文章目录
- 1 自媒体账号
- 2 Pipelining 流水线
- 2.1 只对最内层的 LOOP_J 循环进行 pipeline
- 2.2 对最外层的 LOOP_I 循环进行 pipeline
- 2.3 对函数 loop_pipeline 进行 pipeline,并对数组A进行分组
- 2.4 思考
1 自媒体账号
目前运营的自媒体账号如下:
- 哔哩哔哩 【雪天鱼】: 雪天鱼个人主页-bilibili.com
- 微信公众号 【雪天鱼】

- CSDN 【雪天鱼】: 雪天鱼-CSDN博客
QQ 学习交流群
- FPGA科研硕博交流群 910055563 (进群有一定的学历门槛,长期未发言会被请出群聊,主要交流FPGA科研学术话题)
- CNN | RVfpga学习交流群(推荐,人数上限 2000) 541434600
- FPGA&IC&DL学习交流群 866169462
菜鸡一枚,记录下自己的学习过程,可能后续有更新,也可能没有更新,谨慎参考。
2 Pipelining 流水线
示例代码链接:Vitis-HLS-Introductory-Examples/Pipelining/Loops/pipelined_loop at master · Xilinx/Vitis-HLS-Introductory-Examples · GitHub
GUI 图形化界面
- 创建 HLS 工程,复制
