1、认识哈希函数 (out f(in data))
- 输入参数in,其值域范围可以看作是无穷大的。
- 输出函数out,其值域范围可能性很大,但是一定是有穷尽的
- 哈希函数没有任何随机的机制,固定的输入一定是固定的输出
- 输入无穷多但输出值有限,所以不同输入也可能输出相同(哈希碰撞)
- 再相似的不同输入,得到的输出值,会几乎均匀的分布在out域上
推论:相似字符串,经过 f(str1) 输出一个
0
0
0 ~
2
128
−
1
2^{128} - 1
2128−1中的一个数,经过 %10 之后,在 0~9 上还是均匀分布的
离散性和某个范围的均匀性是一回事。
2、哈希函数作用:可以把数据根据不同值,几乎均匀地分开
举个例子:
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.security.Security;
import javax.xml.bind.DatatypeConverter;
public class Hash {
private MessageDigest hash;
public Hash(String algorithm) {
try {
hash = MessageDigest.getInstance(algorithm);
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
}
}
public String hashCode(String input) {
return DatatypeConverter.printHexBinary(hash.digest(input.getBytes())).toUpperCase();
}
public static void main(String[] args) {
System.out.println("支持的算法 : ");
for (String str : Security.getAlgorithms("MessageDigest")) {
System.out.println(str); //SHA-384、SHA-224、SHA-256、MD2、SHA、SHA-512、MD5
}
System.out.println("=======");
String algorithm = "MD5";
Hash hash = new Hash(algorithm);
String input1 = "maureenmaureen1";
String input2 = "maureenmaureen2";
String input3 = "maureenmaureen3";
String input4 = "maureenmaureen4";
String input5 = "maureenmaureen5";
//结果表示一个十六进制的数,input值的区别很小,但是经过不同的哈希方法,都会将这个不同放得很大
System.out.println(hash.hashCode(input1));
System.out.println(hash.hashCode(input2));
System.out.println(hash.hashCode(input3));
System.out.println(hash.hashCode(input4));
System.out.println(hash.hashCode(input5));
}
}
3、哈希表的设计
哈希表有一个初始的桶区域,长度为17(经验值),即17个桶。
经典的哈希表的设计是 数组 + 单链表。
例如:
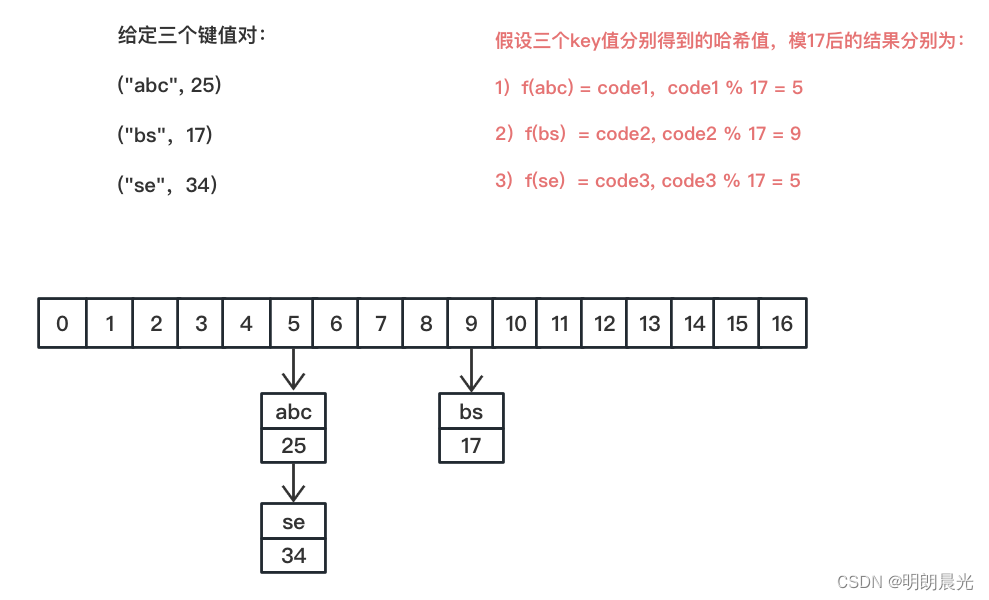
随着数据量的增大,每个桶中的数据数量会均匀增长。
基于上述结构,如果加入 N N N 条记录,一共 17 个桶,则每个桶中的长度是 N / 17 N/17 N/17,且每个桶是用链表保存数据的,那增删改查的时间复杂度是 O ( N ) O(N) O(N) ?那么为什么我们说哈希表的增删改查时间复杂度为 O ( 1 ) O(1) O(1) 呢?
