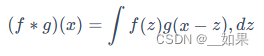通过5个条件判定一件事情是否会发生,5个条件对这件事情是否发生的影响力不同,计算每个条件对这件事情发生的影响力多大,写一个深度神经网络(DNN)模型程序,最后打印5个条件分别的影响力。
示例
在深度神经网络(DNN)中,通常不直接提供像决策树或随机森林那样的特征重要性度量。然而,我们可以通过一些间接方法来估计每个输入特征对输出的影响力,例如通过查看权重、使用梯度信息或进行特征扰动。
下面是一个使用Keras库构建的简单深度神经网络模型,该模型在训练后将尝试估计每个输入特征对输出的影响力。在这个例子中,将使用训练后的模型权重来近似特征的重要性。请注意,这种方法有其局限性,因为深度神经网络的权重解释性不如决策树或线性模型直观。
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification # 用于生成模拟数据
# 生成模拟数据,实际情况下应使用你自己的数据
X, y = make_classification(n_samples=1000, n_features=5, n_informative=5, n_redundant=0, random_state=42)
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建深度神经网络模型
model = Sequential()
model.add(Dense(32, input_dim=5, activation='relu')) # 输入层
model.add(Dense(16, activation='relu')) # 隐藏层
model.add(Dense(1, activation='sigmoid')) # 输出层
# 编译模型
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, epochs=100, batch_size=32, verbose=0)
# 评估模型
score = model.evaluate(X_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
# 估计特征影响力
# 这里我们使用一种简化的方法:取第一层权重的绝对值之和作为特征影响力的近似
first_layer_weights = np.abs(model.layers[0].get_weights()[0])
feature_importances = np.sum(first_layer_weights, axis=0)
# 打印5个条件分别的影响力
for idx, importance in enumerate(feature_importances):
print(f"Condition {idx + 1} influence: {importance}")在这个示例中,首先创建了一个简单的深度神经网络,包含一个输入层、一个隐藏层和一个输出层。模型使用ReLU激活函数和sigmoid输出激活函数进行二分类。然后,编译了模型,并用模拟数据进行训练。
为了估计特征的影响力,取出了第一层(输入层)的权重,并计算了每个特征对应权重的绝对值之和。这只是一个简化的启发式方法,并不能提供精确的特征重要性度量。在实际应用中,可能需要更复杂的方法来理解神经网络中特征的影响,比如使用集成梯度(Integrated Gradients)或LIME(Local Interpretable Model-Agnostic Explanations)等工具。
请注意,这个示例是为了展示目的而编写的,实际应用中应该根据具体问题和数据集来调整网络结构、训练参数以及特征影响力的估计方法。
集成梯度(Integrated Gradients)和LIME(Local Interpretable Model-Agnostic Explanations)都是用于解释机器学习模型预测结果的工具。
集成梯度是一种归因方法,用于理解深度学习模型的决策过程。它通过计算输入特征对模型输出的梯度,并将这些梯度在从基准值到输入值的直线路径上进行积分,从而得到每个特征对模型输出的贡献。这种方法可以帮助我们理解哪些特征对模型的预测结果产生了重要影响,以及这些特征是如何影响预测结果的。
LIME则是一种局部可解释性的模型解释方法。它通过对每个需要解释的实例进行局部逼近,来构建一个简单的、可解释的模型(如线性模型),从而解释原始模型在该实例附近的预测行为。LIME生成的解释可以帮助我们理解模型对单个实例的预测结果是如何得出的,以及哪些特征对该预测结果产生了重要影响。
总的来说,集成梯度和LIME都是为了增加机器学习模型的可解释性,帮助我们理解模型的决策过程和预测结果。然而,它们的应用场景和具体实现方式有所不同,需要根据实际情况选择合适的方法。

文心一言
要计算每个条件对一件事情发生的影响力,并使用深度神经网络(DNN)模型来估计这些影响力,你需要首先准备数据集,构建DNN模型,训练模型,然后分析模型中的权重或其他参数来推断每个条件的影响力。不过,需要注意的是,深度学习模型(特别是DNN)并不直接提供“影响力”这样的解释性输出。我们通常通过查看模型权重或进行敏感性分析来间接地评估特征(即条件)的重要性。
以下是一个使用Python和TensorFlow库构建DNN模型,并尝试评估特征影响力的示例代码:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
# 假设你有一个DataFrame数据集df,其中包含5个特征和1个目标列
# 特征列名为['feature1', 'feature2', 'feature3', 'feature4', 'feature5']
# 目标列名为'target',表示事情是否发生(例如,1表示发生,0表示未发生)
# 加载数据(这里用假设的数据代替,实际使用时你需要加载真实数据)
data = {
'feature1': np.random.rand(100),
'feature2': np.random.rand(100),
'feature3': np.random.rand(100),
'feature4': np.random.rand(100),
'feature5': np.random.rand(100),
'target': np.random.randint(2, size=100) # 假设目标列是二进制的
