目录
哈希表
定义节点类
根据hash码获取value
向hash表存入新key value,如果key重复,则更新value
根据hash码删除,返回删除的value
关于resize()一些问题的解答
冲突测试
MurmurHash
设计思考
练习
Leetcode01
Leetcode03
Leetcode49
Leetcode217
Leetcode136
Leetcode242
Leetcode387
Leetcode819
哈希表
查找数据红黑树B树是对数时间,但是哈希表的速度更快O(1),增删查改

定义节点类
static class Entry{
int hash;//哈希码
Object key;//键
Object value;//值
Entry next;
public Entry(int hash, Object key, Object value) {
this.hash = hash;
this.key = key;
this.value = value;
}
}
//数组存链表头指针即可
Entry[] table = new Entry[16];//选择2^n
int size=0;//元素个数根据hash码获取value
/*求模运算替换为位运算
- 前提:数组长度是2的n次方
- hash % 数组长度 等价于 hash & (数组长度-1)
*/
// 根据hash码获取value
Object get(int hash,Object key){
int idx = hash & (table.length-1);
if(table[idx] == null){
return null;
}
Entry p = table[idx];
while(p!=null){
if(p.key.equals(key)){
return p.value;
}
p=p.next;
}
return null;
}
向hash表存入新key value,如果key重复,则更新value
// 向hash表存入新key value,如果key重复,则更新value
void put(int hash,Object key,Object value){
int idx = hash & (table.length-1);
if(table[idx] == null){
table[idx] = new Entry(hash,key,value);
}else{
Entry p = table[idx];
while(true){
if(p.key.equals(key)){
p.value = value;//更新
return;
}
if(p.next==null){
break;
}
p=p.next;
}
p.next = new Entry(hash,key,value);//新增
}
size++;
}根据hash码删除,返回删除的value
// 根据hash码删除,返回删除的value
Object remove(int hash,Object key){
int idx = hash&(table.length-1);
if(table[idx]==null){
return null;
}
Entry p = table[idx];
Entry prev = null;
while(p!=null){
if(p.key.equals(key)){
//找到了删除 -- 参考单向链表删除
if(prev==null){//删的是链表头元素
table[idx]=p.next;
}else{
prev.next = p.next;
}
size--;
return p.value;
}
prev=p;
p=p.next;
}
return null;
}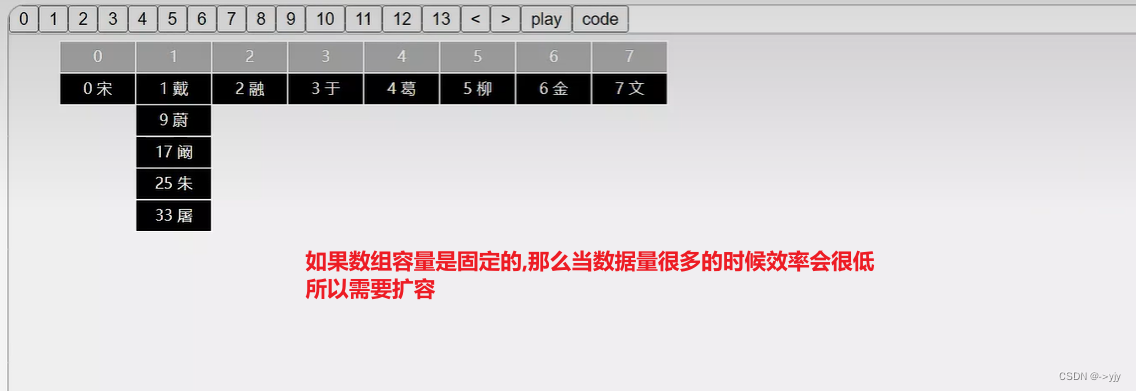
什么时候对哈希表扩容合适呢?
这里引入一个名词:负载因子 load factor(a) = n/m, [n:元素个数 m:数组长度]
这个load factor不宜过大也不宜太小,在Java中合适取值为3/4,这是一个经验值.


