文章目录
- 知识图谱的发展历史
- 知识图谱的重要性
- 知识图谱与Ontology、语义网络之间的区别
- 知识图谱的定义
知识图谱的发展历史
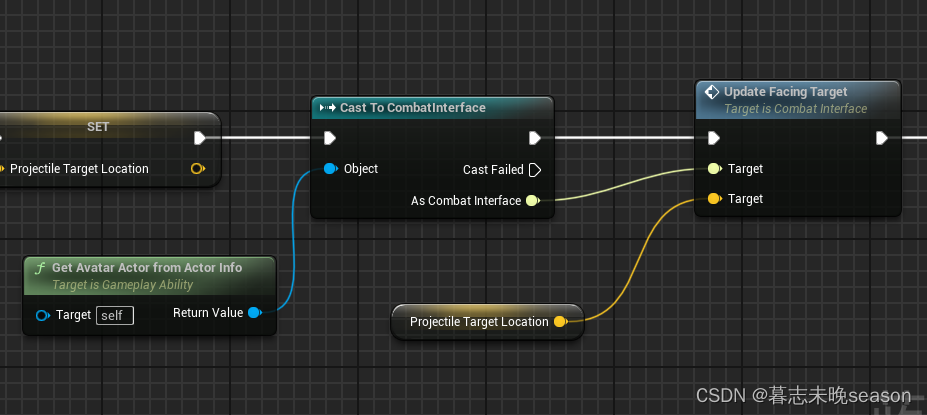
知识图谱始于20世纪50年代,至今大致分为三个发展阶段:第一阶段 (1955年—1977年)是知识图谱的起源阶段,在这一阶段中引文网络分析开始成为一种研究当代科学发展脉络的常用方法;第二阶段(1977年-2012年)是知识图谱的发展阶段,语义网得到快速发展,“知识本体”的研究开始成为计算机科学的一个重要领域,知识图谱吸收了语义网、本体在知识组织和表达方面的理念,使得知识更易于在计算机之间和计算机与人之间交换、流通和加工;第三阶段(2012年—至今)是知识图谱繁荣阶段,2012年谷歌提出Google Knowledge Graph,知识图谱正式得名,谷歌通过知识图谱技术改善了搜索引擎性能。在人工智能的蓬勃发展下,知识图谱涉及到的知识抽取、表示、融合、推理、问答等关键问题得到一定程度的解决和突破,知识图谱成为知识服务领域的一个新热点,受到国内外学者和工业界广泛关注。知识图谱具体的发展历程如下图所示。
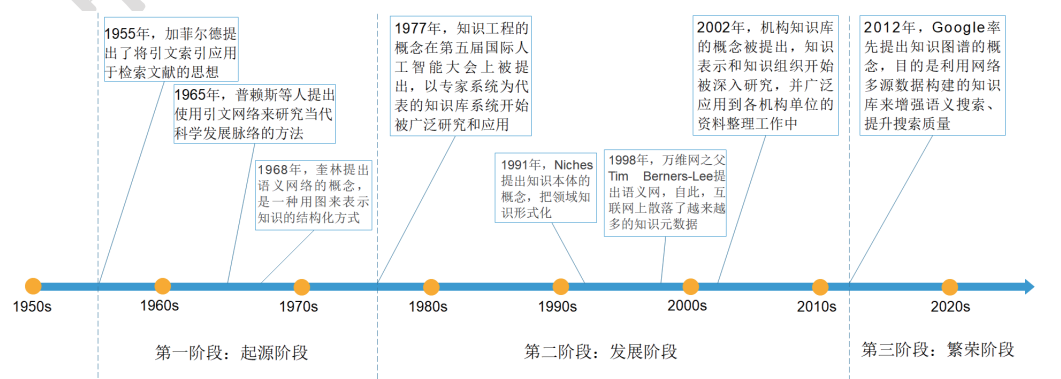
起源阶段(1955年—1977年):1955年,加菲尔德提出了将引文索引应用于检索文献的思想。1965年,普赖斯在《Networks of Scientific Papers》一文中指出,引证网络--科学文献之间的引证关系,类似于当代科学发展的“地形图”,从此分析引文网络开始成为一种研究当代科学发展脉络的常用方法,进而形成了知识图谱的概念。奎林(J. R. Quillian)于1968年提出语义网络,最初作为人类联想记忆的一个明显公理模型提出,随后在AI中用于自然语言理解,表示命题信息,语义网络是一种以网络格式表达人类知识构造的形式,是人工智能程序运用的表示方式之一。
发展阶段(1977年-2012年):1977年,在第五届国际人工智能会议上,美国计算机科学家B.A. Feigenbaum首次提出知识工程的概念,知识工程是通过存储现存的知识来实现对用户的提问进行求解的系统,其中最典型和成功的知识工程的应用是基于规则的专家系统,此后,以专家系统为代表的知识库系统开始被广泛研究和应用。1991年,美国计算机专家尼彻斯(R. Niches)等人在完成美国国防部高级研究计划局(Defense Advanced Research Projects Agency, 简称DARPA)关于知识共享的科研项目中,提出了一种构建智能系统的新思想,该智能系统由两个部分组成,一个部分是“知识本体”(ontologies),另一部分是“问题求解方法”(Problem Solving Methods,简称PSMs),知识本体是知识库的核心,涉及特定领域共有的知识结构,是静态的知识;后者(PSMs)涉及在相应领域的推理知识,是动态的知识,PSMs使用知识本体中的静态知识进行动态推理。自1998年万维网之父Tim Berners-Lee提出语义网,同时随着链接开放数据(Linked Open Data)的规模激增,互联网上散落了越来越多的知识元数据。2002年,机构知识库的概念被提出,知识表示和知识组织开始被深入研究,并广泛应用到各机构单位的资料整理工作中。