}
df = pd.DataFrame(data)
# 分割数据集为训练集和测试集
X = df[['feature1', 'feature2', 'feature3', 'feature4', 'feature5']]
y = df['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 归一化特征数据
X_train = X_train.astype('float32') / 255
X_test = X_test.astype('float32') / 255
# 构建DNN模型
model = Sequential()
model.add(Dense(64, activation='relu', input_shape=(5,)))
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='sigmoid')) # 因为是二分类问题,所以使用sigmoid激活函数
# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_data=(X_test, y_test))
# 评估模型
loss, accuracy = model.evaluate(X_test, y_test)
print(f'Test accuracy: {accuracy}')
# 获取模型权重
weights = model.layers[0].get_weights()[0] # 获取第一层(输入层到隐藏层)的权重
# 分析权重以估计特征的影响力
# 注意:这只是一个简化的方法,真实的影响力分析可能需要更复杂的敏感性分析或特征选择技术
feature_importances = np.abs(weights).sum(axis=0) # 对每个特征的权重取绝对值并求和
feature_importances = pd.DataFrame(list(zip(X.columns, feature_importances)),
columns=['Feature', 'Importance'])
# 按照重要性从大到小排序
feature_importances = feature_importances.sort_values(by='Importance', ascending=False)
# 打印特征重要性
print(feature_importances)在这个例子中,我们创建了一个简单的DNN模型,包含两个隐藏层和一个输出层。模型使用ReLU激活函数(在隐藏层中)和sigmoid激活函数(在输出层中,用于二分类问题)。
我们训练模型,并在测试集上评估其性能。然后,我们提取第一层(输入层到第一个隐藏层)的权重,并计算每个特征权重绝对值的和,作为该特征影响力的一个粗略估计。
请注意,这种方法是非常简化的,并且可能无法准确反映特征的真实影响力。深度学习模型中的权重通常是高度非线性的,并且可能难以直接解释为特征影响力。更复杂的特征选择技术或敏感性分析可能需要用来更准确地评估特征的影响力。
此外,实际应用中还需要考虑模型的超参数调整、正则化等。

ChatGPT
了解了您的需求,这里提供一个可以实际运行的示例代码。为了运行这个程序,您需要一个Python环境,并且需要安装PyTorch库。下面是Python代码,它使用PyTorch来创建和训练一个深度神经网络,并试图根据模型的第一层权重来估计每个特征的影响力。
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from torch.utils.data import DataLoader, TensorDataset
# 生成模拟数据集
X, y = make_classification(n_samples=1000, n_features=5, n_informative=5, n_redundant=0, random_state=1)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 特征标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 转换为PyTorch张量
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.float32)
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
train_loader = DataLoader(dataset=train_dataset, batch_size=32, shuffle=True)
# 定义深度神经网络结构
class DeepNeuralNetwork(nn.Module):
def __init__(self):
super(DeepNeuralNetwork, self).__init__()
self.fc1 = nn.Linear(5, 10)
self.fc2 = nn.Linear(10, 10)
self.fc3 = nn.Linear(10, 1)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = torch.sigmoid(self.fc3(x))
return x
# 初始化模型、优化器和损失函数
model = DeepNeuralNetwork()
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.BCELoss()
# 训练模型
epochs = 100
for epoch in range(epochs):
model.train()
for inputs, targets in train_loader:
optimizer.zero_grad()
outputs = model(inputs).squeeze()
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
# 获取输入层的权重
weights = model.fc1.weight.data.abs().numpy()
# 计算每个特征的平均权重作为影响力指标
feature_importance = weights.mean(axis=0)