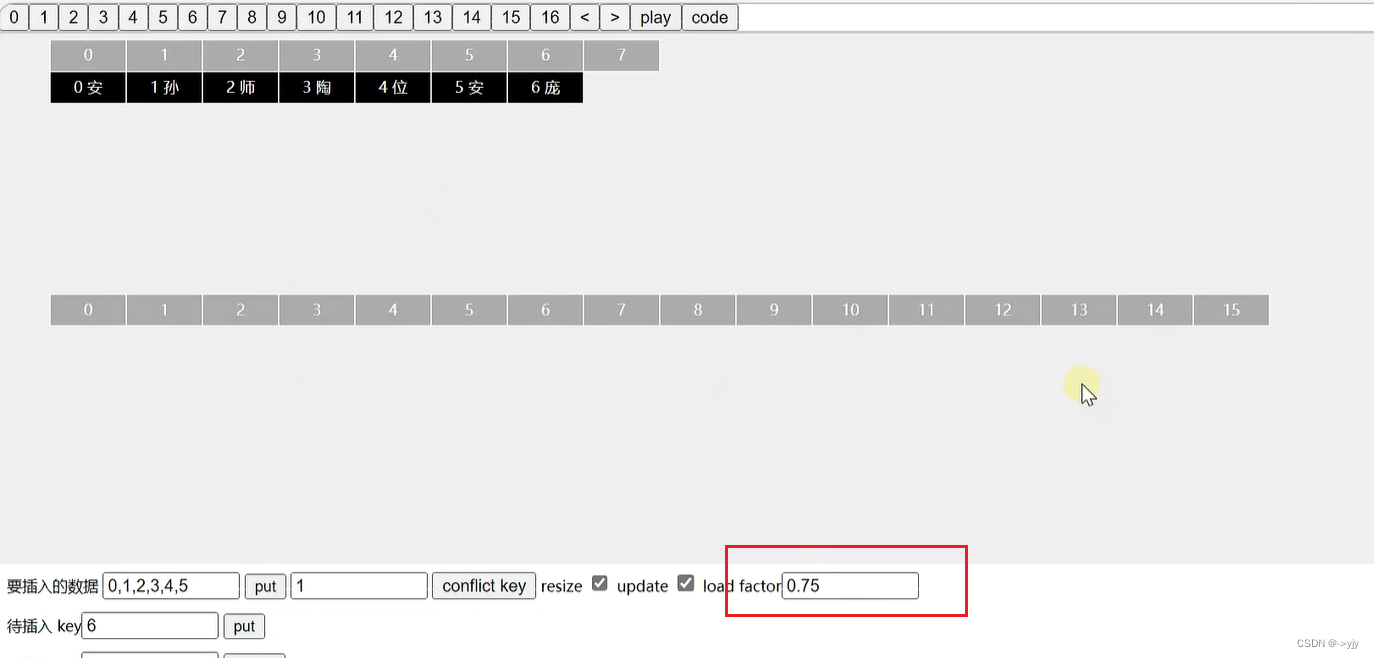
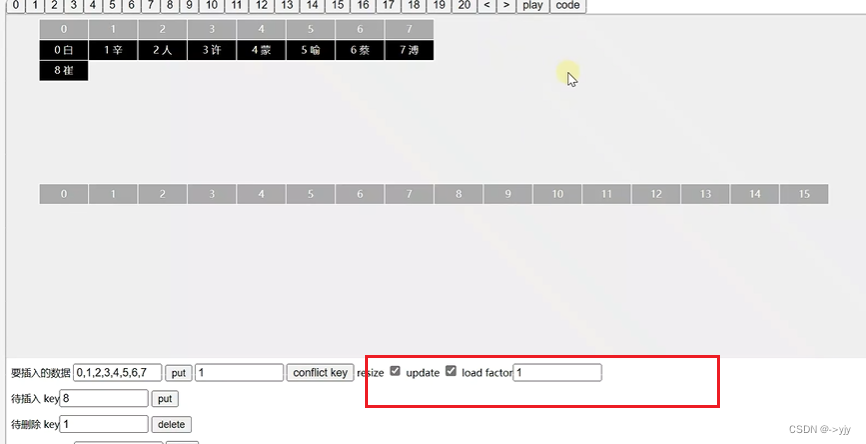
扩容后我们需要将数据转移到新数组中,要重新计算索引
float loadFactor = 0.75f;// 0.75 * 16 = 12(阈值)超过就扩容
int threshold = (int)(loadFactor*table.length);
/*求模运算替换为位运算
- 前提:数组长度是2的n次方
- hash % 数组长度 等价于 hash & (数组长度-1)
*/
// 根据hash码获取value
Object get(int hash,Object key){
int idx = hash & (table.length-1);
if(table[idx] == null){
return null;
}
Entry p = table[idx];
while(p!=null){
if(p.key.equals(key)){
return p.value;
}
p=p.next;
}
return null;
}
// 向hash表存入新key value,如果key重复,则更新value
void put(int hash,Object key,Object value){
int idx = hash & (table.length-1);
if(table[idx] == null){
table[idx] = new Entry(hash,key,value);
}else{
Entry p = table[idx];
while(true){
if(p.key.equals(key)){
p.value = value;//更新
return;
}
if(p.next==null){
break;
}
p=p.next;
}
p.next = new Entry(hash,key,value);//新增
}
size++;
if(size>threshold){
resize();
}
}
private void resize(){
Entry[] newTable = new Entry[table.length<<1];
for(int i = 0;i<table.length;i++){
Entry p = table[i];//拿到每个链表头
if(p!=null){
//拆分链表,移动到新数组
/*
拆分规律
* 一个链表最多拆成两个
* hash & table.length == 0 的一组
* hash & table.length != 0 的一组
p
0->8->16->24->32->40->48->null
a
0->16->32->48->null
b
8->24->40->null
*/
Entry a = null;
Entry b = null;
Entry aHead = null;
Entry bHead = null;
while(p!=null){
if((p.hash & table.length)==0){
if(a!=null){
a.next = p;
}else{
aHead =p;
}
//分配到a
a = p;
}else{
if(b!=null){
b.next = p;
}else{
bHead = p;
}
//分配到b
b = p;
}
p=p.next;
}
// 规律: a 链表保持索引位置不变, b 链表索引位置+table.length
if(a!=null){
a.next = null;
newTable[i] = aHead;
}
if(b!=null){
b.next = null;
newTable[i+table.length] = bHead;
