一、本文介绍
本文给大家带来的改进机制是Haar 小波的下采样HWD替换传统下采样(改变YOLO传统的Conv下采样)在小波变换中,Haar小波作为一种基本的小波函数,用于将图像数据分解为多个层次的近似和细节信息,这是一种多分辨率的分析方法。我将其用在YOLOv9上其明显降低参数和GFLOPs在V9上使用该机制后参数量为530W计算量GFLOPs为240(均有大幅度下降),欢迎大家订阅本专栏,本专栏每周更新3-5篇最新机制,更有包含我所有改进的文件和交流群提供给大家。
欢迎大家订阅我的专栏一起学习YOLO!
专栏地址:YOLOv9有效涨点专栏-持续复现各种顶会内容-有效涨点-全网改进最全的专栏
目录
一、本文介绍
二、原理介绍
三、核心代码
四、手把手教你添加HWD机制
4.1 修改一
4.2 修改二
4.3 修改三
4.4 修改四
五、HWD的yaml文件和运行记录
5.1 HWD的yaml文件
5.2 HWD的训练过程截图
五、本文总结
二、原理介绍
官方论文地址:官方论文地址点击此处即可跳转(论文需要花钱此论文)
官方代码地址:官方代码地址点击此处即可跳转
论文介绍了一种基于Haar小波变换的图像压缩方法及其压缩图像质量的评估方法。下面是对论文内容的详细分析:
主要内容和方法
1. Haar小波变换的介绍:
- Haar小波是最简单的小波形式之一,具有易于计算和实现的优点。
- 文章中应用了二维离散小波变换(2D DWT),将图像信息矩阵分解为细节矩阵和信息矩阵。
- 重构图像使用这些矩阵和小波变换的信息完成。
2. 图像压缩技术:
- 压缩技术通过使用Haar小波作为基函数,减少图像文件大小,同时尽可能保持图像质量。
- 压缩过程包括将图像信息转换为更易于编码的格式,这通常涉及转换、量化和熵编码。
结论:论文证明了Haar小波变换是一种有效的图像压缩工具,尤其适合需要高压缩比而又不希望图像质量下降太多的应用场景。此外,通过对比传统的DCT和最新的小波变换方法,作者指出Haar小波在处理图像边缘和细节方面具有一定的优势,尤其是在压缩高分辨率图像时。
三、核心代码
本节的代码使用方式看章节四!
PS:# 按照这个第三方库需要安装pip install pytorch_wavelets==1.3.0
# 如果提示缺少pywt库则安装 pip install
import torch
import torch.nn as nn