繁荣阶段(2012年—至今):21世纪,随着互联网的蓬勃发展,信息量呈爆炸式增长以及搜索引擎的出现,人们开始渴望更加快速、准确地获取所需的信息。知识图谱强调语义检索能力,关键技术包括从互联网的网页中抽取实体、属性及关系,旨在解决自动问答、个性化推荐和智能信息检索等方面的问题。目前,知识图谱技术正逐渐改变现有的信息检索方式,如谷歌、百度等主流搜索引擎都在采用知识图谱技术提供信息检索,一方面通过推理实现概念检索(相对于现有的字符串模糊匹配方式而言);另一方面以图形化方式向用户展示经过分类整理的结构化知识,从而使人们从人工过滤网页寻找答案的模式中解脱而来。
知识图谱的重要性
哲学家柏拉图把知识定义为“Justified True Belief”,即知识需要满足三个核心要素:合理性(Justified)、真实性(True)、被相信(Believed)。简单而言,知识是人类通过观察、学习和思考有关客观世界的各种现象而获得和总结出的所有事实(Facts)、概念(Concepts)、规则或原则(Rules & Principles)的集合。人类发明了各种手段来描述、表示和传承知识,如自然语言、绘画、音乐、数学语言、物理模型、化学公式等,可见对于客观世界规律的知识化描述对于人类社会发展的重要性。具有获取、表示和处理知识的能力是人类心智区别于其它物种心智的重要特征,知识图谱已成为推动机器基于人类知识获取认知能力的重要途径,并将逐渐成为未来智能社会的重要生产资料。
人工智能分为两个层次:感知层与认知层。首先感知层,即计算机的视觉、听觉、触觉等感知能力,目前人类在语音识别、图像识别等感知领域已取得重要突破,机器在感知智能方面已越来越接近于人类;第二个层次是认知层,是指机器能够理解世界和具有思考的能力。认知世界是通过大量的知识积累实现的,要使机器具有认知能力,就需要建立一个丰富完善的知识库,因此从这个角度说,知识图谱是人工智能的一个重要分支,也是机器具有认知能力的基石,在人工智能领域具有非常重要的地位。
知识图谱将人与知识智能地连接起来,能够对各类应用进行智能化升级,为用户带来更智能的应用体验。知识图谱是一个宏大的数据模型,可以构建庞大的“知识”网络,包含客观世界存在的大量实体、属性以及关系,为人们提供一种快速便捷进行知识检索与推理的的方式。近些年蓬勃发展的人工智能本质上是一次知识革命,其核心在于通过数据观察与感知世界,实现分类预测、自动化等智能化服务。 知识图谱作为人类知识描述的重要载体,推动着信息检索、智能问答等众多智能应用。