}
}
}
table = newTable;
threshold=(int)(loadFactor*table.length);
}
关于resize()一些问题的解答
/*
为什么计算索引位置用式子:hash & (数组长度-1) 等价于 hash % 数组长度
解释: %10看后一位 %100看后两位
30%2==0
0011110 % 0000010 = 0000000 看后1位
4 0011110 % 0000100 = 0000010 看后2位
0011110 % 0001000 = 0000110 ...
0011110 % 0010000 = 0001110 ...
0011110 % 0100000 = 0011110 ...
文字表达: 10进制中去除以 10,100,1000时,余数就是被除数的后1,2,3位
10^1 10^2 10^3
2进制中去除以10,100,1000时,余数也是被除数的后1,2,3位
2^1 2^2 2^3
:任何一个数字跟 0按位与都等于0 跟1按位与能保留该位
为什么旧链表会拆分成两条,一条hash & 旧数组长度==0 另一条!=0
解释:
旧数组长度换算成二进制后,其中的1就是我们要检查的倒数第几位
旧数组长度 8 二进制 => 1000 检查倒数第4位
旧数组长度 16 二进制 => 10000 检查倒数第5位
hash & 旧数组长度,就是用来检查扩容前后索引位置(余数) 会不会变
为什么拆分后的两条链表,一条原索引不变,另一个是原索引+旧数组长度
解释:跟上面那个问题一样 二进制第i位 只能是0或者1
它们都有个共同的前提:数组长度是2的n次方
*/
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
Object obj = new Object();
System.out.println(obj.hashCode());
/*
1922154895
883049899
2093176254
1854731462
317574433
885284298
1389133897
1534030866
664223387
824909230
*/
}
Object obj1 = new Object();
for (int i = 0; i < 10; i++) {
System.out.println(obj1.hashCode());//同一对象的hashCode值是一样的
}
} public Object get(Object key){
int hash = getHash(key);
return get(hash,key);
}
public void put(Object key,Object value){
int hash = getHash(key);
put(hash,key,value);
}
public Object remove(Object key){
int hash = getHash(key);
return remove(hash,key);
}
private static int getHash(Object key) {
int hash = key.hashCode();
return hash;
}但是更多时候我们是不想用Object父类给我们提供的hashCode方法的,比如字符串类
public static void main(String[] args) {
String s1 = "abc";
String s2 = new String("abc");
System.out.println(s1.hashCode());
System.out.println(s2.hashCode());//结果发现两个哈希码一样 说明父类的hashcode被重写了