loop_pipeline.cpp和loop_pipeline.h源文件到该工程 src目录(自己建一个)中并添加 - Project Settings -> Synthesis -> 选择要综合的 Top Function
- 运行 C综合,并进行结果分析
TCL 脚本操作
- 修改 set_part 命令后的芯片型号,确保可用,每次创建一个 solution 都要指定,所以都需要修改下
源文件 loop_pipeline.cpp:
#include "loop_pipeline.h"
dout_t loop_pipeline(din_t A[N]) {
int i, j;
static dout_t acc;
LOOP_I:
for (i = 0; i < 20; i++) {
LOOP_J:
for (j = 0; j < 20; j++) {
acc += A[j] * i;
}
}
return acc;
}
该函数接收数组 A 作为输入,并通过两层嵌套循环计算一个累加表达式 sum(i * A[j]),其中 i 和 j 都是从 0 到 19的整数。最终,函数返回这个累加的结果。接下来进行采用不同的优化指令的综合结果的分析。
2.1 只对最内层的 LOOP_J 循环进行 pipeline
- 试了下对 LOOP_J 添加
set_directive_pipeline -off "loop_pipeline/LOOP_J"编译指示也无法关闭对最内层循环的pipeline,说明 Vitis HLS 可能默认就会优化循环的 II,进行 pipeline . - C++ 综合报告:
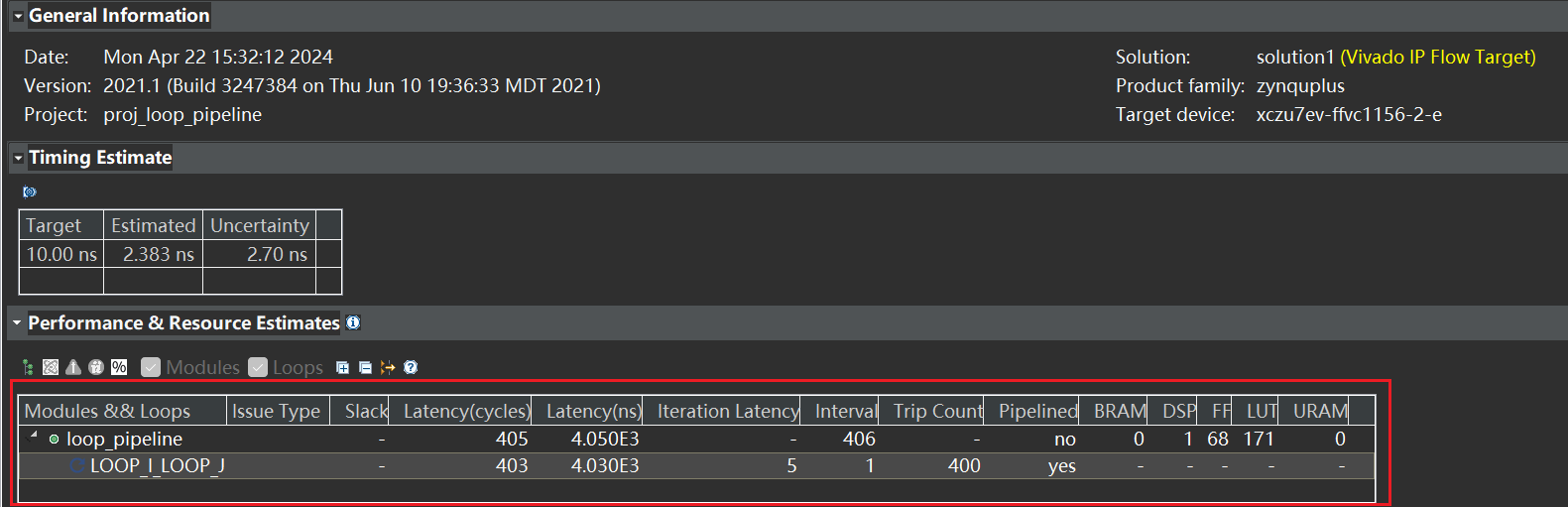
基础概念在 UG1399 的 ch.15 分析综合的结果 章节的 小节 调度查看器中有

LOOP_J 循环单次迭代所需要的时钟周期数(对应报告中的是 Iteration Latency)是 5,然后两次迭代之间的启动时间间隔(对应报告中的 Interval) 是 1, 循环完成的总迭代数( Trip Count)是 400, 即 20x20,循环完成所有迭代所需的时钟周期数(Latency)为 403, 可以理解为 5 + (400 - 1)= 404 (这里不知道为什么少了一周期),即 Latency = Iteration Latency + (Trip Count - 1) x II
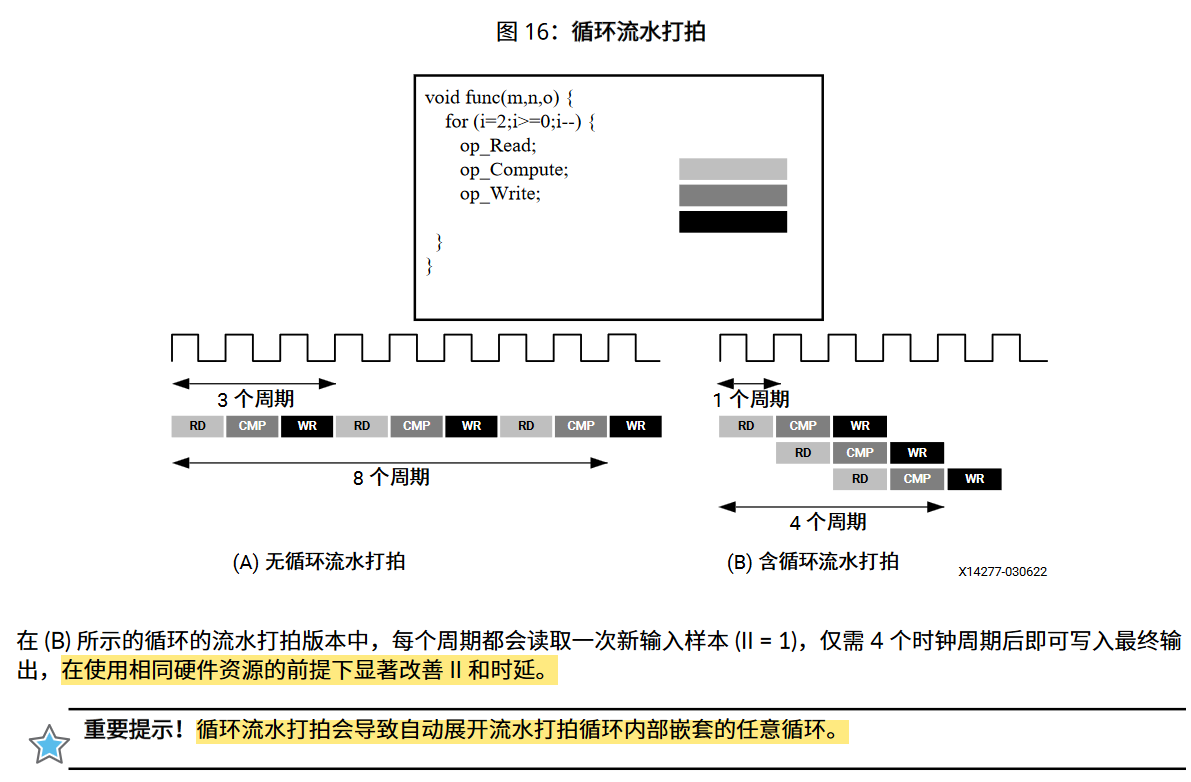
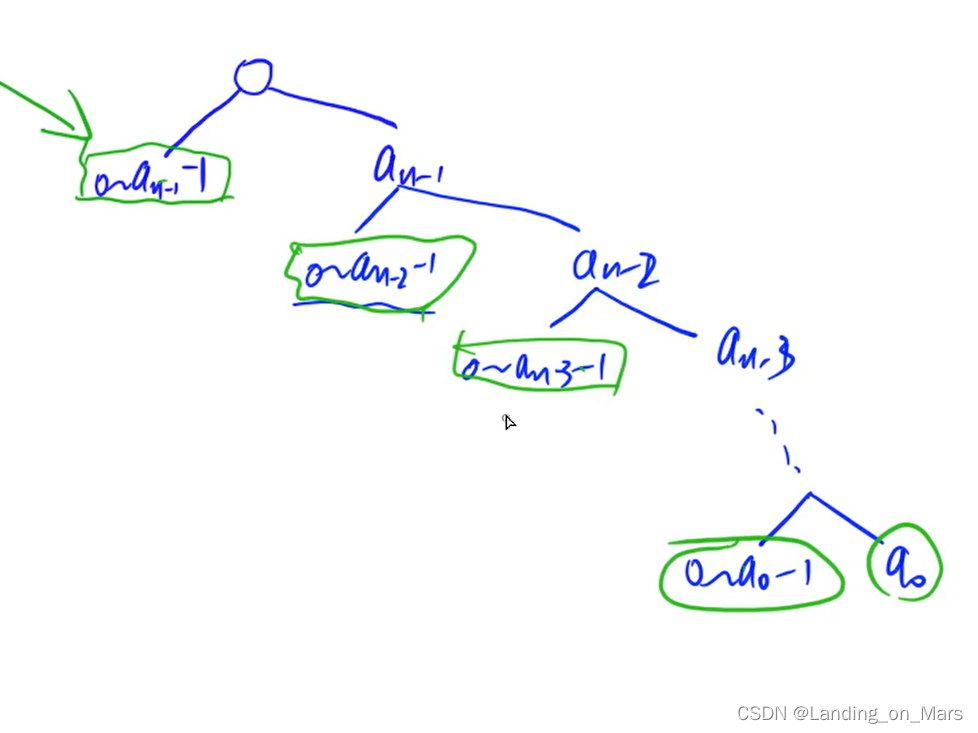
可以参考此图进行理解,无流水线化时 (A) 循环完成3次迭代需要 3x3=9 cycles, 循环流水打拍后(B) 需要 3 +(3-1)=5个周期
我们来把 II 设置为3时,看下结果,根据上面的式子得到 Latency = Iteration Latency + (Trip Count - 1) x II = 5 + 399 x 3 = 1202
(与 HLS 结果相比还是多了一个周期,猜测是HLS是从0计数导致?)