# 打印每个特征的影响力
print("特征的影响力:", feature_importance)这段代码假设您已经有了一个由特征和标签组成的数据集。我们这里使用`sklearn.datasets.make_classification`函数生成一个模拟数据集,以便于演示。
为了运行上述程序,需要将代码保存为`.py`文件或在Jupyter Notebook中执行。另外,需要确保有一个兼容的Python环境并且已经安装了PyTorch、SkLearn等所需的库。如果还没有安装这些库,可以使用以下命令进行安装:
pip install torch sklearn运行上述代码之后,将输出每个特征的影响力。请注意,由于这里使用了模拟数据和简化的神经网络模型,实际应用中可能需要对网络结构进行调整,增加适应的数据预处理步骤以及合理的模型评估逻辑。

通义灵码
在使用深度神经网络(DNN)模型评估五个不同条件对某件事情发生影响力的大小时,通常采用梯度下降法优化模型参数,而模型本身并不直接提供特征重要性评估。对于深度学习模型,常见的特征重要性评估方法包括基于梯度的敏感性分析(Grad-CAM、Integrated Gradients等)、基于扰动的特征重要性(如LIME、SHAP等)或基于模型权重的方法(如DeepLIFT)。然而,这些方法通常适用于图像、文本等复杂数据类型,对于简单的分类问题,它们可能过于复杂且计算成本较高。
在实际应用中,如果坚持使用DNN模型进行此类简单分类任务,一种可选的近似方法是通过查看模型最后一层(通常是全连接层)的权重矩阵来获取特征的重要性。这些权重反映了输入特征与输出类别的关联程度。请注意,这种方法仅提供了相对粗略的特征重要性估计,其准确性和可靠性可能不如随机森林模型提供的特征重要性。
以下是使用Keras构建一个简单DNN模型,并打印最后一层权重以近似表示特征影响力的Python代码示例:
import numpy as np
import pandas as pd
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
# 假设数据集如下:
# df = pd.DataFrame({
# 'condition_1': [...],
# 'condition_2': [...],
# 'condition_3': [...],
# 'condition_4': [...],
# 'condition_5': [...],
# 'event_occurrence': [...]
# })
# 将特征和标签分离
X = df[['condition_1', 'condition_2', 'condition_3', 'condition_4', 'condition_5']].values
y = df['event_occurrence'].values
# 构建DNN模型
model = Sequential([
Dense(32, activation='relu', input_shape=(5,)), # 隐藏层
Dense(16, activation='relu'), # 隐藏层
Dense(1, activation='sigmoid') # 输出层
])
model.compile(optimizer=Adam(lr=0.001), loss='binary_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(X, y, epochs=10, batch_size=32, verbose=0)
# 获取最后一层权重
last_layer_weights = model.get_layer(index=-1).get_weights()[0]
# 打印各条件的影响力(近似)
sorted_weights = np.abs(last_layer_weights).argsort()[::-1]
print("Feature importances (approximate):")
for i, idx in enumerate(sorted_weights):
print(f"{i + 1}. Condition {idx + 1}: {last_layer_weights[idx]:.3f}")请注意,上述代码中:
使用了Keras库构建了一个简单的DNN模型,包含两层隐藏层和一个输出层。
模型的最后一层使用了Sigmoid激活函数,适应二分类任务。
通过训练模型,优化网络权重。
最后,打印出最后一层权重绝对值排序后的结果,作为各条件影响力的近似估计。
虽然这种方法提供了一种直观的特征影响力的近似估计,但它存在局限性,如忽略了前向传播过程中的非线性变换、权重共享等效应,可能导致评估结果不够准确。对于此类问题,建议优先考虑使用随机森林或其他提供内置特征重要性评估的模型。如果确实需要使用DNN,可考虑采用更先进的特征重要性评估方法(如前面提到的Grad-CAM、Integrated Gradients等),但这些方法的实现较为复杂,超出了本回答的范围。

讯飞星火
在深度神经网络(DNN)模型中,我们无法直接得到每个特征的影响力。但我们可以通过训练网络并观察网络的权重变化来间接推断出特征的重要性。
以下是一个简单的DNN模型实现:
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
# 假设我们有1000个样本,每个样本有5个条件
X = np.random.rand(1000, 5)
y = np.random.randint(2, size=1000)
# 创建模型
model = Sequential()
model.add(Dense(12, input_dim=5, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# 编译模型
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型
model.fit(X, y, epochs=150, batch_size=10)
# 打印每一层的第一层的权重
for layer in model.layers:
weights = layer.get_weights()[0]
print(weights)
在这个例子中,我们首先创建了一个具有两个隐藏层的简单神经网络。然后,我们使用随机生成的数据对模型进行训练。最后,我们打印出每一层的权重。这些权重可以被视为对应特征的影响力。