//那我们来看看字符串的哈希码如何生成的
//原则:值相同的字符串生成相同的hash码,尽量让值不同的字符串生成不同的hash码
/*
对于 abc a*100 + b*10 + c
对应 bac b*100 + a*10 + c
*/
int hash=0;
for (int i = 0; i < s1.length(); i++) {
char c = s1.charAt(i);
System.out.println((int)c);
// hash= hash*10 + c;//这个10 换成31就是底层内部的实现了
// hash = hash*31+c;
hash = (hash<<5)-hash+c; //这样效率比乘法更高
}
System.out.println(hash);
}冲突测试
检测链表长度
public void print(){
int[] sums = new int[table.length];
for(int i = 0;i<table.length;i++){
Entry p = table[i];
while(p!=null){
sums[i]++;
p = p.next;
}
}
System.out.println(Arrays.toString(sums));
}
public static void main(String[] args) {
HashTable table = new HashTable();
for (int i = 0; i < 20; i++) {
Object obj = new Object();
table.put(obj,obj);
}
table.print();
}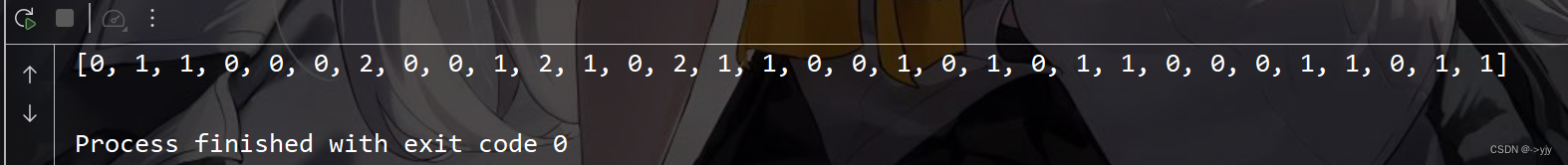
当然数量可能还是有点少
public void print(){
int[] sums = new int[table.length];
for(int i = 0;i<table.length;i++){
Entry p = table[i];
while(p!=null){
sums[i]++;
p = p.next;
}
}
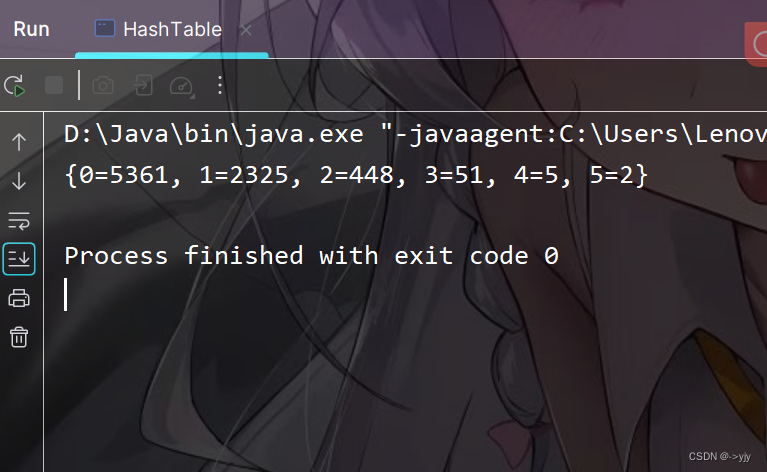
// System.out.println(Arrays.toString(sums));
Map<Integer, Long> collect = Arrays.stream(sums).boxed().
collect(Collectors.groupingBy(e -> e, Collectors.counting()));
System.out.println(collect);
}
public static void main(String[] args) {
HashTable table = new HashTable();
for (int i = 0; i < 200000; i++) {
Object obj = new Object();
table.put(obj,obj);
}
table.print();
}
如果对字符串呢?
public void print(){
int[] sums = new int[table.length];
for(int i = 0;i<table.length;i++){
Entry p = table[i];
while(p!=null){
sums[i]++;
p = p.next;
}
}
// System.out.println(Arrays.toString(sums));
Map<Integer, Long> collect = Arrays.stream(sums).boxed().