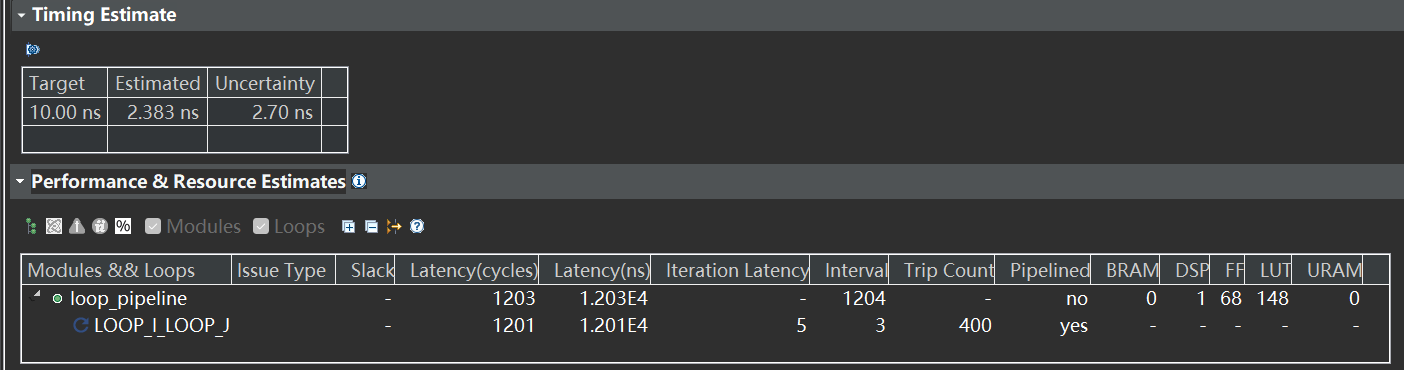
这里我们就可以看出来,对循环的总延迟影响比较大的是 Trip Count 和 II,而 Trip Count 在设计中一般是和实现的算法绑定的比较深的,能比较自由优化的往往是 II, II=3时,可以看到 LUT 是比 II=1时 少用了一些资源,说明当优化 II 时,可能会导致额外的资源开销。而迭代的延迟是和该循环每次迭代进行的具体操作有关,可以打开 Schedule Viewer 进行查看
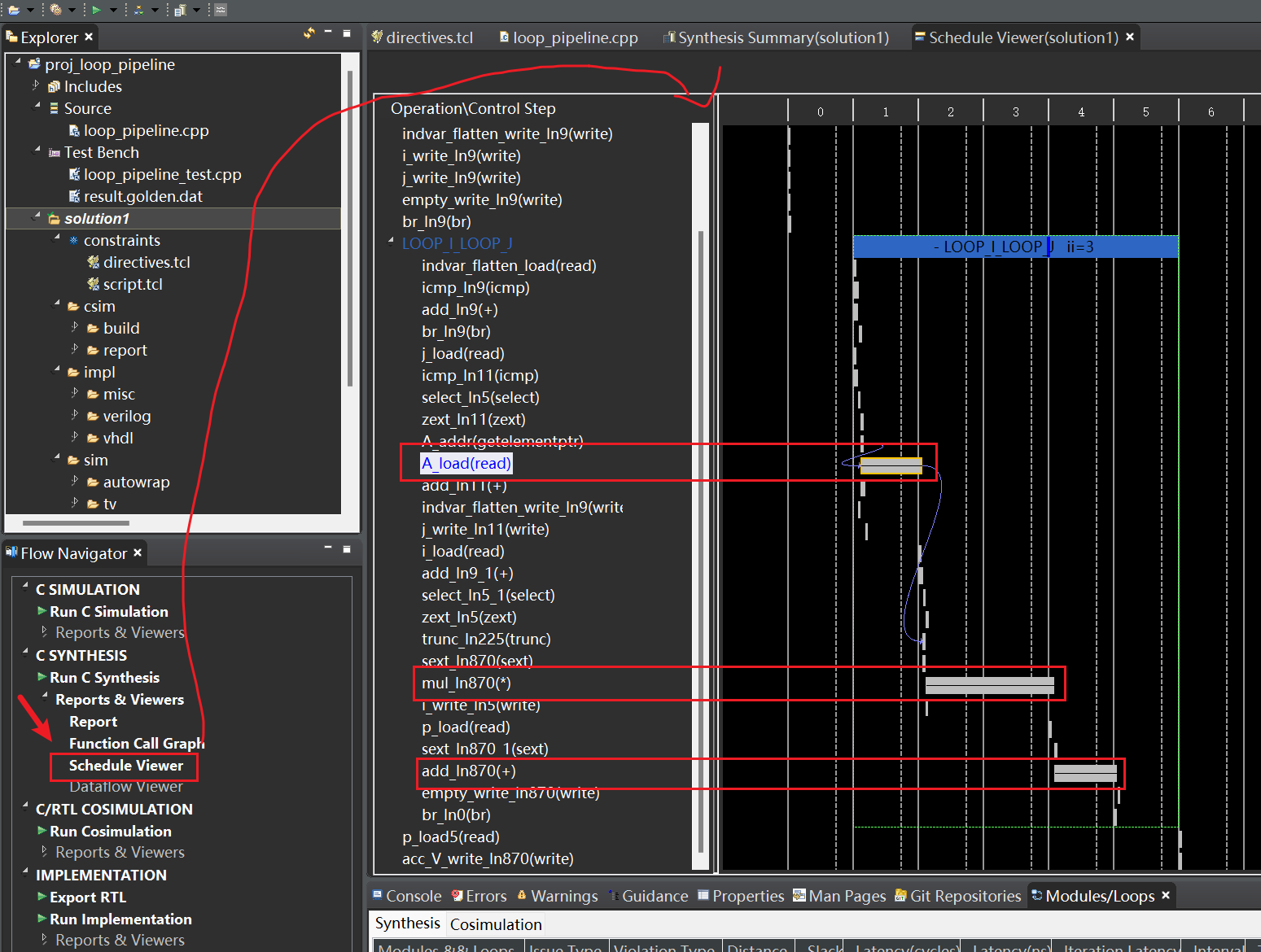
从图中可以看出来,一次迭代主要是加载 A[j] 数据,乘以 i, 以及 累加 acc这三步,所以单次迭代内进行的操作越复杂,所需要的延迟就越大。
2.2 对最外层的 LOOP_I 循环进行 pipeline
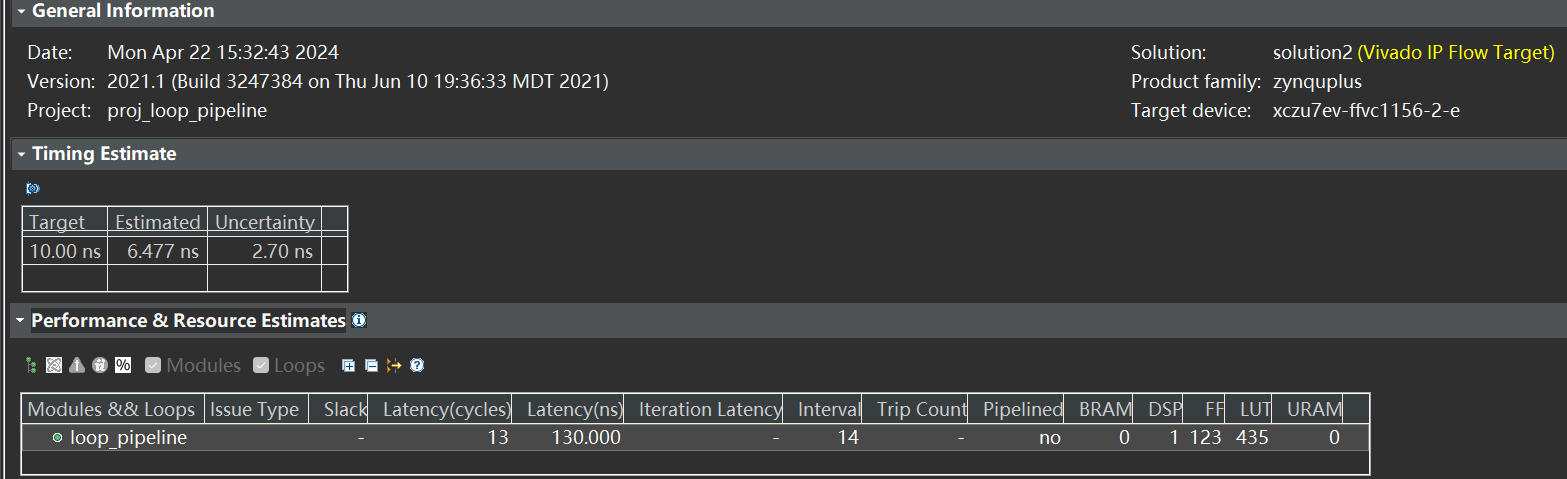
循环就直接没有迭代了,也就是说可以一次性把原先需要迭代 400 次的循环给计算完毕。这里查看如下的C++综合 log 可以发现对 LOOP_J 进行了 unroll 展开,并且是完全展开。可以在一次迭代中完成原先的 LOOP_J 所有计算,而 LOOP_I 没有过多的数据依赖, i 的值是已知的0~19, 所以猜测这里通过表达式优化,直接把所有循环都展开了。
这里的表达式优化是指:每个 A[j] 都会和 0~19都乘以一遍,可以直接求和 0~19,然后一起乘以A[j], 而由于 A[j] 与同一被乘数相乘,所以还可以累加所有的 A[j]
INFO: [XFORM 203-502] Unrolling all sub-loops inside loop 'LOOP_I' (loop_pipeline.cpp:5) in function 'loop_pipeline' for pipelining.
