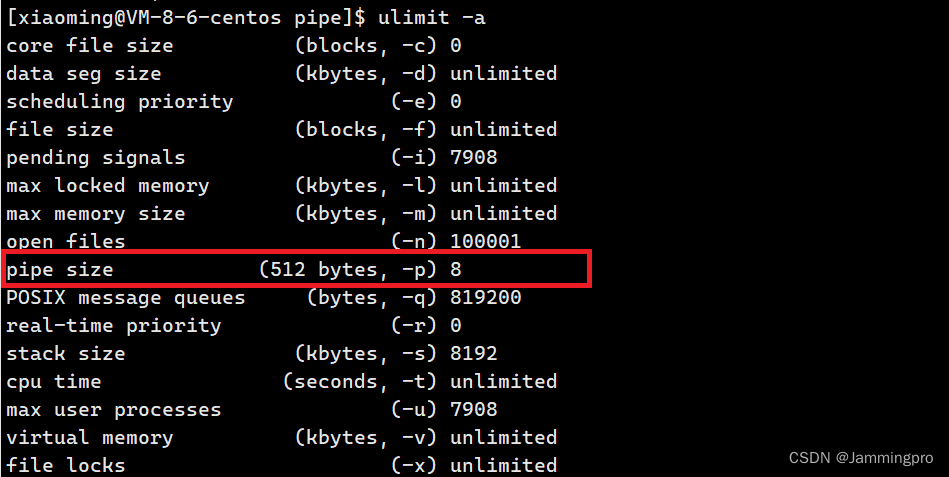
匿名管道的应用——进程池
注意:进程池应用代码使用C++语言
当我们的系统中有大量的任务需要被处理时,我们可以将这些任务派发给各个子进程。但由于多次创建和销毁进程会带来较大的时间开销。我们可以通过提前创建一批子进程(避免需要时再创建),且子进程空闲时就阻塞等待(避免子进程执行完被销毁,下次需要子进程时还需要创建)。
实现上述需求时,我们需要借助匿名管道。通过在各个父子进程间建立匿名管道,实现父进程向指定子进程派发任务。↓↓↓
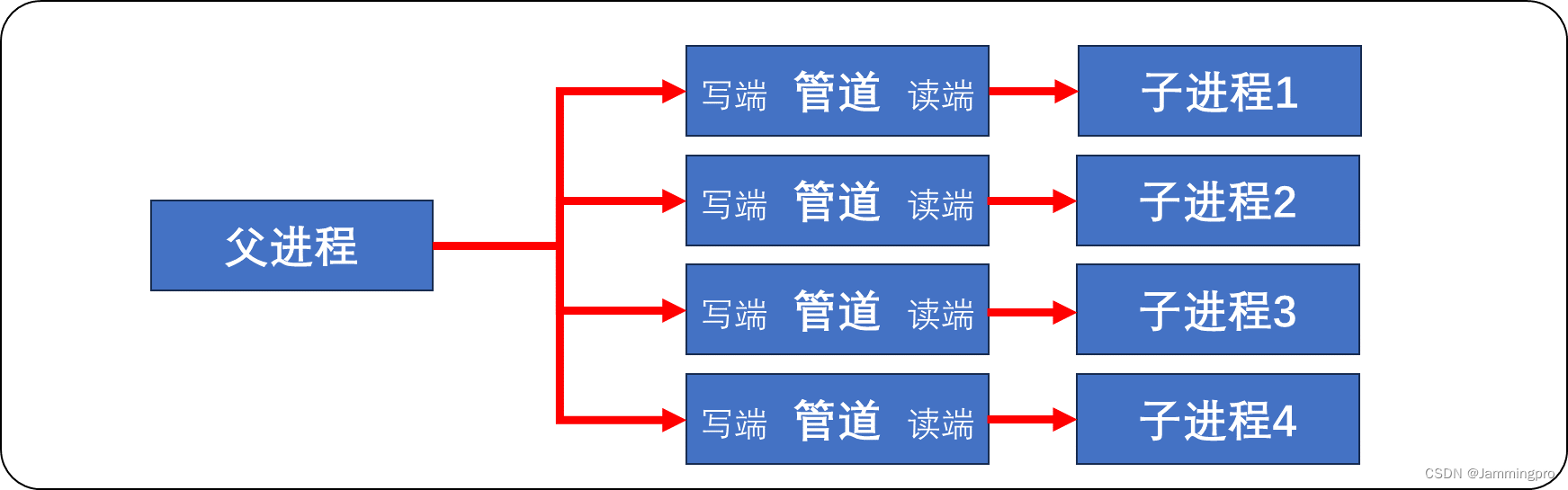
但需要注意的是,父进程不应该将大量任务集中派发给某个子进程,而让其他子进程处于空闲状态,这样会使得整机效率低下。我们可以通过轮询或随机派发的方式给子进程派发任务,实现负载均衡。
要给子进程派发任务,我们就需要先拥有任务(Task.hpp)↓↓↓
#include <iostream>
#include <vector>
typedef void(*func_t)();
void task1()
{
std::cout << "昭君一技能" << std::endl;
}
void task2()
{
std::cout << "回城中..." << std::endl;
}
void task3()
{
std::cout << "大招特效" << std::endl;
}
void task4()
{
std::cout << "暴君降临" << std::endl;
}
void LoadTask(std::vector<func_t>& tasks)
{
tasks.push_back(task1);
tasks.push_back(task2);
tasks.push_back(task3);
tasks.push_back(task4);
}
当我们创建进程池时,需要保存各个子进程的写端、进程PID和进程名称(写端是必须保存的,后两者只是为了调试时方便),故我们可以创建一个channel类,用于保存子进程信息↓↓↓
//先描述
class channel
{
public:
channel(int cmdfd, pid_t slaverid, std::string processname)
:_cmdfd(cmdfd)
,_slaverid(slaverid)
,_processname(processname)
{}
int _cmdfd; //发送任务的文件描述符
pid_t _slaverid; //子进程的PID
std::string _processname; //子进程的名字——方便打印日志信息
};
下面给出子进程处理任务的函数(子进程fork之后循环执行该函数代码)↓↓↓
std::vector<func_t> tasks;
void slaver()
{
while(true)
{
int cmdcode = 0;
int n = read(0, &cmdcode, sizeof(int)); //如果父进程没有给子进程发送,子进程阻塞等待
if(n == sizeof(int))
{
std::cout << getpid() << "收到一个任务,并开始执行:" << std::endl;
tasks[cmdcode]();
}
if(n == 0)
{
close(0);
std::cout << getpid() << " quit" << std::endl;
break;
}
}
exit(0);
}
下面我们就要开始编写主体逻辑了,即进程池↓↓↓
std::vector<func_t> tasks;
const int processNum = 5; //进程池中进程个数
void InitProcessPull(std::vector<channel> *channels)
{
std::vector<int> wfd;
for(int i = 0; i < processnum; i++)
{
int pipefd[2]; //临时空间
int n = pipe(pipefd);
assert(!n);
(void)n;
wfd.push_back(pipefd[1]);
pid_t id = fork();
if(id == 0) //child
{
for(auto e : wfd) close(e);
dup2(pipefd[0], 0);
slaver();
exit(0);
}
//father
close(pipefd[0]);
//添加channel字段
std::string name = "process-" + std::to_string(i);
channels->push_back(channel(pipefd[1], id, name));
}
}
下面函数用于给进程池中的进程派发任务↓↓↓
std::vector<func_t> tasks;
const int processNum = 5;
void distribute(const std::vector<channel>& channels)
{
for(int i = 0; i < 10; i++)
{
//1.选择任务
int cmdcode = rand() % tasks.size();
//2.选择进程
int processpos = rand() % channels.size();
//3.发送任务
write(channels[processpos]._cmdfd, &cmdcode, sizeof(int));