collect(Collectors.groupingBy(e -> e, Collectors.counting()));
System.out.println(collect);
}
public static void main(String[] args) throws IOException {
HashTable table = new HashTable();
List<String> strings = Files.readAllLines(Path.of("C:\\大一学习\\Java\\YJY\\learning\\src\\Tree\\a.txt"));
for (String string : strings) {
table.put(string,string);
}
table.print();
}
}
MurmurHash
第二代哈希算法

- 引入google guava 依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.1-jre</version>
</dependency>
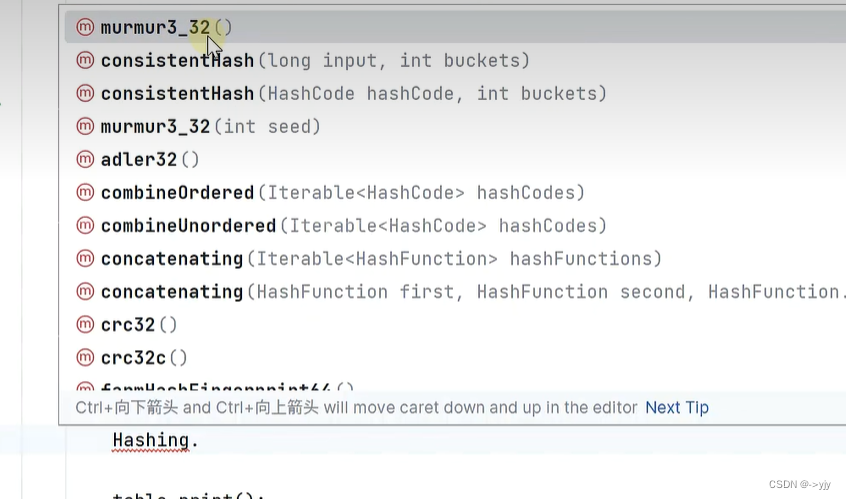
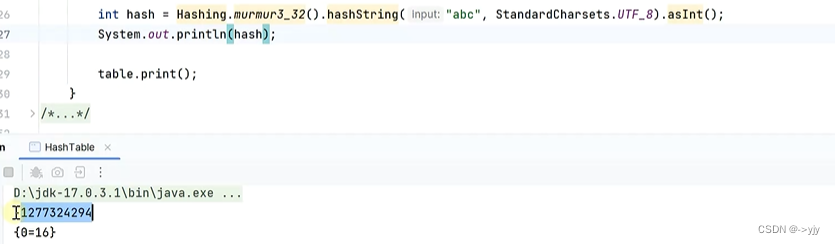

对比:

设计思考

1.Java内部HashTable 就是运用头插法 HashMap 在1.7版本也是头插法,后来因为在多线程下会导致死循环问题所以改为尾插法
2.
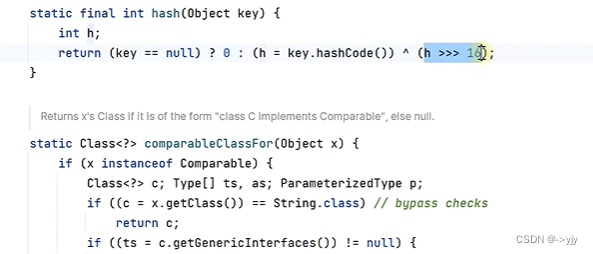
在我们自己的实现中:
源代码中通过 hash^(hash>>>16) 这样就能够避免上面产生的问题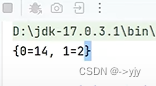
不过这是有前提的 是要在数组容量是2^n次方下,如果不是就可以不用
3. ==> 2^n 按位与 拆分链表 高低位异或
Java中的HashTable 就不是用2^n次方 初始容量是11 是一个质数 求模算余数分布性更好 因此也不需要高低位异或
4.防患于未然 有的人造攻击的哈希数组,一旦造成冲突会导致服务器性能下降,这种做法是一种保底的做法 一般都是6到头了 除非恶意
练习
Leetcode01
1. 两数之和 - 力扣(LeetCode)
import java.util.HashMap;
/**
* <h3>两数之和</h3>
* 给定一个整数数组nums和一个整数目标值target,请你在该数组中找出和为目标值target的那两个整数,并返回他们的数组下标
* 注意:<strong>只会存在一个有效答案</strong>
*/
public class Leetcode01 {
/*
[(2,0),(6,1),]
输入: nums = [2,7,11,15],target = 9
输出: [0,1]
解释: 因为 nums[0] + nums[1] == 9,返回[0,1]
输入: nums = [3,3],target = 6
输出: [1,2]
输入: nums = [3,3],target = 6
输出: [0,1]
思路:
1.循环遍历数组,拿到每个数字 X
2.以 target-x作为key到hash表查找
1) 若没找到,将x作为key,它的索引作为value放入hash表
2) 若找到了,返回x和它配对数的索引即可
*/
public int[] twoSum(int[] nums,int target){
HashMap<Integer,Integer>map = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
int x = nums[i];
int y = target-x;
if(map.containsKey(y)){
return new int[]{i,map.get(y)};
}else{
map.put(x,i);
}
}
return null;
}
}
Leetcode03
3. 无重复字符的最长子串 - 力扣(LeetCode)
import java.util.HashMap;
/**
* <h2>无重复字符的最长子串</h2>
* <p>1.给定一个字符串s,请你找出其中不含有重复字符的最长子串的长度.</p>
* <p>2.s由英文字母,数字,符号和空格组成</p>
*/
public class Leetcode03 {
public int lengthOfLongestSubstring(String s){
HashMap<Character,Integer> map = new HashMap<>();//key返回比较大用hashMap 但是这道题目仅仅是128个字符可以用数组
int begin = 0;
int maxLength = 0;
for(int end = 0;end<s.length();end++){
char ch = s.charAt(end);
if (map.containsKey(ch)) {//重复时,调整begin
begin = Math.max(begin,map.get(ch) + 1);//防止begin回退
map.put(ch,end);
}else{//没有重复
map.put(ch,end);
}
// System.out.println(s.substring(begin,end+1));
maxLength = Math.max(maxLength,end - begin +1);
}
return maxLength;
}
public static void main(String[] args){
// System.out.println(new Leetcode03().lengthOfLongestSubstring("abcabcbb"));
Leetcode03 e02 = new Leetcode03();
// System.out.println(e02.lengthOfLongestSubstring("abcabcbb"));
System.out.println(e02.lengthOfLongestSubstring("abba"));
