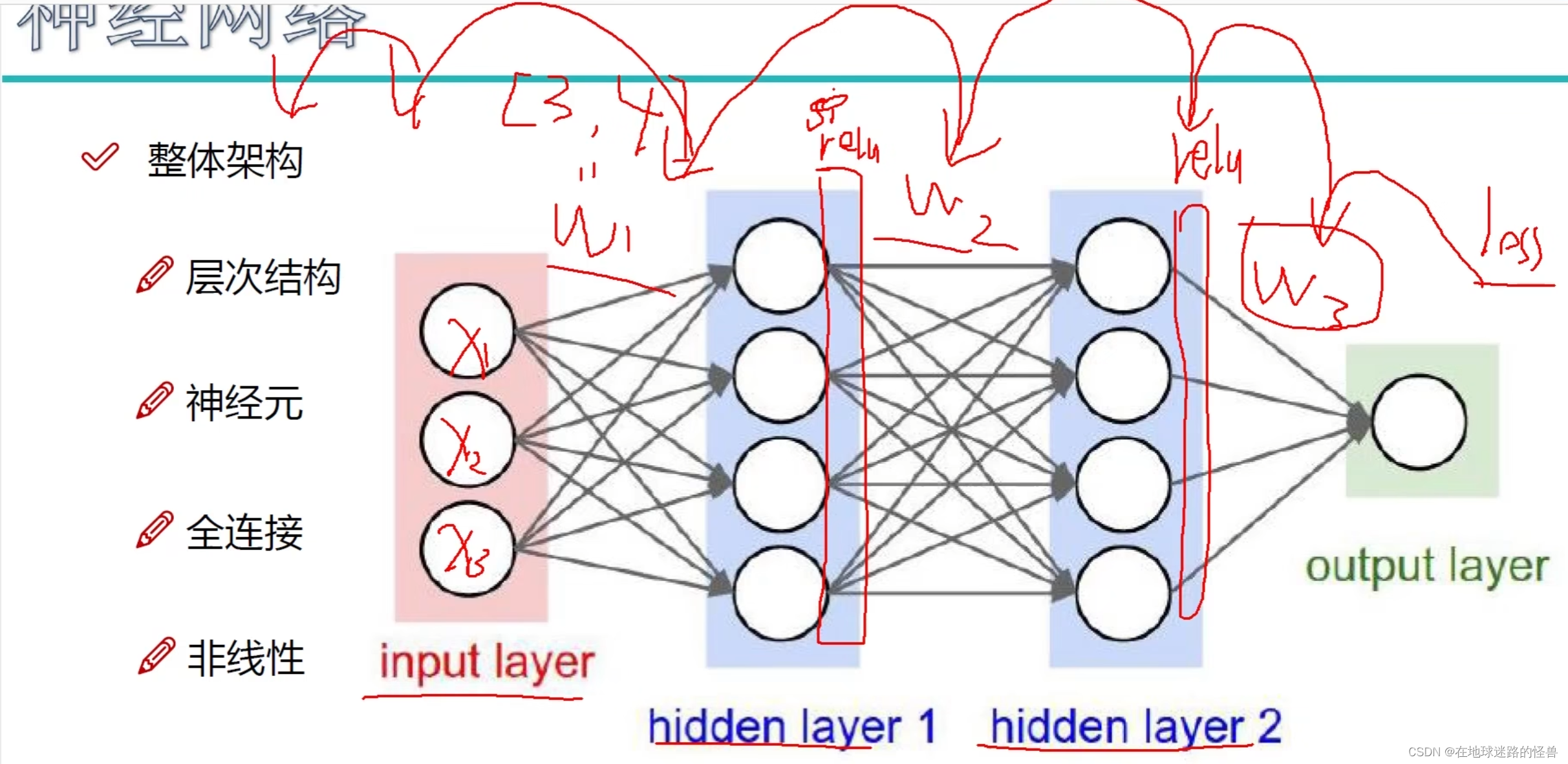
自然语言处理基础
自然语言处理:让计算机读懂人所写好的这些文本,能够像人一样进行交互。
自然语言处理的任务和应用
任务:
词性标注 part of speech tagging
动词,名词,形容词?
命名实体的识别 named entity recognition
地名? 姓?时间?
共指消解 Co-reference
代词指示的是哪个?
依赖关系识别 Basic dependencies
主谓宾?
中文:自动分词
应用:
Machine Reading:自动的阅读文本内容,然后挖掘出一些相关的结构化知识
例如浏览器知识图谱
Personal Assistant
例如虚拟助手,小米的智能管家
Machine translation 机器翻译
Sentiment Analysis and Opinion Mining 情感分析和意见挖掘
Computational Social Science 与社会科学进行交叉
词的表示:
核心目的:让机器理解词的意思
1.计算单词相似度 (例如:月亮和太阳;游泳和走路 关系相当 )
2.计算单词之间的关系(例如 中国-北京 和 日本-东京 关系相当)
方法:
1.用一些系列相关的词来表示,
例如:(近义词、反义词)good:+ benecifal -bad ; (从属关系,上位词):东北虎属于猫科虎类……
问题:
1.词之间会有差异,例如good和benefit并不完全一样;
2.错过单词的新含义 ;例如:apple 原先是水果 ,现在又是IT 公司
3. 主观性问题;
4. 数据吸收问题;
5. 需要大量的人工进行标注
one-hot representation
把一个词表示为一个独立的符号
建立一个和词表长度一样的向量,一个单词只在某一维(固定)上值为1 ,其余维都为0;
可以用来计算文档的相似度。
问题:词和词之间的向量都正交,无法表示之间的关系。
例如:月亮moon和太阳sun moon=[1,0] sun=[0,1] 相互正交
represent Word by context
根据上下文,判断单词语义。(解决one-hot蒸饺问题)

例如:单词stars 可以用频繁出现的单词( shining bright trees dark look )的出现频率 来表示 从而得到关于每一个词的一个稠密向量。从而使用这个稠密向量计算出两个词之间的相似度
问题:1,词表增大的话,存储的需求就会增大。
Word embedding
针对上面的问题我们提出改进。
常用模型:word2vec(后期介绍 )
语言模型language model
目的:根据当前已有单词预测下一个单词。
主要完成两个工作 :1.一个序列的词成为一句话的概率是多少(比如:饭吃我 不大可能成为一句话,但我吃饭却又很大可能)2.根据前面的话预测下一个单词。
基础假设:后面词出现的概率只取决于前面出现的单词

n-gram model
举个例子:4-gram #p(w/ too late to) too late to 后面接w 的概率 #count(a)a出现的次数
p(w/ too late to)=count( too late to w)/count( too late to) 只考虑前面的三个单词,不会考虑更前面的单词
在大数据中也只需要计算出每个序列出现的频度,从而估算频率
遵循马尔科夫假设。
问题:1.做统计的时候上下文其实都是基于符号来做统计的,n越大,存储的信息也就越大,所以一般都是使用2-gram,3-gram,但这样无法充分考虑上下文之间的关系 2. 基于符号做统计,和one-hot一样,认为词之间相互独立的,无法考虑到单词,句子的相似度。
neural language model
例如 :never too late to leran 这句话,考虑to 出现的概率,我们可以将前面的三个词(never too late )分别用一个低纬的向量来表示,再讲这些向量拼在一起,形成一个更高的上下文向量经过非线性的转换预测下一个向量(单词)是什么。