对于这个问题,出现了 哈希表的扩容操作。
人为规定,当某个桶里的数据长度到达 7 的时候,就需要进行扩容。
即当某个桶中存储的数据长度到达 7 的时候(即链的长度为7),因为是均匀增长的,其他桶的长度也差不多到 7 了,于是将桶的个数增长一倍,即由原来 17 长度的桶扩成 34 长度的桶。原先桶中的数据每个都重新计算哈希值,然后模 34,根据不同结果放到新的桶中相应序号中,毫无疑问,每个桶中链表的长度一定是长度为 17 的桶的链表的一半长度。
【证明:都扩容重新计算哈希值了,为什么哈希表的增删改查时间复杂度还是 O ( 1 ) O(1) O(1) 呢?】
假设一开始只有桶区域长度为1,即只有1个桶,且桶中链表长度为2的时候进行扩容,当放入2个数的时候,需要重新准备长度为2的桶区域,然后将原先的2个数重新计算放入新桶中,扩容的代价就是 2 个数变化的代价, O ( 2 ) O(2) O(2);
接下来,放入第 3 个数的时候,又需要扩容,桶区域扩容成4,原先桶中的 3 个数重新计算,扩容代价是 3 个数变化的代价 O ( 3 ) O(3) O(3);
放入第 5 个数的时候,又要扩容,桶区域扩容成 8,原先桶中的 5 个数重新计算,扩容代价是 5 个数变化的代价, O ( 5 ) O(5) O(5);
…
即当桶区域长度为
m
m
m 时,放入第
m
+
1
m+1
m+1 个数的时候就需要扩容。
如果要放入 N N N 个数,则扩容代价 = O ( 2 ) + O ( 3 ) + O ( 5 ) + O ( 9 ) + O ( 17 ) + O ( 33 ) + . . . . . . O(2) + O(3) + O(5) + O(9) + O(17) + O(33) + ...... O(2)+O(3)+O(5)+O(9)+O(17)+O(33)+......,而扩容代价的规律是 当前次是前一次乘2,前面可能不太符合,越到后面越符合这个规律,近似一个等比数列。
所以即便是一开始长度为 1 的桶区域,要放入 N N N 个数,也只需要扩容 l o g N logN logN 次。
且上述例子中,2个数的时候,总代价和 2 有关;4个数的时候,总代价和 4 有关;8个数的时候,总代价和 8 有关;则 N N N 个数的时候,总代价和 N N N 有关。即是等比数列,将这些代价求和的结果就是一个 O ( N ) O(N) O(N) 的时间复杂度。