INFO: [HLS 200-489] Unrolling loop 'LOOP_J' (loop_pipeline.cpp:5) in function 'loop_pipeline' completely with a factor of 20.
INFO: [XFORM 203-11] Balancing expressions in function 'loop_pipeline' (loop_pipeline.cpp:5:26)...19 expression(s) balanced.
INFO: [HLS 200-111] Finished Loop, function and other optimizations: CPU user time: 0 seconds. CPU system time: 0 seconds. Elapsed time: 0.111 seconds; current allocated memory: 166.698 MB.
INFO: [HLS 200-111] Finished Architecture Synthesis: CPU user time: 0 seconds. CPU system time: 0 seconds. Elapsed time: 0.058 seconds; current allocated memory: 163.661 MB.
INFO: [HLS 200-10] Starting hardware synthesis ...
INFO: [HLS 200-10] Synthesizing 'loop_pipeline' ...
通过 Schedule Viewer 发现 0~9 每个时钟周期加载了两个 A[j]的值并存储,然后在此过程中不断的累加 A[j] 和 i的值,在第10 ~ 11 完成两个累加结果最终相乘。在第 12 周期完成与 acc 初值的累加,在第 13 周期完成结果的写回。
2.3 对函数 loop_pipeline 进行 pipeline,并对数组A进行分组
编译指示:
set_directive_pipeline "loop_pipeline"
set_directive_array_partition -dim 0 -type complete "loop_pipeline" A
综合报告:
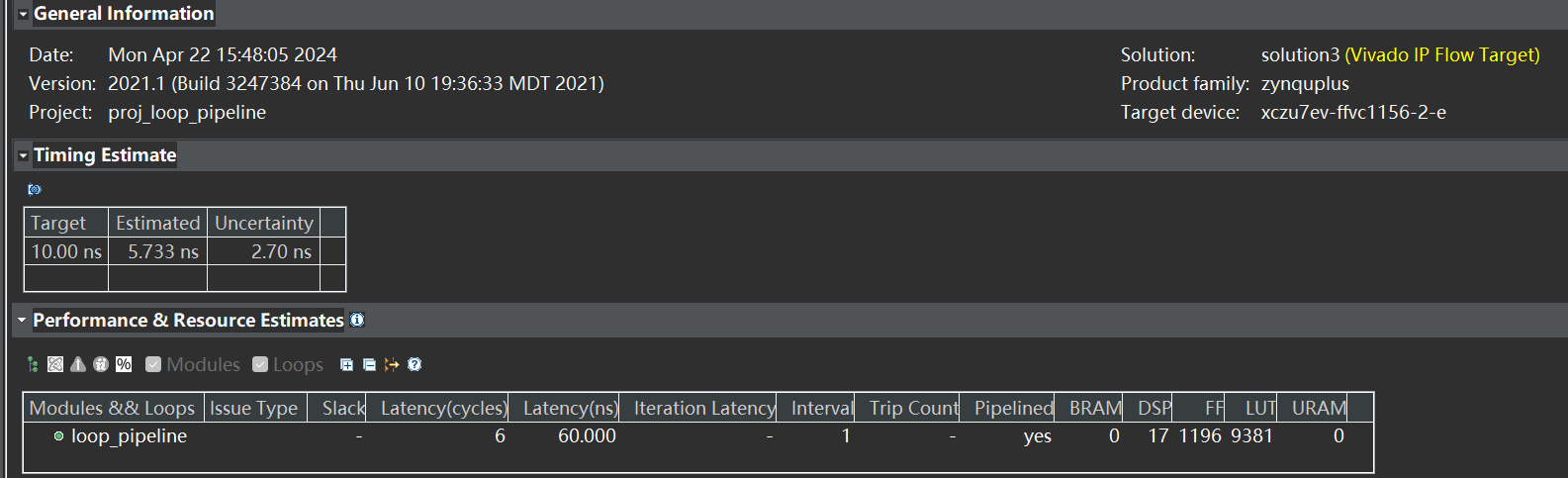
假设我们能在一个时刻而不是顺序依次读取所有 A[j],然后 DSP 的数量也足够,那么可以在一个周期内完成所有 A[j] 与 sum(0, 19)的累加值的相乘,查看 Schedule Viewer 发现 0~4周期用 17个 DSP 完成了所有乘法,第 0~6 周期完成所有加法,最后写入结果。
2.4 思考
- 如何在对最外层的 LOOP_I 循环进行 pipeline 时,控制最内层的 LOOP_J 部分展开。
尝试的方法: - 编译指示solution: 对最外层的 LOOP_I 进行 pipeline 的同时,设置 LOOP_J 按因数 factor = 10 展开 不可行
set_directive_pipeline "loop_pipeline/LOOP_I"
set_directive_unroll -factor 10 "loop_pipeline/LOOP_J"
但实际测试外层的pipeline 会强制完全展开内循环,相关 log 如下:
INFO: [HLS 214-188] Unrolling loop 'LOOP_J' (loop_pipeline.cpp:11:9) in function 'loop_pipeline' partially with a factor of 10 (loop_pipeline.cpp:3:0)
INFO: [XFORM 203-502] Unrolling all sub-loops inside loop 'LOOP_I' (loop_pipeline.cpp:5) in function 'loop_pipeline' for pipelining.