/*
[(a,0),(b,2)]
b
e
abba
*/
/*
a
ab
abc
bca
cab
abc
cb
b
*/
/*
给定一个字符串 s ,请你找出其中不含重复字符的最长子串的长度
abcabcbb 3
a
ab
abc
bca
cab
abc
cb
b
bbbbbb 1
b
pwwkew 3
p
pw
w
wk
wke
kew
[(a,3),(b,7),(c,5)]
b
e
abcabcbb
要点:
1.用 begin 和 end 表示子串开始和结束位置
2.用hash表检查重复字符
3.从左到右查看每一个字符,如果:
- 没遇到重复字符,调整end
- 遇到重复的字符,调整begin
- 将当前字符放入hash表
4.end - begin + 1 是当前子串长度
*/
}
}
运用了滑动窗口的思路
滑动窗口做题思路-CSDN博客
Leetcode49
49. 字母异位词分组 - 力扣(LeetCode)
import java.util.*;
/**
* 字母异位次分组
*/
public class Leetcode49 {
/*
思路:
1.遍历字符串数组,每个字符串中的字符重新排序后作为key
2.所谓分组,其实就是准备一个集合,把这些单词加入到key相同的集合中
3.返回分组结果
*/
public List<List<String>> groupAnagrams(String[] strs){ // 6ms
HashMap<String, List<String>>map = new HashMap<>();
for (String str : strs) {
char[] chars = str.toCharArray();
Arrays.sort(chars);
String key = new String(chars);//字符数组->字符串
List<String> list = map.computeIfAbsent(key, k -> new ArrayList<>());
//computeIfAbsent原理:先看key在map中是否存在,如果缺失(absent)就会创建一个新的集合放到集合中
//如果不是absent那就不会创建 然后把list集合作为结果进行返回
list.add(str);
}
return new ArrayList<>(map.values());//map.values就是分的组
}
public static void main(String[] args) {
// ab ba
// eat eta tae tea ate aet
String[] strs = {"eat","tea","tan","ate","nat","bat"};
// eat tea ate => aet
// tan nat => ant
// bat => abt
// [(aet,{eat,tea}), (ant,{tan})]
List<List<String>>lists = new Leetcode49().groupAnagrams(strs);
System.out.println(lists);
}
}
computeIfAbsent()那一段可以这么写: 性能上是差不多的只是看起来更简洁
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
HashMap<String,List<String>>map = new HashMap<>();
for(String str:strs){
char[] chars = str.toCharArray();
Arrays.sort(chars);
String key = new String(chars);
List<String>list = map.get(key);
if(list ==null){
list = new ArrayList<>();
map.put(key,list);
}
list.add(str);
}
return new ArrayList<>(map.values());
}
}第二种方法:效率更高 5ms
static class ArrayKey {//一个整数数组做一个封装
int[] key = new int[26];
//alt+insert ==>生成 基于数组的equals 和 hashCode
@Override
public boolean equals(Object o) {
if (this == o) return true;//同一对象
if (o == null || getClass() != o.getClass()) return false;
ArrayKey arrayKey = (ArrayKey) o;
return Arrays.equals(key, arrayKey.key);//比较内容
}
@Override
public int hashCode() {
return Arrays.hashCode(key);
}
//将字符串变成整数数组
public ArrayKey(String str){
for (int i = 0; i < str.length(); i++) {
char ch = str.charAt(i);// 'a'97-97= 0(映射到索引0) 'b'98-97=1 'a'
key[ch-97]++;
}
}
}
/*
bitmap 位图思想
题目有说明:strs[i] 仅包含小写字母
key = [2,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0] 26
key = [2,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0] 26
"eaat","teaa"
*/
public List<List<String>> groupAnagrams(String[] strs){
HashMap<ArrayKey,List<String>>map = new HashMap<>();
for (String str : strs) {
ArrayKey key = new ArrayKey(str);