现在知道,加入 N N N 条记录的时候,即加入了 N N N 个 key,扩容的总代价是 O ( N ) O(N) O(N),而哈希表的增删改查的复杂度指的是单次代价,于是均摊得到 O ( N ) / N = O ( 1 ) O(N) / N = O(1) O(N)/N=O(1)。
已经证明了在桶区域长度为1的情况下,即最差的情况下的哈希表的增删改查的单次时间复杂度为 O ( 1 ) O(1) O(1)。那接下来就要谈谈哈希表在工程上的改进:
- 初始的桶区域长度设置较大。则扩容次数就更少。
- 每个桶中放红黑树组织数据。原先每个桶中用单链表保存数据的时间复杂度已经是 O ( 1 ) O(1) O(1),如果每个桶中放一棵红黑树来保存数据,那时间复杂度比 O ( 1 ) O(1) O(1) 更好了,但是仍然是 O ( 1 ) O(1) O(1)。
所以工程上哈希表的改进对时间复杂度来说并无影响,和经典的哈希表的时间复杂度一样,工程上的改进只是在优化常数项。
更多可见算法:哈希表的设计
4、布隆过滤器
目前布隆过滤器已经在工程上广泛地使用,比如Hadoop分布式文件系统(HDFS)、Redis。
假设现在有一个集合,里面存放的是一些 URL 的黑名单,假设有100亿的数据,规定每个URL的长度不会超过 64 字节。希望把这个集合变成一个服务,以后每出现一个URL,就在集合中查询一下是否在黑名单中,若在黑名单中,则不显示该URL,否则显示。
该要求的最基本实现就是使用哈希表,把每个URL都存入哈希表中,但是这种做法浪费空间,哈希表中如果要存放字符串,一条记录就是 64 字节,100亿不同的URL就需要6400亿字节的空间,则需要 640G 的内存才能支持这个服务。
此时,布隆过滤器就登场了!它解决的仍然是类似的黑名单问题,但是可以节省空间。
布隆过滤器有一定的失误率,这是不可避免的,但是可以通过设计将失误率控制到一个范围中,即在将失误率压得很低的情况下实现空间的节省。这个失误指的是一个给定的URL本来不在黑名单中,但是用布隆过滤器实现的服务可能会有万分之一的误报,而对于一个本来就在黑名单中的URL,会百分百正确地报告,不会失误,也就是宁可误杀也绝不放过。
例如各个搜索引擎公司都会做爬虫,假设有1000个爬虫,如果某个爬虫已经爬到一个URL,那么就不希望别的爬虫重复爬这个URL。所以当某个爬虫爬到了某个URL之后,就希望加入到这个类黑名单的服务中,其他的爬虫在爬URL之前先检查这个URL之前是否爬过,如果没爬过,则继续爬,然后将该URL放到服务中;如果爬过,则直接跳到下一个URL。