WARNING: [XFORM 203-503] Ignored partial unroll directive for loop 'LOOP_J' (loop_pipeline.cpp:5) because its parent loop or function is pipelined.
INFO: [HLS 200-489] Unrolling loop 'LOOP_J' (loop_pipeline.cpp:5) in function 'loop_pipeline' completely with a factor of 2.
可以看到 WARNING 报的信息是 由于父循环是被 pipelined,所有内循环的部分展开被忽略,强制按 factor = 10x2=20 完全展开
- 编译指示solution: 对最外层的 LOOP_I 不进行 pipeline 的同时,设置 LOOP_J 按因数 factor = 10 展开,与此同时,由于可以同时进行内循环不同迭代的计算了,所以需要对 A数组进行分组,确保可以同时读取对应的A数组中的元素,否则 II 是没法正常优化为 1 的 可行
set_directive_unroll -factor 10 "loop_pipeline/LOOP_J"
set_directive_array_partition -dim 0 -type complete "loop_pipeline" A
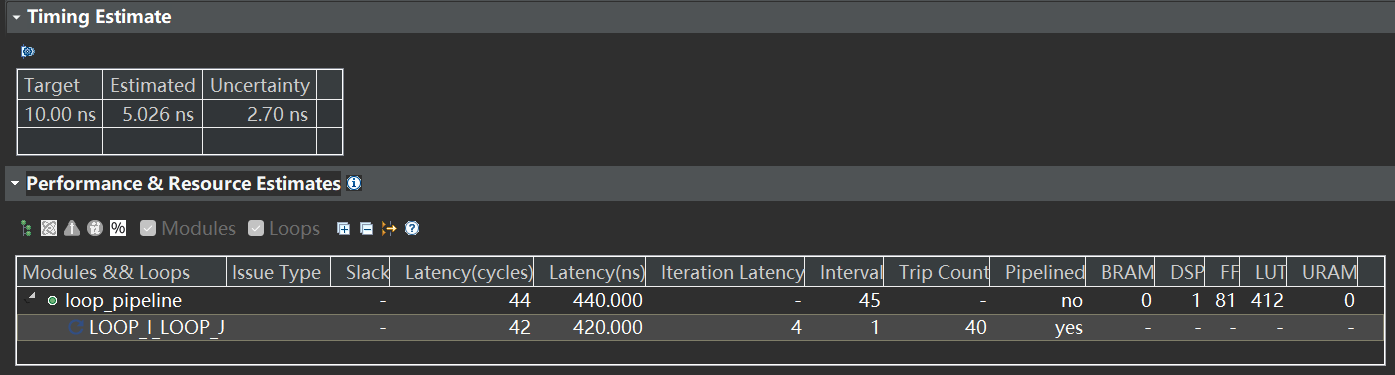
Latency = 4 + (40-1) x 1 = 43, Trip Count = 20x20 / factor(10) = 40
而且这里自动给 II 优化为了 1, 相当于 pipeline 了
没有数组分组的综合报告:

最终优化后的 II 由于数组接口限制就没法达到 1,而是变为了 5