List<String> list = map.computeIfAbsent(key, k -> new ArrayList<>());
list.add(str);
}
return new ArrayList<>(map.values());
}
Leetcode217
217. 存在重复元素 - 力扣(LeetCode)
/*
[1,2,3,1]
[1,2,3] => true
*/
public boolean containsDuplicate1(int[] nums) {//11ms
HashMap<Integer,Integer> map = new HashMap<>();
for(int key:nums){
if(map.containsKey(key)){
//找到重复
return true;
}
map.put(key,key);//一次循环调用put 和 containsKey
}
return false;
}
public boolean containsDuplicate(int[] nums){//5ms
HashSet<Integer>set = new HashSet<>();
for(int key:nums){
if(!set.add(key)){//一次循环调用一次put
return true;
}
}
return false;
}
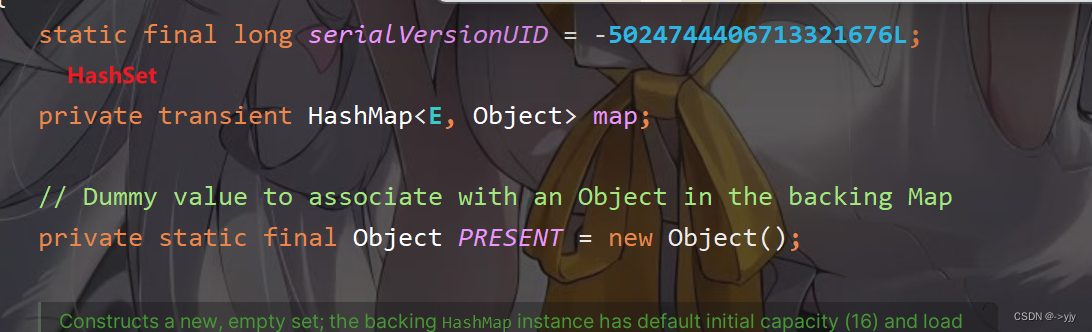

通过分析我们可以来这样修改我们的代码:6ms
public boolean containsDuplicate(int[] nums) {
HashMap<Integer,Object>map = new HashMap<>(nums.length*2);
Object value = new Object();
for(int key:nums){
Object put = map.put(key,value);
if(put!=null){
return true;
}
}
return false;
}Leetcode136
136. 只出现一次的数字 - 力扣(LeetCode)

import java.util.HashSet;
/**
* 找出出现一次的数字
* 除了某个元素只出现一次以外,其余每个元素均出现两次
*/
public class Leetcode136 {
/*
输入:nums = [2,2,1]
输出:1
HashSet
[2,] 遇到重复的就把第一个拿出来 最后集合中唯一的元素就是只出现一次的答案
输入:nums = [4,1,2,1,2]
输出4
[4]
思路一:
1.准备一个Set 集合,逐一放入数组元素
2.遇到重复的,则删除
3.最后留下来的,就是那个没有重复的数字
*/
public int singleNumber1(int[] nums){//效率低
HashSet<Integer> set = new HashSet<>();
for(int num:nums){
if (!set.add(num)) {
set.remove(num);
}
}
return set.toArray(new Integer[0])[0];
}
/*
思路二:
1.任何相同的数字异或,结果都是0
2.任何数字与0异或,结果都是数字本身
*/
public int singleNumber(int[] nums){
int num = nums[0];
for(int i=1;i<nums.length;i++){
num = num^nums[i];
}
return num;
}
public static void main(String[] args) {
Leetcode136 e06 = new Leetcode136();
System.out.println(e06.singleNumber(new int[]{2, 2, 1}));
System.out.println(e06.singleNumber(new int[]{4, 1, 2, 1, 2}));
}
}

Leetcode242
242. 有效的字母异位词 - 力扣(LeetCode)
import java.util.Arrays;
public class Leetcode242 {
/*
输入:s = "anagram", t = "nagaram"
输出:true
1.拿到字符数组,排序后比较字符数组
2.字符打散放入 int[26] 比较数组
*/
public boolean isAnagram(String s,String t){
return Arrays.equals(getKey(s),getKey(t));
}
private int[] getKey1(String s){//3ms
int[] array = new int[26];
for (int i = 0; i < s.length(); i++) {
char ch = s.charAt(i); //'a' - 97 = 0
array[ch-97]++;
}
return array;
}
private int[] getKey(String s){//1ms
int[] array = new int[26];
char[] chars = s.toCharArray();
for(char ch:chars){
array[ch-97]++;
}
return array;
}
}
Leetcode387
387. 字符串中的第一个唯一字符 - 力扣(LeetCode)
public class Leetcode387 {
public int firstUniqChar(String s) {
int[] array = new int[26];
char[] chars = s.toCharArray();
for (char ch : chars) {
array[ch - 97]++;
}
for (int i = 0; i < chars.length; i++) {
char ch = chars[i];
if(array[ch-97]==1){
return i;
}
}
return -1;