【布隆过滤器】
- 利用哈希函数的性质
- 每一条数据提取特征
- 加入描黑库
【布隆过滤器的原理】
什么是位图
假设有一个int型数组 int[10] arr;,,每个数据4字节,于是每个数据有32位,一共占用40B;但是如果用 bit 数组来实现,bit[0] 就是 arr[0] 的第 0 位,bit[1] 就是 arr[0] 的第1位,…, bit[31] 就是 arr[0] 的第 31 位,bit[32] 就是 arr[1] 的第0位,以此类推。如此一来,看似申请了一个长度为10的整型数组,但实际上申请了一个长度为320的bit数组。
布隆过滤器可认为是一系列逻辑 + 位图的整体。
假设准备一个长度为 m m m 的 bit 类型的数组,实际占用的空间为 m / 8 m/8 m/8 字节,这可认为是布隆过滤器的物理结构,即落地在一个长度为 m m m 的比特类型的数组上。
布隆过滤器的逻辑:是如何将URL加入到黑名单中的呢?
假设准备了3个哈希函数 f1 、f2、f3,三个函数相互独立,互不影响。现在有一个 str1,str1会通过三个哈希函数算出三个哈希值,三个哈希值 %m 的结果的相应三个位置(也可能有重复位置,结果数 <=3 )都描黑。然后 str2 也用同样的方式加入黑名单,一直到100亿的URL加入黑名单。
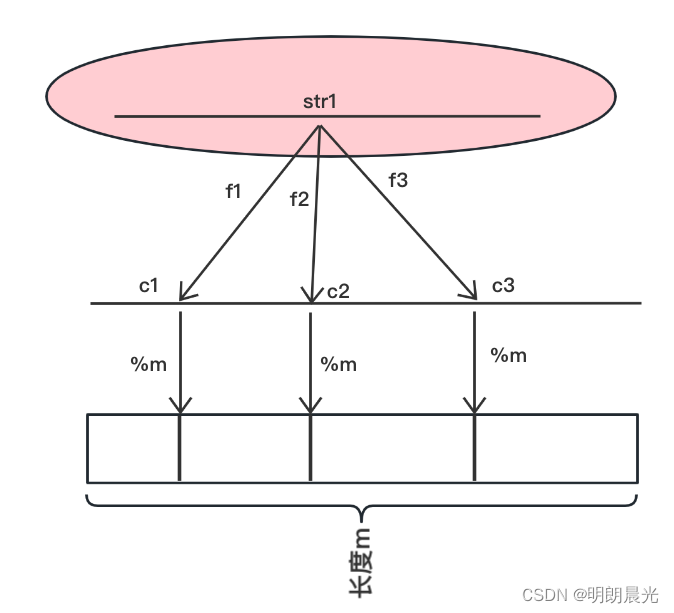
如何查询某个 str 是否在黑名单中
将 str 通过三个哈希函数算出三个哈希值,都 %m 后把状态取出来,只要状态中有一个是白色就说明当初没有加入到黑名单过,三个状态都为黑色才表示在黑名单中。
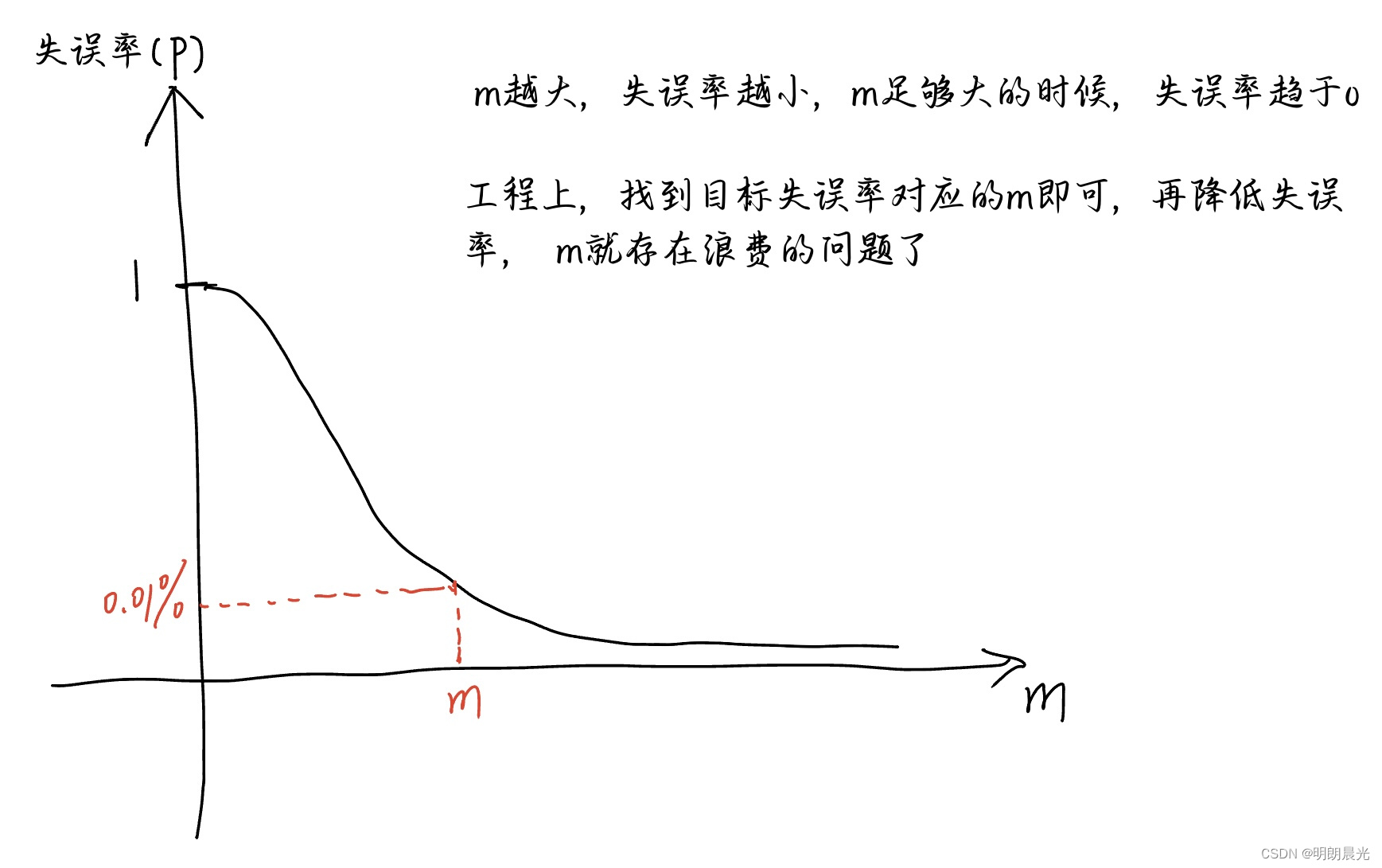
m m m 应该定多大呢?
如果 m m m 定得很小,当数据量很大的时候,可能整个数组都被描黑了,那接下来查的任意字符串都在黑名单中;如果 m m m 定得很大,又很浪费空间。对于布隆过滤器来说, m m m 越大,失误率越小; m m m 越小,失误率越大。
那么 m m m 应该和什么有关呢?(上述例子)
猜测:
1)样本量(100亿)
2)失误率 (0.01%)
3)单样本大小 (64字节) 。
实际哈希函数与“单样本大小 ”无关,任何一个样本只要能通过哈希函数算出哈希值即可,与单样本大小无关, m m m 与其也无关。
所以布隆过滤器到底应该开多大的空间只与 样本量 和 失误率 有关。那到底是什么关系呢?