try:
from pytorch_wavelets import DWTForward # 按照这个第三方库需要安装pip install pytorch_wavelets==1.3.0
# 如果提示缺少pywt库则安装 pip install PyWavelets
except:
pass
class Down_wt(nn.Module):
def __init__(self, in_ch, out_ch):
super(Down_wt, self).__init__()
self.wt = DWTForward(J=1, mode='zero', wave='haar')
self.conv_bn_relu = nn.Sequential(
nn.Conv2d(in_ch*4, out_ch, kernel_size=1, stride=1),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True),
)
def forward(self, x):
yL, yH = self.wt(x)
y_HL = yH[0][:,:,0,::]
y_LH = yH[0][:,:,1,::]
y_HH = yH[0][:,:,2,::]
x = torch.cat([yL, y_HL, y_LH, y_HH], dim=1)
x = self.conv_bn_relu(x)
return x
if __name__ == "__main__":
# Generating Sample image
image_size = (1, 64, 224, 224)
image = torch.rand(*image_size)
# Model
model = Down_wt(64, 32)
out = model(image)
print(out.size())四、手把手教你添加HWD机制
4.1 修改一
第一还是建立文件,我们找到如下yolov9-main/models文件夹下建立一个目录名字呢就是'modules'文件夹(用群内的文件的话已经有了无需新建)!然后在其内部建立一个新的py文件将核心代码复制粘贴进去即可。

4.2 修改二
第二步我们在该目录下创建一个新的py文件名字为'__init__.py'(用群内的文件的话已经有了无需新建),然后在其内部导入我们的检测头如下图所示。