}
}
Leetcode819
819. 最常见的单词 - 力扣(LeetCode)
这种方法14ms 非常不理想
import java.util.HashMap;
import java.util.Map;
import java.util.Optional;
import java.util.Set;
public class Leetcode819 {
/*
1. 将Paragraph截取为一个个单词
2.将单词加入map集合,单词本身作为key,出现次数作为value,避免禁用词加入
3.在map集合中找到value最大的,返回它对应的key即可
*/
public String mostCommonWord(String paragraph,String[] banned){
//1
String[] split = paragraph.toLowerCase().split("[^A-Za-z]+");
Set<String> set = Set.of(banned);//Java9以上版本 转成set集合
HashMap<String,Integer>map = new HashMap<>();
for (String key : split) {
if(!set.contains(key)){//如果set中包含了key 就不加入 不包含再加入
map.compute(key,(k,v)->v==null?1:v+1);
}
// System.out.println(key);
// Integer value = map.get(key);
// if(value==null){
// value=0;
// }
// map.put(key,value+1);
// map.compute(key,(k,v)->v==null?1:v+1);//第一次放入1 不是第一次就加1 跟上面4行等效
}
// System.out.println(map);
Optional<Map.Entry<String, Integer>> max = map.entrySet().stream().max(Map.Entry.comparingByValue());
System.out.println(max);
return max.map(Map.Entry::getKey).orElse(null);
}
}
改进1:
public String mostCommonWord(String paragraph,String[] banned){//12ms
//1
String[] split = paragraph.toLowerCase().split("[^A-Za-z]+");
Set<String> set = Set.of(banned);//Java9以上版本 转成set集合
HashMap<String,Integer>map = new HashMap<>();
for (String key : split) {
if(!set.contains(key)){//如果set中包含了key 就不加入 不包含再加入
map.compute(key,(k,v)->v==null?1:v+1);
}
}
int max = 0;
String maxKey = null;
for (Map.Entry<String, Integer> e : map.entrySet()) {
Integer value = e.getValue();
if(value>max){
max= value;
maxKey = e.getKey();
}
}
return maxKey;
}import com.sun.jdi.event.StepEvent;
import java.util.HashMap;
import java.util.Map;
import java.util.Optional;
import java.util.Set;
public class Leetcode819 {
/*
1. 将Paragraph截取为一个个单词
2.将单词加入map集合,单词本身作为key,出现次数作为value,避免禁用词加入
3.在map集合中找到value最大的,返回它对应的key即可
*/
public String mostCommonWord(String paragraph,String[] banned){// 4ms
// String[] split = paragraph.toLowerCase().split("[^A-Za-z]+");
Set<String>set = Set.of(banned);
HashMap<String,Integer>map = new HashMap<>();
char[] chars = paragraph.toLowerCase().toCharArray();
StringBuilder sb =new StringBuilder();
for (char ch : chars) {
if(ch>='a'&&ch<='z'){
sb.append(ch);
}else{
String key = sb.toString();
if(!set.contains(key)){
map.compute(key,(k,v)->v==null?1:v+1);
}
// sb = new StringBuilder();
sb.setLength(0);//不创建置为0
}
}
if(sb.length()>0){
String key = sb.toString();
if(!set.contains(key)){
map.compute(key,(k,v)->v==null?1:v+1);
}
}
System.out.println(map);
int max = 0;
String maxKey = null;
for (Map.Entry<String, Integer> e : map.entrySet()) {
Integer value = e.getValue();
if(value>max){
max= value;
maxKey = e.getKey();
}
}
return maxKey;
}
}