布隆过滤器的空间 m m m 与 失误率 p p p 的关系
假设样本量固定:
哈希函数的个数如何确定?
如果只选 1 个哈希函数,就会有采样不足的问题,可能会使得失误率变大;但是如果哈希函数的个数过多,则布隆过滤器的空间会被迅速耗尽,也会增大失误率。
哈希函数个数 k k k 与 失误率 p p p 的关系
样本固定的情况下,失误率和哈希函数个数的关系:
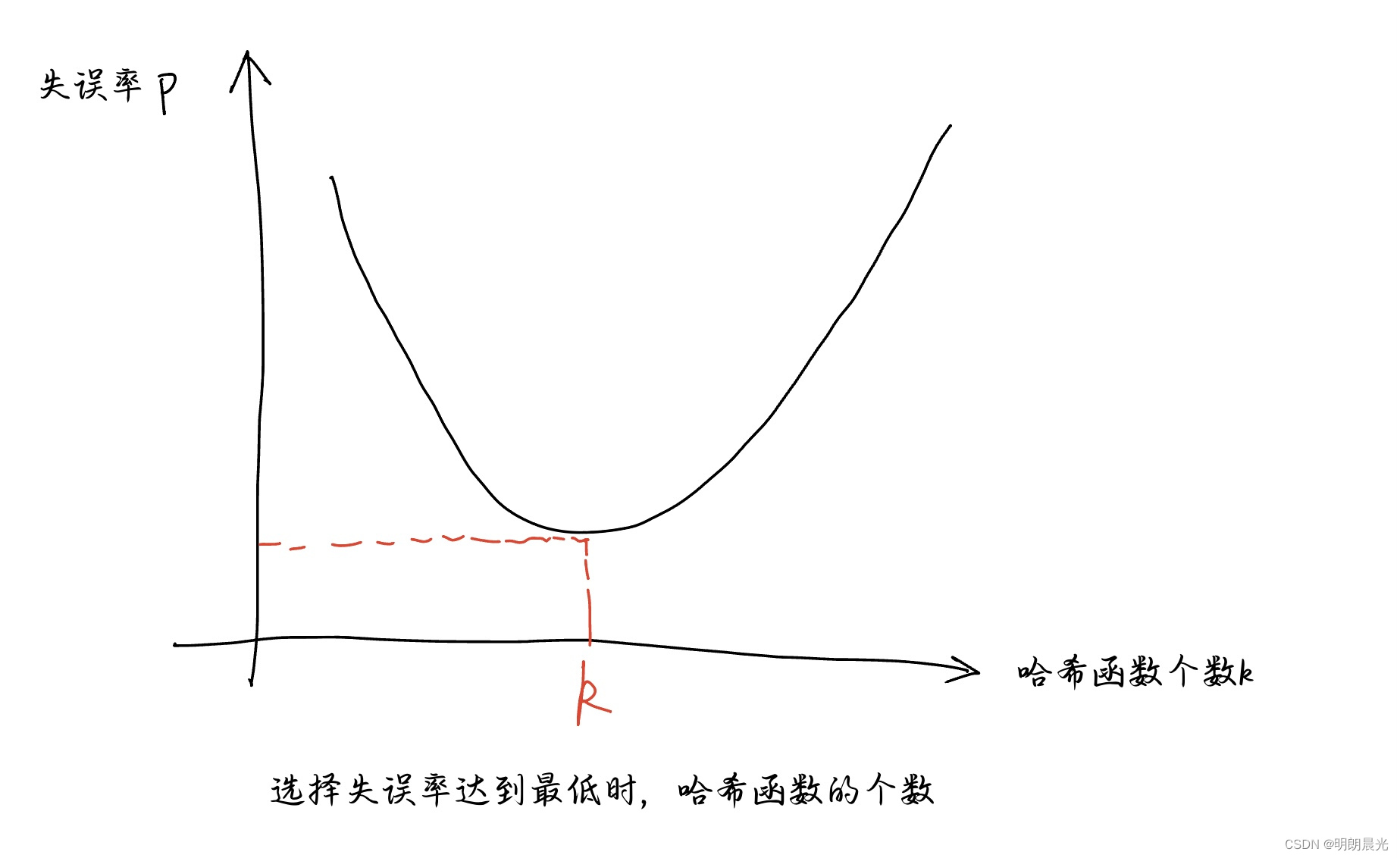
根据上述的关系图,得出了如下的布隆过滤器的三个公式。
5、布隆过滤器重要的三个公式
- 假设数据量为 n n n,预期的失误率为 p p p(布隆过滤器大小和每个样本的大小无关)
- 根据 n n n 和 p p p,算出Bloom Filter一共需要多少个 bit 位,向上取整,记为 m m m
- 根据 m m m 和 n n n,算出Bloom Filter需要多少个哈希函数,向上取整,记为 k k k
- 根据修正公式,算出真实的失误率 p _ t r u e p\_true p_true
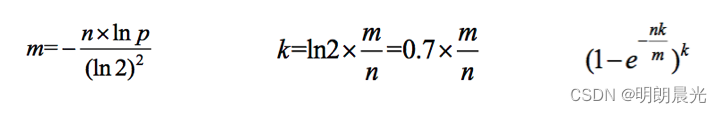
m
=
−
n
×
l
n
p
(
l
n
2
)
2
(
公式
1
)
m = -\frac{n \times ln p}{(ln2)^2} \ \ \ \ (公式1)
m=−(ln2)2n×lnp (公式1)
k
=
l
n
2
×
m
n
=
0.7
×
m
n
(
公式
2
)
k = ln2\times \frac{m}{n} = 0.7\times\frac{m}{n} \ \ \ \ (公式2)
k=ln2×nm=0.7×nm (公式2)
p
_
t
r
u
e
=
(
1
−
e
−