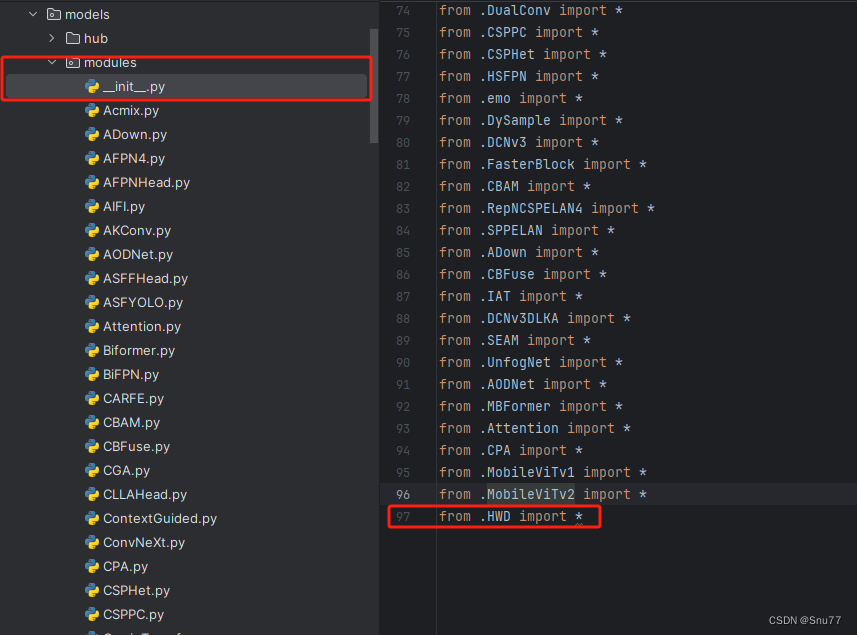
4.3 修改三
然后我们找到如下文件''models/yolo.py''在开头的地方导入我们的模块按照如下修改->
(如果你看了我多个改进机制此处只需要添加一个即可,无需重复添加)
注意的添加位置要放在common的导入上面!!!!!

4.4 修改四
按照我的添加在parse_model里添加即可。
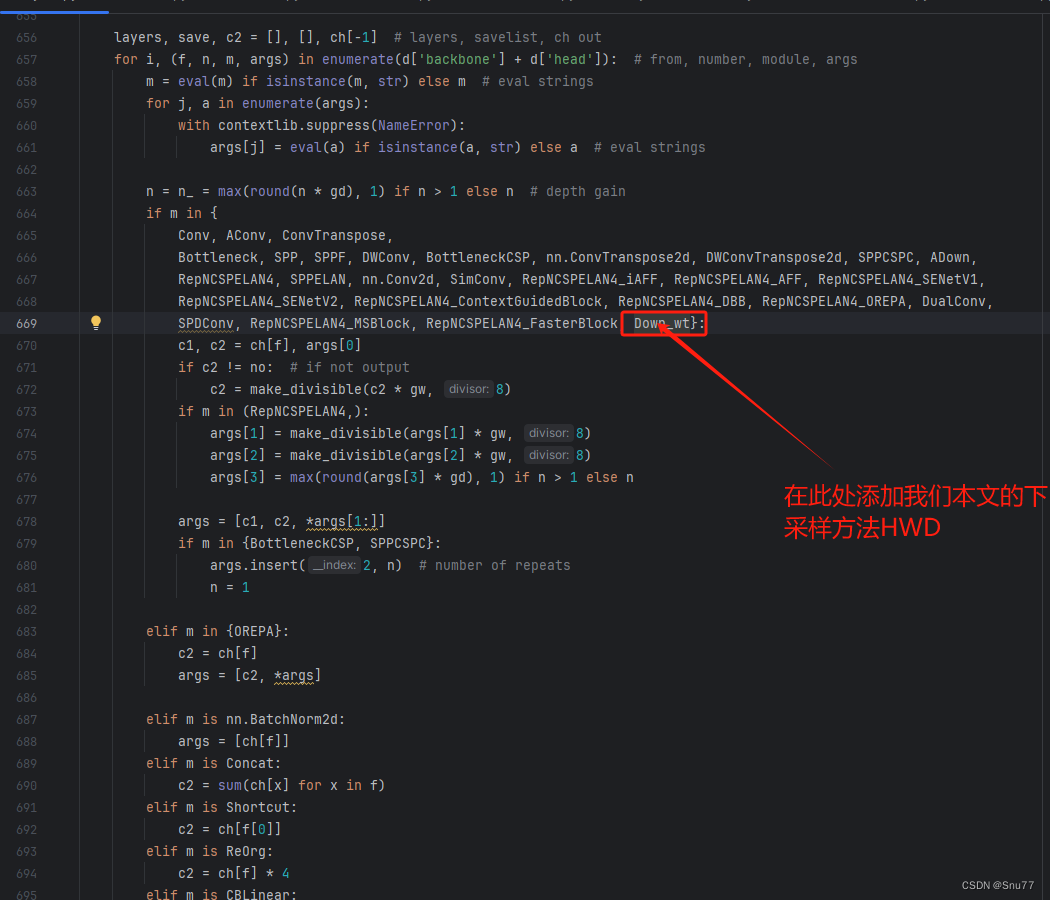
到此就修改完成了,大家可以复制下面的yaml文件运行。
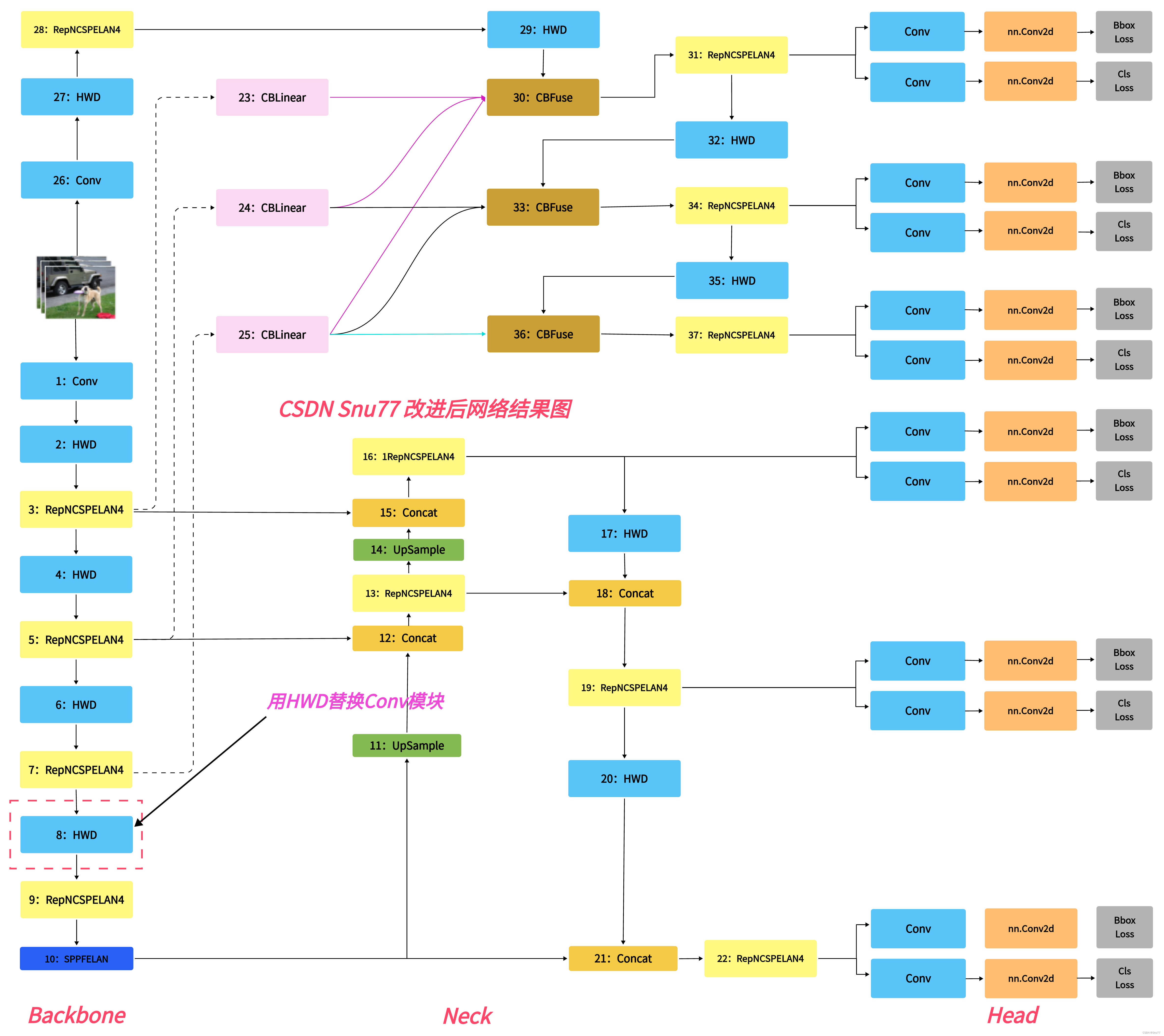
五、HWD的yaml文件和运行记录
5.1 HWD的yaml文件
主干和Neck全部用上该卷积轻量化到机制的yaml文件。
# YOLOv9
# parameters
nc: 80 # number of classes
depth_multiple: 1 # model depth multiple
width_multiple: 1 # layer channel multiple
#activation: nn.LeakyReLU(0.1)
#activation: nn.ReLU()
# anchors
anchors: 3
# YOLOv9 backbone
backbone:
[
[-1, 1, Silence, []],
# conv down
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
# conv down
[-1, 1, Down_wt, [128]], # 2-P2/4
# elan-1 block
[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 3
# conv down
[-1, 1, Down_wt, [256]], # 4-P3/8
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 5
# conv down
[-1, 1, Down_wt, [512]], # 6-P4/16
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 7