sleep(1);
}
}
下面是最终的进程池代码↓↓↓
#include "Task.hpp"
#include <iostream>
#include <string>
#include <vector>
#include <cstdlib>
#include <cassert>
#include <ctime>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
const int processnum = 5;
std::vector<task_t> tasks;
//先描述
class channel
{
public:
channel(int cmdfd, pid_t slaverid, std::string processname)
:_cmdfd(cmdfd)
,_slaverid(slaverid)
,_processname(processname)
{}
int _cmdfd; //发送任务的文件描述符
pid_t _slaverid; //子进程的PID
std::string _processname; //子进程的名字——方便打印日志信息
};
void slaver()
{
while(true)
{
int cmdcode = 0;
int n = read(0, &cmdcode, sizeof(int)); //如果父进程没有给子进程发送,子进程阻塞等待
if(n == sizeof(int))
{
std::cout << getpid() << "收到一个任务,并开始执行:" << std::endl;
tasks[cmdcode]();
}
if(n == 0)
{
close(0);
std::cout << getpid() << " quit" << std::endl;
break;
}
}
exit(0);
}
//输入:const &
//输出:*
//输入输出:&
void InitProcessPull(std::vector<channel> *channels)
{
std::vector<int> wfd;
for(int i = 0; i < processnum; i++)
{
int pipefd[2]; //临时空间
int n = pipe(pipefd);
assert(!n);
(void)n;
wfd.push_back(pipefd[1]);
pid_t id = fork();
if(id == 0) //child
{
for(auto e : wfd) close(e);
dup2(pipefd[0], 0);
slaver();
exit(0);
}
//father
close(pipefd[0]);
//添加channel字段
std::string name = "process-" + std::to_string(i);
channels->push_back(channel(pipefd[1], id, name));
}
}
void debug(std::vector<channel>& channels)
{
for(auto &c : channels)
{
std::cout << c._cmdfd << " " << c._slaverid << " " << c._processname << std::endl;
}
}
void distribute(const std::vector<channel>& channels)
{
for(int i = 0; i < 10; i++)
{
//1.选择任务
int cmdcode = rand() % tasks.size();
//2.选择进程
int processpos = rand() % channels.size();
//3.发送任务
write(channels[processpos]._cmdfd, &cmdcode, sizeof(int));
sleep(1);
}
}
void clean(const std::vector<channel>& channels)
{
for(int i = 0; i < channels.size(); i++)
{
close(channels[i]._cmdfd);
waitpid(channels[i]._slaverid, NULL, 0);
}
// 方式1
// for(int i = 0; i < channels.size(); i++)
// {
// close(channels[i]._cmdfd);
// }
// sleep(2);
// for(int i = 0; i < channels.size(); i++)
// {
// waitpid(channels[i]._slaverid, NULL, 0);
// }
}
int main()
{
srand(time(nullptr)); //种随机数种子
LoadTask(&tasks);
//在组织
std::vector<channel> channels;
//初始化
InitProcessPull(&channels);
//开始控制子进程
//debug(channels);
distribute(channels);
//清理收尾
clean(channels);
return 0;
}
🎈欢迎进入从浅学到熟知Linux专栏,查看更多文章。
如果上述内容有任何问题,欢迎在下方留言区指正b( ̄▽ ̄)d