n
k
m
)
k
(
公式
3
)
p\_true = (1-e^{-\frac{nk}{m}})^k \ \ \ \ (公式3)
p_true=(1−e−mnk)k (公式3)
各个公式:
- 公式1用于求解布隆过滤器的空间一共需要 m m m 个bit位;
- 公式2用于求解需要 k k k 个哈希函数;
- 公式3用于求解真实的失误率 p _ t r u e p\_true p_true
代入前文的例子, n = 100 亿 n = 100亿 n=100亿, p = 0.0001 p = 0.0001 p=0.0001:
根据公式1可以得到 m m m bits,即 m / 8 m/8 m/8 Bytes,约为 17G 空间,若有更多的空间如20G,则可以将失误率降得更低。其中17G为理论值 m m m,20G为实际值 m ′ m' m′。
计算哈希函数的个数时代入的是实际值 m ′ m' m′,代入公式 2 中则 k = m ′ / n ∗ 0.7 = 12.7 k = m'/n *0.7 = 12.7 k=m′/n∗0.7=12.7,向上取整 13 13 13。其中 12.7 12.7 12.7 是理论的哈希函数个数 k k k, 13 13 13 是实际的哈希函数个数 k ′ k' k′。
根据实际的空间 m ′ m' m′ 和 实际的哈希函数个数 k ′ k' k′,就能计算出真实的失误率 p _ t r u e p\_true p_true,即上述的公式3。如果多要了空间,算出来的真实失误率一定是比 预期的失误率 p = 0.0001 p = 0.0001 p=0.0001 小的。
那么 13 个哈希函数怎么找呢?
事实上只需要准备两个哈希函数 f1 和 f2,其他的哈希函数都可以由这两个哈希函数造出来:
1)
1
×
(
f
1
返回值
)
+
f
2
1 \times (f1返回值) + f2
1×(f1返回值)+f2
2)
2
×
(
f
1
返回值
)
+
f
2
2 \times (f1返回值) + f2
2×(f1返回值)+f2
3)
3
×
(
f
1
返回值
)
+
f
2
3 \times (f1返回值) + f2
3×(f1返回值)+f2
… …
这些哈希函数之间是几乎独立的。
6、布隆过滤器的应用
- Hadoop分布式文件系统(HDFS)
分块,每块里面存储了若干条记录,每块维护一个各自的布隆过滤器。
当要查询某个字符串在哪一块中时,如果没有Bloom Filter,则要遍历每片中的所有记录;但是如果有布隆过滤器,当字符串来的时候,过滤器就会报告自己所在片是否有该记录,只需要在报告有记录的片中查询即可。
7、一致性哈希
一致性哈希解决的是数据存储的问题。
经典的存储结构
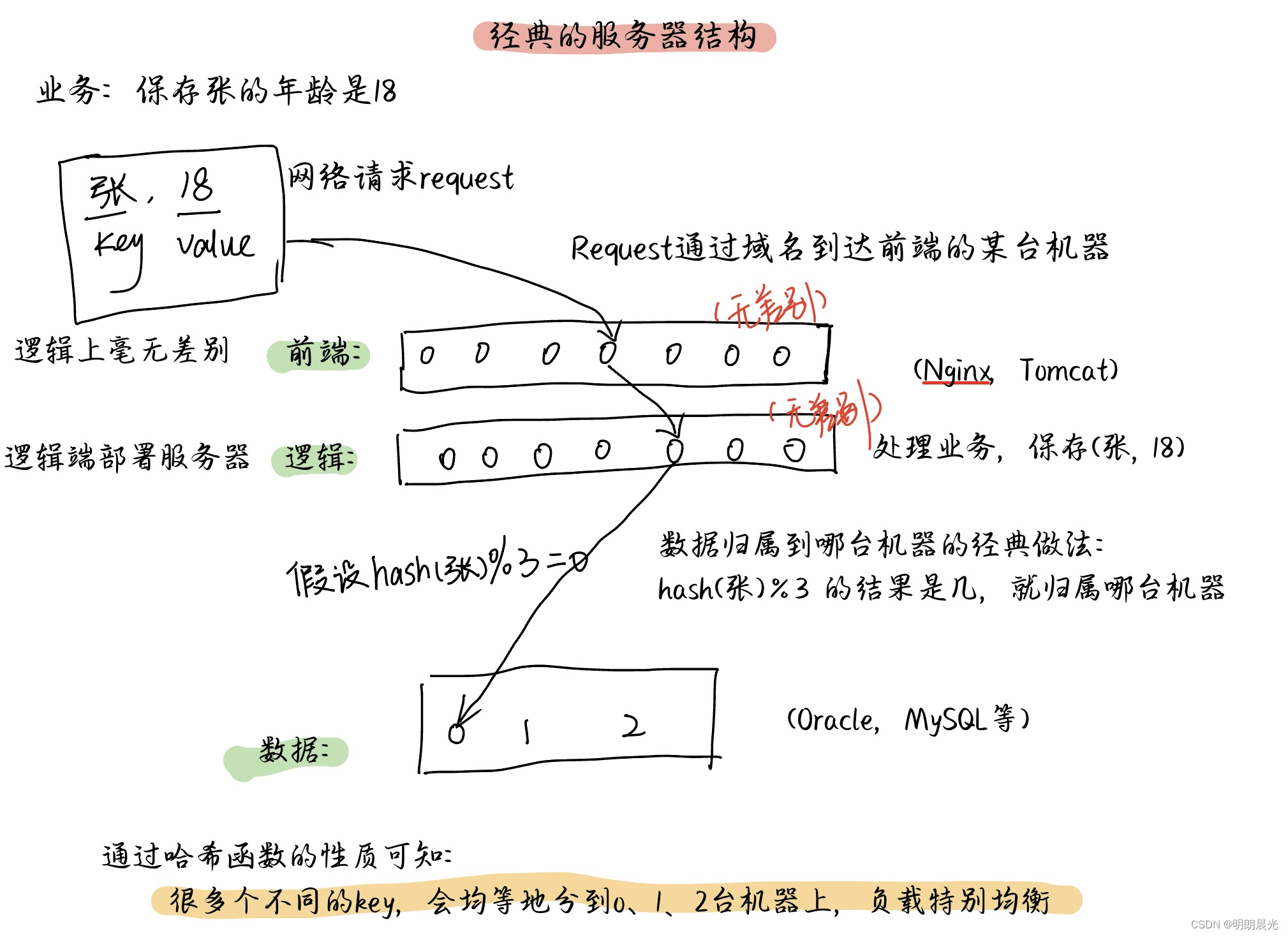
一个小知识:哪个数据是最后用哈希值确定分片的,这个数据中的key叫作HashKey。选择一个良好的HashKey非常重要。
上述例子中,底层数据服务器就0、1、2三台,不同的key会均匀地分到这三台机器上,但是如果HashKey选择不当,可能会出现严重的问题。比如,某天将“国家名”(中、俄、美、日)弄成了HashKey,虽然底层的数据服务器会把不同的key都分到0/1/2机器上去,但是来自中和俄的服务特别多,如此一来,key虽然均分了,但是实际执行的时候总有一台服务器没有中国和俄罗斯的归属那么频繁。即是说不同的key虽然会均等地分到不同的机器上,但是如果业务上很高频,也会导致负载不均衡。
那么应该如何选择HashKey呢?