尽管人工智能依靠机器学习和深度学习取得了快速进展,但严重依赖于人类的监督以及大量的标注数据,属于弱人工智能智能范畴,离强人工智能仍然具有较大差距,而强人工智能的实现需要机器掌握大量的常识性知识,同时以人的思维模式和知识结构来进行语言理解、视觉场景解析和决策分析。如下图所示,知识图谱技术将信息中的知识或者数据加以关联,实现人类知识的描述及推理计算,并最终实现像人类一样对事物进行理解与解释。知识图谱技术是由弱人工智能发展到强人工智能过程中的必然趋势,对于实现强人工智能有着重要的意义。

知识图谱与Ontology、语义网络之间的区别
知识图谱与Ontology、语义网络等概念之间具有密切的相互联系。语义网络(Semantic Networks)是由Quillian于上世纪60年代提出的知识表达模式,主要用于自然语言理解领域,其用相互连接的节点和边来表示知识,节点表示对象、概念,边表示节点之间的关系。语义网络具有容易理解和展示、相关概念容易聚类的优点,同时也有以下几个方面的缺点:一是节点和边的值没有标准,完全由用户自己定义;二是多元数据融合比较困难,没有标准;三是无法区分概念节点和对象节点;四是无法对节点和边的标签进行定义。语义网络虽然可以让我们比较容易理解语义间的关系,但由于缺少标准,比较难以应用于实践。
1980年,本体论(Ontology)哲学概念“本体”被引入到人工智能领域用来刻画知识。本体是共享概念模型的明确的形式化规范说明,该定义体现了本体的四层含义:概念模型、明确、形式化、共享。本体是实体存在形式的描述,往往表述为一组概念定义和概念之间的层级关系,本体框架形成树状结构,通常被用来为知识图谱定义Schema。
知识图谱的定义
知识图谱(Knowledge Graph)以结构化的形式描述客观世界中概念、实体及其关系,将互联网的信息表达成更接近人类认知世界的形式,提供了一种更好地组织、管理和理解互联网海量信息的能力。知识图谱给互联网语义搜索带来了活力,同时也在智能问答中显示出强大威力,已经成为互联网知识驱动的智能应用的基础设施。知识图谱与大数据和深度学习一起,成为推动互联网和人工智能发展的核心驱动力之一。
知识图谱不是一种新的知识表示方法,而是知识表示在工业界的大规模知识应用,它将互联网上可以识别的客观对象进行关联,以形成客观世界实体和实体关系的知识库,其本质上是一种语义网络,其中的节点代表实体(entity)或者概念(concept),边代表实体/概念之间的各种语义关系。知识图谱的架构,包括知识图谱自身的逻辑结构以及构建知识图谱所采用的技术(体系)架构。知识图谱的逻辑结构可分为模式层与数据层,模式层在数据层之上,是知识图谱的核心,模式层存储的是经过提炼的知识,通常采用本体库来管理知识图谱的模式层,借助本体库对公理、规则和约束条件的支持能力来规范实体、关系以及实体的类型和属性等对象之间的联系。数据层主要是由一系列的事实组成,而知识将以事实为单位进行存储。在知识图谱的数据层,知识以事实(fact)为单位存储在图数据库。如果以“实体-关系-实体”或者“实体-属性-性值”三元组作为事实的基本表达方式,则存储在图数据库中的所有数据将构成庞大的实体关系网络,形成“知识图谱“。