# conv down
[-1, 1, Down_wt, [512]], # 8-P5/32
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 9
]
# YOLOv9 head
head:
[
# elan-spp block
[-1, 1, SPPELAN, [512, 256]], # 10
# up-concat merge
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 7], 1, Concat, [1]], # cat backbone P4
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 13
# up-concat merge
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 5], 1, Concat, [1]], # cat backbone P3
# elan-2 block
[-1, 1, RepNCSPELAN4, [256, 256, 128, 1]], # 16 (P3/8-small)
# conv-down merge
[-1, 1, Down_wt, [256]],
[[-1, 13], 1, Concat, [1]], # cat head P4
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 19 (P4/16-medium)
# conv-down merge
[-1, 1, Down_wt, [512]],
[[-1, 10], 1, Concat, [1]], # cat head P5
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 22 (P5/32-large)
# routing
[5, 1, CBLinear, [[256]]], # 23
[7, 1, CBLinear, [[256, 512]]], # 24
[9, 1, CBLinear, [[256, 512, 512]]], # 25
# conv down
[0, 1, Conv, [64, 3, 2]], # 26-P1/2
# conv down
[-1, 1, Down_wt, [128]], # 27-P2/4
# elan-1 block
[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 28
# conv down fuse
[-1, 1, Down_wt, [256]], # 29-P3/8
[[23, 24, 25, -1], 1, CBFuse, [[0, 0, 0]]], # 30
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 31
# conv down fuse
[-1, 1, Down_wt, [512]], # 32-P4/16
[[24, 25, -1], 1, CBFuse, [[1, 1]]], # 33
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 34
# conv down fuse
[-1, 1, Down_wt, [512]], # 35-P5/32
[[25, -1], 1, CBFuse, [[2]]], # 36
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 37
# detect
[[31, 34, 37, 16, 19, 22], 1, DualDDetect, [nc]], # DualDDetect(A3, A4, A5, P3, P4, P5)
]
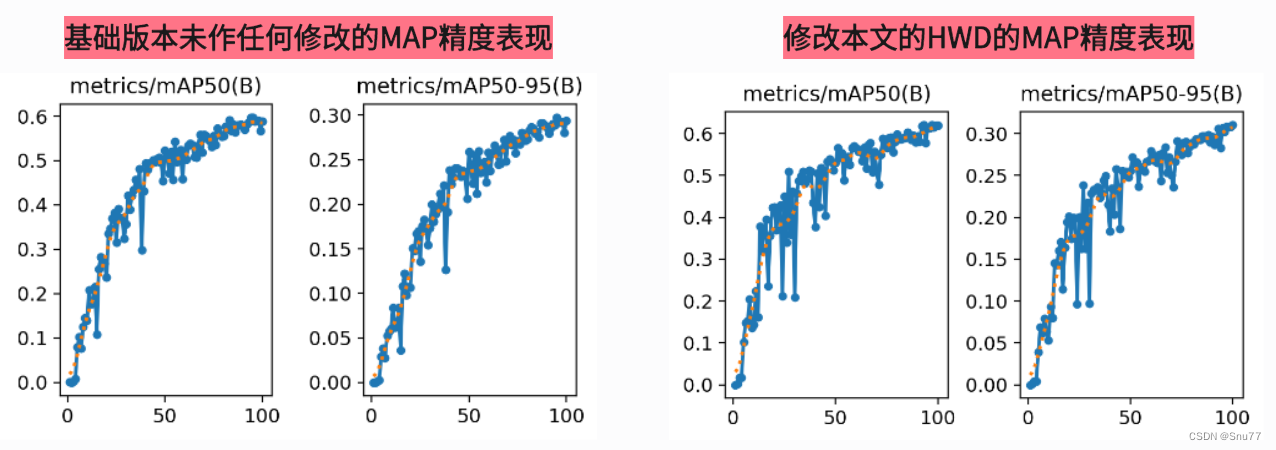
5.2 HWD的训练过程截图
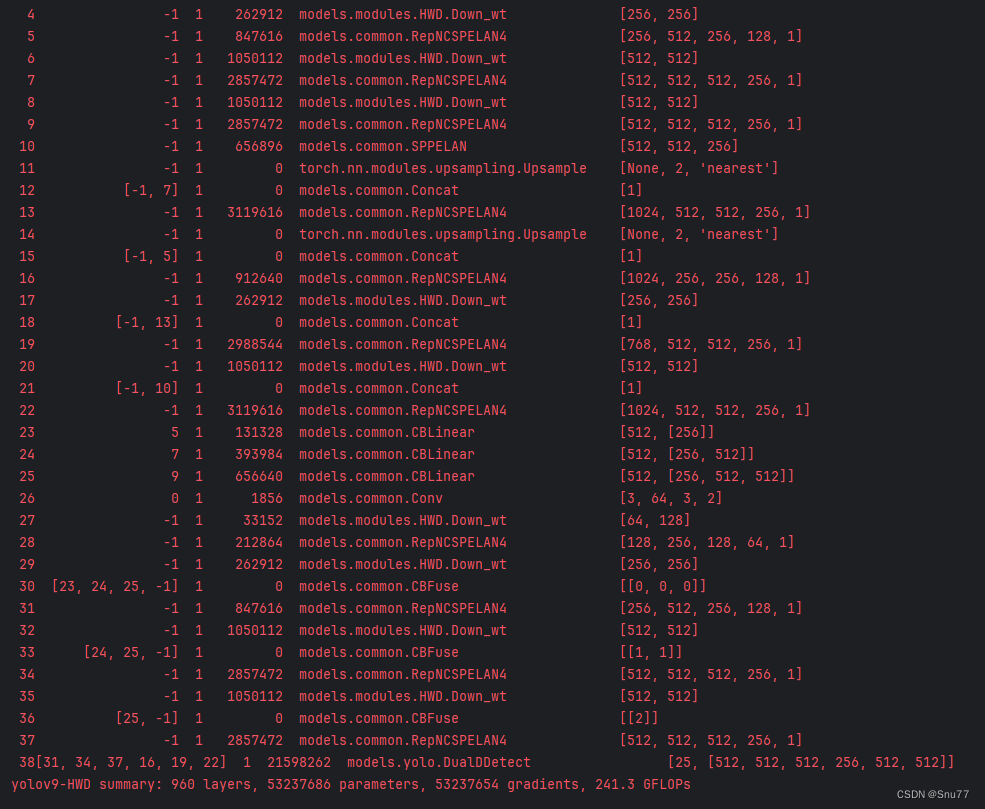
五、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv9改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏地址:YOLOv9有效涨点专栏-持续复现各种顶会内容-有效涨点-全网改进最全的专栏

![哈希表实现[很详细!]](https://img-blog.csdnimg.cn/direct/42ef5e3cf1b34e43998e1d488fc20f8b.png)