保证高频的key有一定的量,中频的key也有一定的量,低频的key也有一定的量,且量不小,则各个频次的业务都会均分到三台机器上,这一点只能从业务上挖掘什么key适合做HashKey。
这种存储结构已经几乎完美了——选择合适的HashKey,三台机器能到达负载均衡。但是有一个问题,如果加一台机器,原先的key都要重新 %4 确定它的归属,即便只增加一台机器,数据迁移的代价也是全量的,同理少一台机器也是一样。即只要机器数发生了变化,数据迁移的代价就是全量的。
而一致性哈希就是解决的增加或减少机器使得数据迁移的代价不是全量的,但是仍然负载均衡。
分布式存储结构最常见的结构
1、哈希域变成环的设计
将哈希函数的返回值想象成一个环,假设哈希函数返回值的范围是 0 ~
2
64
−
1
2^{64}-1
264−1,那么形成的环如下:
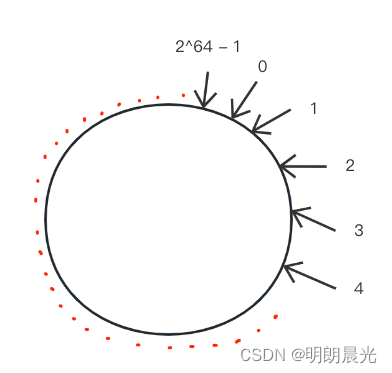
假设一开始有 3 台机器m1、m2、m3,那么每台机器有属于自己的信息(IP、MAC等),就拿 IP 来说,将它们的 IP 认为是字符串,用唯一的哈希函数让 m1、m2、m3上环,即通过哈希函数计算出该字符串的哈希值,然后将三台机器放置到环上。
注意:一致性哈希中通过哈希函数得到的哈希值不需要进行模操作。
继续前文的例子,网络请求“保存(张,18)的数据”会经过层层转发,最后到数据服务器,通过哈希函数计算key值“张”的哈希值,然后上环,数据会被存储到环中顺时针遇到的第一台机器上。
如下图所示:

如何顺时针找到第一台机器?
上述的整个过程就是 IP 值经过哈希函数得到哈希值,然后对哈希值进行排序得到了一个路由表。在逻辑端的每台服务器上都维护了这个有序数组(路由表),假设 hash(“张”) = x,在该有序数组中找到大于 x 最左的位置即可,而这个过程可以使用二分查找。
提出问题:如何保证初始的机器能将环均分?
机器能否将环均分与哈希函数的均匀性无关,因为哈希函数的均匀性针对的是大量的数据会均匀地分布,而少量的数据与其无关。
少量的机器是可能导致哈希值在环上不均的。
即使人为给机器分配哈希值使得原本的机器能均分环,但一旦新增机器立马会导致不均。
解决方案就是下文的虚拟节点技术。
2、虚拟节点技术
依然是上文的三台机器m1、m2、m3,给每台机器分配1000个字符串:
- m1:[a1,a2,…,a1000]
- m2:[b1,b2,…,b1000]
- m3:[c1,c2,…,c1000]
这是一张路由表,每个机器中包含哪些字符可以查到,每个字符串在哪台机器中也可以查到。
我们说,每台机器有 1000 个虚拟节点,每台机器的 1000 个虚拟节点去抢环:a1 抢自己的位置,a2抢自己的位置,…, a1000抢自己的位置,虚拟节点抢到的数据实际归属于m1,另外两台机器同理。
若 b17 的数据要迁移到 c200,后台能查到 b17 属于 m2,于是将 m2 的某些数据给 m3 即可,这就是两台机器之间的数据转移,可以使用物理的方式。
注意,使用虚拟节点技术后,环上没有机器了,只放着各自虚拟节点抢来的数据。这样一来,m1、m2、m3 都负载均衡了。
当新增机器m4的时候,也给m4分配1000个字符串,当这些虚拟节点上环后,m4会均等地向m1、m2、m3要来一样的数据组成自己占所有数据的 1/4 段,这是因为哈希函数的均匀性。
所以,负载问题、均匀问题都是用虚拟节点技术来解决的。
另外,假设m1机器的性能非常强,m2、m3机器较为平庸,m4机器非常差,则可以通过调整虚拟节点的比例,即m1分配2000个虚拟节点,m2、m3分配1000个虚拟节点,m4分配500个虚拟节点来实现负载管理。即虚拟节点技术既能实现负载均衡,也能实现负载管理。